BtrLog: Low-Latency Logging for Cloud Database Systems
Pith reviewed 2026-06-26 02:03 UTC · model grok-4.3
The pith
BtrLog achieves lower write latency than remote block storage while archiving logs cheaply to object storage for single-writer cloud databases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
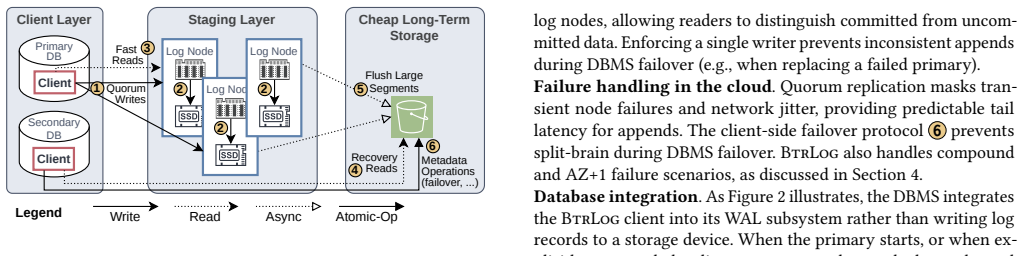
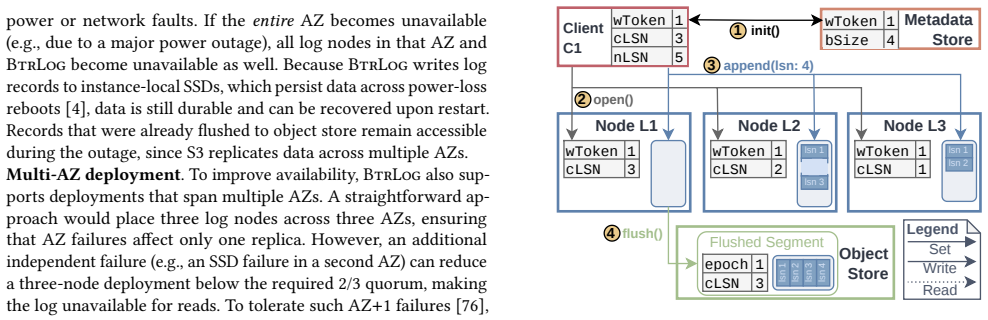
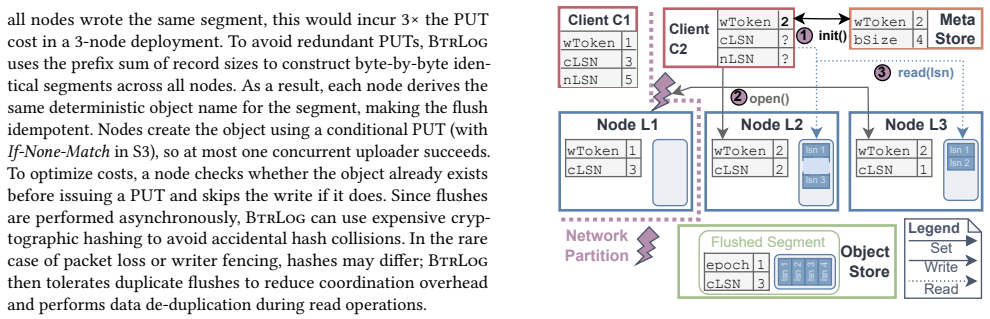
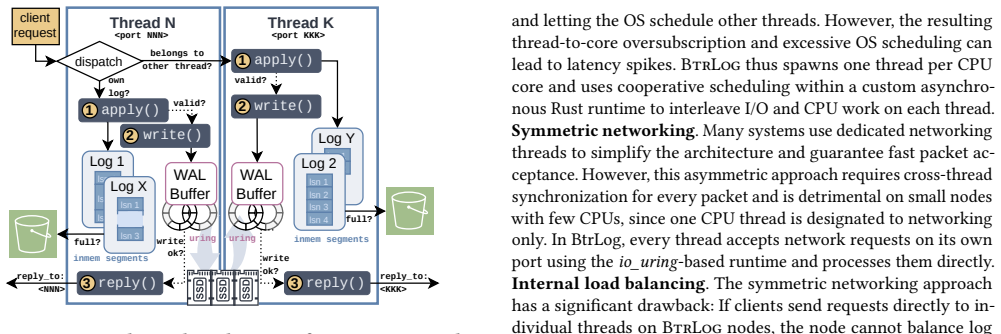
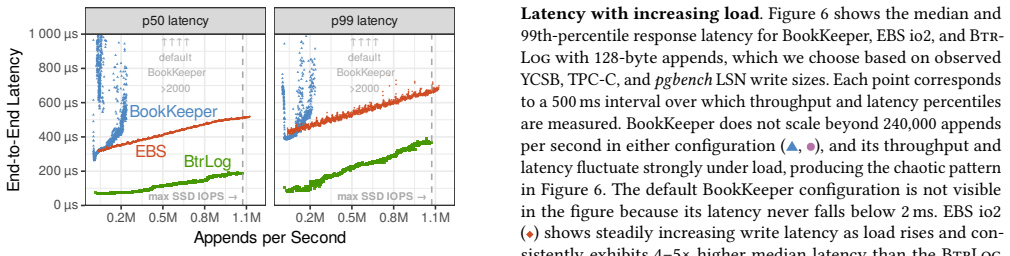
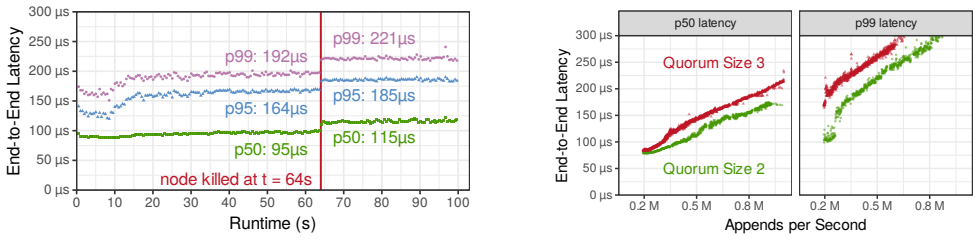
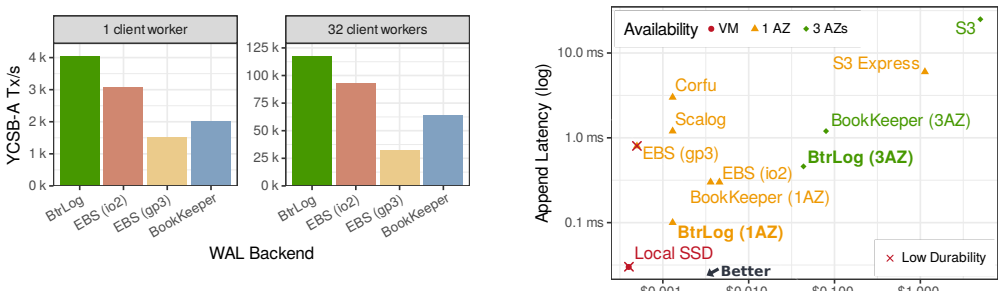
BtrLog replicates log records across a quorum of SSD-backed log nodes in a single network round trip to provide low-latency durable appends for the common single-writer architecture, while archiving those records asynchronously as large segments to object storage to keep storage costs low; when integrated into a DBMS this yields lower latency than EBS and higher end-to-end transaction throughput.
What carries the argument
Quorum replication of log records to SSD nodes in one round trip, paired with asynchronous off-path archiving of segments to object storage.
If this is right
- Cloud databases can replace remote block storage for WAL with a service that reduces commit latency.
- Transaction throughput rises when the logging layer is swapped for BtrLog in a single-writer DBMS.
- A single reusable logging backend can serve multiple engines instead of requiring engine-specific proprietary solutions.
- Log nodes become less sensitive to individual stragglers because durability is achieved in one round trip.
Where Pith is reading between the lines
- The single-writer restriction may require additional coordination layers before the approach can be used in multi-writer or sharded deployments.
- If archiving latency ever leaks into the critical path under heavy load, the latency advantage over EBS would disappear.
- The same quorum-plus-async pattern could be tested on other durable-append workloads outside databases, such as event streams.
Load-bearing premise
The design assumes a single-writer architecture and that archiving to object storage can run asynchronously without touching the latency-critical write path.
