DPIFrame: A Dual-Level Parallelism Acceleration Framework for CTR Model Inference
Pith reviewed 2026-06-26 13:40 UTC · model grok-4.3
The pith
DPIFrame accelerates CTR model inference on GPU by using dual-level parallelism, anticipatory embedding lookup, and breadth-first stream scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
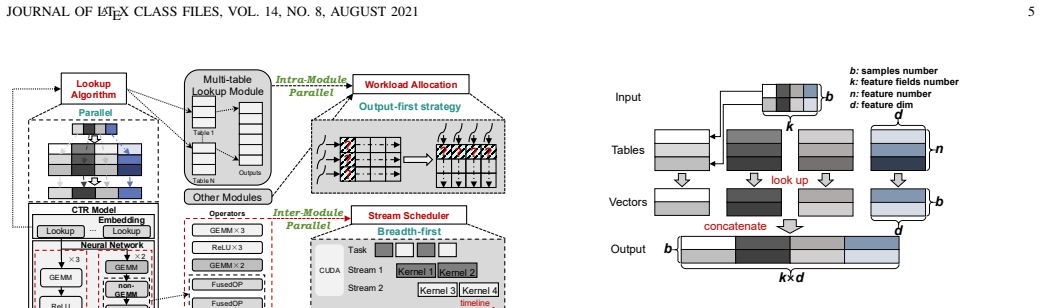
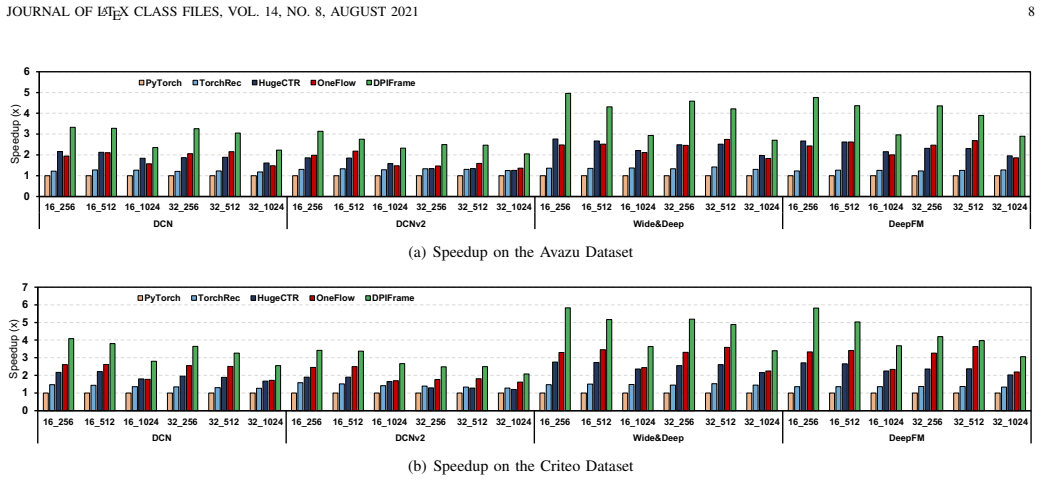
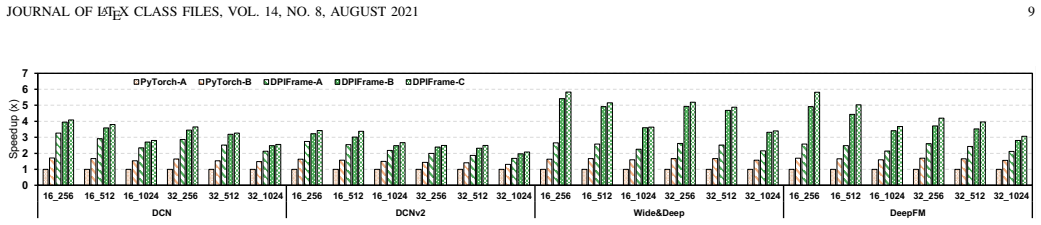
DPIFrame is the first dual parallelizable framework for CTR model inference. It performs parallel execution in both intra-module and inter-module settings via a dual parallelizable architecture, anticipates the full embedding workload for efficient multi-table lookup, and applies breadth-first stream scheduling to enable fine-grained parallel computation management on GPU. Experiments on two real-world datasets show embedding latency reduced by 23.0 times versus PyTorch and overall speedups of 5.83 times, 4.29 times, 2.15 times, and 2.0 times versus PyTorch, TorchRec, HugeCTR, and OneFlow respectively.
