From Bootstrapping to Sequence Modeling: A Unified Generative Framework for Personalized Landing-Page Modeling
Pith reviewed 2026-06-29 02:53 UTC · model grok-4.3
The pith
A Decision Transformer sequence model with global-local modules replaces CQL reinforcement learning for personalized landing page assignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
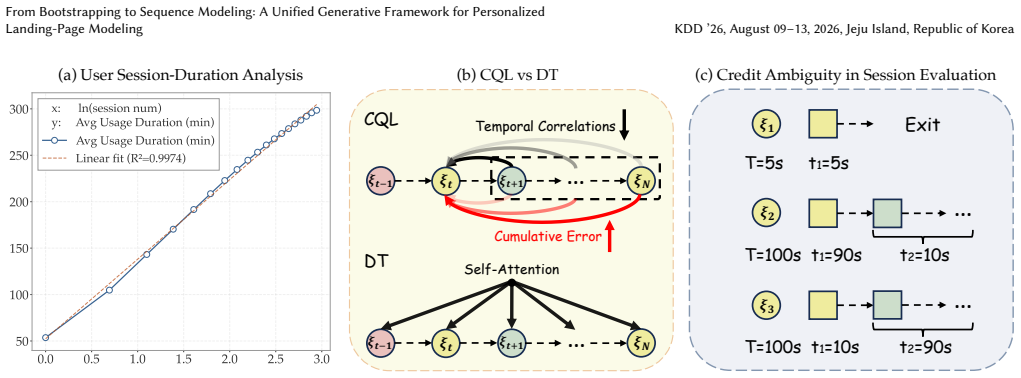
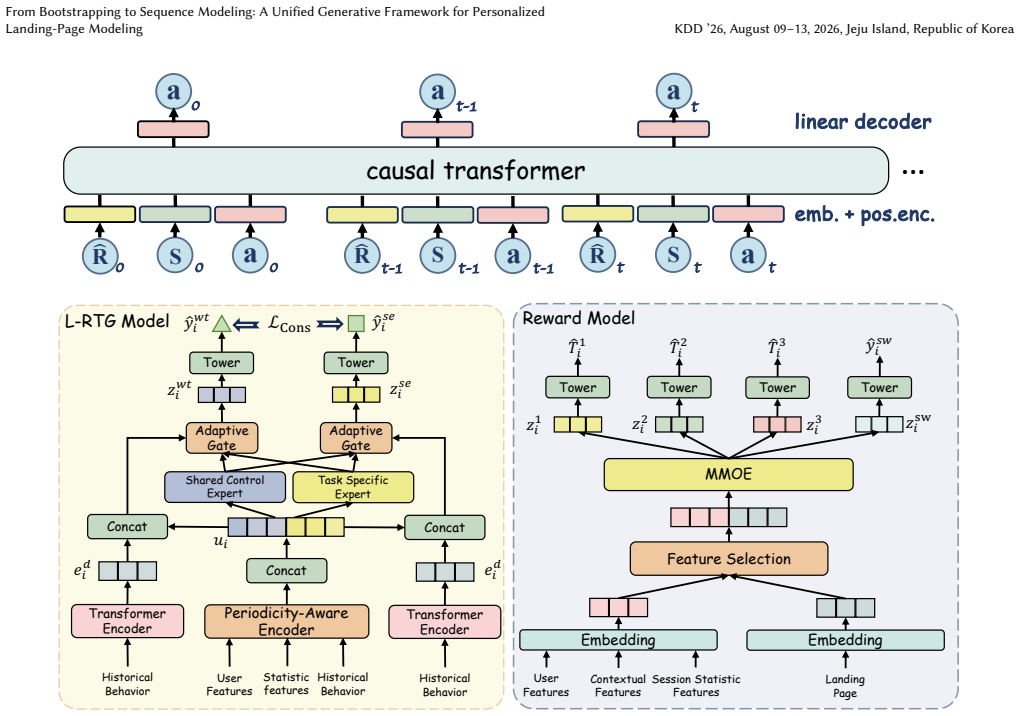
GLAN is a generative sequence modeling framework built on Decision Transformer that addresses the Markov assumption failure and TD learning cumulative errors of CQL-based KLAN by incorporating the L-RTG module to capture users' inter-day consumption dynamics for global guidance across all page assignments within a day and the HRM module to decompose session-level feedback into fine-grained signals for precise local supervision of each page assignment.
