Distributed Persistence Domain for Persistent Memory Pooling
Pith reviewed 2026-06-27 20:06 UTC · model grok-4.3
The pith
Distributed persistence domains let CXL switches support pooled persistent memory with lower latency while preserving crash consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Distributed Persistence Domain abstraction formalizes the hazards of distributed persistence in CXL fabrics and supplies the minimal requirements that let a Persistent CXL Switch reduce persist latency, enable read forwarding, and coalesce writes while still guaranteeing crash consistency.
What carries the argument
The Distributed Persistence Domain (DPD) abstraction, which identifies stale-read and stale-write hazards and derives the coordination rules needed when persistence logic is placed inside CXL switches.
If this is right
- Persist operations no longer traverse the full CXL fabric, directly lowering latency.
- Read forwarding at the switch becomes safe under the stated coordination rules.
- Writes can be coalesced at the switch without violating persistence ordering.
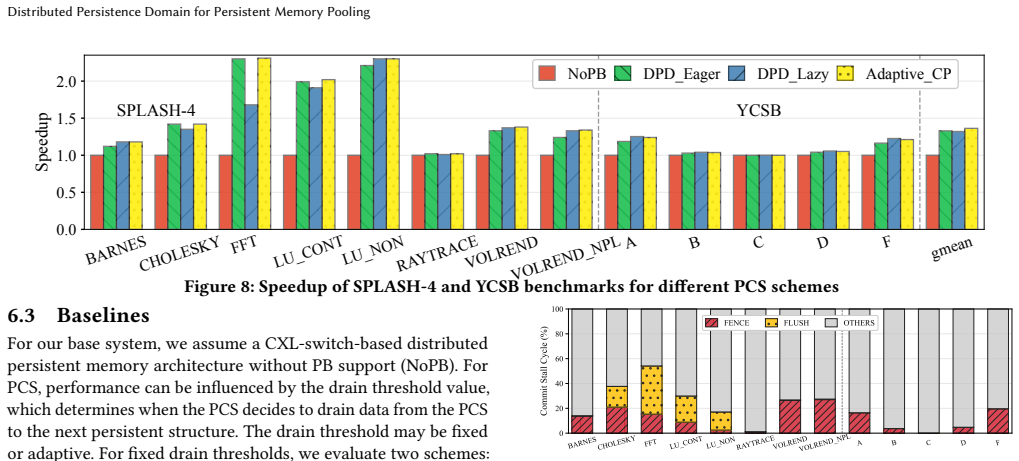
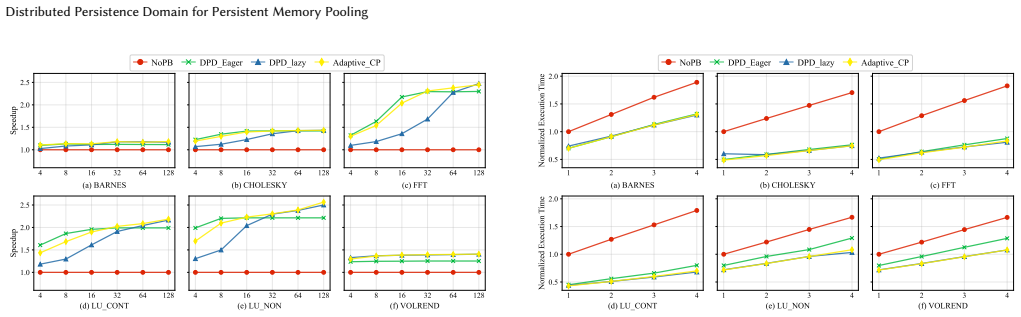
- Average performance improves 33 percent over volatile CXL switches across the evaluated workloads.
- Crash consistency holds even though persistence logic is no longer centralized.
Where Pith is reading between the lines
- The same hazard-analysis approach could be applied to other disaggregated interconnects that want to move persistence closer to memory.
- Real silicon would still need to confirm that no protocol-level corner cases exist beyond those captured in the simulation model.
- The design opens the possibility of larger-scale persistent memory pools whose size is no longer limited by centralized persistence-domain latency.
Load-bearing premise
The design requirements derived from the DPD analysis are sufficient to guarantee correctness and crash consistency when persistence support is moved into distributed CXL switches, without introducing unmodeled hazards or overheads in real hardware deployments.
What would settle it
A workload run or crash-recovery test that produces a stale read or write in the Persistent CXL Switch would show that the derived requirements do not fully preserve consistency.