What would settle it
A direct latency comparison in the same cloud region showing BtrLog commit times equal to or higher than EBS, or an integration test where end-to-end transaction throughput does not increase.
Figures
read the original abstract
Cloud database systems cannot rely on instance-local disks for write-ahead logging (WAL) durability, forcing WAL onto remote storage. Existing options are unsatisfying: remote block storage like EBS is easy to adopt but adds substantial write latency and cost, while object storage offers excellent durability and low storage cost but is impractical for OLTP due to high latency and per-append cost. Many cloud-native databases, therefore, depend on purpose-built logging backends, which are typically proprietary and tightly coupled to engine-specific replication and recovery protocols, limiting reuse. We present BtrLog, a reusable cloud logging service that combines low-latency durable appends with low-cost archival for the common single-writer architecture. BtrLog replicates log records across a quorum of SSD-backed log nodes in a single network round trip, reducing sensitivity to stragglers in commit latency. To minimize storage cost, log nodes archive records to object storage as large segments, which are written asynchronously and off the latency-critical write path. In our evaluation, BtrLog achieves lower latency than EBS and enables higher end-to-end transaction throughput when integrated into a DBMS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BtrLog, a reusable logging service for cloud database systems under the common single-writer architecture. It replicates log records to a quorum of SSD-backed log nodes in a single network RTT for durable low-latency appends, while asynchronously archiving large segments to object storage off the critical path to achieve low storage cost. The central claim is that this design yields lower write latency than EBS while enabling higher end-to-end transaction throughput when integrated into a DBMS.
Significance. If the performance isolation and latency claims hold with reproducible evidence, BtrLog would address a recurring pain point in cloud-native OLTP by offering a reusable, non-proprietary logging backend that combines the latency of block storage with the cost of object storage. This could influence the design of multiple cloud database engines.
major comments (2)
- [Evaluation] Evaluation section: the headline claim of lower latency than EBS and higher throughput rests on the assertion that asynchronous archival imposes zero overhead on the append path, yet the provided abstract (and by extension the evaluation) supplies no resource-utilization traces, latency histograms with/without archiving, or I/O-bandwidth measurements under sustained load. This directly bears on whether the single-RTT quorum design actually beats EBS once background work is active.
- [Design and Implementation] §3 (design) and §4 (implementation): the paper states that archival writes occur 'asynchronously and off the latency-critical write path,' but does not specify the scheduling, throttling, or isolation mechanisms (e.g., separate thread pools, rate limiters, or SSD queue separation) used to prevent contention for CPU, network, or SSD bandwidth on the log nodes. Without these details the zero-overhead claim cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the evaluation sentence reports qualitative outcomes ('lower latency', 'higher throughput') but omits any numerical values, baselines, or workload descriptions; this should be expanded with at least one concrete result (e.g., 'X µs median latency vs. EBS Y µs at Z tps').
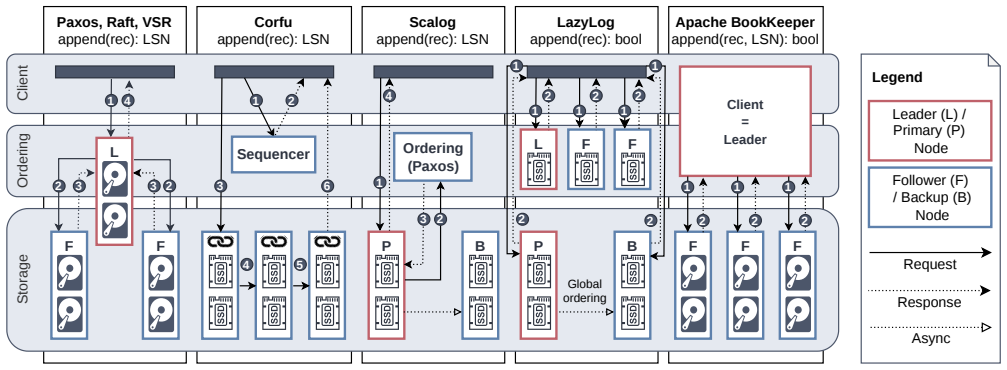
- [Introduction] The manuscript should clarify the exact replication protocol (e.g., which variant of Paxos or Raft is used) and recovery semantics to allow reuse by other engines, as promised in the introduction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which identify gaps in our evaluation evidence and implementation details. We will revise the manuscript to strengthen these sections while preserving the core claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline claim of lower latency than EBS and higher throughput rests on the assertion that asynchronous archival imposes zero overhead on the append path, yet the provided abstract (and by extension the evaluation) supplies no resource-utilization traces, latency histograms with/without archiving, or I/O-bandwidth measurements under sustained load. This directly bears on whether the single-RTT quorum design actually beats EBS once background work is active.
