DREAM-Chunk: Reactive Action Chunking with Latent World Model
Pith reviewed 2026-06-26 21:23 UTC · model grok-4.3
The pith
DREAM-Chunk selects among multiple action chunks at test time by matching a latent world model's short-horizon predictions to observed robot states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
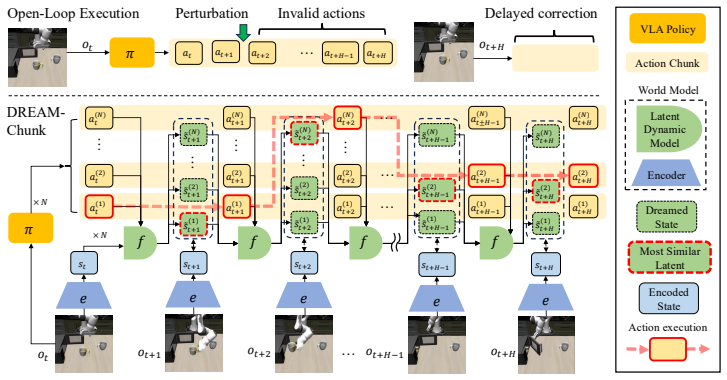
DREAM-Chunk augments chunking-based policies with a lightweight latent world model that samples multiple candidate action chunks, rolls out their predicted latent futures, and selects the chunk whose predicted state best matches the observed rollout, thereby improving reactivity during long-horizon execution without additional policy fine-tuning.
What carries the argument
The best-match selection between predicted and observed latent states produced by the lightweight latent world model.
If this is right
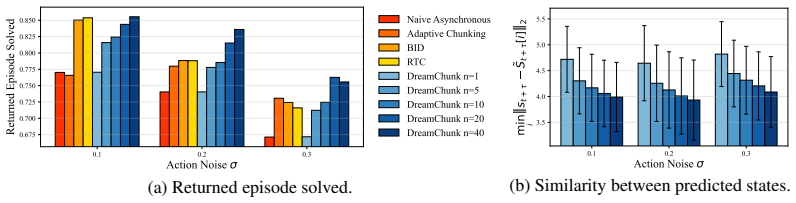
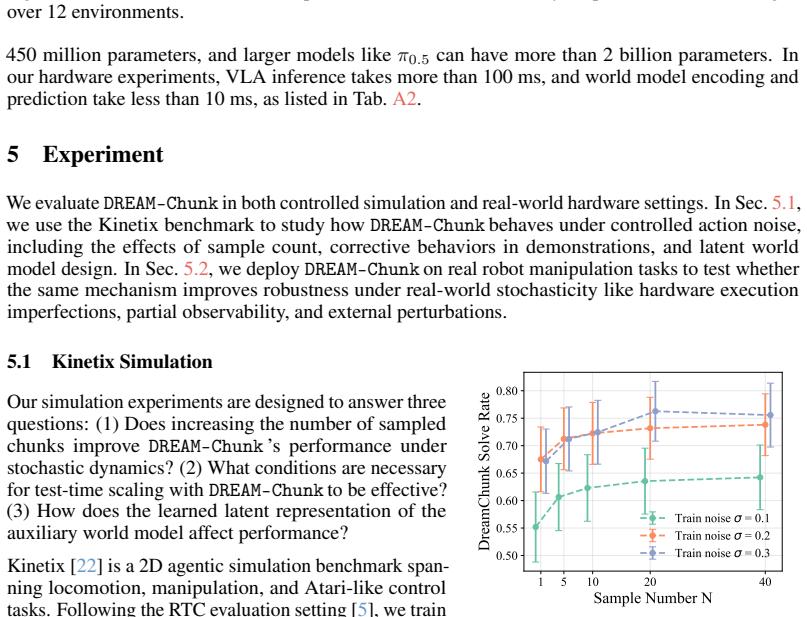
- On the Kinetix benchmark, robustness improves under rising action noise and scales with larger numbers of candidate chunks, especially when training data contains corrective behaviors.