Figures





read the original abstract
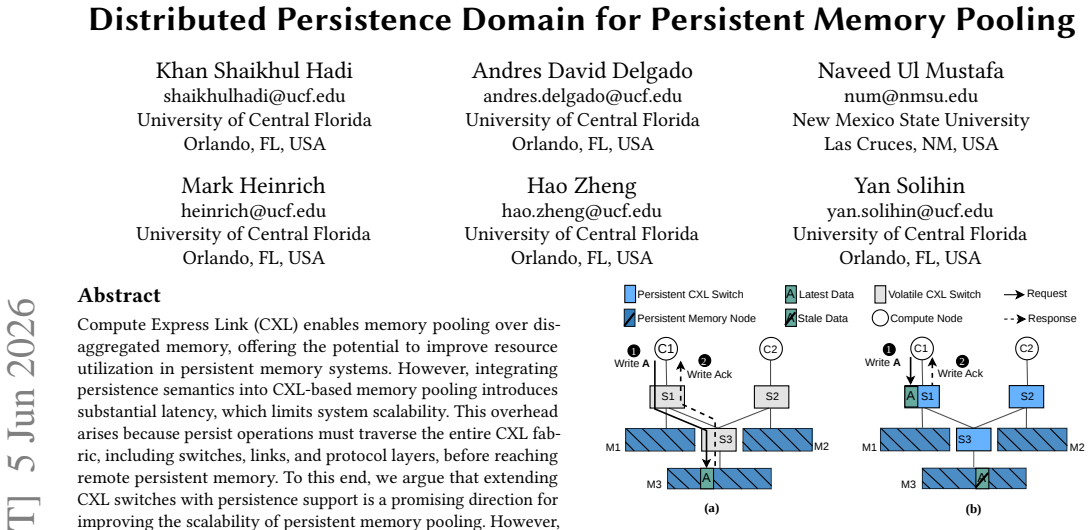
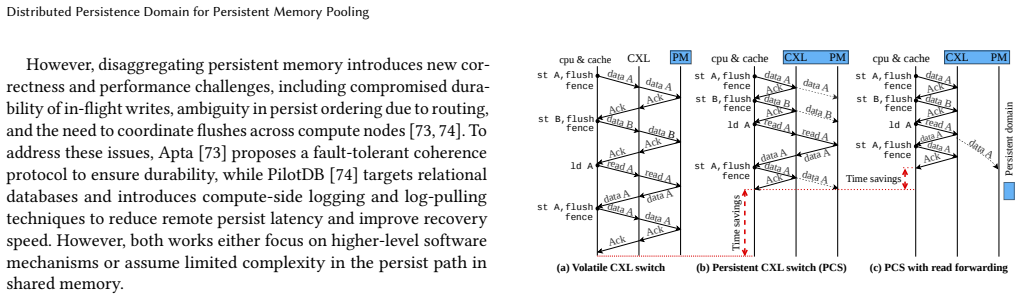
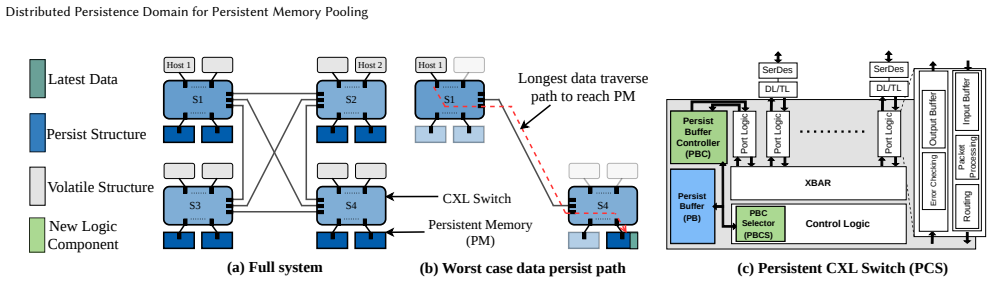
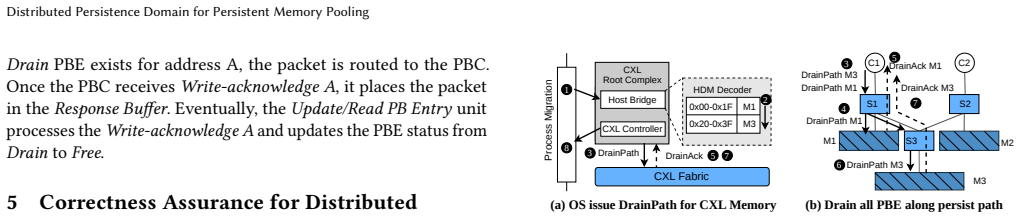
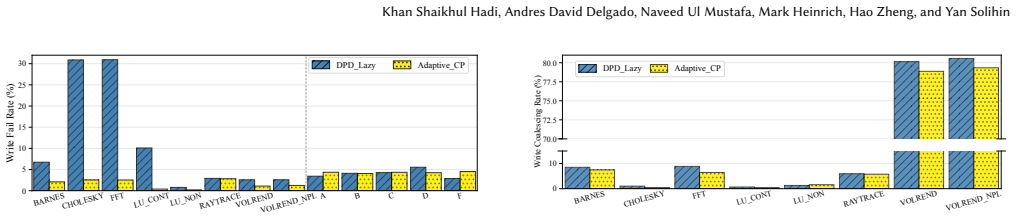
Compute Express Link (CXL) enables memory pooling over disaggregated memory, offering the potential to improve resource utilization in persistent memory systems. However, integrating persistence semantics into CXL-based memory pooling introduces substantial latency, which limits system scalability. This overhead arises because persist operations must traverse the entire CXL fabric, including switches, links, and protocol layers, before reaching remote persistent memory. To this end, we argue that extending CXL switches with persistence support is a promising direction for improving the scalability of persistent memory pooling. However, moving persistence support into the network breaks the traditional correctness assumptions of centralized persistence domains. In particular, enabling persistence within distributed structures, such as CXL switches, can introduce stale reads and writes if not carefully coordinated. In this paper, we propose Distributed Persistence Domain (DPD), a new abstraction for persistent memory pooling that enables persistence support at the CXL switch level. We first formalize the concept of a distributed persistence domain and use DPD as a framework to identify the correctness hazards that arise when persistence structures are distributed across the CXL fabric. Based on this analysis, we derive the design requirements needed to guarantee correctness. Building on these insights, we present Persistent CXL Switch, a CXL switch architecture that incorporates persistence support to significantly reduce persist latency, enable read forwarding, and coalesce writes, while preserving correctness and crash consistency. We evaluated our system design using both SPLASH-4 and YCSB benchmarks. Simulation results show an average speedup of 33% over volatile CXL switches, and up to 36% speedup with read forwarding optimization across all workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Distributed Persistence Domain (DPD) abstraction for CXL-based persistent memory pooling. It formalizes DPD to identify correctness hazards such as stale reads and writes when persistence is distributed across CXL switches, derives design requirements from this analysis, and proposes the Persistent CXL Switch architecture that incorporates persistence support to reduce persist latency, enable read forwarding, and coalesce writes while maintaining crash consistency. Evaluation using SPLASH-4 and YCSB benchmarks in simulation shows an average 33% speedup over volatile CXL switches, with up to 36% with read forwarding.
Significance. If the DPD framework accurately captures all distributed persistence hazards and the Persistent CXL Switch design satisfies the derived requirements without unmodeled issues, this work could significantly improve the scalability and performance of persistent memory systems over CXL fabrics by moving persistence logic closer to the network. The simulation results provide initial evidence of performance benefits, though the absence of correctness validation in the reported experiments limits the strength of the claims.
major comments (1)