What carries the argument
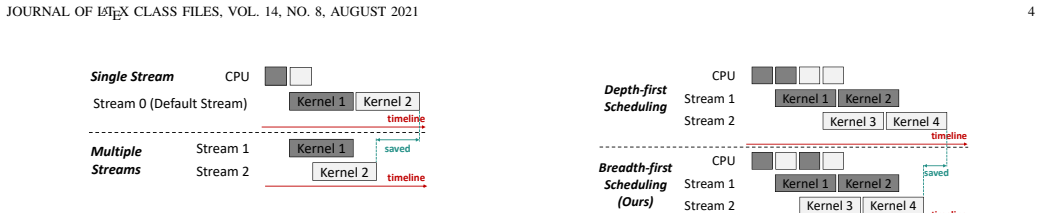
Dual parallelizable architecture that enables parallel CTR model inference at both intra-module and inter-module levels, supported by anticipatory multi-table lookup and breadth-first stream scheduling.
If this is right
- Embedding operations in CTR models can achieve up to 23 times lower latency than standard PyTorch implementations.
- Full model inference can run 5.83 times faster than PyTorch, 4.29 times faster than TorchRec, 2.15 times faster than HugeCTR, and 2.0 times faster than OneFlow on GPU.
- CTR models can be deployed for inference on GPU while preserving the original serial computational pattern through added parallelism layers.
- Fine-grained stream management on GPU becomes feasible for models with irregular module structures.
Where Pith is reading between the lines
- The same anticipatory workload preparation could reduce latency in other embedding-heavy recommendation or ranking models.
- Breadth-first scheduling might transfer to other GPU tasks that mix dense and sparse operations.
- If overhead remains low, the approach could support scaling CTR inference to larger batch sizes without proportional slowdowns.
Load-bearing premise
The dual parallelizable architecture, anticipatory multi-table lookup, and breadth-first stream scheduling can be realized on real CTR models with negligible overhead and without breaking compatibility or accuracy.
What would settle it
A head-to-head test on the same CTR models and hardware where DPIFrame fails to deliver the reported speedups when the dual architecture and scheduling are implemented in a standard framework without custom optimizations.
Figures


read the original abstract
Deep learning technology has enhanced the ability of Click-through rate (CTR) prediction models to learn features and improve prediction accuracy. However, it is challenging to deploy CTR models on GPU smoothly and perform inference efficiently, because there is a huge mismatch between the serial computational pattern and the parallel model structure. In this paper, we propose DPIFrame, the first dual parallelizable framework to accelerate CTR model inference. In DPIFrame, a) a dual parallelizable architecture is proposed to perform parallel CTR model inference in both intra-module and inter-module; b) an efficient multi-table lookup algorithm is presented for embedding operations through anticipating the whole workload in advance; c) a breadth-first stream scheduling strategy is designed for fine-grained management of parallel computation on GPU to further supporting the dual parallel execution. Extensive experiments are conducted on two real-world datasets, and the results highlight that DPIFrame can reduce the embedding latency efficiently by \textbf{23.0$\times$} compared to PyTorch. Compared with PyTorch, TorchRec, HugeCTR, and OneFlow, DPIFrame can achieve state-of-the-art inference performance on GPU with speedups of \textbf{5.83$\times$}, \textbf{4.29$\times$}, \textbf{2.15$\times$}, and \textbf{2.0$\times$}, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DPIFrame, the first dual parallelizable framework for CTR model inference on GPU. It introduces (a) a dual parallelizable architecture supporting intra-module and inter-module parallelism, (b) an anticipatory multi-table lookup algorithm for embedding operations, and (c) a breadth-first stream scheduling strategy. On two real-world datasets the work claims a 23.0× reduction in embedding latency versus PyTorch and end-to-end speedups of 5.83×, 4.29×, 2.15× and 2.0× versus PyTorch, TorchRec, HugeCTR and OneFlow respectively.
Significance. If the reported speedups are substantiated with reproducible experiments, the framework could meaningfully improve GPU deployment of CTR models by exploiting dual-level parallelism and anticipatory scheduling, a combination not previously demonstrated for this workload class.
major comments (3)
- [Abstract] Abstract: the headline speedups (23.0× embedding, 5.83× overall) are presented with no description of the CTR models, the two real-world datasets (cardinality, feature counts, sparsity), batch sizes, hardware, precision, or measurement protocol (including statistical variation). These omissions are load-bearing for any empirical performance claim.
