Understanding LLM Intervention Explanations in Multi-Party Human-Robot Interaction
Pith reviewed 2026-06-30 07:16 UTC · model grok-4.3
The pith
LLM orchestrators in multi-party robot interactions explain interventions by prioritizing group agreement, participation, and flow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The LLM orchestrator generates intervention explanations that are facilitation-oriented, centering on agreement, participation, and interaction flow. Patterns stay stable across homogeneous and heterogeneous robot-role conditions, yet clear role differentiation appears: the mover robot supports coordination while the opposer robot advances goal-oriented interventions.
What carries the argument
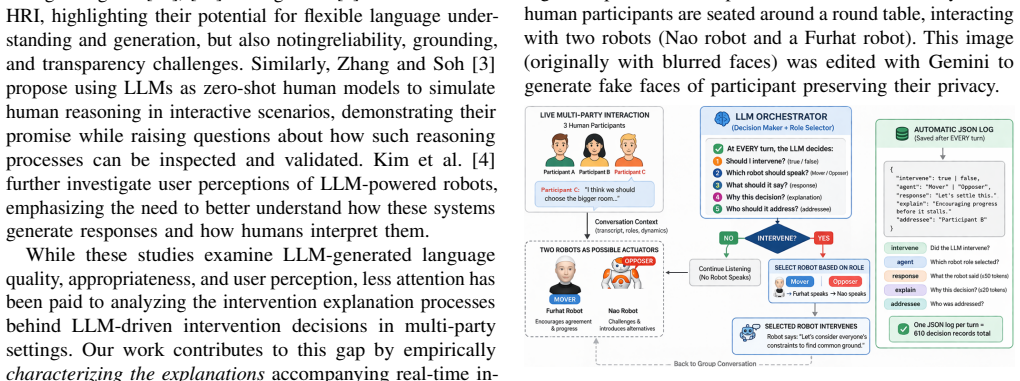
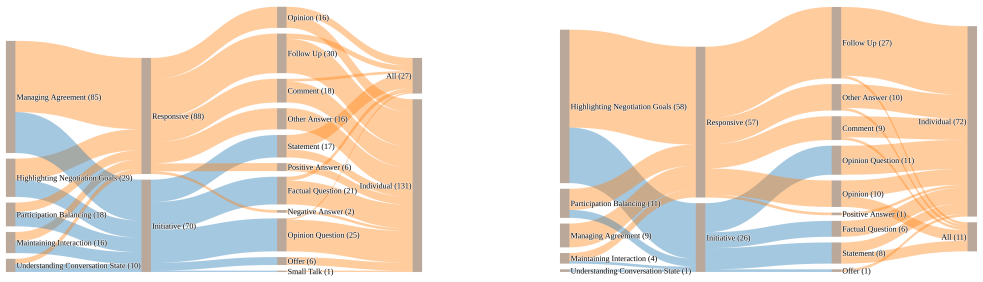
Thematic analysis of the 610 generated intervention explanations that extracts five recurring themes.
If this is right
- LLM-driven robots can be expected to produce consistent, group-focused justifications for speaking up regardless of whether their roles match or differ.
- Role assignment influences the specific aim of each intervention while leaving the overall explanatory style unchanged.
- Designers can anticipate that explanations will emphasize coordination and flow more than individual task completion.
- The approach supplies a concrete method for making real-time LLM decisions legible to human participants in group settings.
Where Pith is reading between the lines
- The same facilitation bias might appear in LLM systems used for other multi-agent coordination tasks such as meeting facilitation software.
- Making these themes explicit could let developers tune an LLM to produce more goal-directed explanations when needed.
- Testing whether participants change their behavior after seeing these explanations would reveal whether the explanations actually affect group dynamics.
Load-bearing premise
The themes identified in the explanations accurately reflect the LLM's underlying reasons for deciding to intervene.