- [Abstract and Evaluation] Abstract and Evaluation: The simulation results report only performance speedups (average 33%, up to 36% with read forwarding) but contain no description of experiments that exercise or validate crash consistency against the stale read/write hazards identified by the DPD analysis. Because the central claim is that the Persistent CXL Switch preserves correctness while delivering these gains, the lack of any reported failure-mode testing or hazard-mitigation verification is a load-bearing gap.
minor comments (1)
- [Abstract] Abstract: Workload coverage, number of runs, and presence/absence of error bars or variance measures are not stated, making it difficult to assess the robustness of the reported speedups.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The observation regarding the lack of explicit crash-consistency validation is valid and we address it directly below.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation: The simulation results report only performance speedups (average 33%, up to 36% with read forwarding) but contain no description of experiments that exercise or validate crash consistency against the stale read/write hazards identified by the DPD analysis. Because the central claim is that the Persistent CXL Switch preserves correctness while delivering these gains, the lack of any reported failure-mode testing or hazard-mitigation verification is a load-bearing gap.
Authors: We agree that the current evaluation section reports only performance results and does not describe dedicated experiments that inject the stale-read and stale-write hazards identified by the DPD analysis. The manuscript argues correctness by construction: the DPD formalization enumerates the hazards, derives the minimal requirements (atomic persistence ordering, forwarding coherence, and write coalescing under crash), and the Persistent CXL Switch is shown to satisfy each requirement through its protocol extensions. Nevertheless, we acknowledge that an explicit verification campaign would strengthen the central claim. In the revised manuscript we will add a new subsection (Evaluation: Correctness Validation) that describes targeted simulation experiments: (1) controlled injection of link delays and switch failures to trigger potential stale reads, (2) concurrent persist and read workloads that could produce stale writes, and (3) post-crash recovery checks confirming that no hazard manifests when the design invariants hold. These experiments will be run on the same SPLASH-4 and YCSB workloads plus micro-benchmarks crafted to stress the identified corner cases. We will also clarify in the abstract and introduction that correctness is established both analytically via DPD and empirically via the new validation suite. revision: yes
Circularity Check
No circularity; design derives from independent hazard analysis without reduction to inputs or self-citations.
full rationale
The paper formalizes DPD to identify hazards (stale reads/writes) when distributing persistence, derives requirements for correctness/crash consistency, and proposes Persistent CXL Switch to satisfy them, with simulation results for performance. No equations, fitted parameters, or self-citations appear in the provided text; the chain is a standard analysis-to-requirements-to-design flow that does not reduce by construction to its own inputs. The correctness claim rests on the sufficiency of derived requirements rather than any enumerated circular pattern.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Distributed Persistence Domain (DPD)
no independent evidence
-
Persistent CXL Switch
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Intel®64 and IA-32 Architectures Software Developer’s Manual. Volume 2A: Instruction Set Reference.Order Number: 325383-077US([n. d.])
