Towards Detecting Neural Audio Codec Synthesized Heart Sounds
Pith reviewed 2026-06-26 12:51 UTC · model grok-4.3
The pith
A fusion framework combining MFCC and WavLM representations detects neural audio codec-synthesized heart sounds more accurately than either feature set alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
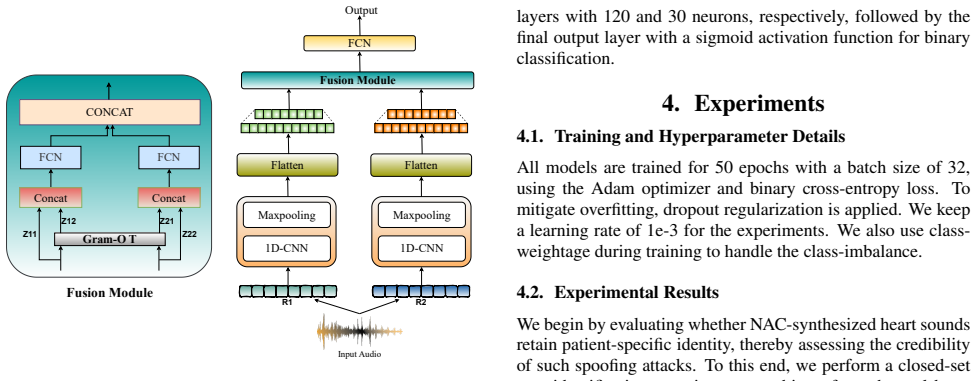
GROOT, a fusion framework that integrates spectral representations like MFCC with self-supervised learning representations like WavLM, achieves state-of-the-art performance on the SHAC task by outperforming individual representations and competitive baselines on the CARDIOFAKE dataset of real and codec-synthesized phonocardiograms.
What carries the argument
GROOT, a fusion framework that integrates spectral and SSL features for leveraging their complementary behavior.
If this is right
- GROOT outperforms standalone MFCC, LFCC, and WavLM representations on the SHAC detection task.
- Spectral and self-supervised features supply complementary information that improves synthetic heart sound identification.
- The CARDIOFAKE dataset serves as a public benchmark for future work on neural audio codec detection in medical audio.
- The proposed fusion approach establishes a stronger baseline than prior single-representation methods for this task.
Where Pith is reading between the lines
- If the fusion method proves robust to codec variations, similar combinations could be tested on other physiological audio signals such as lung sounds or fetal heart tones.
- Widespread use of neural audio codecs for medical data generation would create demand for lightweight detection modules that can run on clinical recording devices.
- The task raises the question of whether detection performance remains high when the synthesis model is fine-tuned specifically to evade the chosen feature extractors.
Load-bearing premise
The CARDIOFAKE dataset and the chosen neural audio codec synthesis methods produce examples that are representative of potential real-world synthetic heart sounds and that the detection task has practical medical relevance.
What would settle it
Performance of the MFCC-WavLM fusion drops below that of the individual features when evaluated on a fresh set of heart sounds synthesized by a neural audio codec architecture not used to create the CARDIOFAKE training examples.
Figures
read the original abstract
In this paper, we introduce Synthetic Heart Sound Detection (SHAC), a task aimed at identifying phonocardiograms (PCGs) synthesized using neural audio codecs (NACs). To facilitate research in this direction, we release CARDIOFAKE, the first benchmark dataset for SHAC containing both real and codec-synthesized PCGs. We benchmark spectral representations (MFCC, LFCC) and self-supervised learning (SSL) representations (e.g., WavLM) for the task. Furthermore, we propose GROOT, a fusion framework that integrates spectral and SSL features for leveraging their complementary behavior. Experiments show that GROOT, combining MFCC and WavLM, achieves state-of-the-art performance, outperforming individual representations and competitive baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Synthetic Heart Sound Detection (SHAC) task for identifying phonocardiograms (PCGs) synthesized using neural audio codecs (NACs). It releases the CARDIOFAKE benchmark dataset containing both real and codec-synthesized PCGs, benchmarks spectral representations (MFCC, LFCC) and self-supervised learning representations (e.g., WavLM), and proposes the GROOT fusion framework that integrates spectral and SSL features, claiming state-of-the-art performance when combining MFCC and WavLM.