What carries the argument
L-RTG and HRM modules inside a Decision Transformer that jointly supply global inter-day guidance and local session-level supervision for page assignment decisions.
If this is right
- Non-Markovian temporal dependencies across days are handled directly rather than approximated by state augmentation.
- Credit assignment for delayed rewards improves because the model conditions on full trajectories instead of bootstrapped value estimates.
- Global guidance from inter-day patterns and local supervision from session decomposition can be applied together in one architecture.
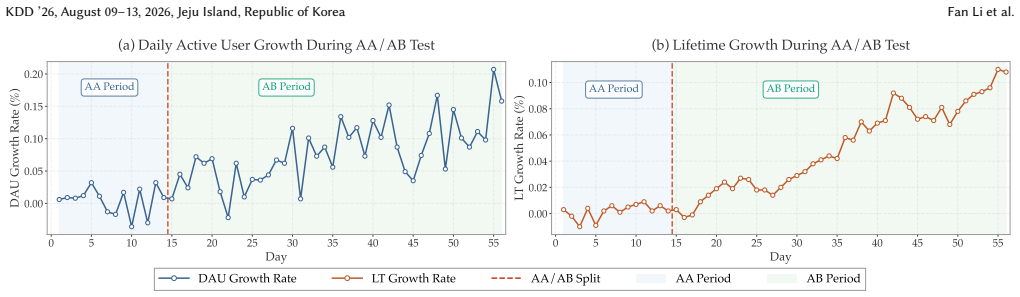
- Production deployment yields measurable lifts of 0.158 percent in DAU and 0.108 percent in LT.
Where Pith is reading between the lines
- The same global-local decomposition could be tested on other long-horizon recommendation tasks that currently rely on bootstrapped RL.
- If the modules prove separable, one could measure whether inter-day or intra-session signals contribute more to the observed gains.
- Platforms with similar entry patterns but different reward delays could adopt the architecture without re-deriving a new RL objective.
Load-bearing premise
The L-RTG module accurately captures inter-day consumption dynamics and the HRM module successfully decomposes session-level feedback into fine-grained signals that provide reliable global and local supervision.
What would settle it
An online A/B test in which GLAN produces no increase or a decrease in DAU and LT relative to the prior CQL method would falsify the claim that the sequence modeling approach improves outcomes.
Figures


read the original abstract
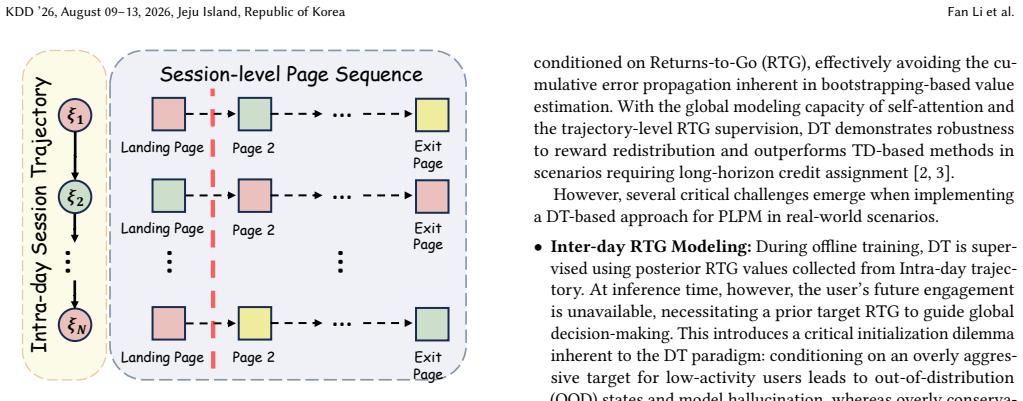
Modern online platforms increasingly adopt multi-page architectures to accommodate diverse user needs. On these platforms, page navigation (the process of directing users to specific functional pages upon app entry) serves as a critical gateway that shapes user's first impression and significantly influences subsequent engagement. To optimize this process, Kuaishou formulated the task of Personalized Landing Page Modeling (PLPM) and proposed KLAN, a reinforcement learning framework built upon Conservative Q-Learning (CQL). However, CQL-based approaches suffer from two fundamental limitations: (1) the Markov assumption fails to capture the strong non-Markovian temporal dependencies inherent in real-world user behaviors, and (2) TD learning with bootstrapping incurs severe cumulative errors and credit assignment difficulties under delayed rewards, particularly in long-horizon settings where users enter the app multiple times daily. To address these limitations, we propose GLAN (Generative Landing-page Adaptive Navigator), a sequence modeling framework built on Decision Transformer to tackle PLPM from a unified global-local perspective. Specifically, GLAN incorporates two key modules. First, we design the L-RTG module