Authors: We agree that the current evaluation lacks sufficient supporting measurements to fully substantiate the zero-overhead claim under concurrent archival. In the revised manuscript we will add (1) resource-utilization traces for CPU, network, and SSD I/O on log nodes, (2) latency histograms for append operations with and without active archiving, and (3) sustained-load I/O-bandwidth measurements. These additions will allow readers to assess whether background archival affects the single-RTT critical path. revision: yes
-
Referee: [Design and Implementation] §3 (design) and §4 (implementation): the paper states that archival writes occur 'asynchronously and off the latency-critical write path,' but does not specify the scheduling, throttling, or isolation mechanisms (e.g., separate thread pools, rate limiters, or SSD queue separation) used to prevent contention for CPU, network, or SSD bandwidth on the log nodes. Without these details the zero-overhead claim cannot be assessed.
Authors: The referee correctly notes that the manuscript does not describe the concrete isolation mechanisms. We will expand §4 to specify the implementation: dedicated background thread pools for archival, configurable rate limiters on archival bandwidth, and explicit separation of SSD I/O queues plus distinct network connections for foreground appends versus background archiving. These details will make the off-critical-path claim verifiable. revision: yes
Circularity Check
No circularity: system design with no equations or self-referential derivations
full rationale
The paper presents a system architecture for low-latency logging rather than any mathematical derivation chain. Claims rest on the described design (quorum replication in one RTT, asynchronous off-path archival to object storage) and subsequent evaluation, with no equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations visible in the provided text. The single-writer assumption and asynchronous archiving are stated design choices, not reductions to prior results by the same authors. This matches the default expectation of a non-circular systems paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
BtrLog
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services. 2025. Amazon EC2 Placement Groups. https://docs.aws. amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
2025
-
[2]
Amazon Web Services. 2025. Availability Zones. https://docs.aws.amazon.com/ whitepapers/latest/aws-fault-isolation-boundaries/availability-zones.html
2025
-
[3]
Amazon Web Services. 2025. Placement strategies for your placement groups. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement- strategies.htm
2025
-
[4]
Amazon Web Services. 2026. Data persistence for Amazon EC2 instance store volumes. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance- store-lifetime.html
2026
-
[5]
Amazon Web Services. 2026. Data protection in Amazon S3. https://docs.aws. amazon.com/AmazonS3/latest/userguide/DataDurability.html
2026
-
[6]
Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernan- dez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chai- tanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. 2019. Socrates: The New SQL Server in the Cloud....
