ComHymba: Low-Complexity Domain-Informed Foundation Model for Wireless Communications
Pith reviewed 2026-05-25 03:53 UTC · model grok-4.3
The pith
ComHymba pre-trains a wireless foundation model on channel state information using domain-informed masking and linear-complexity blocks to outperform task-specific baselines on eight tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
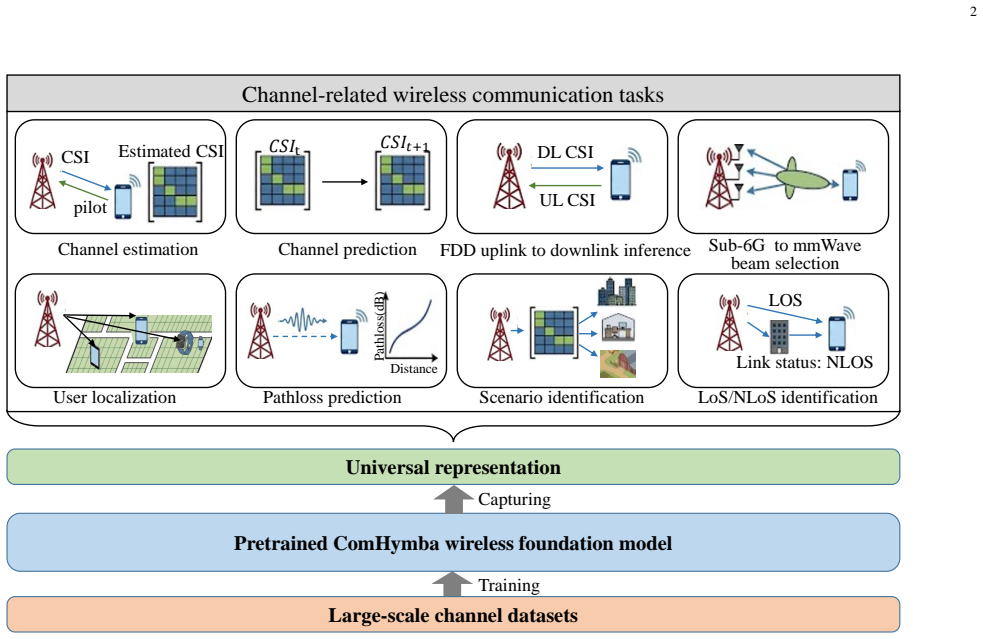
ComHymba is a domain-informed wireless foundation model built on an asymmetric masked autoencoder for self-supervised pre-training on CSI. It uses 3D spatio-temporal-frequency patchification with rotary positional embeddings, masking strategies that emulate realistic CSI sparsity and fading patterns, and a decoupled amplitude-phase weighted objective tailored to channel statistics. Architecturally it replaces standard Transformer layers with Hymba blocks that fuse windowed self-attention and state space models, producing linear-time scaling with respect to overall channel input size. When evaluated on eight downstream tasks in channel reconstruction, environmental sensing, and beam管理, thepre
What carries the argument
Hymba blocks that fuse windowed self-attention with state space models, together with domain-informed masking and a decoupled amplitude-phase objective, to enable linear-time modeling of CSI during pre-training.
If this is right
- A single pre-trained network can be fine-tuned for channel reconstruction, sensing, and beam management instead of training separate models for each.
- Inference cost grows linearly with the size of the channel input rather than quadratically, supporting larger antenna arrays or wider bandwidths.
- The same backbone yields measurable accuracy improvements on all eight tested tasks while delivering up to 3.3 times faster inference than Transformer equivalents.
- Domain-specific priors injected only at pre-training time reduce the need for extensive hyperparameter search on each downstream task.
Where Pith is reading between the lines
- The same masking and loss design could be adapted to other signal types such as radar returns or acoustic channels if the underlying sparsity patterns share similar structure.
- Further scaling of the pre-training corpus size or model depth would likely produce additional gains, following the pattern observed in other foundation-model domains.
- Deployment in a live network could allow the model to be updated periodically on new CSI collected from the field, gradually improving performance across all supported tasks without retraining from scratch each time.
Load-bearing premise
The chosen masking patterns and amplitude-phase loss actually reproduce the statistical structure of real wireless channels closely enough for the learned representations to transfer to new tasks without heavy per-task retuning.
What would settle it
Running the pre-trained model on a fresh collection of measured CSI from an environment or frequency band not seen in pre-training and finding no accuracy gain over strong task-specific baselines on at least one of the eight task types.