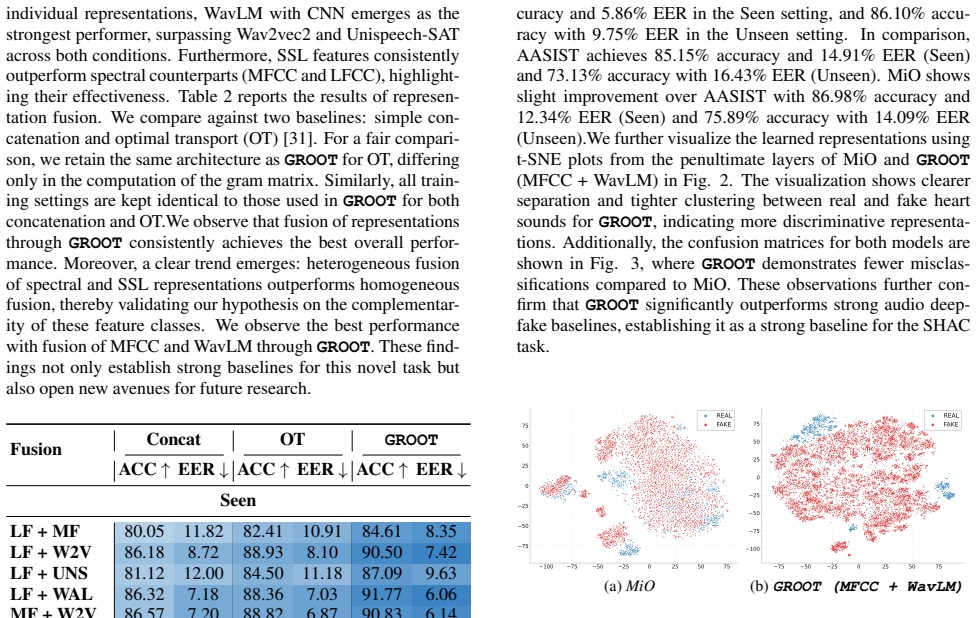
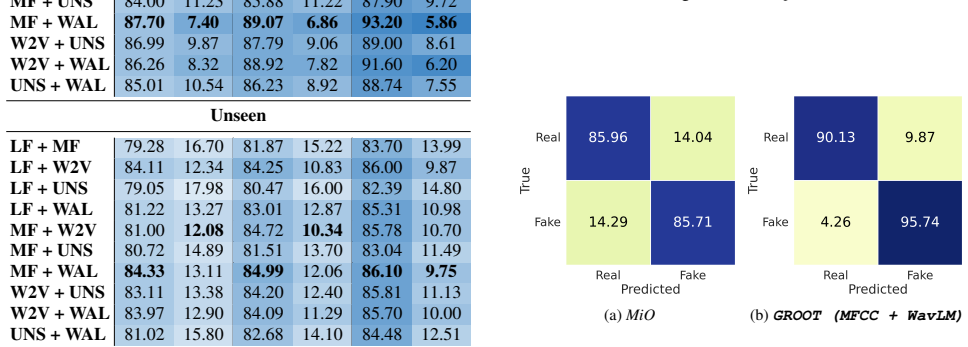
Significance. If the empirical results hold under rigorous validation and the CARDIOFAKE synthesis pipeline is shown to produce artifacts representative of realistic medical forgeries, the work could provide a useful starting benchmark for detecting synthetic heart sounds with implications for healthcare data integrity. The idea of fusing complementary spectral and SSL features is a standard and defensible approach for audio detection tasks, but the absence of methodological details prevents any assessment of whether the claimed gains are robust or generalizable.
major comments (2)
- [Abstract] Abstract: The claim that GROOT achieves state-of-the-art performance is stated without any supporting experimental details on dataset statistics, NAC synthesis methods, train/validation/test splits, baseline implementations, or error analysis, rendering the central empirical result impossible to evaluate.
- [Abstract] Abstract: The practical relevance of GROOT's reported superiority requires that the CARDIOFAKE generation process (real PCGs passed through selected NACs) produces synthesis artifacts matching those an adversary would create in a medical setting. No codec selection criteria, perceptual validation, or comparison against alternative synthesis methods are supplied, so it remains possible that performance gains are an artifact of the specific benchmark construction rather than evidence of a general detector.
minor comments (1)
- The abstract would be strengthened by including at least high-level dataset size or class balance information to contextualize the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that GROOT achieves state-of-the-art performance is stated without any supporting experimental details on dataset statistics, NAC synthesis methods, train/validation/test splits, baseline implementations, or error analysis, rendering the central empirical result impossible to evaluate.