2019
-
[7]
Apache Software Foundation. 2020. Apache Pulsar. https://pulsar.apache.org/. Accessed: 2026-01-31
2020
-
[8]
Apache Software Foundation. 2026. Apache BookKeeper Github Repository. https://github.com/apache/bookkeeper
2026
-
[9]
Jens Axboe. 2026. Flexible I/O Tester. https://github.com/axboe/fio
2026
-
[10]
September 13, 2023
Jens Axboe. September 13, 2023. Efficient IO with io_uring. https://kernel.dk/ io_uring.pdf
2023
-
[11]
Mahesh Balakrishnan, Jason Flinn, Chen Shen, Mihir Dharamshi, Ahmed Jafri, Xiao Shi, Santosh Ghosh, Hazem Hassan, Aaryaman Sagar, Rhed Shi, Jingming Liu, Filip Gruszczynski, Xianan Zhang, Huy Hoang, Ahmed Yossef, Francois Richard, and Yee Jiun Song. 2020. Virtual Consensus in Delos. InOSDI. 617–632
2020
-
[12]
Davis, Vijayan Prabhakaran, Michael Wei, and Ted Wobber
Mahesh Balakrishnan, Dahlia Malkhi, John D. Davis, Vijayan Prabhakaran, Michael Wei, and Ted Wobber. 2013. CORFU: A distributed shared log.ACM Trans. Comput. Syst.31, 4 (2013), 10
2013
-
[13]
Mahesh Balakrishnan, Dahlia Malkhi, Vijayan Prabhakaran, Ted Wobber, Michael Wei, and John D. Davis. 2012. CORFU: A Shared Log Design for Flash Clusters. InNSDI. 1–14
2012
-
[14]
Jeff Barr. 2008. Amazon EBS (elastic block store) – bring us your data | Amazon Web Services. https://aws.amazon.com/blogs/aws/amazon-elastic/
2008
-
[15]
Jeff Barr. 2009. Introducing Amazon RDS – The Amazon Relational Database Service. https://aws.amazon.com/blogs/aws/introducing-rds-the-amazon- relational-database-service/
2009
-
[16]
Bernstein, Colin W
Philip A. Bernstein, Colin W. Reid, and Sudipto Das. 2011. Hyder - A Transactional Record Manager for Shared Flash. InCIDR. 9–20
2011
-
[17]
Bhat, Tony Hong, Xuhao Luo, Jiyu Hu, Aishwarya Ganesan, and Ramnatthan Alagappan
Shreesha G. Bhat, Tony Hong, Xuhao Luo, Jiyu Hu, Aishwarya Ganesan, and Ramnatthan Alagappan. 2025. Low End-to-End Latency atop a Speculative Shared Log with Fix-Ante Ordering. InOSDI. USENIX Association, 465–481
2025
-
[18]
Thomas Bodner, Theo Radig, David Justen, Daniel Ritter, and Tilmann Rabl. 2025. An Empirical Evaluation of Serverless Cloud Infrastructure for Large-Scale Data Processing. InEDBT. 935–948
2025
-
[19]
James Bornholt, Rajeev Joshi, Vytautas Astrauskas, Brendan Cully, Bernhard Kragl, Seth Markle, Kyle Sauri, Drew Schleit, Grant Slatton, Serdar Tasiran, Ja- cob Van Geffen, and Andrew Warfield. 2021. Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3. InSOSP. ACM, 836–850
2021
-
[20]
Marc Brooker. 2024. AWS re:Invent 2024 - Deep dive into Amazon Aurora DSQL and its architecture (DAT427-NEW). https://www.youtube.com/watch?v= huGmR_mi5dQ&t=627s
2024
-
[21]
Marc Brooker, Tao Chen, and Fan Ping. 2020. Millions of Tiny Databases. In 17th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2020, Santa Clara, CA, USA, February 25-27, 2020, Ranjita Bhagwan and George Porter (Eds.). 463–478. https://www.usenix.org/conference/nsdi20/presentation/ brooker
2020
-
[22]
Tushar Deepak Chandra and Sam Toueg. 1996. Unreliable Failure Detectors for Reliable Distributed Systems.J. ACM43, 2 (1996), 225–267
1996
-
[23]
Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, J
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, J. J. Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson C. Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Yasushi Saito, Michal Szymani...
