Scalable Network-Aware Experiment Design for Two-Sided Marketplaces
Pith reviewed 2026-06-27 14:55 UTC · model grok-4.3
The pith
Iterative ego clustering cuts spillover threefold in two-sided marketplace experiments while doubling test power.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
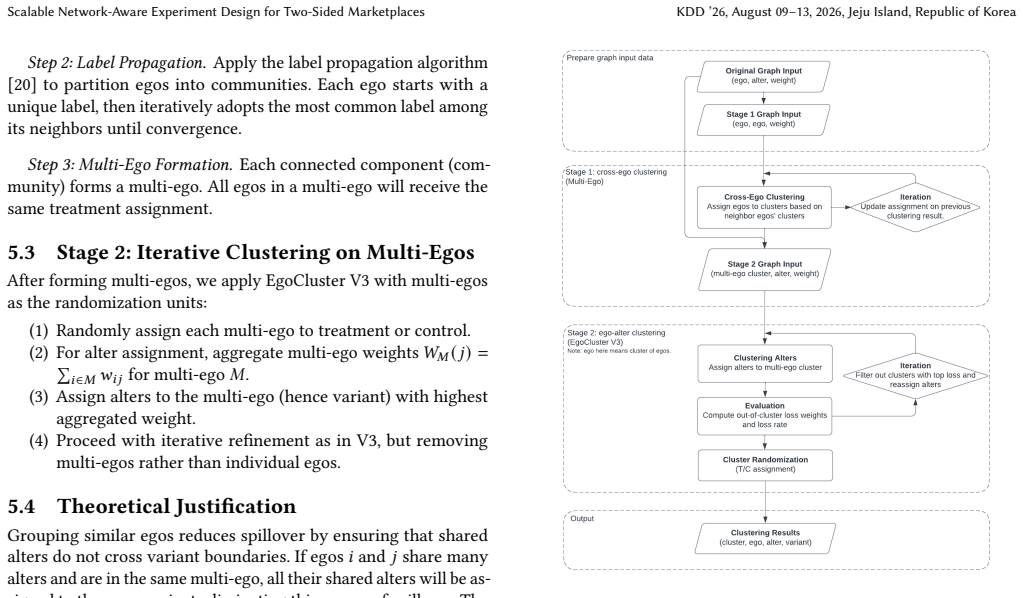
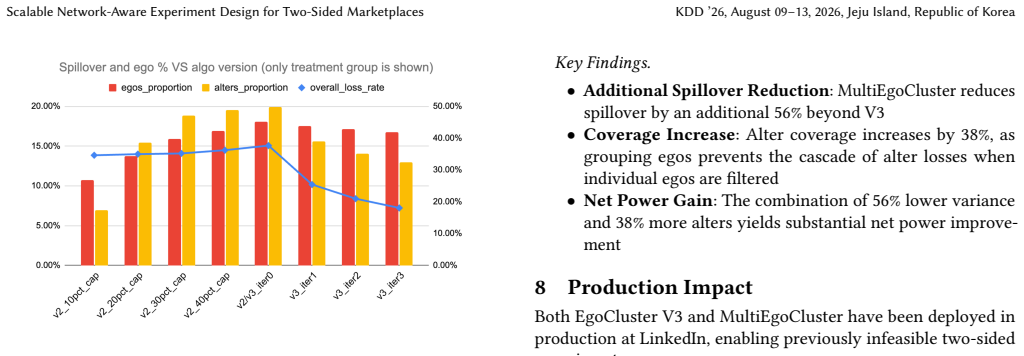
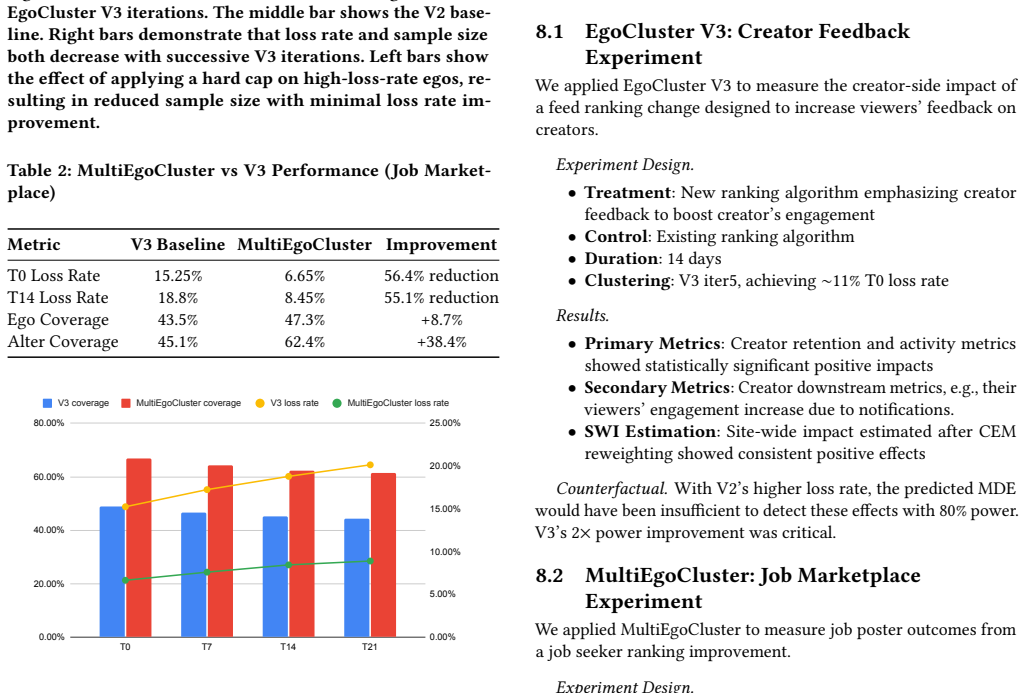
EgoCluster V3 is an iterative clustering algorithm that reduces spillover by a factor of three relative to earlier versions while