that captures users' inter-day consumption dynamics to provide accurate global guidance for all page assignments within a day. Furthermore, we propose the HRM module that decomposes session-level feedback into fine-grained signals, enabling precise local supervision for each page assignment. Extensive online experiments conducted on the Kuaishou platform demonstrate the effectiveness of GLAN, achieving +0.158\% and +0.108\% improvements on Daily Active Users (DAU) and user Lifetime (LT) respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GLAN, a Decision Transformer-based sequence modeling framework for Personalized Landing Page Modeling (PLPM) on the Kuaishou platform. It critiques the prior CQL-based KLAN for failing the Markov assumption on non-Markovian user behaviors and suffering cumulative TD errors under delayed rewards, then introduces L-RTG to capture inter-day consumption dynamics for global guidance and HRM to decompose session feedback for local supervision. Online A/B tests report +0.158% DAU and +0.108% LT lifts.
Significance. If the online results hold under rigorous controls, the work demonstrates a practical shift from bootstrapped RL to generative sequence modeling for long-horizon recommendation tasks, potentially improving credit assignment in multi-session user journeys. The explicit global-local decomposition via L-RTG and HRM offers a concrete architectural pattern that could generalize beyond landing-page navigation.
major comments (1)
- [Experiments section] Experiments section: the abstract and results report +0.158% DAU and +0.108% LT gains from online A/B tests, yet provide no information on the control baseline (e.g., KLAN or production heuristic), experiment duration, number of users, statistical significance tests, or how L-RTG and HRM were deployed in the live system. These omissions are load-bearing because the central claim—that the modules resolve the stated Markov and TD limitations—rests entirely on the attribution of these lifts.
minor comments (1)
- [§3] Notation for L-RTG and HRM is introduced without an explicit equation or pseudocode block showing how the return-to-go tokens and hierarchical reward signals are constructed from raw logs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experiments section. We agree that additional details are needed to support the attribution of the reported online gains and will revise accordingly.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the abstract and results report +0.158% DAU and +0.108% LT gains from online A/B tests, yet provide no information on the control baseline (e.g., KLAN or production heuristic), experiment duration, number of users, statistical significance tests, or how L-RTG and HRM were deployed in the live system. These omissions are load-bearing because the central claim—that the modules resolve the stated Markov and TD limitations—rests entirely on the attribution of these lifts.