2012
-
[24]
CorfuDB Organization. 2026. Corfu Github Repository. https://github.com/ CorfuDB/CorfuDB
2026
-
[25]
Alex Depoutovitch, Chong Chen, Jin Chen, Paul Larson, Shu Lin, Jack Ng, Wenlin Cui, Qiang Liu, Wei Huang, Yong Xiao, and Yongjun He. 2020. Taurus Database: How to be Fast, Available, and Frugal in the Cloud. InSIGMOD. 1463–1478
2020
-
[26]
Cristian Diaconu, Craig Freedman, Erik Ismert, Per-Åke Larson, Pravin Mittal, Ryan Stonecipher, Nitin Verma, and Mike Zwilling. 2013. Hekaton: SQL server’s memory-optimized OLTP engine. InSIGMOD. 1243–1254
2013
-
[27]
Cong Ding, David Chu, Evan Zhao, Xiang Li, Lorenzo Alvisi, and Robbert van Renesse. 2020. Scalog: Seamless Reconfiguration and Total Order in a Scalable Shared Log. InNSDI. 325–338
2020
-
[28]
Aleksandar Dragojević, Dushyanth Narayanan, Orion Hodson, and Miguel Cas- tro. 2014. FaRM: Fast Remote Memory. InNSDI. 401–414
2014
-
[29]
Satish Duggana, Sriharsha Chintalapani, Ying Zheng, and Suresh Srinivas. 2025. KIP-405: Kafka Tiered Storage. https://cwiki.apache.org/confluence/display/ KAFKA/KIP-405%3A+Kafka+Tiered+Storage
2025
-
[30]
Dominik Durner, Viktor Leis, and Thomas Neumann. 2023. Exploiting Cloud Object Storage for High-Performance Analytics.Proc. VLDB Endow.16, 11 (2023), 2769–2782
2023
-
[31]
Muhammad El-Hindi, Tobias Ziegler, and Carsten Binnig. 2023. Towards Merkle Trees for High-Performance Data Systems. InVDBS@SIGMOD. ACM, 28–33
2023
-
[32]
Muhammad El-Hindi, Tobias Ziegler, Matthias Heinrich, Adrian Lutsch, Zheguang Zhao, and Carsten Binnig. 2022. Benchmarking the Second Gen- eration of Intel SGX Hardware. InDaMoN. ACM, 5:1–5:8
2022
-
[33]
Facebook Engineering. 2017. LogDevice: a distributed data store for logs. https://engineering.fb.com/2017/08/31/core-infra/logdevice-a-distributed- data-store-for-logs/. Accessed: 2026-01-31
2017
-
[34]
Mateusz Gienieczko, Maximilian Kuschewski, Thomas Neumann, Viktor Leis, and Jana Giceva. 2025. AnyBlox: A Framework for Self-Decoding Datasets.Proc. VLDB Endow.18, 11 (2025), 4017–4031
2025
-
[35]
Pascal Ginter and Viktor Leis. 2026. Active Data Lakes: Regaining Physical Data Independence Without Losing Interoperability.Proc. VLDB Endow(2026)
2026
-
[36]
Google. 2026. AlloyDB for PostgreSQL. https://cloud.google.com/products/ alloydb
2026
-
[37]
Gabriel Haas, Michael Haubenschild, and Viktor Leis. 2020. Exploiting Directly- Attached NVMe Arrays in DBMS. InCIDR
2020
-
[38]
Gabriel Haas, Bohyun Lee, Philippe Bonnet, and Viktor Leis. 2025. SSD-iq: Uncovering the Hidden Side of SSD Performance.Proc. VLDB Endow.18, 11 (2025), 4295–4308
2025
-
[39]
Fusheng Han, Hao Liu, Bin Chen, Debin Jia, Jianfeng Zhou, Xuwang Teng, Chuanhui Yang, Huafeng Xi, Wei Tian, Shuning Tao, Sen Wang, Quanqing Xu, and Zhenkun Yang. 2024. PALF: Replicated Write-ahead Logging for Distributed Databases.Proc. VLDB Endow.17, 12 (2024), 3745–3758
2024
-
[40]
Michael Haubenschild and Viktor Leis. 2025. Oltp in the cloud: architectures, tradeoffs, and cost.VLDB J.34, 4 (2025), 42
2025
-
[41]
Michael Haubenschild, Caetano Sauer, Thomas Neumann, and Viktor Leis. 2020. Rethinking Logging, Checkpoints, and Recovery for High-Performance Storage Engines. InSIGMOD. 877–892
2020
-
[42]
Rebecca Isaacs, Peter Alvaro, Rupak Majumdar, Kiran Kumar, Muniswamy Reddy, Mahmoud Salamati, and Sadegh Soudjani. 2025. Analyzing Metastable Failures. InHotOS. ACM, 172–178