Figures







read the original abstract
Wireless foundation models are a promising route to unify channel reconstruction, sensing, and beam management in future wireless communication systems, but existing designs often inherit LLM-style Transformers with quadratic token complexity and weak integration of propagation priors. This paper proposes ComHymba, a domain-informed wireless foundation model built on an asymmetric masked autoencoder for large-scale self-supervised pre-training on Channel State Information (CSI). ComHymba introduces (i) 3D spatio-temporal-frequency patchification with rotary positional embedding, (ii) domain-informed masking strategies that emulate realistic CSI sparsity and fading patterns, and (iii) a decoupled amplitude--phase weighted objective tailored to channel statistics. Architecturally, we employ Hymba blocks that fuse windowed self-attention with state space models (SSMs), enabling linear-time modeling with respect to the overall channel input size. Experiments on eight downstream tasks spanning channel state information reconstruction, environmental sensing, and beam management show consistent accuracy gains over strong task-specific baselines, together with up to a $3.3\times$ inference speedup versus Transformer backbones. Overall, ComHymba provides a scalable and efficient backbone for AI-native physical-layer intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ComHymba, a domain-informed wireless foundation model using an asymmetric masked autoencoder for self-supervised pre-training on CSI. It introduces 3D spatio-temporal-frequency patchification with rotary embeddings, domain-informed masking to emulate CSI sparsity and fading, a decoupled amplitude-phase weighted objective, and Hymba blocks that fuse windowed self-attention with state-space models for linear-time modeling. Experiments across eight downstream tasks in CSI reconstruction, environmental sensing, and beam management report consistent accuracy gains over task-specific baselines and up to 3.3× inference speedup versus Transformer backbones.
Significance. If the reported gains and speedup hold under the described pre-training and evaluation protocol, the work offers a practical route toward scalable, domain-aware backbones for AI-native physical-layer processing. The explicit incorporation of propagation priors via masking and the objective, together with the linear-complexity claim from SSM fusion, distinguishes it from generic LLM-style adaptations and could reduce the need for per-task retraining in wireless systems.
minor comments (3)
- [§4.2] §4.2: the description of the eight downstream tasks would benefit from an explicit table listing task names, input dimensions, training-set sizes, and the precise metric used for each (e.g., NMSE, accuracy, or beamforming gain).
- [Figure 3] Figure 3: the caption does not state whether the plotted curves are averaged over multiple random seeds or single runs; error bars or standard deviations should be added or the single-run nature clarified.
- [§3.3] §3.3, Eq. (7): the weighting coefficients α and β in the decoupled amplitude-phase loss are introduced without a sensitivity study; a brief ablation on their effect on downstream transfer would strengthen the claim that the objective is tailored to channel statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The summary and significance assessment accurately capture the contributions of ComHymba, including the domain-informed masking, decoupled objective, Hymba blocks for linear complexity, and gains across the eight downstream tasks. No major comments were provided in the report.
Circularity Check
No significant circularity; empirical architecture validated by experiments
full rationale
The paper describes an empirical engineering contribution: a masked autoencoder architecture (ComHymba) with 3D patchification, domain-informed masking, decoupled amplitude-phase loss, and Hymba blocks fusing attention and SSMs for linear complexity. All load-bearing claims (accuracy gains on eight downstream tasks, 3.3× speedup) rest on reported experimental results rather than any closed-form derivation, fitted parameter renamed as prediction, or self-citation chain. No equations appear in the provided text, and design choices are explicitly motivated by CSI properties without reducing to tautology or prior self-work. The contribution is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ComHymba introduces (i) 3D spatio-temporal-frequency patchification with rotary positional embedding, (ii) domain-informed masking strategies that emulate realistic CSI sparsity and fading patterns, and (iii) a decoupled amplitude–phase weighted objective