- [Abstract] Abstract / Experimental claims: no ablation is reported that isolates the contribution of anticipatory multi-table lookup or breadth-first scheduling, nor any quantification of synchronization or memory-copy overhead incurred by the dual architecture and CUDA-stream management. Without these data it is impossible to determine whether the stated gains survive realistic implementation costs.
- [Abstract] Abstract: the cross-system comparisons assume identical models, parameters and input batches are executed under PyTorch, TorchRec, HugeCTR and OneFlow, yet the manuscript provides no explicit confirmation that the models were left unmodified or that batching/precision were held constant across baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires additional context to substantiate the reported speedups and will revise it accordingly. We will also strengthen the experimental section with ablations and explicit statements on baseline equivalence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline speedups (23.0× embedding, 5.83× overall) are presented with no description of the CTR models, the two real-world datasets (cardinality, feature counts, sparsity), batch sizes, hardware, precision, or measurement protocol (including statistical variation). These omissions are load-bearing for any empirical performance claim.
Authors: We agree that these details are important for interpreting the claims. The full manuscript already specifies the models (DeepFM, xDeepFM, DIN), dataset statistics, batch sizes (1024–4096), hardware (NVIDIA A100), FP32 precision, and measurement protocol (median of 100 runs after 10 warm-ups) in Sections 4.1–4.2. In the revision we will condense the key elements into the abstract itself. revision: yes
-
Referee: [Abstract] Abstract / Experimental claims: no ablation is reported that isolates the contribution of anticipatory multi-table lookup or breadth-first scheduling, nor any quantification of synchronization or memory-copy overhead incurred by the dual architecture and CUDA-stream management. Without these data it is impossible to determine whether the stated gains survive realistic implementation costs.
Authors: The original submission presents only end-to-end results. We will add a dedicated ablation subsection (new Table 3 and Figure 6) that isolates the latency reduction from anticipatory lookup versus breadth-first scheduling and reports measured CUDA synchronization and host-to-device copy overheads for the dual-module design. This will be included in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the cross-system comparisons assume identical models, parameters and input batches are executed under PyTorch, TorchRec, HugeCTR and OneFlow, yet the manuscript provides no explicit confirmation that the models were left unmodified or that batching/precision were held constant across baselines.
Authors: All baselines used exactly the same model definitions, parameter counts, and input batches; no model modifications were made and both batch size and precision were identical. We will add an explicit paragraph in Section 4.3 confirming these controls and will reference the equivalence in the abstract revision. revision: yes
Circularity Check
No circularity; purely empirical performance claims with no derivations
full rationale
The paper proposes DPIFrame as an engineering framework for GPU-accelerated CTR inference and reports measured speedups (23.0× embedding, 5.83× vs PyTorch, etc.) on two real-world datasets. No equations, parameters, or mathematical derivations appear in the abstract or described content; the central claims rest on implementation and benchmarking rather than any chain that reduces to fitted inputs or self-citations. The architecture descriptions (dual parallelism, anticipatory lookup, breadth-first scheduling) are presented as design choices whose overhead is asserted to be negligible, but these are testable engineering assertions, not self-referential definitions or renamed known results. This is the normal case of a systems paper whose validity is external to any internal derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Click-through rate prediction in online advertising: A literature review
Yanwu Yang and Panyu Zhai. “Click-through rate prediction in online advertising: A literature review”. In:Information Processing & Management59.2 (2022), p. 102853 (cit. on p. 1)
2022
-
[2]