preserving node coverage and doubling test power; MultiEgoCluster extends this via a two-stage multi-ego grouping procedure to obtain a further 56 percent spillover reduction and 38 percent sample-size increase; a theoretical bias-correction formula based on the observed graph structure then removes residual interference bias from the ATE estimator.
What carries the argument
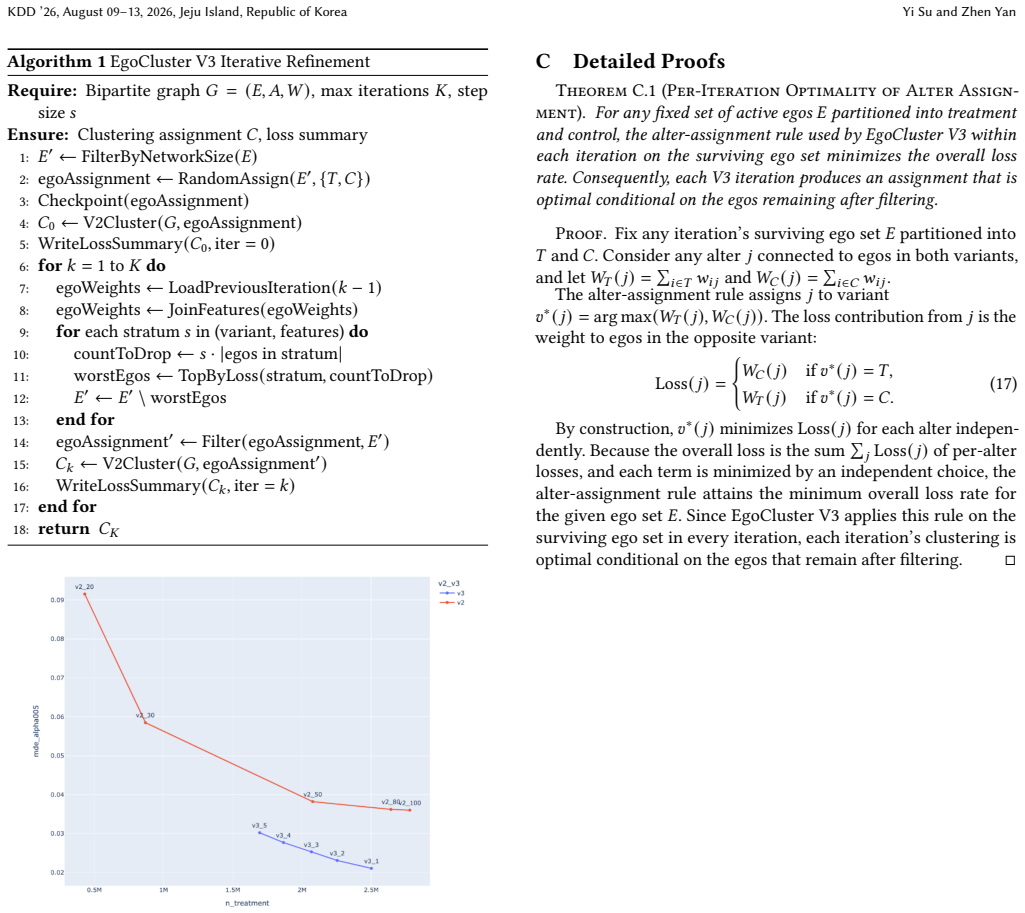
EgoCluster V3, an iterative clustering procedure that repeatedly refines ego-centered clusters to isolate cross-side interactions.