- The method transfers to four manipulation tasks on two different robot platforms using two distinct VLA policies.
- Gains appear under multiple sources of stochasticity in both simulation and hardware.
- No policy fine-tuning is required; only test-time sampling and selection are added.
Where Pith is reading between the lines
- The approach decouples policy frequency from execution frequency by shifting reactivity into test-time search over futures.
- If the latent model remains accurate only over short horizons, the method may still help on tasks where corrective chunks can be chosen frequently.
- The same selection logic could be applied to other open-loop execution schemes that suffer from stochastic drift.
- Hardware validation on two platforms suggests the overhead of latent rollouts is compatible with real-time control loops.
Load-bearing premise
The lightweight latent world model produces accurate enough short-horizon predictions that the best-match criterion reliably identifies the chunk that will succeed in the real environment.
What would settle it
A controlled experiment in which DREAM-Chunk produces equal or lower success rates than standard chunking across increasing levels of action noise and partial observability would falsify the central claim.
Figures


read the original abstract
Action chunking has become a common interface for vision-language-action (VLA) models, enabling low-frequency policy inference to drive high-frequency robot execution. However, once an action chunk is committed, its open-loop execution can be brittle under stochastic dynamics, hardware execution errors, and partial observability. We propose DREAM-Chunk, a test-time scaling method that augments chunking-based policies with a lightweight latent world model, without requiring additional policy fine-tuning. At test time, DREAM-Chunk samples multiple candidate action chunks, rolls out their predicted latent futures, and selects actions from the chunk whose predicted state best matches the observed rollout. In this way, DREAM-Chunk uses additional test-time computation to cover multiple plausible stochastic futures and improve reactivity during long-horizon chunk execution. On the Kinetix benchmark, DREAM-Chunk improves robustness under increasing action noise and benefits from larger candidate sample sizes, especially when demonstrations contain corrective behaviors. We further validate DREAM-Chunk on four manipulation tasks across two robot platforms and two VLA policies under various sources of stochasticity. Across simulation and hardware experiments, DREAM-Chunk improves the robustness of action-chunking policies in stochastic dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DREAM-Chunk, a test-time scaling method for action-chunking policies in vision-language-action (VLA) models. It augments existing policies with a lightweight latent world model that samples multiple candidate action chunks, rolls out their predicted latent futures, and selects the chunk whose predicted state best matches the observed state. This is intended to improve reactivity and robustness under stochastic dynamics, hardware errors, and partial observability without any policy fine-tuning. Experiments are reported on the Kinetix benchmark (showing gains with increasing action noise and larger sample sizes) and on four manipulation tasks across two robot platforms and two VLA policies under various stochasticity sources.
Significance. If the empirical results hold, the approach provides a practical, training-free way to add test-time reactivity to chunked policies by covering multiple stochastic futures via additional compute. This could be useful for long-horizon robotic tasks where open-loop chunk execution is brittle, and the method is presented as compatible with existing VLA policies.
minor comments (2)
- [Abstract] The abstract and method description would benefit from explicit statements of the latent world model architecture, training procedure, and exact selection criterion (e.g., distance metric in latent space).
- It would be helpful to report the computational overhead (inference time or FLOPs) of the candidate sampling and rollout procedure relative to the baseline policy.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DREAM-Chunk and the recommendation to accept the manuscript.