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Hymba blocks that fuse windowed self-attention with state space models (SSMs), enabling linear-time modeling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The road towards 6G: A comprehensive survey,
W. Jiang, B. Han, M. A. Habibi, and H. D. Schotten, “The road towards 6G: A comprehensive survey,”IEEE Open J. Commun. Soc., vol. 2, pp. 334–366, Feb. 2021
work page 2021
-
[2]
Large AI models for wireless physical layer,
J. Guo, Y . Cui, S. Jin, and J. Zhang, “Large AI models for wireless physical layer,”IEEE Commun. Mag., vol. 64, no. 5, pp. 148–155, 2026
work page 2026
-
[3]
Signal processing and learning for next generation multiple access in 6G,
W. Chen, Y . Liu, H. Jafarkhani, Y . C. Eldar, P. Zhu, and K. B. Letaief, “Signal processing and learning for next generation multiple access in 6G,”IEEE J. Sel. Topics Signal Process., vol. 18, no. 7, pp. 1146–1177, Oct. 2024
work page 2024
-
[4]
A comprehensive survey on GenAI-enabled 6G: Technologies, challenges, and future research avenues,
M. Sheraz, T. C. Chuah, W. U. K. Tareen, A. Al-Habashna, S. I. Saeed, M. Ahmed et al., “A comprehensive survey on GenAI-enabled 6G: Technologies, challenges, and future research avenues,”IEEE Open J. Commun. Soc., vol. 6, pp. 4563–4590, 2025
work page 2025
-
[5]
F. Jiang, C. Pan, L. Dong, K. Wang, M. Debbah, D. Niyato, and Z. Han, “A comprehensive survey of large AI models for future communications: Foundations, applications, and challenges,”IEEE Commun. Surv. Tuto- rials, vol. 28, pp. 4731–4764, 2026
work page 2026
-
[6]
An introduction to deep learning for the physical layer,
T. J. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,”IEEE Trans. Cognit. Commun. Networking, vol. 3, no. 4, pp. 563–575, Dec. 2017
work page 2017
-
[7]
Deep learning for intelligent wireless networks: A comprehensive survey,
Q. Mao, F. Hu, and Q. Hao, “Deep learning for intelligent wireless networks: A comprehensive survey,”IEEE Commun. Surv. Tutorials, vol. 20, no. 4, pp. 2595–2621, 2018
work page 2018
-
[8]
AI- driven wireless positioning: Fundamentals, standards, state-of-the-art, and challenges,
G. Pan, Y . Gao, Y . Gao, W. Yu, Z. Zhong, X. Yanget al., “AI- driven wireless positioning: Fundamentals, standards, state-of-the-art, and challenges,”IEEE Commun. Surv. Tutorials, vol. 28, pp. 4394–4428, 2026
work page 2026
-
[9]
Advancing 6G: Survey for explainable AI on communications and network slicing,
H. Sun, Y . Liu, A. Al-Tahmeesschi, A. Nag, M. Soleimanpour, B. Canberk, H. Arslan, and H. Ahmadi, “Advancing 6G: Survey for explainable AI on communications and network slicing,”IEEE Open J. Commun. Soc., vol. 6, pp. 1372–1412, 2025
work page 2025
-
[10]
Wireless large AI model: shaping the AI-empowered future of 6G and beyond
F. Zhuet al., “Wireless large AI model: shaping the AI-empowered future of 6G and beyond,” 2026, arXiv:2504.14653. [Online]. Available: https://arxiv.org/abs/2504.14653
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Big AI models for 6G wireless networks: Opportunities, challenges, and research directions,
Z. Chen, Z. Zhang, and Z. Yang, “Big AI models for 6G wireless networks: Opportunities, challenges, and research directions,”IEEE Wireless Commun., vol. 31, no. 5, pp. 164–172, Oct. 2024
work page 2024
-
[12]
Large language models for wireless communications: From adaptation to autonomy,
L. Lianget al., “Large language models for wireless communications: From adaptation to autonomy,”arXiv preprint arXiv:2507.21524, 2025
-
[13]
ST-LLM: Multi-scenario adaptation and multi-task learning wireless large language model,
W. Chen, B. Yang, J. Cheng, and B. Ai, “ST-LLM: Multi-scenario adaptation and multi-task learning wireless large language model,”Sci. China Inf. Sci., 2026
work page 2026
-
[14]
Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,
J. Jiang, Y . Gao, X. Wu, and S. Xu, “Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,”arXiv preprint arXiv:2507.13637, 2025
-
[15]
WiFo: Wireless foundation model for channel prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Yang, “WiFo: Wireless foundation model for channel prediction,”Sci. China Inf. Sci., vol. 68, no. 6, p. 162302, 2025
work page 2025
-
[16]
WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,
T. Yang, P. Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,”IEEE Network, vol. 39, no. 5, pp. 58–65, 2025
work page 2025
-
[17]
L. Yu, L. Shi, J. Zhang, Z. Zhang, Y . Zhang, and G. Liu, “ChannelGPT: A large model toward real-world channel foundation model for 6G en- vironment intelligence communication,”IEEE Commun. Mag., vol. 63, no. 10, pp. 68–74, Oct. 2025
work page 2025
-
[18]
LVM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks,