-
[2]
[n. d.]. Persistent Memory Development Kit (PMDK). https://pmem.io/pmdk/
-
[3]
[n. d.]. Samsung Electronics Unveils Far-Reaching, Next-Generation Memory Solutions at Flash Memory Summit 2022. https: //news.samsung.com/global/samsung-electronics-unveils-far-reaching- next-generation-memory-solutions-at-flash-memory-summit-2022
2022
-
[4]
Intel®Optane™Persistent Memory 200 Series Brief
2018. Intel®Optane™Persistent Memory 200 Series Brief. https: //investors.micron.com/news-releases/news-release-details/micron-and- intel-announce-update-3d-xpointtm-joint-development
2018
-
[5]
eADR: New Opportunities for Persistent Memory Applica- tions
2021. eADR: New Opportunities for Persistent Memory Applica- tions. https://www.intel.com/content/www/us/en/developer/articles/technical/ eadr-new-opportunities-for-persistent-memory-applications.html
2021
-
[6]
Hasan Al Maruf and Mosharaf Chowdhury. 2023. Memory disaggregation: advances and open challenges.SIGOPS Oper. Syst. Rev.57, 1 (June 2023), 29–37. https://doi.org/10.1145/3606557.3606562
-
[7]
Alshboul, Prakash Ramrakhyani, William Wang, James Tuck, and Yan Solihin
Mohammad A. Alshboul, Prakash Ramrakhyani, William Wang, James Tuck, and Yan Solihin. 2021. BBB: Simplifying Persistent Programming Using Battery- Backed Buffers. InProceedings of the 27th IEEE International Symposium on High-Performance Computer Architecture (HPCA). 111–124
2021
-
[8]
ARM. [n. d.]. Arm®Architecture Reference Manual for A-profile architecture. https://developer.arm.com/documentation/ddi0487/ha/
-
[9]
Ashby, Pedro Díaz, and Marcelo Cintra
Thomas J. Ashby, Pedro Díaz, and Marcelo Cintra. 2011. Software-Based Cache Coherence with Hardware-Assisted Selective Self-Invalidations Using Bloom Filters.IEEE Trans. Comput.60, 4 (2011). https://doi.org/10.1109/TC.2010.155
-
[10]
Gal Assa, Lucas Bürgi, Michal Friedman, and Ori Lahav. 2025. A Programming Model for Disaggregated Memory over CXL. arXiv:2407.16300 [cs.DC]
arXiv 2025
-
[11]
Gal Assa, Moritz Lumme, Lucas Bürgi, Michal Friedman, and Ori Lahav. 2026. A programming model for disaggregated memory over CXL. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 41–58
2026
-
[12]
Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R
Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K. Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R. Hower, Tushar Krishna, Somayeh Sardashti, Rathijit Sen, Korey Sewell, Muhammad Shoaib, Nilay Vaish, Mark D. Hill, and David A. Wood. 2011. The gem5 simulator.SIGARCH Comput. Archit. News39, 2 (Aug. 2011), 1–7. https://doi.org/10.1145/2...