Circularity Check
No significant circularity
full rationale
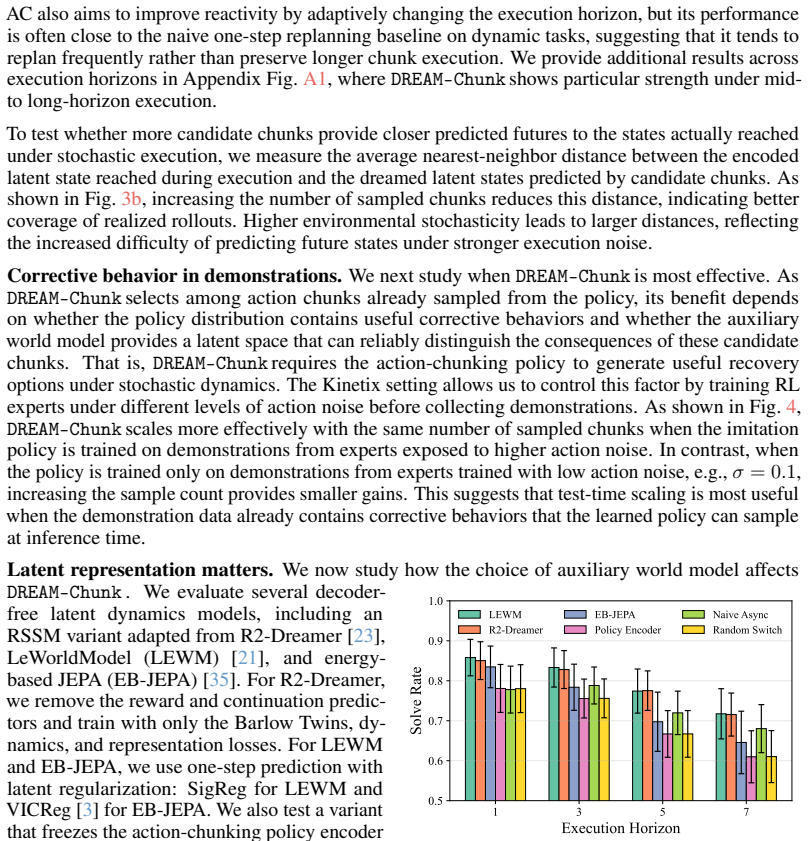
The paper presents DREAM-Chunk as an empirical test-time augmentation to existing action-chunking policies. It describes sampling candidate chunks, rolling out a lightweight latent world model, and selecting the chunk whose predicted latent state best matches the observed state. No derivation chain, first-principles equations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems are present in the abstract or described method. The approach is validated through simulation and hardware experiments rather than reduced to prior inputs by construction. This is the expected honest non-finding for an engineering method paper without closed-form claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion for world modeling: Visual details matter in atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari. InProc. NeurIPS,
-
[2]
Real-time whole-body control of legged robots with model-predictive path integral control
Juan Alvarez-Padilla, John Z Zhang, Sofia Kwok, John M Dolan, and Zachary Manchester. Real-time whole-body control of legged robots with model-predictive path integral control. In Proc. ICRA, 2025. 16
2025
-
[3]
VICReg: Variance-invariance-covariance regular- ization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. VICReg: Variance-invariance-covariance regular- ization for self-supervised learning. InProc. ICLR, 2022. 7
2022
-
[4]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
2025
-
[5]
Galliker, and Sergey Levine
Kevin Black, Manuel Y . Galliker, and Sergey Levine. Real-time execution of action chunking flow policies. InProc. NeurIPS, 2026. 2, 6
2026
-
[6]
WorldVLA: Towards autoregressive action world model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. WorldVLA: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539, 2025. 1, 3
Pith/arXiv arXiv 2025
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. IJRR, 2025. 2
2025
-
[8]
Panda Technical Data
Franka Emika GmbH. Panda Technical Data. https://www.generationrobots.com/med ia/panda-franka-emika-datasheet.pdf, 2018. Datasheet, accessed 2026-05-04. 14
2018
-
[9]
Gemini robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montser- rat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025. 1
Pith/arXiv arXiv 2025
-
[10]
Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019. 3
Pith/arXiv arXiv 1912
-
[11]
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023. 5
Pith/arXiv arXiv 2023
-
[12]
World model for robot learning: A comprehensive survey
Bohan Hou, Gen Li, Jindou Jia, Tuo An, Xinying Guo, Sicong Leng, Haoran Geng, Yanjie Ze, Tatsuya Harada, Philip Torr, et al. World model for robot learning: A comprehensive survey. arXiv preprint arXiv:2605.00080, 2026. 2
Pith/arXiv arXiv 2026
-
[13]
Hugging Face LeRobot. SO-101. https://huggingface.co/docs/lerobot/so101, 2026. LeRobot documentation, accessed 2026-05-04. 14
2026
-
[14]