J. Guo, P. Jiang, C.-K. Wen, S. Jin, and J. Zhang, “LVM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks,”arXiv preprint arXiv:2507.05121, 2025
-
[19]
LWM: A pre-trained wireless foundation model for universal feature extraction,
S. Alikhani, G. Charan, and A. Alkhateeb, “LWM: A pre-trained wireless foundation model for universal feature extraction,” inProc. IEEE Int. Conf. Mach. Learn. Commun. Netw., 2025, pp. 1–6
work page 2025
-
[20]
Efficient Transformers: A Survey,
Y . Tay, M. Dehghani, D. Bahri, and D. Metzler, “Efficient Transformers: A Survey,”ACM Comput. Surv., vol. 55, no. 6, pp. 1–28, 2022
work page 2022
-
[21]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 15979–15988
work page 2022
-
[22]
Hymba: A hybrid-head architecture for small language models,
X. Donget al., “Hymba: A hybrid-head architecture for small language models,” inProc. Int. Conf. Learn. Represent., 2025, pp. 1–23
work page 2025
-
[23]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inProc. Adv. Neural Inf. Process. Syst., 2017, pp. 5998–6008
work page 2017
-
[24]
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,”Proc. Mach. Learn. Res., vol. 235, pp. 10041–10071, 2024. [25]Study on channel model for frequencies from 0.5 to 100 GHz (Release 16), 3GPP Technical report (TR) 38.901, Dec. 2019, v16.1.0
work page 2024
-
[25]
QuaDRiGa: A 3- D multi-cell channel model with time evolution for enabling virtual field trials,
S. Jaeckel, L. Raschkowski, K. B ¨orner, and L. Thiele, “QuaDRiGa: A 3- D multi-cell channel model with time evolution for enabling virtual field trials,”IEEE Trans. Antennas Propag., vol. 62, no. 6, pp. 3242—3256, Jun. 2014
work page 2014
-
[26]
Deep learning for mmWave beam and blockage prediction using sub-6 GHz channels,
M. Alrabeiah and A. Alkhateeb, “Deep learning for mmWave beam and blockage prediction using sub-6 GHz channels,”IEEE Trans. Commun., vol. 68, no. 9, pp. 5504–5518, Sep. 2020
work page 2020
-
[27]
CSI-based fingerprinting for indoor localization: A deep learning approach,
X. Wang, L. Gao, S. Mao, and S. Pandey, “CSI-based fingerprinting for indoor localization: A deep learning approach,”IEEE Trans. Veh. Technol., vol. 66, no. 1, pp. 763–776, Jan. 2017
work page 2017
-
[28]
Deep UL2DL: Data- driven channel knowledge transfer from uplink to downlink,
M. S. Safari, V . Pourahmadi, and S. Sodagari, “Deep UL2DL: Data- driven channel knowledge transfer from uplink to downlink,”IEEE Open J. Veh. Technol., vol. 1, pp. 29–44, 2020
work page 2020
-
[29]
CSI-based MIMO indoor positioning using attention-aided deep learning,
R. Wan, Y . Chen, S. Song, and Z. Wang, “CSI-based MIMO indoor positioning using attention-aided deep learning,”IEEE Commun. Lett., vol. 28, no. 1, pp. 53–57, Jan. 2024
work page 2024
-
[30]
Deep learning for fading channel predic- tion,
W. Jiang and H. D. Schotten, “Deep learning for fading channel predic- tion,”IEEE Open J. Commun. Soc., vol. 1, pp. 320–332, Mar. 2020
work page 2020
-
[31]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,”arXiv preprint arXiv:1412.3555, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Attention aided CSI wireless localization,
A. Salihu, S. Schwarz, and M. Rupp, “Attention aided CSI wireless localization,” inProc. IEEE Int. Workshop Signal Process. Adv. Wireless Commun., 2022, pp. 1–5
work page 2022
-
[33]
Accurate channel prediction based on transformer: Making mobility negligible,
H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate channel prediction based on transformer: Making mobility negligible,”IEEE J. Sel. Areas Commun., vol. 40, no. 9, pp. 2717–2732, Sep. 2022
work page 2022
-
[34]
LLM4CP: Adapting large language models for channel prediction,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “LLM4CP: Adapting large language models for channel prediction,”J. Commun. Inf. Net- works, vol. 9, no. 2, pp. 113–125, Jun. 2024
work page 2024
-
[35]
LLM4WM: Adapting LLM for wireless multi-tasking,
X. Liu, S. Gao, B. Liu, X. Cheng, and L. Yang, “LLM4WM: Adapting LLM for wireless multi-tasking,”IEEE Trans. Mach. Learn. Commun. Networking, vol. 3, pp. 835–847, 2025
work page 2025
-
[36]
HELENA: High-Efficiency Learning-based channel Estimation using dual Neural Attention
M. C. Botero, E. A. Beyazit, N. Slamnik-Krijestorac, and J. M. Marquez- Barja, “HELENA: High-efficiency learning-based channel estimation using dual neural attention,”arXiv preprint arXiv:2506.13408, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Millimeter wave beam-selection using out-of-band spatial information,
A. Ali, N. Gonz ´alez-Prelcic, and R. W. Heath, Jr., “Millimeter wave beam-selection using out-of-band spatial information,”IEEE Trans. Wireless Commun., vol. 17, no. 2, pp. 1038–1052, Feb. 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.