Authors: The abstract is intended as a concise summary, which is standard practice. All requested experimental details are provided in the full manuscript: dataset statistics and CARDIOFAKE construction in Section 3, NAC synthesis methods in Section 3.1, train/validation/test splits in Section 4.1, baseline implementations in Section 4.2, and error analysis in Section 5. The SOTA claim is supported by the quantitative results in Section 5. revision: no
-
Referee: [Abstract] Abstract: The practical relevance of GROOT's reported superiority requires that the CARDIOFAKE generation process (real PCGs passed through selected NACs) produces synthesis artifacts matching those an adversary would create in a medical setting. No codec selection criteria, perceptual validation, or comparison against alternative synthesis methods are supplied, so it remains possible that performance gains are an artifact of the specific benchmark construction rather than evidence of a general detector.
Authors: We agree that realism of the synthesis artifacts is important. The manuscript constructs CARDIOFAKE by applying popular NACs to real PCGs from public datasets, with codec selection based on their prevalence in recent literature and low-bitrate high-fidelity capabilities. A formal perceptual validation study with medical experts is not included in this initial benchmark paper, but the pipeline is designed to reflect plausible adversarial use of current NACs. We will expand the discussion of codec selection criteria and note the value of future perceptual studies in the revision. revision: partial
Circularity Check
No circularity: purely empirical benchmarking with no derivations or fitted predictions
full rationale
The paper introduces the SHAC task and CARDIOFAKE dataset, then benchmarks spectral and SSL representations before proposing the GROOT fusion model. All claims rest on experimental performance numbers obtained by training and evaluating classifiers on the released data. No equations, parameter-fitting steps, uniqueness theorems, or self-citations are invoked to derive results; the reported SOTA is a direct empirical outcome rather than a reduction to inputs by construction. This matches the default expectation for an empirical ML paper and receives the lowest circularity score.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards Detecting Neural Audio Codec Synthesized Heart Sounds
Introduction & Background Spoofing attack detection (SAD) is widely regarded as a core safeguard for biometric systems, and has been systematically explored in speech [1] and facial recognition [2]. In the speech domain, extensive research has investigated replay and voice conversion-based attacks, leading to standardized evaluations such as the ASVspoof ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
CARDIOFAKE Dataset This section outlines the resources and methodology employed in creating theCARDIOFAKEdataset, including the heart sounds corpora, the NACs used for synthesis, and the overall pipeline for producing the artificial samples. 2.1. Heart Sound Dataset For synthesizing heart sounds, we employ CirCor DigiScope dataset [17], which is openly ac...
-
[3]
Feature Extraction We employ MFCC 2 and and linear-frequency cepstral coef- ficients (LFCC 3) as spectral representations
Methodology 3.1. Feature Extraction We employ MFCC 2 and and linear-frequency cepstral coef- ficients (LFCC 3) as spectral representations. We extract 14- dimensional LFCC and 40-dimensional MFCC after average pooling. We employ different SOTA SSL representations as they have shown effectiveness for heart sound classfication tasks [26]. We use Wav2vec2 4 ...
-
[4]
Training and Hyperparameter Details All models are trained for 50 epochs with a batch size of 32, using the Adam optimizer and binary cross-entropy loss
Experiments 4.1. Training and Hyperparameter Details All models are trained for 50 epochs with a batch size of 32, using the Adam optimizer and binary cross-entropy loss. To mitigate overfitting, dropout regularization is applied. We keep a learning rate of 1e-3 for the experiments. We also use class- weightage during training to handle the class-imbalanc...
-
[5]
To facilitate research in this direction, we releaseCARDIOFAKE, the first benchmark dataset for SHAC, containing both real and codec-synthesized heart sounds
Conclusion In summary, this work introduces the novel task of SHAC, high- lighting the emerging risk posed by NACs. To facilitate research in this direction, we releaseCARDIOFAKE, the first benchmark dataset for SHAC, containing both real and codec-synthesized heart sounds. We perform extensive evalaution of both spec- tral (MFCC, LFCC) and SSL representa...