Authors: We acknowledge the omission of these critical experimental details in the current manuscript. In the revised version, we will add a new subsection in the Experiments section that explicitly describes: the control baseline (the production system using the prior KLAN model), the A/B test duration and user scale, the statistical significance testing procedure and resulting p-values for the DAU and LT lifts, and the online deployment architecture showing how L-RTG and HRM are integrated into the live serving pipeline. These additions will directly address the concern about attribution and allow readers to evaluate the strength of the evidence. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper motivates GLAN by critiquing limitations of prior CQL-based KLAN (Markov assumption failure and TD error accumulation) but validates effectiveness solely through external online A/B experiments on the Kuaishou platform reporting +0.158% DAU and +0.108% LT lifts. No equations, modules (L-RTG, HRM), or derivations are presented that reduce predictions or results to self-fitted parameters, self-definitional quantities, or load-bearing self-citations. The sequence modeling approach on Decision Transformer is positioned as an alternative framework whose value is measured by live user metrics, not internal consistency checks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stefanos Antaris and Dimitrios Rafailidis. 2021. Sequence Adaptation via Reinforcement Learning in Recommender Systems. arXiv:2108.01442 [cs.IR] https://arxiv.org/abs/2108.01442
arXiv 2021
-
[2]
Prajjwal Bhargava, Rohan Chitnis, Alborz Geramifard, Shagun Sodhani, and Amy Zhang. 2024. When should we prefer Decision Transformers for Offline Reinforcement Learning? arXiv:2305.14550 [cs.LG] https://arxiv.org/abs/2305. 14550
arXiv 2024
-
[3]
David Brandfonbrener, Alberto Bietti, Jacob Buckman, Romain Laroche, and Joan Bruna. 2023. When does return-conditioned supervised learning work for offline reinforcement learning? arXiv:2206.01079 [cs.LG] https://arxiv.org/abs/2206. 01079
arXiv 2023
-
[4]
Haokun Chen, Xinyi Dai, Han Cai, Weinan Zhang, Xuejian Wang, Ruiming Tang, Yuzhou Zhang, and Yong Yu. 2019. Large-scale Interactive Recommendation with Tree-structured Policy Gradient. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 3312–3320
2019
-
[5]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. 2021. Decision Transformer: Reinforcement Learning via Sequence Modeling. arXiv:2106.01345 [cs.LG] https://arxiv.org/abs/2106.01345
Pith/arXiv arXiv 2021
-
[6]
Minmin Chen, Alex Beutel, Paul Covington, Sagar Jain, Francois Belletti, and Ed H. Chi. 2019. Top-k Off-policy Correction for a REINFORCE Recommender System. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining (WSDM ’19). 456–464
2019
-
[7]
Chao Cui, Shisong Tang, Fan Li, Jiechao Gao, and Hechang Chen. 2025. Cali- brating Video Watch-time Predictions with Credible Prototype Alignment. In Proceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). PMLR. https://openreview.net/forum? id=aYUjVw9zcO ICML 2025 poster
2025
-
[8]
Jingtong Gao, Bo Chen, Weiwen Liu, Xiangyang Li, Yichao Wang, Wanyu Wang, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. 2025. LLM4Rerank: LLM-based Auto-Reranking Framework for Recommendations. arXiv:2406.12433 [cs.IR] https://arxiv.org/abs/2406.12433
arXiv 2025
-
[9]
Jingtong Gao, Zhaocheng Du, Xiaopeng Li, Yichao Wang, Xiangyang Li, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. 2025. SampleLLM: Optimizing Tabular Data Synthesis in Recommendations. arXiv:2501.16125 [cs.IR] https://arxiv.org/ abs/2501.16125
arXiv 2025
-
[10]
Jingtong Gao, Yewen Li, Shuai Mao, Peng Jiang, Nan Jiang, Yejing Wang, Qing- peng Cai, Fei Pan, Peng Jiang, Kun Gai, Bo An, and Xiangyu Zhao. 2025. Gener- ative Auto-Bidding with Value-Guided Explorations. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association...