User experience of mobile internet: analysis and recommendations
Eija Kaasinen et al. “User experience of mobile internet: analysis and recommendations”. In:International Journal of Mobile Human Computer Interaction (IJMHCI)1.4 (2009), pp. 4–23 (cit. on p. 1)
2009
-
[3]
A survey of online advertising click-through rate prediction models
Xinfei Wang. “A survey of online advertising click-through rate prediction models”. In:2020 IEEE International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA). V ol. 1. IEEE. 2020, pp. 516–521 (cit. on p. 1)
2020
-
[4]
Embedding optimization for training large-scale deep learning recommendation systems with embark
Shijie Liu et al. “Embedding optimization for training large-scale deep learning recommendation systems with embark”. In:Proceedings of the 18th ACM Conference on Recommender Systems. 2024, pp. 622– 632 (cit. on p. 1)
2024
-
[5]
Ndrec: A near-data processing system for training large-scale recommendation models
Shiyu Li et al. “Ndrec: A near-data processing system for training large-scale recommendation models”. In:IEEE Transactions on Com- puters73.5 (2024), pp. 1248–1261 (cit. on pp. 1, 12)
2024
-
[6]
EENet: An Efficient and Effective Network for Large- Scale CTR Prediction
Dezhi Yi et al. “EENet: An Efficient and Effective Network for Large- Scale CTR Prediction”. In:ACM Transactions on Information Systems (2026) (cit. on p. 1)
2026
-
[7]
A unified framework for multi-domain ctr predic- tion via large language models
Zichuan Fu et al. “A unified framework for multi-domain ctr predic- tion via large language models”. In:ACM Transactions on Information Systems43.5 (2025), pp. 1–33 (cit. on p. 1)
2025
-
[8]
Understanding training efficiency of deep learning recommendation models at scale
Bilge Acun et al. “Understanding training efficiency of deep learning recommendation models at scale”. In:2021 IEEE International Sym- posium on High-Performance Computer Architecture (HPCA). IEEE. 2021, pp. 802–814 (cit. on p. 1)
2021
-
[9]
{OPER}:{Optimality-Guided}Embedding Table Parallelization for Large-scale Recommendation Model
Zheng Wang et al. “{OPER}:{Optimality-Guided}Embedding Table Parallelization for Large-scale Recommendation Model”. In:2024 USENIX Annual Technical Conference (USENIX ATC 24). 2024, pp. 667–682 (cit. on pp. 1, 11)
2024
-
[10]
Evolution of the GPU Device widely used in AI and Massive Parallel Processing
Toru Baji. “Evolution of the GPU Device widely used in AI and Massive Parallel Processing”. In:2018 IEEE 2nd Electron devices technology and manufacturing conference (EDTM). IEEE. 2018, pp. 7–9 (cit. on p. 1)
2018
-
[11]
Adaptive low-precision training for embeddings in click-through rate prediction
Shiwei Li et al. “Adaptive low-precision training for embeddings in click-through rate prediction”. In:Proceedings of the AAAI Confer- ence on Artificial Intelligence. V ol. 37. 4. 2023, pp. 4435–4443 (cit. on pp. 1, 11)
2023
-
[12]
DeepFM: a factorization-machine based neural network for CTR prediction
Huifeng Guo et al. “DeepFM: a factorization-machine based neural network for CTR prediction”. In:Proceedings of the 26th Interna- tional Joint Conference on Artificial Intelligence. 2017, pp. 1725– 1731.DOI: 10.24963/ijcai.2017/239 (cit. on pp. 1, 6, 7, 11)
-
[13]
Deep & cross network for ad click predictions
Ruoxi Wang et al. “Deep & cross network for ad click predictions”. In:Proceedings of the ADKDD’17. 2017, pp. 1–7 (cit. on pp. 1–3, 7, 11)
2017
-
[14]
Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems
Ruoxi Wang et al. “Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems”. In:Pro- ceedings of the web conference 2021. 2021, pp. 1785–1797 (cit. on pp. 1, 3, 6, 7, 11)
2021
-
[15]
Recom: A compiler approach to accelerating recommendation model inference with massive embedding columns
Zaifeng Pan et al. “Recom: A compiler approach to accelerating recommendation model inference with massive embedding columns”. In:Proceedings of the 28th ACM International Conference on Archi- tectural Support for Programming Languages and Operating Systems, Volume 4. 2023, pp. 268–286 (cit. on pp. 1, 11)
2023
-
[16]
BERT4CTR: An Efficient Framework to Combine Pre-trained Language Model with Non-textual Features for CTR Prediction
Dong Wang et al. “BERT4CTR: An Efficient Framework to Combine Pre-trained Language Model with Non-textual Features for CTR Prediction”. In:Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2023, pp. 5039–5050 (cit. on p. 1)