What would settle it
Re-running the thematic analysis on the same 610 texts or inspecting the LLM's internal state directly and obtaining different or inconsistent themes would undermine the claim that the explanations reliably show facilitation-oriented decision logic.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly embedded in social robots to support natural group interactions, yet their role in complex multi-party settings remains underexplored. In particular, it is unclear how LLM-driven robots decide when and why to intervene in group conversations. This paper investigates the intervention explanations generated by an LLM-based orchestrator in a multi-party interaction involving three human participants and two robots. We conducted a between-subjects study with 24 groups (66 university students), comparing a homogeneous condition (two robots with the same role, i.e., a mover) and a heterogeneous condition (two robots with different roles, i.e., a mover and an opposer). At each conversational turn, the LLM orchestrator decided whether to intervene and generated a textual explanation of its decision. We performed a thematic analysis of 610 intervention explanations, identifying five recurring themes. Results show that explanations are facilitation-oriented, emphasizing agreement, participation, and interaction flow. While patterns remain stable across conditions, role differentiation emerges: the mover supports coordination, whereas the opposer drives goal-oriented interventions. These findings contribute to explainable AI by characterizing how LLM-driven systems justify intervention decisions in real-time, multi-party human-robot interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper investigates how an LLM-based orchestrator generates explanations for intervention decisions in multi-party human-robot interactions. Through a between-subjects study with 24 groups comparing homogeneous (two movers) and heterogeneous (mover and opposer) conditions, the authors analyze 610 intervention explanations via thematic analysis, identifying five recurring themes. The results indicate that explanations are primarily facilitation-oriented, focusing on agreement, participation, and interaction flow, with stable patterns across conditions but emerging role differentiation where the mover aids coordination and the opposer focuses on goal-oriented interventions.
Significance. If the reported thematic analysis holds up under scrutiny for reliability and validity, the findings would meaningfully advance understanding of LLM behavior in social robotics, particularly in explainable AI for group interactions. The empirical approach with a sizable number of explanations from actual participant groups provides a solid foundation for characterizing intervention rationales.
major comments (2)
- [Methods / Abstract] The description of the thematic analysis (mentioned in the abstract and presumably detailed in the Methods section) supplies no information on the coding process, inter-rater reliability (e.g., Cohen's kappa), number of coders, blinding to condition, inductive vs. deductive approach, or validation that themes reflect actual decision triggers rather than phrasing artifacts. This is load-bearing for the central claim, as the extraction of five themes and the reported role differentiation (mover for coordination, opposer for goal-oriented interventions) depend entirely on the reproducibility and lack of bias in this analysis.
- [Results / Abstract] The assertion that 'patterns remain stable across conditions' (Abstract) is presented without any quantitative support such as theme frequency counts, distribution tables, or statistical comparisons between the homogeneous and heterogeneous conditions, leaving the stability claim and its implications for role differentiation difficult to evaluate.
minor comments (2)
- [Abstract] The abstract states that five recurring themes were identified but does not name or briefly characterize them, which would immediately clarify the facilitation-oriented emphasis for readers.
- [Methods] Additional details on interaction duration, exact number of turns per group, or how the 610 explanations were sampled from the total conversational turns would aid interpretation of the dataset size.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below and will revise the manuscript to strengthen the description of the thematic analysis and provide quantitative support for the stability claims.
read point-by-point responses
-
Referee: [Methods / Abstract] The description of the thematic analysis (mentioned in the abstract and presumably detailed in the Methods section) supplies no information on the coding process, inter-rater reliability (e.g., Cohen's kappa), number of coders, blinding to condition, inductive vs. deductive approach, or validation that themes reflect actual decision triggers rather than phrasing artifacts. This is load-bearing for the central claim, as the extraction of five themes and the reported role differentiation (mover for coordination, opposer for goal-oriented interventions) depend entirely on the reproducibility and lack of bias in this analysis.
Authors: We agree that the current description of the thematic analysis is insufficient for assessing reliability and validity. In the revised manuscript we will expand the Methods section to specify: two independent coders performed the analysis; an inductive approach was used with iterative codebook development; Cohen's kappa was calculated for inter-rater reliability; coders were blinded to experimental condition; and themes were validated by cross-referencing a subset of explanations against the LLM's actual decision triggers and raw conversation logs. These additions will directly address concerns about reproducibility and potential bias. revision: yes
-
Referee: [Results / Abstract] The assertion that 'patterns remain stable across conditions' (Abstract) is presented without any quantitative support such as theme frequency counts, distribution tables, or statistical comparisons between the homogeneous and heterogeneous conditions, leaving the stability claim and its implications for role differentiation difficult to evaluate.