If this is right
- Marketplace experiments can maintain higher statistical power at any given level of allowable interference.
- One-sided treatments can be tested with reduced contamination of the opposite side.
- The bias-correction step allows extrapolation of results from the clustered sample to the full population.
- Production systems can run more frequent, smaller, or more precise tests without violating interference assumptions.
Where Pith is reading between the lines
- The same iterative clustering logic could be tested on time-varying graphs where edges appear and disappear during the experiment window.
- If the bias correction proves accurate, the method may reduce the minimum cluster size required in other interference settings such as social or recommendation networks.
- The two-stage multi-ego grouping could be combined with stratification on node attributes to further improve balance across treatment arms.
Load-bearing premise
The underlying network must permit iterative ego clustering to isolate spillover without losing too many qualifying clusters or introducing new selection biases, and the graph-based correction must fully capture any remaining interference.
What would settle it
A controlled deployment or simulation in which direct measurement of cross-side interactions shows no reduction in spillover after applying EgoCluster V3 or MultiEgoCluster, or in which the bias-corrected ATE differs from the known true effect.
Figures
read the original abstract
Measuring causal effects in networked two-sided marketplaces is challenging due to treatment interference between market participants on different sides. When treatment is applied to one side (e.g., job seekers), their interactions with the other side (e.g., job posters) introduce spillover effects that violate the Stable Unit Treatment Value Assumption (SUTVA) and bias causal estimates. While cluster-based randomization mitigates this problem, prior approaches struggle with a fundamental trade-off: reducing spillover requires isolated clusters that will reduce the number of qualifying clusters, which decreases statistical power. This paper introduces EgoCluster V3, an iterative clustering algorithm that reduces spillover by 3x compared to prior versions while preserving node coverage and doubling test power. We further introduce MultiEgoCluster, which extends V3 through a two-stage procedure that first groups highly connected egos into multi-ego clusters before applying the iterative clustering algorithm. This achieves an additional ~56% spillover reduction and ~38% increase in sample size. Both methods are deployed in production at LinkedIn and have systematically enabled high-impact two-sided marketplace experiments. Since residual bias cannot be fully eliminated through clustering alone, we derive a theoretical bias correction method for average treatment effect (ATE) estimation based on graph structure and propose an approach to generalize results to the general population.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that EgoCluster V3, an iterative clustering algorithm on ego graphs, reduces spillover by 3x relative to prior versions while preserving node coverage and doubling test power in two-sided marketplace experiments. MultiEgoCluster extends this via a two-stage multi-ego grouping procedure, yielding an additional ~56% spillover reduction and ~38% sample-size increase. Both algorithms are deployed in production at LinkedIn. The paper further derives a graph-structure-based theoretical bias correction for ATE estimation to address residual interference and proposes a method to generalize results to the broader population.
Significance. If the empirical performance claims and the bias-correction derivation hold under the stated graph assumptions, the work would be significant for causal inference in networked two-sided markets: it directly tackles SUTVA violations via scalable clustering that trades off spillover against power, and the production deployment supplies real-world evidence of utility. The attempt to supply a graph-based correction is a positive step toward generalizability. The manuscript receives credit for the LinkedIn deployment demonstrating practical impact.
major comments (2)
- [Abstract / bias-correction section] Abstract and bias-correction section: the central claim that a 'theoretical bias correction method for ATE estimation based on graph structure' enables generalization to the general population is load-bearing, yet the manuscript supplies no equations, derivation steps, or proof sketch showing whether the correction is independent of quantities fitted from the same experimental data or reduces to a data-dependent adjustment.
- [EgoCluster V3 / MultiEgoCluster sections] EgoCluster V3 and MultiEgoCluster sections: the headline claims (3× spillover reduction, doubled power, +38% sample size, preservation of node coverage) presuppose that the underlying bipartite graph admits iterative clustering whose output clusters remain sufficiently isolated yet numerous; no analysis of graph properties (degree distribution, density, cross-side bridges) or sensitivity checks is provided to establish that these conditions hold beyond the specific LinkedIn deployment.
minor comments (1)
- [Abstract] Abstract: numerical claims (3×, ~56%, ~38%, doubled power) are stated without reference to the specific baseline methods, tables, or figures that support them.