2025
-
[43]
Matthias Jasny, Muhammad El-Hindi, Tobias Ziegler, and Carsten Binnig. 2025. A Wake-Up Call for Kernel-Bypass on Modern Hardware. InDaMoN. ACM, 14:1–14:5
2025
-
[44]
Matthias Jasny, Muhammad El-Hindi, Tobias Ziegler, Viktor Leis, and Carsten Binnig. 2025. High-Performance DBMSs with io_uring: When and How to use it.CoRRabs/2512.04859 (2025). https://doi.org/10.48550/ARXIV.2512.04859 arXiv:2512.04859
-
[45]
Zhipeng Jia and Emmett Witchel. 2021. Boki: Stateful Serverless Computing with Shared Logs. InSOSP. 691–707
2021
-
[46]
Flavio Paiva Junqueira, Ivan Kelly, and Benjamin C. Reed. 2013. Durability with BookKeeper.ACM SIGOPS Oper. Syst. Rev.47, 1 (2013), 9–15
2013
-
[47]
Donald Kossmann, Tim Kraska, and Simon Loesing. 2010. An evaluation of alternative architectures for transaction processing in the cloud. InSIGMOD. 579–590
2010
-
[48]
Jay Kreps, Neha Narkhede, and Jun Rao. 2011. Kafka: A distributed messaging system for log processing. InProceedings of the NetDB, Vol. 11. 1–7
2011
-
[49]
Maximilian Kuschewski, Jana Giceva, Thomas Neumann, and Viktor Leis. 2024. High-Performance Query Processing with NVMe Arrays: Spilling without Killing Performance.Proc. ACM Manag. Data2, 6 (2024), 238:1–238:27
2024
-
[50]
Leslie Lamport. 1998. The Part-Time Parliament.ACM Trans. Comput. Syst.16, 2 (1998), 133–169
1998
-
[51]
Bohyun Lee, Tobias Ziegler, and Viktor Leis. 2026. How to Write to SSDs. Proceedings of the VLDB Endowment19 (2026), 1469–1482
2026
-
[52]
Viktor Leis, Michael Haubenschild, Alfons Kemper, and Thomas Neumann. 2018. LeanStore: In-Memory Data Management beyond Main Memory. InICDE. 185– 196
2018
-
[53]
Feifei Li. 2019. Cloud native database systems at Alibaba: Opportunities and Challenges.Proc. VLDB Endow.12, 12 (2019), 2263–2272
2019
-
[54]
Feifei Li. 2023. Modernization of Databases in the Cloud Era: Building Databases that Run Like Legos.Proc. VLDB Endow.16, 12 (2023), 4140–4151. https://doi. org/10.14778/3611540.3611639
-
[55]
Faleiro, Juno Kim, Soham Sankaran, Daniel J
Joshua Lockerman, Jose M. Faleiro, Juno Kim, Soham Sankaran, Daniel J. Abadi, James Aspnes, Siddhartha Sen, and Mahesh Balakrishnan. 2018. The FuzzyLog: A Partially Ordered Shared Log. InOSDI. USENIX Association, 357–372
2018
-
[56]
Bhat, Jiyu Hu, Ramnatthan Alagappan, and Aishwarya Ganesan
Xuhao Luo, Shreesha G. Bhat, Jiyu Hu, Ramnatthan Alagappan, and Aishwarya Ganesan. 2024. LazyLog: A New Shared Log Abstraction for Low-Latency Appli- cations. InSOSP. 296–312
2024
-
[57]
Adrian Lutsch, Muhammad El-Hindi, Zsolt István, and Carsten Binnig. 2025. Towards High-performance and Trusted Cloud DBMSs.Datenbank-Spektrum25, 1 (2025), 39–50
2025
-
[58]
Adrian Lutsch, Christian Franck, Muhammad El-Hindi, Zsolt István, and Carsten Binnig. 2025. An Analysis of AWS Nitro Enclaves for Database Workloads. In DaMoN. ACM, 5:1–5:8
2025
-
[59]
Accessed: April 22, 2026
Mellanox. Accessed: April 22, 2026. https://github.com/Mellanox/sockperf
2026
-
[60]
Microsoft. 2024. Global data distribution with Azure Cosmos DB - under the hood. https://learn.microsoft.com/en-us/azure/cosmos-db/global-dist-under- the-hood. Accessed: 2026-01-28
2024
-
[61]
Mohan, Don Haderle, Bruce G
C. Mohan, Don Haderle, Bruce G. Lindsay, Hamid Pirahesh, and Peter M. Schwarz