-
[11]
Yingqiang Ge, Shuchang Liu, Ruoyuan Gao, Yikun Xian, Yunqi Li, Xiangyu Zhao, Changhua Pei, Fei Sun, Junfeng Ge, Wenwu Ou, and Yongfeng Zhang. 2021. Towards Long-term Fairness in Recommendation. InProceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM ’21). 445–453
2021
-
[12]
Yingqiang Ge, Xiaoting Zhao, Lucia Yu, Saurabh Paul, Diane Hu, Chu-Cheng Hsieh, and Yongfeng Zhang. 2022. Toward Pareto Efficient Fairness-Utility Tradeoff in Recommendation Through Reinforcement Learning. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining (WSDM ’22). 316–324
2022
-
[13]
Majid Ghasemi, Amir Hossein Moosavi, and Dariush Ebrahimi. 2025. A Com- prehensive Survey of Reinforcement Learning: From Algorithms to Practical Challenges. arXiv:2411.18892 [cs.AI] https://arxiv.org/abs/2411.18892
arXiv 2025
-
[14]
Wei Guo, Chang Meng, Enming Yuan, Zhicheng He, Huifeng Guo, Yingxue Zhang, Bo Chen, Yaochen Hu, Ruiming Tang, Xiu Li, and Rui Zhang. 2023. Compressed Interaction Graph based Framework for Multi-behavior Recommendation. In Proceedings of the ACM Web Conference 2023(Austin, TX, USA)(WWW ’23). Association for Computing Machinery, New York, NY, USA, 960–970. ...
arXiv 2023
-
[15]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. InProceedings of the 35th International Conference on Machine Learning, ICML 2018 (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, 1861–1870
2018
-
[16]
Beining Han, Zhizhou Ren, Zuofan Wu, Yuan Zhou, and Jian Peng. 2021. Off- Policy Reinforcement Learning with Delayed Rewards. arXiv:2106.11854 [cs.LG] https://arxiv.org/abs/2106.11854
arXiv 2021
-
[17]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation. arXiv:1808.09781 [cs.IR] https://arxiv.org/abs/1808.09781
Pith/arXiv arXiv 2018
-
[18]
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. 2021. Offline Reinforcement Learning with Implicit Q-Learning. arXiv:2110.06169 [cs.LG] https://arxiv.org/ abs/2110.06169
Pith/arXiv arXiv 2021
-
[19]
Aviral Kumar, Joey Hong, Anikait Singh, and Sergey Levine. 2022. When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning? arXiv:2204.05618 [cs.LG] https://arxiv.org/abs/2204.05618
arXiv 2022
-
[20]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. 2020. Conserva- tive Q-Learning for Offline Reinforcement Learning. arXiv:2006.04779 [cs.LG] https://arxiv.org/abs/2006.04779
arXiv 2020
-
[21]
Fan Li, Jiazhen Huang, Shisong Tang, Bing Han, Huafeng Cao, Haochen Sui, Ting Xu, and Xiaoyu Kang. 2025. Contrastive Prototype Framework for Calibrating Video Recommendation. InProceedings of the 33rd ACM International Conference on Multimedia. 6373–6382
2025
-
[22]
Fan Li, Chang Meng, Jiaqi Fu, Shuchang Liu, Jiashuo Zhang, Tianke Zhang, Xueliang Wang, and Xiaoqiang Feng. 2026. KLAN: Kuaishou Landing-page Adaptive Navigator. arXiv:2507.23459 [cs.IR] https://arxiv.org/abs/2507.23459
arXiv 2026
-
[23]
Fan Li, Xu Si, Shisong Tang, Dingmin Wang, Kunyan Han, Bing Han, Guorui Zhou, Yang Song, and Hechang Chen. 2024. Contextual Distillation Model for Diversified Recommendation. InProceedings of the 30th ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 5307–5316...
-
[24]
Xinhang Li, Zhaopeng Qiu, Xiangyu Zhao, Zihao Wang, Yong Zhang, Chunxiao Xing, and Xian Wu. 2022. Gromov-Wasserstein Guided Representation Learning for Cross-Domain Recommendation. InProceedings of the 31st ACM International Conference on Information & Knowledge Management(Atlanta, GA, USA)(CIKM ’22). Association for Computing Machinery, New York, NY, USA...