-
[13]
David Boles, Daniel Waddington, and David A. Roberts. 2023. CXL-Enabled Enhanced Memory Functions.IEEE Micro43, 2 (2023), 58–65
2023
-
[14]
Tony Brewer and Nathan Kalyanasundharam. 2022. CXL3 Fabric – Introduction and use cases. InHot Chips. https://hc34.hotchips.org/assets/program/ tutorials/CXL/Hot%20Chips%202022%20CXL3%20Fabric%20Intro%20and% 20use%20cases.pdf
2022
-
[15]
Miao Cai, Junru Shen, and Baoliu Ye. 2024. Ethane: An asymmetric file system for disaggregated persistent memory. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 191–207. https:// www.usenix.org/conference/atc24/presentation/cai
2024
-
[16]
Andreas Chatzistergiou, Marcelo Cintra, and Stratis D Viglas. 2015. Rewind: Recovery write-ahead system for in-memory non-volatile data-structures.Pro- ceedings of the VLDB Endowment (PVLDB)8, 5 (2015), 497–508
2015
-
[17]
Byn Choi, Rakesh Komuravelli, Hyojin Sung, Robert Smolinski, Nima Hon- armand, Sarita V. Adve, Vikram S. Adve, Nicholas P. Carter, and Ching-Tsun Chou. 2011. DeNovo: Rethinking the Memory Hierarchy for Disciplined Paral- lelism. In2011 International Conference on Parallel Architectures and Compilation Techniques. 155–166. https://doi.org/10.1109/PACT.2011.21
-
[18]
Joel Coburn, Adrian M Caulfield, Ameen Akel, Laura M Grupp, Rajesh K Gupta, Ranjit Jhala, and Steven Swanson. 2011. NV-Heaps: Making persistent objects fast and safe with next-generation, non-volatile memories.ACM SIGARCH Computer Architecture News39, 1 (2011), 105–118
2011
-
[19]
Adrian Colaso, Pablo Prieto, Jose Angel Herrero, Pablo Abad, Lucia G Menezo, Valentin Puente, and Jose Angel Gregorio. 2017. Memory Hierarchy Char- acterization of NoSQL Applications through Full-System Simulation.IEEE Transactions on Parallel and Distributed Systems29, 5 (2017), 1161–1173
2017
-
[20]
Compute Express Link Consortium. 2024. Compute Express Link ® (CXL®) Specification, Revision 3.2 Version 1.0. https://computeexpresslink.org/wp- content/uploads/2024/11/CXL-Specification_rev3p2_ver1p0_2024October2_ evalcopy.pdf
2024
-
[21]
Brian F Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010. Benchmarking cloud serving systems with YCSB. InProceedings of the 1st ACM symposium on Cloud computing. 143–154
2010
-
[22]
Debendra Das Sharma, Robert Blankenship, and Daniel Berger. 2024. An Intro- duction to the Compute Express Link (CXL) Interconnect.ACM Comput. Surv. 56, 11, Article 290 (2024), 37 pages. https://doi.org/10.1145/3669900
-
[23]
Nan Ding, Pieter Maris, Hai Ah Nam, Taylor Groves, Muaaz Gul Awan, LeAnn Lindsey, Christopher Daley, Oguz Selvitopi, Leonid Oliker, Nicholas Wright, and Samuel Williams. 2024. Evaluating the potential of disaggregated memory systems for HPC applications.Concurrency and Computation: Practice and Experience36, 19 (2024), e8147
2024
-
[24]
Zhuohui Duan, Haodi Lu, Haikun Liu, Xiaofei Liao, Hai Jin, Yu Zhang, and Song Wu. 2021. Hardware-Supported Remote Persistence for Distributed Persistent Memory. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). 1–14
2021
-
[25]
Hussein Elnawawy, Mohammad Alshboul, James Tuck, and Yan Solihin. 2017. Efficient Checkpointing of Loop Based Codes for Non Volatile Main Mem- ory. In26th International Conference on Parallel Architectures and Compilation Techniques (PACT). 318–329. https://doi.org/10.1109/PACT.2017.58
-
[26]
David Fiala, Frank Mueller, Kurt Ferreira, and Christian Engelmann. 2016. Mini- Ckpts: Surviving OS Failures in Persistent Memory. InProceedings of the 2016 International Conference on Supercomputing(Istanbul, Turkey)(ICS ’16). As- sociation for Computing Machinery, New York, NY, USA, Article 7, 14 pages. https://doi.org/10.1145/2925426.2926295
-
[27]
Brad Fitzpatrick and Anatoly Vorobey. 2011. Memcached: a distributed memory object caching system. https://memcached.org
2011
-
[28]
Alexander Freij, Huiyang Zhou, and Yan Solihin. 2023. Secpb: Architectures for secure non-volatile memory with battery-backed persist buffers. InIEEE International Symposium on High-Performance Computer Architecture (HPCA). 677–690. https://doi.org/10.1109/HPCA56546.2023.10071082
-
[29]
Yehonatan Fridman, Suprasad Mutalik Desai, Navneet Singh, Thomas Willhalm, and Gal Oren. 2023. CXL Memory as Persistent Memory for Disaggregated HPC: A Practical Approach. InProceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis (SC-W). 983–994. https://doi.org/10.1145/3624062.3624175
-
[30]
Yehonatan Fridman, Yaniv Snir, Matan Rusanovsky, Kfir Zvi, Harel Levin, Danny Hendler, Hagit Attiya, and Gal Oren. 2021. Assessing the use cases of persistent memory in high-performance scientific computing. In2021 IEEE/ACM 11th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS). IEEE, 11–20
2021
-
[31]
Marina García, Enrique Vallejo, Ramón Beivide, Miguel Odriozola, Cristóbal Camarero, Mateo Valero, Germ’n Rodríguez, Jesús Labarta, and Cyriel Minken- berg. 2012. On-the-Fly Adaptive Routing in High-Radix Hierarchical Net- works. In2012 41st International Conference on Parallel Processing. 279–288. https://doi.org/10.1109/ICPP.2012.46
-
[32]