-
[6]
These tools were not involved in developing the scientific ideas, conducting data analysis, generating results, or interpreting the findings
Generative AI Use Disclosure AI-assisted tools were used only to enhance grammar, clarity, and overall presentation of the manuscript. These tools were not involved in developing the scientific ideas, conducting data analysis, generating results, or interpreting the findings. The authors take full responsibility for the accuracy, validity, and integrity o...
-
[7]
Toward a universal synthetic speech spoofing detection using phase information,
J. Sanchezet al., “Toward a universal synthetic speech spoofing detection using phase information,”IEEE Transactions on Infor- mation F orensics and Security, vol. 10, no. 4, pp. 810–820, 2015
2015
-
[8]
Face recognition under spoofing attacks: counter- measures and research directions,
L. Liet al., “Face recognition under spoofing attacks: counter- measures and research directions,”Iet Biometrics, vol. 7, no. 1, pp. 3–14, 2018
2018
-
[9]
Asvspoof 2015: the first automatic speaker verifica- tion spoofing and countermeasures challenge,
Z. Wuet al., “Asvspoof 2015: the first automatic speaker verifica- tion spoofing and countermeasures challenge,” inINTERSPEECH 2015, 2015, pp. 2037–2041
2015
-
[10]
ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection
M. Todiscoet al., “Asvspoof 2019: Future horizons in spoofed and fake audio detection,”arXiv preprint arXiv:1904.05441, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Audio replay attack detection with deep learning frameworks
G. Lavrentyevaet al., “Audio replay attack detection with deep learning frameworks.” inInterspeech, 2017, pp. 82–86
2017
-
[12]
H. Delgadoet al., “Asvspoof 2021: Automatic speaker verifi- cation spoofing and countermeasures challenge evaluation plan,” arXiv preprint arXiv:2109.00535, 2021
-
[13]
Face spoofing detection from single images using micro-texture analysis,
J. M ¨a¨att¨aet al., “Face spoofing detection from single images using micro-texture analysis,” in2011 international joint conference on Biometrics (IJCB). IEEE, 2011, pp. 1–7
2011
-
[14]
Face spoof detection with image distortion anal- ysis,
D. Wenet al., “Face spoof detection with image distortion anal- ysis,”IEEE Transactions on Information F orensics and Security, vol. 10, no. 4, pp. 746–761, 2015
2015
-
[15]
Face anti-spoofing based on color texture analysis,
Z. Boulkenafetet al., “Face anti-spoofing based on color texture analysis,” in2015 IEEE international conference on image pro- cessing (ICIP). IEEE, 2015, pp. 2636–2640
2015
-
[16]
Deep representations for iris, face, and fin- gerprint spoofing detection,
D. Menottiet al., “Deep representations for iris, face, and fin- gerprint spoofing detection,”IEEE Transactions on Information F orensics and Security, vol. 10, no. 4, pp. 864–879, 2015
2015
-
[17]
Heart sound as a biometric,
K. Phuaet al., “Heart sound as a biometric,”Pattern recognition, vol. 41, no. 3, pp. 906–919, 2008
2008
-
[18]
Biometric system from heart sound using wavelet based feature set,
G. Gautam and D. Kumar, “Biometric system from heart sound using wavelet based feature set,” in2013 International Confer- ence on Communication and Signal Processing, 2013, pp. 551– 555
2013
-
[19]
Analysis of heart sound as biometric using mfcc & linear svm classifier,
S. Vermaet al., “Analysis of heart sound as biometric using mfcc & linear svm classifier,”International Journal of Advanced Re- search in Electrical, Electronics and Instrumentation Engineer- ing, vol. 3, no. 1, pp. 6626–6633, 2014
2014
-
[20]
Enabling passive user authentication via heart sounds on in-ear microphones,
Y . Caoet al., “Enabling passive user authentication via heart sounds on in-ear microphones,”IEEE Transactions on Depend- able and Secure Computing, vol. 22, no. 2, pp. 1195–1209, 2025
2025
-
[21]
Codecfake: An initial dataset for detecting llm-based deepfake audio,
Y . Luet al., “Codecfake: An initial dataset for detecting llm-based deepfake audio,” inInterspeech 2024, 2024, pp. 1390–1394
2024
-
[22]
Codecfake: Enhancing anti-spoofing models against deepfake audios from codec-based speech synthesis sys- tems,