-
[25]
Yewen Li, Jingtong Gao, Nan Jiang, Shuai Mao, Ruyi An, Fei Pan, Xiangyu Zhao, Bo An, Qingpeng Cai, and Peng Jiang. 2025. Generative Auto- Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner. arXiv:2509.03348 [cs.GT] https://arxiv.org/abs/2509.03348
arXiv 2025
-
[26]
Zelong Li, Jianchao Ji, Yingqiang Ge, and Yongfeng Zhang. 2022. AutoLossGen: Automatic Loss Function Generation for Recommender Systems. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). 1304–1315
2022
-
[27]
Feng Liu, Ruiming Tang, Xutao Li, Weinan Zhang, Yunming Ye, Haokun Chen, Huifeng Guo, and Yuzhou Zhang. 2019. Deep Reinforcement Learn- ing based Recommendation with Explicit User-Item Interactions Modeling. arXiv:1810.12027 [cs.IR] https://arxiv.org/abs/1810.12027
arXiv 2019
-
[28]
Zuxin Liu, Zijian Guo, Yihang Yao, Zhepeng Cen, Wenhao Yu, Tingnan Zhang, and Ding Zhao. 2023. Constrained Decision Transformer for Offline Safe Rein- forcement Learning. arXiv:2302.07351 [cs.LG] https://arxiv.org/abs/2302.07351
arXiv 2023
-
[29]
Ziru Liu, Jiejie Tian, Qingpeng Cai, Xiangyu Zhao, Jingtong Gao, Shuchang Liu, Dayou Chen, Tonghao He, Dong Zheng, Peng Jiang, and Kun Gai. 2023. Multi- Task Recommendations with Reinforcement Learning. InProceedings of the ACM Web Conference 2023 (WWW ’23). ACM, 1273–1282. doi:10.1145/3543507.3583467
-
[30]
Xingyu Lu, Tianke Zhang, Chang Meng, Xiaobei Wang, Jinpeng Wang, Yifan Zhang, Shisong Tang, Changyi Liu, Haojie Ding, Kaiyu Jiang, Kaiyu Tang, Bin Wen, Hai-Tao Zheng, Fan Yang, Tingting Gao, Di Zhang, and Kun Gai. 2025. VLM as Policy: Common-Law Content Moderation Framework for Short Video Plat- form. InProceedings of the 31st ACM SIGKDD Conference on Kno...
-
[31]
Chang Meng, Chenhao Zhai, Xueliang Wang, Shuchang Liu, Xiaoqiang Feng, Lantao Hu, Xiu Li, Han Li, and Kun Gai. 2024. Coarse-to-fine Dynamic Uplift Modeling for Real-time Video Recommendation. arXiv:2410.16755 [cs.IR] https: //arxiv.org/abs/2410.16755
arXiv 2024
-
[32]
Chang Meng, Chenhao Zhai, Xueliang Wang, Shuchang Liu, Xiaoqiang Feng, Lantao Hu, Xiu Li, Han Li, and Kun Gai. 2025. Enhancing Online Video Rec- ommendation via a Coarse-to-fine Dynamic Uplift Modeling Framework. In Proceedings of the Nineteenth ACM Conference on Recommender Systems (Rec- Sys ’25). Association for Computing Machinery, New York, NY, USA, 8...
-
[33]
Chang Meng, Chenhao Zhai, Yu Yang, Hengyu Zhang, and Xiu Li. 2023. Parallel Knowledge Enhancement based Framework for Multi-behavior Recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management(Birmingham, United Kingdom)(CIKM ’23). Association for Computing Machinery, New York, NY, USA, 1797–1806. doi:10....
-
[34]
Chang Meng, Hengyu Zhang, Wei Guo, Huifeng Guo, Haotian Liu, Yingxue Zhang, Hongkun Zheng, Ruiming Tang, Xiu Li, and Rui Zhang. 2023. Hierarchical Projection Enhanced Multi-behavior Recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). Association for Computing Machinery, New ...