Joonkyung Kim, Wenxi Chen, Davood Soleymanzadeh, Yi Ding, Xiangbo Gao, Zhengzhong Tu, Ruqi Zhang, Fan Fei, Sushant Veer, Yiwei Lyu, et al. Modular safety guardrails are necessary for foundation-model-enabled robots in the real world.arXiv preprint arXiv:2602.04056, 2026. 2
arXiv 2026
-
[15]
OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 2 10
Pith/arXiv arXiv 2024
-
[16]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Foutter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models.arXiv preprint arXiv:2506.17811, 2025. 3
arXiv 2025
-
[17]
Dart: Noise injection for robust imitation learning
Michael Laskey, Jonathan Lee, Roy Fox, Anca Dragan, and Ken Goldberg. Dart: Noise injection for robust imitation learning. InProc. CoRL, 2017. 2
2017
-
[18]
A path towards autonomous machine intelligence version 0.9.2, 2022-06-27
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9.2, 2022-06-27. OpenReview, 2022. 5
2022
-
[19]
Yuanchang Liang, Xiaobo Wang, Kai Wang, Shuo Wang, Xiaojiang Peng, Haoyu Chen, David Kim Huat Chua, and Prahlad Vadakkepat. Adaptive action chunking at inference-time for vision-language-action models.arXiv preprint arXiv:2604.04161, 2026. 2, 3, 16
Pith/arXiv arXiv 2026
-
[20]
Bidi- rectional decoding: Improving action chunking via guided test-time sampling
Yuejiang Liu, Jubayer Ibn Hamid, Annie Xie, Yoonho Lee, Max Du, and Chelsea Finn. Bidi- rectional decoding: Improving action chunking via guided test-time sampling. InProc. ICLR,
-
[21]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorld- Model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026. 2, 3, 5, 7, 14
Pith/arXiv arXiv 2026
-
[22]
Kinetix: Investi- gating the training of general agents through open-ended physics-based control tasks
Michael Matthews, Michael Beukman, Chris Lu, and Jakob Nicolaus Foerster. Kinetix: Investi- gating the training of general agents through open-ended physics-based control tasks. InProc. ICLR, 2025. 2, 6
2025
-
[23]
R2-Dreamer: Redundancy-reduced world models without decoders or augmentation
Naoki Morihira, Amal Nahar, Kartik Bharadwaj, Yasuhiro Kato, Akinobu Hayashi, and Tatsuya Harada. R2-Dreamer: Redundancy-reduced world models without decoders or augmentation. InProc. ICLR, 2026. 2, 3, 5, 6, 7
2026
-
[24]
Chaojun Ni, Cheng Chen, Xiaofeng Wang, Zheng Zhu, Wenzhao Zheng, Boyuan Wang, Tianrun Chen, Guosheng Zhao, Haoyun Li, Zhehao Dong, et al. SwiftVLA: Unlocking spatiotemporal dynamics for lightweight VLA models at minimal overhead.arXiv preprint arXiv:2512.00903,
-
[25]
Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 2
Pith/arXiv arXiv 2024
-
[26]
Chaoyi Pan, Giri Anantharaman, Nai-Chieh Huang, Claire Jin, Daniel Pfrommer, Chenyang Yuan, Frank Permenter, Guannan Qu, Nicholas Boffi, Guanya Shi, et al. Much ado about noising: Dispelling the myths of generative robotic control.arXiv preprint arXiv:2512.01809,
-
[27]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025. 2
Pith/arXiv arXiv 2025
-
[28]
π 0.7: A steerable model with emergent capabilities
Physical Intelligence. π 0.7: A steerable model with emergent capabilities. https://www.pi .website/blog/pi07, 2026. Blog post, accessed April 20, 2026. 1, 2
2026
-
[29]
π∗ 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025. 2