H. Wuet al., “Codecfake: Enhancing anti-spoofing models against deepfake audios from codec-based speech synthesis sys- tems,” inInterspeech 2024, 2024, pp. 1770–1774
2024
-
[23]
The circor digiscope dataset: from murmur de- tection to murmur classification,
J. Oliveiraet al., “The circor digiscope dataset: from murmur de- tection to murmur classification,”IEEE journal of biomedical and health informatics, vol. 26, no. 6, pp. 2524–2535, 2021
2021
-
[24]
Physiobank, physiotoolkit, and phys- ionet: Components of a new research resource for complex phys- iologic signals,
A. L. Goldbergeret al., “Physiobank, physiotoolkit, and phys- ionet: Components of a new research resource for complex phys- iologic signals,”Circulation [Online], vol. 101, no. 23, pp. e215– e220, 2000
2000
-
[25]
High-fidelity audio compression with improved rvqgan,
R. Kumaret al., “High-fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[26]
High Fidelity Neural Audio Compression
A. D ´efossezet al., “High fidelity neural audio compression,” arXiv preprint arXiv:2210.13438, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Soundstream: An end-to-end neural au- dio codec,
N. Zeghidouret al., “Soundstream: An end-to-end neural au- dio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[28]
Speechtokenizer: Unified speech tokenizer for speech language models,
X. Zhanget al., “Speechtokenizer: Unified speech tokenizer for speech language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=AF9Q8Vip84
2024
-
[29]
Funcodec: A fundamental, reproducible and inte- grable open-source toolkit for neural speech codec,
Z. Duet al., “Funcodec: A fundamental, reproducible and inte- grable open-source toolkit for neural speech codec,” inICASSP 2024-2024. IEEE, 2024, pp. 591–595
2024
-
[30]
Audiodec: An open-source streaming high- fidelity neural audio codec,
Y .-C. Wuet al., “Audiodec: An open-source streaming high- fidelity neural audio codec,” inICASSP 2023. IEEE, 2023, pp. 1–5
2023
-
[31]
Snac: Multi-scale neural audio codec,
H. Siuzdaket al., “Snac: Multi-scale neural audio codec,”arXiv preprint arXiv:2410.14411, 2024
-
[32]
Exploring wav2vec 2.0 model for heart murmur detection,
D. Shariat Panah, A. Hines, and S. McKeever, “Exploring wav2vec 2.0 model for heart murmur detection,” in2023 31st Eu- ropean Signal Processing Conference (EUSIPCO). IEEE, 2023, pp. 1010–1014
2023
-
[33]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevskiet al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,”Advances in neural informa- tion processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[34]
Unispeech-sat: Universal speech representa- tion learning with speaker aware pre-training,
S. Chenet al., “Unispeech-sat: Universal speech representa- tion learning with speaker aware pre-training,”ICASSP 2022, pp. 6152–6156, 2021
2022
-
[35]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
——, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Sig- nal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[36]
Heterogeneity over homogeneity: In- vestigating multilingual speech pre-trained models for detecting audio deepfake,
O. Chetia Phukanet al., “Heterogeneity over homogeneity: In- vestigating multilingual speech pre-trained models for detecting audio deepfake,” inFindings: NAACL 2024, Jun. 2024, pp. 2496– 2506
2024
-
[37]
Multimodal learning using optimal transport for sarcasm and humor detection,
S. Pramanicket al., “Multimodal learning using optimal transport for sarcasm and humor detection,” inProceedings of WACV, 2022, pp. 3930–3940
2022
-
[38]
Lavcap: Llm-based audio-visual captioning using optimal transport,
K. Rhoet al., “Lavcap: Llm-based audio-visual captioning using optimal transport,” inICASSP 2025. IEEE, 2025, pp. 1–5
2025
-
[39]
Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,” inICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022, pp. 6367–6371
2022
-
[40]
Het- erogeneity over homogeneity: Investigating multilingual speech pre-trained models for detecting audio deepfake,
O. C. Phukan, G. Kashyap, A. B. Buduru, and R. Sharma, “Het- erogeneity over homogeneity: Investigating multilingual speech pre-trained models for detecting audio deepfake,” inFindings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 2496–2506
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.