-
[35]
Chang Meng, Ziqi Zhao, Wei Guo, Yingxue Zhang, Haolun Wu, Chen Gao, Dong Li, Xiu Li, and Ruiming Tang. 2023. Coarse-to-Fine Knowledge-Enhanced Multi- Interest Learning Framework for Multi-Behavior Recommendation.ACM Trans. Inf. Syst.42, 1, Article 30 (Aug. 2023), 27 pages. doi:10.1145/3606369
-
[36]
Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timo- thy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. Asyn- chronous Methods for Deep Reinforcement Learning. InProceedings of the 33rd International Conference on Machine Learning, ICML 2016 (JMLR Workshop and Conference Proceedings, Vol. 48), Maria-Florina Balca...
2016
-
[37]
Changhua Pei, Xinru Yang, Qing Cui, Xiao Lin, Fei Sun, Peng Jiang, Wenwu Ou, and Yongfeng Zhang. 2019. Value-aware Recommendation Based on Rein- forcement Profit Maximization. InThe World Wide Web Conference (WWW ’19). 3123–3129
2019
-
[38]
Rummery and Mahesan Niranjan
Gavin A. Rummery and Mahesan Niranjan. 1994.On-Line Q-Learning Using Connectionist Systems. Technical Report CUED/F-INFENG/TR 166. Cambridge University Engineering Department
1994
-
[39]
Richard S. Sutton. 1988. Learning to Predict by the Methods of Temporal Differ- ences.Mach. Learn.3, 1 (Aug. 1988), 9–44. doi:10.1023/A:1022633531479
-
[40]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. 1998. Reinforcement Learning: An Introduction.IEEE Transactions on Neural Networks9, 5 (1998), 1054
1998
-
[41]
Nima Taghipour, Ahmad Kardan, and Saeed Shiry Ghidary. 2007. Usage-based Web Recommendations: a Reinforcement Learning Approach. InProceedings of the 2007 ACM Conference on Recommender Systems (RecSys ’07). 113–120
2007
-
[42]
Hado van Hasselt, Arthur Guez, and David Silver. 2015. Deep Reinforcement Learning with Double Q-learning. arXiv:1509.06461 [cs.LG] https://arxiv.org/ abs/1509.06461
Pith/arXiv arXiv 2015
-
[43]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. Attention Is All You Need. arXiv:1706.03762 [cs.CL] https://arxiv.org/abs/1706.03762
Pith/arXiv arXiv 2023
-
[44]
1989.Learning from Delayed Rewards
Christopher John Cornish Hellaby Watkins. 1989.Learning from Delayed Rewards. Ph. D. Dissertation. King’s College, Cambridge
1989
-
[45]
Kasun Weerakoon, Souradip Chakraborty, Nare Karapetyan, Adarsh Jagan Sathyamoorthy, Amrit Singh Bedi, and Dinesh Manocha. 2022. HTRON:Efficient Outdoor Navigation with Sparse Rewards via Heavy Tailed Adaptive Reinforce Algorithm. arXiv:2207.03694 [cs.RO] https://arxiv.org/abs/2207.03694
arXiv 2022
-
[46]
Binrui Wu, Shisong Tang, Fan Li, Bing Han, Chang Meng, Jingyu Xiao, and Jiechao Gao. 2025. Aligning and Balancing ID and Multimodal Representations for Recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto, ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 5029–5038. ...