2023
-
[17]
Fragment and Integrate Network (FIN): A Novel Spatial-Temporal Modeling Based on Long Sequential Behav- ior for Online Food Ordering Click-Through Rate Prediction
Jun Li and Ge Zhang. “Fragment and Integrate Network (FIN): A Novel Spatial-Temporal Modeling Based on Long Sequential Behav- ior for Online Food Ordering Click-Through Rate Prediction”. In: Proceedings of the 32nd ACM International Conference on Informa- tion and Knowledge Management. 2023, pp. 4688–4694 (cit. on p. 1)
2023
-
[18]
Recflex: Enabling feature heterogeneity-aware op- timization for deep recommendation models with flexible schedules
Zaifeng Pan et al. “Recflex: Enabling feature heterogeneity-aware op- timization for deep recommendation models with flexible schedules”. In:SC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE. 2024, pp. 1–15 (cit. on pp. 1, 11)
2024
-
[19]
Recpipe: Co-designing models and hardware to jointly optimize recommendation quality and performance
Udit Gupta et al. “Recpipe: Co-designing models and hardware to jointly optimize recommendation quality and performance”. In: MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture. 2021, pp. 870–884 (cit. on p. 1)
2021
-
[20]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke et al. “Pytorch: An imperative style, high-performance deep learning library”. In:Advances in neural information processing systems32 (2019) (cit. on pp. 1, 7)
2019
-
[21]
Agile and accurate CTR prediction model training for massive-scale online advertising systems
Zhiqiang Xu et al. “Agile and accurate CTR prediction model training for massive-scale online advertising systems”. In:Proceedings of the 2021 international conference on management of data. 2021, pp. 2404–2409 (cit. on p. 1)
2021
-
[22]
Deeplight: Deep lightweight feature interactions for accelerating ctr predictions in ad serving
Wei Deng et al. “Deeplight: Deep lightweight feature interactions for accelerating ctr predictions in ad serving”. In:Proceedings of the 14th ACM international conference on Web search and data mining. 2021, pp. 922–930 (cit. on pp. 1, 11)
2021
-
[23]
Single-shot embedding dimension search in rec- ommender system
Liang Qu et al. “Single-shot embedding dimension search in rec- ommender system”. In:Proceedings of the 45th International ACM SIGIR conference on research and development in Information Re- trieval. 2022, pp. 513–522 (cit. on p. 1)
2022
-
[24]
Random Offset Block Embedding (ROBE) for compressed embedding tables in deep learning recommendation systems
Aditya Desai, Li Chou, and Anshumali Shrivastava. “Random Offset Block Embedding (ROBE) for compressed embedding tables in deep learning recommendation systems”. In:Proceedings of Machine Learning and Systems4 (2022), pp. 762–778 (cit. on pp. 1, 11)
2022
-
[25]
Learning compressed embeddings for on- device inference
Niketan Pansare et al. “Learning compressed embeddings for on- device inference”. In:Proceedings of Machine Learning and Systems 4 (2022), pp. 382–397 (cit. on pp. 1, 11)
2022
-
[26]
What do compressed deep neural networks forget?
Sara Hooker et al. “What do compressed deep neural networks forget?” In:arXiv preprint arXiv:1911.05248(2019) (cit. on p. 1)
-
[27]
Distributed hierarchical gpu parameter server for massive scale deep learning ads systems
Weijie Zhao et al. “Distributed hierarchical gpu parameter server for massive scale deep learning ads systems”. In:Proceedings of Machine Learning and Systems2 (2020), pp. 412–428 (cit. on p. 1)
2020
-
[28]
Training recommender systems at scale: Communication-efficient model and data parallelism
Vipul Gupta et al. “Training recommender systems at scale: Communication-efficient model and data parallelism”. In:Proceed- ings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021, pp. 2928–2936 (cit. on p. 1)
2021
-
[29]
Accelerating neural recommendation train- ing with embedding scheduling
Chaoliang Zeng et al. “Accelerating neural recommendation train- ing with embedding scheduling”. In:21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 2024, pp. 1141–1156 (cit. on p. 1)
2024
-
[30]
Software-hardware co-design for fast and scalable training of deep learning recommendation models
Dheevatsa Mudigere et al. “Software-hardware co-design for fast and scalable training of deep learning recommendation models”. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 In:Proceedings of the 49th Annual International Symposium on Computer Architecture. 2022, pp. 993–1011 (cit. on p. 1)