-
[62]
Database Syst.17, 1 (1992), 94–162
ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging.ACM Trans. Database Syst.17, 1 (1992), 94–162
1992
-
[63]
Neon. [n.d.]. Neon architecture. https://neon.com/blog/architecture-decisions- in-neon. Accessed: 2025-12-31
2025
-
[64]
Neon. [n.d.]. Neon architecture. https://neon.com/docs/introduction/ architecture-overview. Accessed: 2025-12-31
2025
-
[65]
Lam-Duy Nguyen, Adnan Alhomssi, Tobias Ziegler, and Viktor Leis. 2025. Mov- ing on From Group Commit: Autonomous Commit Enables High Throughput and Low Latency on NVMe SSDs.Proc. ACM Manag. Data3, 3 (2025), 191:1–191:24
2025
-
[66]
Accessed: March 22, 2026
NVMe Express, Inc. Accessed: March 22, 2026. https://nvmexpress.org/ specifications
2026
-
[67]
Oki and Barbara Liskov
Brian M. Oki and Barbara Liskov. 1988. Viewstamped Replication: A General Primary Copy. InPODC. 8–17
1988
-
[68]
Ousterhout
Diego Ongaro and John K. Ousterhout. 2014. In Search of an Understandable Consensus Algorithm. InUSENIX ATC. 305–319
2014
-
[69]
Ousterhout, Arjun Gopalan, Ashish Gupta, Ankita Kejriwal, Collin Lee, Behnam Montazeri, Diego Ongaro, Seo Jin Park, Henry Qin, Mendel Rosenblum, Stephen M
John K. Ousterhout, Arjun Gopalan, Ashish Gupta, Ankita Kejriwal, Collin Lee, Behnam Montazeri, Diego Ongaro, Seo Jin Park, Henry Qin, Mendel Rosenblum, Stephen M. Rumble, Ryan Stutsman, and Stephen Yang. 2015. The RAMCloud Storage System.ACM Trans. Comput. Syst.33, 3 (2015), 7:1–7:55
2015
-
[70]
SAP. [n.d.]. Storage Configuration for SAP HANA. https://docs.aws.amazon. com/sap/latest/sap-hana/hana-ops-storage-config.html. Accessed: 2024-12-08
2024
-
[71]
Scalog Organization. 2019. Scalog Github Repository. https://github.com/scalog/ scalog
2019
-
[72]
Accessed: March 22, 2026
Simplyblock GmbH. Accessed: March 22, 2026. Simplyblock: Cloud-native stor- age in your data center. https://simplyblock.io/
2026
-
[73]
Till Steinert, Maximilian Kuschewski, and Viktor Leis. 2026. Cloudspecs: Cloud Hardware Evolution Through the Looking Glass. InCIDR
2026
-
[74]
Ghanem, Matthew Perron, Xiangyao Yu, Michael Stone- braker, David J
Junjay Tan, Thanaa M. Ghanem, Matthew Perron, Xiangyao Yu, Michael Stone- braker, David J. DeWitt, Marco Serafini, Ashraf Aboulnaga, and Tim Kraska
-
[75]
VLDB Endow
Choosing A Cloud DBMS: Architectures and Tradeoffs.Proc. VLDB Endow. 12, 12 (2019), 2170–2182
2019
-
[76]
Accessed: March 22, 2026
The Linux Foundation. Accessed: March 22, 2026. DAOS: The Open-Source Storage Platform for AI & HPC. https://daos.io/
2026
-
[77]
Raúl Gracia Tinedo, Flavio Junqueira, Tom Kaitchuck, and Sachin Joshi. 2023. Pravega: A Tiered Storage System for Data Streams. InProceedings of the 24th International Middleware Conference, Middleware 2023, Bologna, Italy, December 11-15, 2023. 165–177
2023
-
[78]
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. InSIGMOD. 1041–1052
2017
-
[79]
Tianzheng Wang, Ryan Johnson, and Ippokratis Pandis. 2017. Query Fresh: Log Shipping on Steroids.Proc. VLDB Endow.11, 4 (2017), 406–419
2017
-
[80]
Yu Xia, Xiangyao Yu, Andrew Pavlo, and Srinivas Devadas. 2020. Taurus: Light- weight Parallel Logging for In-Memory Database Management Systems.Proc. VLDB Endow.14, 2 (2020), 189–201
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.