Eduardo Jose Gomez-Hernandez, Ruixiang Shao, Christos Sakalis, Stefanos Kaxiras, and Alberto Ros. 2021. Splash-4: Improving Scalability with Lock-Free Constructs. InIEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). https://doi.org/10.1109/ispass51385.2021.00044
-
[33]
Taylor Liles Groves, Ryan E Grant, Aaron Gonzales, and Dorian Arnold. 2017. Unraveling Network-Induced Memory Contention: Deeper Insights with Ma- chine Learning.IEEE Transactions on Parallel and Distributed Systems (TPDS) 29, 8 (2017), 1907–1922. https://doi.org/10.1109/TPDS.2017.2773483
-
[34]
Juncheng Gu, Youngmoon Lee, Yiwen Zhang, Mosharaf Chowdhury, and Kang G Shin. 2017. Efficient Memory Disaggregation with Infiniswap. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI). 649–667
2017
-
[35]
Yutong Guo, Conan Truong, and Brian Demsky. 2026. CXLMC: Model Checking CXL Shared Memory Programs. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 546–562
2026
-
[36]
Anoop Gupta, Wolf-Dietrich Weber, and Todd Mowry. [n. d.]. Reducing memory and traffic requirements for scalable directory-based cache coherence schemes. InScalable shared memory multiprocessors. Springer, 167–192
-
[37]
Khan Shaikhul Hadi, Naveed Ul Mustafa, Mark Heinrich, and Yan Solihin
-
[38]
In60th ACM/IEEE Design Automation Conference (DAC)
Hardware Support for Durable Atomic Instructions for Persistent Parallel 12 Distributed Persistence Domain for Persistent Memory Pooling Programming. In60th ACM/IEEE Design Automation Conference (DAC). https: //doi.org/10.1109/DAC56929.2023.10247729
-
[39]
Hyungkyu Ham, Jeongmin Hong, Geonwoo Park, Yunseon Shin, Okkyun Woo, Wonhyuk Yang, Jinhoon Bae, Eunhyeok Park, Hyojin Sung, Euicheol Lim, et al. 2024. Low-overhead general-purpose near-data processing in cxl memory expanders. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 594–611
2024
-
[40]
Xijing Han, James Tuck, and Amro Awad. 2022. Horus: Persistent Security for Extended Persistence-Domain Memory Systems. InProceedings of the 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). 1255–1269
2022
-
[41]
Blake A Hechtman and Daniel J Sorin. 2012. The limits of concurrency in cache coherence. InProceedings of the Workshop on Duplicating, Deconstructing and Debunking (WDDD’12)
2012
-
[42]
Xing Hu and A Matheus. 2018. Persistence parallelism optimization: A holis- tic approach from memory bus to rdma network. InIEEE/ACM International Symposium on Microarchitecture (MICRO)
2018
-
[43]
Yibo Huang, Haowei Chen, Newton Ni, Yan Sun, Vijay Chidambaram, Dixin Tang, and Emmett Witchel. 2025. Tigon: A Distributed Database for a CXL Pod. InProceedings of the 19th USENIX Conference on Operating Systems Design and Implementation (OSDI ’25). USENIX Association, USA, Article 7, 20 pages
2025
-
[44]
Jaehyuk Huh, Jichuan Chang, Doug Burger, and Gurindar S. Sohi. 2004. Coher- ence decoupling: making use of incoherence. InProceedings of the 11th Interna- tional Conference on Architectural Support for Programming Languages and Oper- ating Systems(Boston, MA, USA)(ASPLOS XI). Association for Computing Ma- chinery, New York, NY, USA, 97–106. https://doi.or...
-
[45]
Joseph Izraelevitz, Terence Kelly, and Aasheesh Kolli. 2016. Failure-Atomic Persistent Memory Updates via JUSTDO Logging.ACM SIGARCH Computer Architecture News44, 2 (2016), 427–442
2016
-
[46]
Arpit Joshi, Vijay Nagarajan, Marcelo Cintra, and Stratis Viglas. 2015. Efficient persist barriers for multicores. InProceedings of the 48th International Symposium on Microarchitecture (MICRO-48). Association for Computing Machinery, New York, NY, USA, 660–671. https://doi.org/10.1145/2830772.2830805
-
[47]
Arpit Joshi, Vijay Nagarajan, Stratis Viglas, and Marcelo Cintra. 2017. ATOM: Atomic Durability in Non-volatile Memory through Hardware Logging. InIEEE International Symposium on High Performance Computer Architecture (HPCA). 361–372. https://doi.org/10.1109/HPCA.2017.50
-
[48]
Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2014. Using RDMA efficiently for key-value services, In Proceedings of the 2014 ACM conference on SIGCOMM (SIGCOMM).SIGCOMM Comput. Commun. Rev.https://doi.org/ 10.1145/2740070.2626299
-
[49]
Sajad Karim, Johannes Wünsche, Michael Kuhn, Gunter Saake, and David Broneske. 2025. NVM in Data Storage: A Post-Optane Future.ACM Trans. Storage21, 3, Article 23, 85 pages. https://doi.org/10.1145/3731454
-
[50]
Rajat Kateja, Nathan Beckmann, and Gregory R. Ganger. 2020. TVARAK: Software-Managed Hardware Offload for Redundancy in Direct-Access NVM Storage. In2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). 624–637. https://doi.org/10.1109/ISCA45697.2020.00058
-
[51]
Stefanos Kaxiras and Georgios Keramidas. 2010. SARC Coherence: Scaling Directory Cache Coherence in Performance and Power.IEEE Micro30, 5 (2010), 54–65. https://doi.org/10.1109/MM.2010.82
-
[52]
Stefanos Kaxiras, David Klaftenegger, Magnus Norgren, Alberto Ros, and Kon- stantinos Sagonas. 2015. Turning Centralized Coherence and Distributed Critical-Section Execution on their Head: A New Approach for Scalable Dis- tributed Shared Memory. InProceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing (HPDC ...