2021
-
[31]
TRACI: Network Acceleration of Input-Dynamic Communication for Large-Scale Deep Learning Recommendation Model
Guyue Huang et al. “TRACI: Network Acceleration of Input-Dynamic Communication for Large-Scale Deep Learning Recommendation Model”. In:Proceedings of the 52nd Annual International Symposium on Computer Architecture. 2025, pp. 1880–1893 (cit. on pp. 1, 12)
2025
-
[32]
Heterogeneous acceleration pipeline for recommendation system training
Muhammad Adnan et al. “Heterogeneous acceleration pipeline for recommendation system training”. In:2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE. 2024, pp. 1063–1079 (cit. on p. 1)
2024
-
[33]
Rap: Resource-aware automated gpu sharing for multi-gpu recommendation model training and input preprocessing
Zheng Wang et al. “Rap: Resource-aware automated gpu sharing for multi-gpu recommendation model training and input preprocessing”. In:Proceedings of the 29th ACM International Conference on Archi- tectural Support for Programming Languages and Operating Systems, Volume 2. 2024, pp. 964–979 (cit. on pp. 1, 11)
2024
-
[34]
Implementing cuda unified memory in the pytorch framework
Jake Choi, Heon Young Yeom, and Yoonhee Kim. “Implementing cuda unified memory in the pytorch framework”. In:2021 IEEE In- ternational Conference on Autonomic Computing and Self-Organizing Systems Companion (ACSOS-C). IEEE. 2021, pp. 20–25 (cit. on p. 2)
2021
-
[35]
Investigation of parallel data processing using hybrid high performance CPU+ GPU systems and CUDA streams
Paweł Czarnul. “Investigation of parallel data processing using hybrid high performance CPU+ GPU systems and CUDA streams”. In: Computing and informatics39.3 (2020), pp. 510–536 (cit. on p. 2)
2020
-
[36]
Nimble: Lightweight and parallel gpu task scheduling for deep learning
Woosuk Kwon et al. “Nimble: Lightweight and parallel gpu task scheduling for deep learning”. In:Advances in Neural Information Processing Systems33 (2020), pp. 8343–8354 (cit. on p. 2)
2020
-
[37]
Cuda streams: Best practices and common pitfalls
Justin Luitjens. “Cuda streams: Best practices and common pitfalls”. In:GPU Techonology Conference. 2015 (cit. on pp. 3, 4)
2015
-
[38]
CUDA C++ programming guide
Design Guide. “CUDA C++ programming guide”. In:NVIDIA, July (2020) (cit. on pp. 6, 11)
2020
-
[39]
Wide & deep learning for recommender systems
Heng-Tze Cheng et al. “Wide & deep learning for recommender systems”. In:Proceedings of the 1st workshop on deep learning for recommender systems. 2016, pp. 7–10 (cit. on pp. 7, 11)
2016
-
[40]
Torchrec: a pytorch domain library for rec- ommendation systems
Dmytro Ivchenko et al. “Torchrec: a pytorch domain library for rec- ommendation systems”. In:Proceedings of the 16th ACM Conference on Recommender Systems. 2022, pp. 482–483 (cit. on p. 7)
2022
-
[41]
Merlin hugeCTR: GPU-accelerated recom- mender system training and inference
Zehuan Wang et al. “Merlin hugeCTR: GPU-accelerated recom- mender system training and inference”. In:Proceedings of the 16th ACM Conference on Recommender Systems. 2022, pp. 534–537 (cit. on p. 7)
2022
-
[42]
Oneflow: Redesign the distributed deep learning framework from scratch
Jinhui Yuan et al. “Oneflow: Redesign the distributed deep learning framework from scratch”. In:arXiv preprint arXiv:2110.15032(2021) (cit. on p. 7)
-
[43]
Fbgemm: Enabling high-performance low-precision deep learning inference
Daya Khudia et al. “Fbgemm: Enabling high-performance low-precision deep learning inference”. In:arXiv preprint arXiv:2101.05615(2021) (cit. on p. 7)
-
[44]
EL-Rec: Efficient large-scale recommendation model training via tensor-train embedding table
Zheng Wang et al. “EL-Rec: Efficient large-scale recommendation model training via tensor-train embedding table”. In:SC22: Inter- national Conference for High Performance Computing, Networking, Storage and Analysis. IEEE. 2022, pp. 1–14 (cit. on p. 11)
2022
-
[45]
Fec: Efficient deep recommendation model training with flexible embedding communication
Kaihao Ma et al. “Fec: Efficient deep recommendation model training with flexible embedding communication”. In:Proceedings of the ACM on Management of Data1.2 (2023), pp. 1–21 (cit. on p. 11). Dezhi Yireceived the B.Eng. degree in Internet of Things Engineering from Nankai University, Tianjin, China, in 2021. He is currently working toward the Ph.D. degre...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.