Authors: We acknowledge that the stability claim requires quantitative backing to be fully evaluable. In the revised Results section and a new supplementary table we will report per-theme frequency counts (absolute and relative) for each condition, a side-by-side distribution table, and appropriate statistical comparisons (e.g., chi-square tests) between the homogeneous and heterogeneous conditions. The abstract will be updated to reference these supporting data. revision: yes
Circularity Check
No circularity: purely empirical thematic analysis with no derivations or fitted predictions
full rationale
The paper reports results from a between-subjects study with thematic analysis of 610 LLM-generated intervention explanations, identifying five themes and describing facilitation-oriented patterns with role differentiation. No equations, model derivations, parameter fitting, predictions, or self-citation chains appear in the abstract or described methods. The central claims rest on direct observation and inductive coding of collected data rather than any reduction to inputs by construction. This is a standard empirical report whose validity depends on coding reliability (unaddressed here) but exhibits zero circularity in its derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Thematic analysis is a reliable method for surfacing recurring themes in textual intervention explanations
Reference graph
Works this paper leans on
-
[1]
Appropriateness of llm-equipped robotic well-being coach language in the workplace: A qualitative evaluation,
M. Spitale, M. Axelsson, and H. Gunes, “Appropriateness of llm-equipped robotic well-being coach language in the workplace: A qualitative evaluation,” in2024 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN). IEEE, 2024, pp. 1571–1578
2024
-
[2]
Large language models for human– robot interaction: A review,
C. Zhang, J. Chen, J. Li, Y . Peng, and Z. Mao, “Large language models for human– robot interaction: A review,”Biomimetic Intelligence and Robotics, vol. 3, no. 4, 2023
2023
-
[3]
Large language models as zero-shot human models for human-robot interaction,
B. Zhang and H. Soh, “Large language models as zero-shot human models for human-robot interaction,” in2023 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2023, pp. 7961–7968
2023
-
[4]
Understanding large-language model (llm)-powered human-robot interaction,
C. Y . Kim, C. P. Lee, and B. Mutlu, “Understanding large-language model (llm)-powered human-robot interaction,” inProceedings of the 2024 ACM/IEEE international conference on human-robot interaction, 2024, pp. 371–380
2024
-
[5]
Past, present, and future: A survey of the evolution of affective robotics for well-being,
M. Spitale, M. Axelsson, S. Jeong, P. Tutt¨os´ı, C. A. Stamatis, G. Laban, A. Lim, and H. Gunes, “Past, present, and future: A survey of the evolution of affective robotics for well-being,”IEEE Transactions on Affective Computing, 2025
2025
-
[6]
Vita: a multi-modal llm-based system for longitudinal, autonomous and adaptive robotic mental well-being coaching,
M. Spitale, M. Axelsson, and H. Gunes, “Vita: a multi-modal llm-based system for longitudinal, autonomous and adaptive robotic mental well-being coaching,”ACM Transactions on Human-Robot Interaction, vol. 14, no. 2, pp. 1–28, 2025
2025
-
[7]
Designing social robots with llms for engaging human interaction,
M. Pinto-Bernal, M. Biondina, and T. Belpaeme, “Designing social robots with llms for engaging human interaction,”Applied Sciences, vol. 15, no. 11, p. 6377, 2025
2025
-
[8]
Robots in groups and teams: a literature review,
S. Sebo, B. Stoll, B. Scassellati, and M. F. Jung, “Robots in groups and teams: a literature review,”Proceedings of the ACM on Human-Computer Interaction, vol. 4, no. CSCW2, pp. 1–36, 2020
2020
-
[9]
Social group human-robot interaction: A scoping review of computational challenges,
M. Nigro, E. Akinrintoyo, N. Salomons, and M. Spitale, “Social group human-robot interaction: A scoping review of computational challenges,” in2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 2025
2025
-
[10]
A survey and analysis of multi-robot coordination,
Z. Yan, N. Jouandeau, and A. A. Cherif, “A survey and analysis of multi-robot coordination,”International Journal of Advanced Robotic Systems, vol. 10, no. 12, p. 399, 2013
2013
-
[11]
Decision making as optimization in multi-robot teams,
L. E. Parker, “Decision making as optimization in multi-robot teams,” inInterna- tional Conference on Distributed Computing and Internet Technology. Springer, 2012, pp. 35–49
2012
-
[12]
Exploring mechanistic interpretability in large language models: Challenges, approaches, and insights,
S. R. Gantla, “Exploring mechanistic interpretability in large language models: Challenges, approaches, and insights,” inInternational Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI). IEEE, 2025
2025
-
[13]