Simulated Author's Rebuttal
We are grateful for the referee's positive evaluation of the significance and practical impact of our work on network-aware experiment design in two-sided marketplaces. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract / bias-correction section] Abstract and bias-correction section: the central claim that a 'theoretical bias correction method for ATE estimation based on graph structure' enables generalization to the general population is load-bearing, yet the manuscript supplies no equations, derivation steps, or proof sketch showing whether the correction is independent of quantities fitted from the same experimental data or reduces to a data-dependent adjustment.
Authors: We agree that the bias-correction section would benefit from greater mathematical detail. The manuscript derives the correction from the observed graph structure to address residual interference after clustering, but we will expand it in revision to include the explicit equations, derivation steps, and clarification that the adjustment depends only on graph properties rather than quantities estimated from the experimental outcomes. revision: yes
-
Referee: [EgoCluster V3 / MultiEgoCluster sections] EgoCluster V3 and MultiEgoCluster sections: the headline claims (3× spillover reduction, doubled power, +38% sample size, preservation of node coverage) presuppose that the underlying bipartite graph admits iterative clustering whose output clusters remain sufficiently isolated yet numerous; no analysis of graph properties (degree distribution, density, cross-side bridges) or sensitivity checks is provided to establish that these conditions hold beyond the specific LinkedIn deployment.
Authors: The reported performance metrics are empirical results obtained on LinkedIn's production bipartite graph, where the algorithms were deployed at scale. The clustering procedures are constructed around ego-graph isolation properties that are characteristic of two-sided marketplace networks. We will add a discussion of the relevant graph properties (degree distribution, density, and cross-side connectivity) observed in the LinkedIn data and the conditions under which the iterative procedure preserves isolation and coverage. revision: partial
Circularity Check
No significant circularity; derivation remains independent of inputs.
full rationale
The abstract and provided text describe EgoCluster V3 as an iterative clustering algorithm, MultiEgoCluster as a two-stage extension, and a 'theoretical bias correction method for ATE estimation based on graph structure.' No equations, self-citations, or fitted parameters are quoted that reduce any claimed prediction or derivation to its own inputs by construction. The bias correction is presented as derived from graph structure rather than fitted from experimental data, and empirical results are tied to LinkedIn deployment (external). The derivation chain is self-contained against the stated assumptions; no load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aronow and Cyrus Samii
Peter M. Aronow and Cyrus Samii. 2017. Estimating average causal effects under general interference.Annals of Applied Statistics11, 4 (2017), 1912–1947
2017
-
[2]
Eytan Bakshy, Dean Eckles, Rong Yan, and Itamar Rosenn. 2012. Social influence in social advertising: Evidence from field experiments. InProceedings of the 13th ACM Conference on Electronic Commerce. ACM, 146–161
2012
-
[3]
George E. P. Box, William G. Hunter, and J. Stuart Hunter. 2005.Statistics for Experimenters: Design, Innovation, and Discovery(second ed.). John Wiley & Sons
2005
-
[4]
Alex Chin. 2019. Regression adjustments for estimating the global treatment effect in experiments with interference.Journal of Causal Inference7, 2 (2019). doi:10.1515/jci-2018-0026
-
[5]
Alex Deng, Ya Xu, Ronny Kohavi, and Toby Walker. 2013. Improving the sen- sitivity of online controlled experiments by utilizing pre-experiment data. In Proceedings of the 6th ACM International Conference on Web Search and Data Mining. ACM, 123–132
2013
-
[6]
Dean Eckles, Brian Karrer, and Johan Ugander. 2017. Design and Analysis of Experiments in Networks: Reducing Bias from Interference.Journal of Causal Inference5, 1 (2017)
2017
-
[7]
Alessandro Epasto, Silvio Lattanzi, and Renato Paes Leme. 2017. Ego-splitting Framework: from Non-Overlapping to Overlapping Clusters. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 145–154. doi:10.1145/3097983.3098054