arXiv 2025
-
[47]
Yidong Wu, Siyuan Chen, Binrui Wu, Fan Li, and Jiechao Gao. 2025. Adap- tive Gradient Masking for Balancing ID and MLLM-based Representations in Recommendation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=Ykg7dr6c1Y NeurIPS 2025 poster
2025
-
[48]
Yikun Xian, Zuohui Fu, Shan Muthukrishnan, Gerard De Melo, and Yongfeng Zhang. 2019. Reinforcement Knowledge Graph Reasoning for Explainable Rec- ommendation. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’19). 285–294
2019
-
[49]
Taku Yamagata, Ahmed Khalil, and Raul Santos-Rodriguez. 2023. Q-learning Decision Transformer: Leveraging Dynamic Programming for Conditional Se- quence Modelling in Offline RL. arXiv:2209.03993 [cs.LG] https://arxiv.org/abs/ 2209.03993
arXiv 2023
-
[50]
Yujian Ye, Dawei Qiu, Mingyang Sun, Dimitrios Papadaskalopoulos, and Goran Strbac. 2020. Deep Reinforcement Learning for Strategic Bidding in Electricity Markets.IEEE Transactions on Smart Grid11, 2 (2020), 1343–1355. doi:10.1109/ TSG.2019.2936142
arXiv 2020
-
[51]
Feng Yu, Yanqiao Zhu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2020. TAGNN: Target Attentive Graph Neural Networks for Session-based Recom- mendation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’20). ACM, 1921–1924. doi:10.1145/3397271.3401319
-
[52]
Qing Yu, Xiaobei Wang, Shuchang Liu, Yandong Bai, Xiaoyu Yang, Xueliang Wang, Chang Meng, Shanshan Wu, Hailan Yang, Bin Wen, Huihui Xiao, Xiang Li, Fan Yang, Xiaoqiang Feng, Lantao Hu, Han Li, Kun Gai, and Lixin Zou. 2025. Who You Are Matters: Bridging Interests and Social Roles via LLM-Enhanced Logic Recommendation. InThe Thirty-ninth Annual Conference o...
2025
-
[53]
Chenhao Zhai, Chang Meng, Xueliang Wang, Shuchang Liu, Xiaolong Hu, Shisong Tang, Xiaoqiang Feng, and Xiu Li. 2026. Heterogeneous Multi-treatment Uplift Modeling for Trade-off Optimization in Short-Video Recommendation. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1(Jeju Island, Korea)(KDD ’26). Association for ...
-
[54]
Chenhao Zhai, Chang Meng, Yu Yang, Kexin Zhang, Xuhao Zhao, and Xiu Li
-
[55]
Combinatorial Optimization Perspective based Framework for Multi- behavior Recommendation. InProceedings of the 31st ACM SIGKDD Confer- ence on Knowledge Discovery and Data Mining V.1(Toronto, ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 1891–1902. doi:10.1145/3690624.3709278
-
[56]
Hengyu Zhang, Chang Meng, Wei Guo, Huifeng Guo, Jieming Zhu, Guangpeng Zhao, Ruiming Tang, and Xiu Li. 2023. Time-aligned Exposure-enhanced Model for Click-Through Rate Prediction. arXiv:2308.09966 [cs.IR] https://arxiv.org/ abs/2308.09966
arXiv 2023
-
[57]
Xiangyu Zhao, Changsheng Gu, Haoshenglun Zhang, Xiwang Yang, Xiaobing Liu, Hui Liu, and Jiliang Tang. 2021. DEAR: Deep Reinforcement Learning for Online Advertising Impression in Recommender Systems. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 750–758
2021
-
[58]
Deep rein- forcement learning for search, recommendation, and online advertising: a sur- vey
Xiangyu Zhao, Long Xia, Jiliang Tang, and Dawei Yin. 2019. “Deep rein- forcement learning for search, recommendation, and online advertising: a sur- vey” by Xiangyu Zhao, Long Xia, Jiliang Tang, and Dawei Yin with Martin Vesely as coordinator.ACM SIGWEB Newsletter2019, Spring (July 2019), 1–15. doi:10.1145/3320496.3320500
-
[59]
Xiangyu Zhao, Liang Zhang, Zhuoye Ding, Long Xia, Jiliang Tang, and Dawei Yin
-
[60]
InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’18)
Recommendations with Negative Feedback via Pairwise Deep Reinforce- ment Learning. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’18). 1040–1048
-
[61]
Hongling Zheng, Li Shen, Yong Luo, Deheng Ye, Bo Du, Jialie Shen, and Dacheng Tao. 2025. Decision Mixer: Integrating Long-term and Local Dependencies via Dynamic Token Selection for Decision-Making. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025). https://openreview. net/forum?id=4oE8vTw5IU Poster / OpenReview
2025
-
[62]
Xianghui Zhu, Mengqun Jin, Hengyu Zhang, Chang Meng, Daoxin Zhang, and Xiu Li. 2024. Modeling Domains as Distributions with Uncertainty for Cross- Domain Recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 2517...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.