-
[53]
Stefanos Kaxiras and Alberto Ros. 2012. Efficient, snoopless, System-on-Chip coherence. In2012 IEEE International SOC Conference. 230–235. https://doi.org/ 10.1109/SOCC.2012.6398353
-
[54]
Wook-Hee Kim, Jinwoong Kim, Woongki Baek, Beomseok Nam, and Youjip Won. 2016. NVWAL: Exploiting NVRAM in write-ahead logging.ACM SIGPLAN Notices51, 4 (2016), 385–398. https://doi.org/10.1145/2954679.2872392
-
[55]
Madhava Krishnan, Diyu Zhou, Wook-Hee Kim, Sudarsun Kannan, Sanidhya Kashyap, and Changwoo Min
R. Madhava Krishnan, Diyu Zhou, Wook-Hee Kim, Sudarsun Kannan, Sanidhya Kashyap, and Changwoo Min. 2023. TENET: Memory Safe and Fault Tolerant Persistent Transactional Memory. In21st USENIX Conference on File and Storage Technologies (FAST 23). USENIX Association, Santa Clara, CA, 247–264. https: //www.usenix.org/conference/fast23/presentation/krishnan
2023
-
[56]
Alvin R. Lebeck and David A. Wood. 1995. Dynamic self-invalidation: reducing coherence overhead in shared-memory multiprocessors. InProceedings of the 22nd Annual International Symposium on Computer Architecture(S. Margherita Ligure, Italy)(ISCA ’95). Association for Computing Machinery, New York, NY, USA, 48–59. https://doi.org/10.1145/223982.223995
-
[57]
Hyokeun Lee, Kwanseok Choi, Hyuk-Jae Lee, and Jaewoong Sim. 2023. SDM: Sharing-enabled disaggregated memory system with cache coherent compute express link. In2023 32nd International Conference on Parallel Architectures and Compilation Techniques (PACT). IEEE, 86–98
2023
-
[58]
Aguilera, Kimberly Keeton, and Vijay Chidambaram
Sekwon Lee, Soujanya Ponnapalli, Sharad Singhal, Marcos K. Aguilera, Kimberly Keeton, and Vijay Chidambaram. 2022. DINOMO: An Elastic, Scalable, High- Performance Key-Value Store for Disaggregated Persistent Memory (Extended Version). (2022). arXiv:2209.08743 [cs.DC]
arXiv 2022
-
[59]
Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, and Ricardo Bianchini. 2023. Pond: CXL-Based Memory Pooling Systems for Cloud Platforms. InProceedings of the 28th ACM Inter- national Conference on Architectural Support for Pro...
-
[60]
Tianxi Li, Dipti Shankar, Shashank Gugnani, and Xiaoyi Lu. 2020. RDMP-KV: Designing Remote Direct Memory Persistence based Key-Value Stores with PMEM. InInternational Conference for High Performance Computing, Networking, Storage and Analysis (SC). IEEE, 1–14
2020
-
[61]
Kevin Lim, Yoshio Turner, Jose Renato Santos, Alvin AuYoung, Jichuan Chang, Parthasarathy Ranganathan, and Thomas F Wenisch. 2012. System-level im- plications of disaggregated memory. InIEEE International Symposium on High- Performance Comp Architecture. IEEE, 1–12
2012
-
[62]
Jinshu Liu, Hamid Hadian, Yuyue Wang, Daniel S Berger, Marie Nguyen, Xun Jian, Sam H Noh, and Huaicheng Li. 2025. Systematic cxl memory charac- terization and performance analysis at scale. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1203–1217
2025
-
[63]
Ling Liu, Wenqi Cao, Semih Sahin, Qi Zhang, Juhyun Bae, and Yanzhao Wu
-
[64]
In2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS)
Memory Disaggregation: Research Problems and Opportunities. In2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). 1664–1673. https://doi.org/10.1109/ICDCS.2019.00165
-
[65]
Sihang Liu, Korakit Seemakhupt, Yizhou Wei, Thomas Wenisch, Aasheesh Kolli, and Samira Khan. 2020. Cross-Failure Bug Detection in Persistent Memory Programs. InProceedings of the Twenty-Fifth International Confer- ence on Architectural Support for Programming Languages and Operating Sys- tems (ASPLOS). Association for Computing Machinery, 1187–1202. https...