-
[8]
Ronald A. Fisher. 1935.The Design of Experiments. Oliver and Boyd, Edinburgh
1935
-
[9]
Airoldi, and Fabrizia Mealli
Laura Forastiere, Edoardo M. Airoldi, and Fabrizia Mealli. 2021. Identification and Estimation of Treatment and Interference Effects in Observational Studies on Networks.J. Amer. Statist. Assoc.116, 534 (2021), 901–918
2021
-
[10]
Henning Hohnhold, Deirdre O’Brien, and Diane Tang. 2015. Focusing on the long- term: It’s good for users and business. InProceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1849– 1858
2015
-
[11]
Paul W. Holland. 1986. Statistics and Causal Inference.J. Amer. Statist. Assoc.81, 396 (1986), 945–960
1986
-
[12]
David Holtz, Ruben Lobel, Inessa Liskovich, and Sinan Aral. 2024. Reducing Interference Bias in Online Marketplace Pricing Experiments.Management Science(2024). SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id= 3583295
2024
-
[13]
Imbens and Donald B
Guido W. Imbens and Donald B. Rubin. 2015.Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press
2015
-
[14]
Ramesh Johari, Hannah Li, Inessa Liskovich, and Gabriel Y. Weintraub. 2022. Experimental Design in Two-Sided Platforms: An Analysis of Bias.Management Science(2022). doi:10.1287/mnsc.2022.4247
-
[15]
Brian Karrer, Liang Shi, Monica Bhole, Matt Goldman, Tyrone Palmer, Charlie Gelman, Mikael Konutgan, and Feng Sun. 2021. Network Experimentation at Scale. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 3106–3116. doi:10.1145/3447548.3467091
-
[16]
Ronny Kohavi, Alex Deng, Roger Longbotham, and Ya Xu. 2014. Seven Rules of Thumb for Web Site Experimenters. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’14). ACM, 1857–1866. doi:10.1145/2623330.2623341
-
[17]
Ronny Kohavi and Roger Longbotham. 2017. Online Controlled Experiments and A/B Tests. InEncyclopedia of Machine Learning and Data Mining. Springer, 922–929
2017
-
[18]
Ronny Kohavi, Roger Longbotham, Dan Sommerfield, and Randal M. Henne
-
[19]
Controlled experiments on the Web: survey and practical guide.Data Mining and Knowledge Discovery18, 1 (2009), 140–181
2009
-
[20]
Charles F. Manski. 1993. Identification of endogenous social effects: The reflection problem.Review of Economic Studies60, 3 (1993), 531–542
1993
-
[21]
Usha Nair Raghavan, Réka Albert, and Soundar Kumara. 2007. Near linear time algorithm to detect community structures in large-scale networks.Physical Review E76, 3 (2007), 036106
2007
-
[22]
Donald B. Rubin. 1974. Estimating causal effects of treatments in randomized and nonrandomized studies.Journal of Educational Psychology66, 5 (1974), 688–701
1974
-
[23]
Guillaume Saint-Jacques, Maneesh Varshney, Jeremy Simpson, and Ya Xu. 2019. Using Ego-Clusters to Measure Network Effects at LinkedIn.arXiv preprint arXiv:1903.08755(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Martin Saveski, Jean Pouget-Abadie, Guillaume Saint-Jacques, Weitao Duan, Souvik Ghosh, Ya Xu, and Edoardo M. Airoldi. 2017. Detecting Network Effects: Randomizing over Randomized Experiments. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1027–1035
2017
-
[25]
Wentao Su and Weitao Duan. 2024. Improving Ego-Cluster for Network Effect Measurement. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 5713–5722. doi:10.1145/3637528.3671557
-
[26]
Tamhane and Dorothy D
Ajit C. Tamhane and Dorothy D. Dunlop. 2000.Statistics and Data Analysis: From Elementary to Intermediate. Prentice Hall
2000
-
[27]
Diane Tang, Ashish Agarwal, Deirdre O’Brien, and Mike Meyer. 2010. Overlap- ping experiment infrastructure: More, better, faster experimentation. InProceed- ings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 17–26
2010
-
[28]
Kleinberg
Johan Ugander, Brian Karrer, Lars Backstrom, and Jon M. Kleinberg. 2013. Graph cluster randomization: Network exposure to multiple universes. InProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 329–337
2013
-
[29]
Ya Xu, Nanyu Chen, Addrian Fernandez, Omar Sinno, and Anmol Bhasin. 2015. From Infrastructure to Culture: A/B Testing Challenges in Large Scale Social Networks. InProceedings of the 21st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2227–2236. A Algorithm Pseudocode See Algorithm 1 for the pseudocode for EgoCluster V3. B Power Analysi...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.