Pith/arXiv arXiv 2025
-
[30]
Testing of feetech sts3215 servomotor: Backlash, repeatability, and torque
Robo9. Testing of feetech sts3215 servomotor: Backlash, repeatability, and torque. https: //robonine.com/testing-of-feetech-sts3215-servomotor-backlash-repeatabi lity-and-torque/, 2025. Accessed: 2026-05-04. 14
2025
-
[31]
Kohei Sendai, Maxime Alvarez, Tatsuya Matsushima, Yutaka Matsuo, and Yusuke Iwasawa. Leave no observation behind: Real-time correction for VLA action chunks.arXiv preprint arXiv:2509.23224, 2025. 2 11
arXiv 2025
-
[32]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. SmolVLA: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025. 2, 6, 8
Pith/arXiv arXiv 2025
-
[33]
Improving generative behavior cloning via self-guidance and adaptive chunking
Junhyuk So, Chiwoong Lee, Shinyoung Lee, Jungseul Ok, and Eunhyeok Park. Improving generative behavior cloning via self-guidance and adaptive chunking. InProc. NeurIPS, 2025. 2, 6
2025
-
[34]
Jiaming Tang, Yufei Sun, Yilong Zhao, Shang Yang, Yujun Lin, Zhuoyang Zhang, James Hou, Yao Lu, Zhijian Liu, and Song Han. Vlash: Real-time vlas via future-state-aware asynchronous inference.arXiv preprint arXiv:2512.01031, 2025. 2, 6
arXiv 2025
-
[35]
Basile Terver, Randall Balestriero, Megi Dervishi, David Fan, Quentin Garrido, Tushar Nagara- jan, Koustuv Sinha, Wancong Zhang, Mike Rabbat, Yann LeCun, et al. A lightweight library for energy-based joint-embedding predictive architectures.arXiv preprint arXiv:2602.03604,
-
[36]
Yilin Wu, Ran Tian, Gokul Swamy, and Andrea Bajcsy. From foresight to forethought: VLM- in-the-loop policy steering via latent alignment.arXiv preprint arXiv:2502.01828, 2025. 3
arXiv 2025
-
[37]
DynamicVLA: A vision-language-action model for dynamic object manipulation
Haozhe Xie, Beichen Wen, Jiarui Zheng, Zhaoxi Chen, Fangzhou Hong, Haiwen Diao, and Ziwei Liu. DynamicVLA: A vision-language-action model for dynamic object manipulation. arXiv preprint arXiv:2601.22153, 2026. 2
arXiv 2026
-
[38]
Precise manipulation with efficient online RL
Charles Xu, Jost Tobias Springenberg, Michael Equi, Ali Amin, Adnan Esmail, Sergey Levine, and Liyiming Ke. Precise manipulation with efficient online RL. https://www.pi.website /research/rlt, 2026. Research blog post, accessed April 20, 2026. 2
2026
-
[39]
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. GigaWorld-Policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026. 1, 3
arXiv 2026
-
[40]
Jiyao Zhang, Zimu Han, Junhan Wang, Xionghao Wu, Shihong Lin, Jinzhou Li, Hongwei Fan, Ruihai Wu, Dongjiang Li, and Hao Dong. HiPolicy: Hierarchical multi-frequency action chunking for policy learning.arXiv preprint arXiv:2604.06067, 2026. 3
Pith/arXiv arXiv 2026
-
[41]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProc. RSS, 2023. 2
2023
-
[42]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InProc. CoRL, 2023. 1, 2 12 A1 Technical appendices and supplementary material A1.1 Additional Experiment Results 1 2 3 4 5 6 7 Execute Horizon 0.6...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.