Fast multi-party open-ended conversation with a social robot,
G. A. Abbo, M. J. Pinto-Bernal, M. Catrycke, and T. Belpaeme, “Fast multi-party open-ended conversation with a social robot,”arXiv preprint arXiv:2503.15496, 2025
-
[14]
Explainability for large language models: A survey,
H. Zhao, H. Chen, F. Yang, N. Liu, H. Deng, H. Cai, S. Wang, D. Yin, and M. Du, “Explainability for large language models: A survey,”ACM Transactions on Intelligent Systems and Technology, vol. 15, no. 2, pp. 1–38, 2024
2024
-
[15]
An llm benchmark for addressee recognition in multi-modal multi-party dialogue,
K. Inoue, D. Lala, M. Elmers, K. Ochi, and T. Kawahara, “An llm benchmark for addressee recognition in multi-modal multi-party dialogue,” inProceedings of the 15th International Workshop on Spoken Dialogue Systems Technology, 2025
2025
-
[16]
Do llms suffer from multi-party hangover? a diagnostic approach to addressee recognition and response selection in conversations,
N. Penzo, M. Sajedinia, B. Lepri, S. Tonelli, and M. Guerini, “Do llms suffer from multi-party hangover? a diagnostic approach to addressee recognition and response selection in conversations,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[17]
Agentic llm-based robotic systems for real-world applications: a review on their agenticness and ethics,
E. K. Raptis, A. C. Kapoutsis, and E. B. Kosmatopoulos, “Agentic llm-based robotic systems for real-world applications: a review on their agenticness and ethics,”Frontiers in Robotics and AI, vol. 12, p. 1605405, 2025
2025
-
[18]
Assessing the alignment of large language models with human values for mental health integration: cross-sectional study using schwartz’s theory of basic values,
D. Hadar-Shoval, K. Asraf, Y . Mizrachi, Y . Haber, and Z. Elyoseph, “Assessing the alignment of large language models with human values for mental health integration: cross-sectional study using schwartz’s theory of basic values,”JMIR Mental Health, vol. 11, p. e55988, 2024
2024
-
[19]
A multi-party conversational social robot using llms,
A. Addlesee, N. Cherakara, N. Nelson, D. Hern ´andez Garc ´ıa, N. Gunson, W. Siei´nska, M. Romeo, C. Dondrup, and O. Lemon, “A multi-party conversational social robot using llms,” inCompanion of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, 2024
2024
-
[20]
Thematic analysis,
V . Clarke and V . Braun, “Thematic analysis,”The journal of positive psychology, vol. 12, no. 3, pp. 297–298, 2017
2017
-
[21]
A framework for dialogue act specification,
H. Bunt, “A framework for dialogue act specification,”Proceedings of SIGSEM WG on Representation of Multimodal Semantic Information, 2005
2005
-
[22]
Midas: A dialog act annotation scheme for open domain humanmachine spoken conversations,
D. Yu and Z. Yu, “Midas: A dialog act annotation scheme for open domain humanmachine spoken conversations,” inProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021
2021
-
[23]
Coding dialogs with the damsl annotation scheme,
M. G. Core and J. Allen, “Coding dialogs with the damsl annotation scheme,” in AAAI fall symposium on communicative action in humans and machines. Boston, MA, 1997
1997
-
[24]
Learning gaze behaviors for balancing participation in group human-robot interactions,
S. Gillet, M. T. Parreira, M. V´azquez, and I. Leite, “Learning gaze behaviors for balancing participation in group human-robot interactions,” in2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 2022
2022
-
[25]
Ali-agent: Assessing llms’ alignment with human values via agent-based evaluation,
H. Wang, A. Zhang, N. Duy Tai, J. Sun, T.-S. Chuaet al., “Ali-agent: Assessing llms’ alignment with human values via agent-based evaluation,”Advances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[26]
R. Dass, T. Bowlin, Z. Li, X. Jin, and A. Goel, “Improving procedural skill explanations via constrained generation: A symbolic-llm hybrid architecture,”arXiv preprint arXiv:2511.20942, 2025
-
[27]
R. Sharma and M. Mehta, “Adaptive and explainable ai agents for anomaly detection in critical iot infrastructure using llm-enhanced contextual reasoning,”arXiv preprint arXiv:2510.03859, 2025
-
[28]
Dexter-llm: Dynamic and explainable coordination of multi-robot systems in unknown environments via large language models,
Y . Zhu, J. Chen, X. Zhang, M. Guo, and Z. Li, “Dexter-llm: Dynamic and explainable coordination of multi-robot systems in unknown environments via large language models,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 10 182–10 189
2025
-
[29]
Vulnerable robots positively shape human conversational dynamics in a human– robot team,
M. L. Traeger, S. Strohkorb Sebo, M. Jung, B. Scassellati, and N. A. Christakis, “Vulnerable robots positively shape human conversational dynamics in a human– robot team,”Proceedings of the National Academy of Sciences, vol. 117, no. 12, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.