-
[66]
Jason Lowe-Power, Abdul Mutaal Ahmad, Ayaz Akram, Mohammad Alian, Rico Amslinger, Matteo Andreozzi, Adrià Armejach, Nils Asmussen, Brad Beckmann, Srikant Bharadwaj, et al . 2020. The gem5 simulator: Version 20.0+.arXiv preprint arXiv:2007.03152(2020). arXiv:2007.03152 [cs.AR]
arXiv 2020
-
[67]
Youyou Lu, Jiwu Shu, Long Sun, and Onur Mutlu. 2014. Loose-Ordering Consis- tency for persistent memory. InIEEE 32nd International Conference on Computer Design (ICCD). 216–223. https://doi.org/10.1109/ICCD.2014.6974684
-
[68]
Teng Ma, Zheng Liu, Chengkun Wei, Jialiang Huang, Youwei Zhuo, Haoyu Li, Ning Zhang, Yijin Guan, Dimin Niu, Mingxing Zhang, and Tao Ma. 2024. HydraRPC: RPC in the CXL Era. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 387–395. https:// www.usenix.org/conference/atc24/presentation/ma
2024
-
[69]
Teng Ma, Mingxing Zhang, Kang Chen, Zhuo Song, Yongwei Wu, and Xuehai Qian. 2020. AsymNVM: An Efficient Framework for Implementing Persis- tent Data Structures on Asymmetric NVM Architecture. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 757–773
2020
-
[70]
Justin Meza, Qiang Wu, Sanjev Kumar, and Onur Mutlu. 2015. A Large-Scale Study of Flash Memory Failures in the Field. InProceedings of the 2015 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems (SIGMETRICS ’15). Association for Computing Machinery, New York, NY, USA, 177–190. https://doi.org/10.1145/2745844.2745848
-
[71]
Dushyanth Narayanan and Orion Hodson. 2012. Whole-system persistence. In Proceedings of the seventeenth international conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 401–410
2012
-
[72]
Mahesh Natu and Thomas Won Ha Choi. 2021. Compute Express Link™ (CXL™): Supporting Persistent Memory. https://computeexpresslink.org/wp- content/uploads/2023/12/CXL-2.0-Presentation-Persistent-Memory- 20210615_FINAL.pdf
2021
-
[73]
João Oliveira, João Gonçalves, and Miguel Matos. 2025. Rethinking PM Crash Consistency in the CXL Era. (2025). arXiv:2504.17554 [cs.ET]
arXiv 2025
-
[74]
Xiaoyue Pan and Bengt Jonsson. 2014. Modeling cache coherence misses on multicores. In2014 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). https://doi.org/10.1109/ISPASS.2014.6844465
-
[75]
Adarsh Patil, Vijay Nagarajan, Nikos Nikoleris, and Nicolai Oswald. 2023. Apta: Fault-Tolerant Object-Granular CXL Disaggregated Memory for Accelerating FaaS. InProceedings of the 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 119–131
2023
-
[76]
Chaoyi Ruan, Yingqiang Zhang, Chao Bi, Xiaosong Ma, Hao Chen, Feifei Li, Xinjun Yang, Cheng Li, Ashraf Aboulnaga, and Yinlong Xu. 2023. Persistent Memory Disaggregation for Cloud-Native Relational Databases. InProceed- ings of the 28th ACM International Conference on Architectural Support for Pro- gramming Languages and Operating Systems (ASPLOS 2023, Vol...
-
[77]
Andy Rudoff. 2017. Persistent Memory Programming.Login: The Usenix Magazine42, 2 (2017), 34–40. 13 Khan Shaikhul Hadi, Andres David Delgado, Naveed Ul Mustafa, Mark Heinrich, Hao Zheng, and Yan Solihin
2017
-
[78]
Andy Rudoff. 2020. Persistent memory programming without all that cache flushing. InStorage Developer Conf (SDC). 1–38
2020
-
[79]
Andy Rudoff. 2022. Persistent Memory on CXL. https://www.snia.org/ educational-library/persistent-memory-cxl-2021
2022
-
[80]
2020.Programming Persistent Memory: A Comprehensive Guide for Developers
Steve Scargall. 2020.Programming Persistent Memory: A Comprehensive Guide for Developers. Apress, Berkeley, CA, Chapter Persistent Memory Architecture, 11–30. https://doi.org/10.1007/978-1-4842-4932-1_2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.