Efficient Algorithms for Influence Maximization in General Models and Observed Cascades
Pith reviewed 2026-06-26 10:37 UTC · model grok-4.3
The pith
A low-adaptivity optimization framework combined with sketching yields the first nearly-linear time algorithm with provable guarantees for influence maximization on observed cascades.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a low-adaptivity optimization framework for general stochastic models with black-box sample access that improves sample complexity and running time over prior work. Combining the framework with sketching produces the first algorithm with provable guarantees and nearly-linear running time for influence maximization on observed cascades, optimal up to logarithmic factors. For the independent-cascade model we prove a novel tail bound that replaces a factor of n with τ (the number of diffusion steps) in the sample complexity whenever τ is small.
What carries the argument
Low-adaptivity optimization framework that uses adaptive sampling guided by empirical variance, combined with sketching to obtain nearly-linear running time.
If this is right
- The framework improves sample complexity and running time over Sadeh et al. (2020) for any stochastic model with black-box access.
- Observed-cascade influence maximization now admits a nearly-linear-time algorithm with guarantees, optimal up to log factors.
- In the independent-cascade model the sample complexity improves from an n-factor to a τ-factor whenever diffusion depth is small.
- An empirical-variance adaptive variant avoids the pessimistic worst-case sample bounds of earlier methods.
Where Pith is reading between the lines
- The same low-adaptivity plus sketching pattern may apply to other submodular maximization tasks that currently rely on black-box oracles.
- If τ grows with network size, the IC-model improvement disappears and a different tail bound would be needed.
- The variance-guided adaptivity could be combined with existing sketching libraries to obtain practical implementations that beat the theoretical nearly-linear bound on real data.
- Extending the framework to models without efficient black-box sampling would require an alternative way to generate unbiased estimates.
Load-bearing premise
The stochastic models admit efficient black-box sample access and, in the independent-cascade case, the diffusion depth τ remains small.
What would settle it
A runtime measurement on a sequence of observed-cascade instances whose size doubles each time, checking whether wall-clock time grows linearly rather than quadratically or worse.
Figures
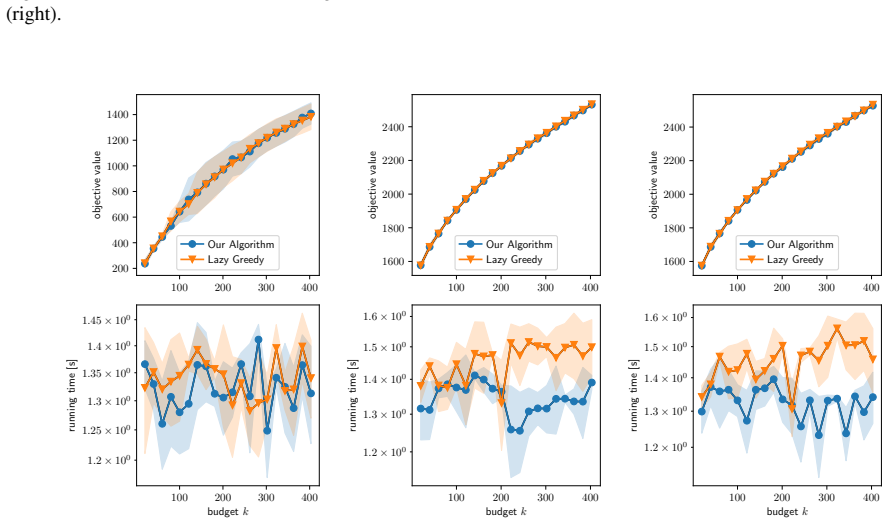
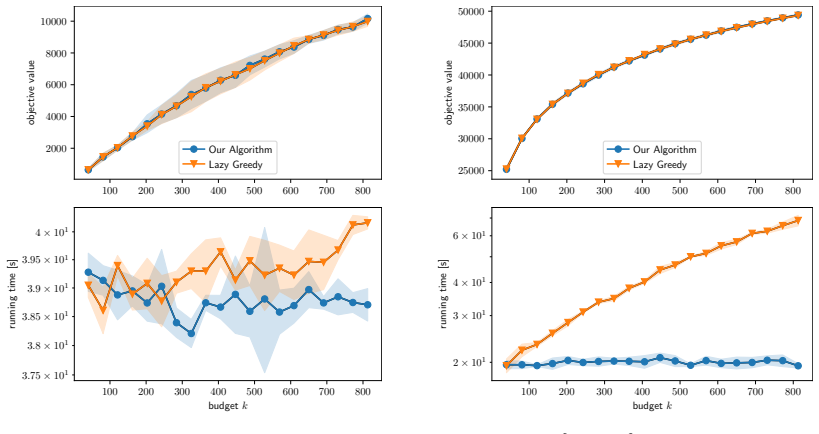
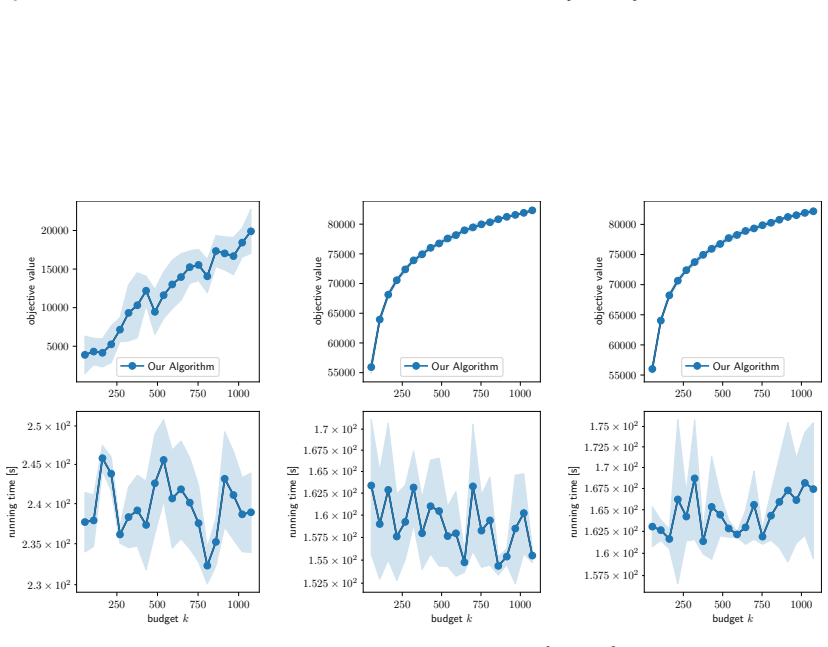
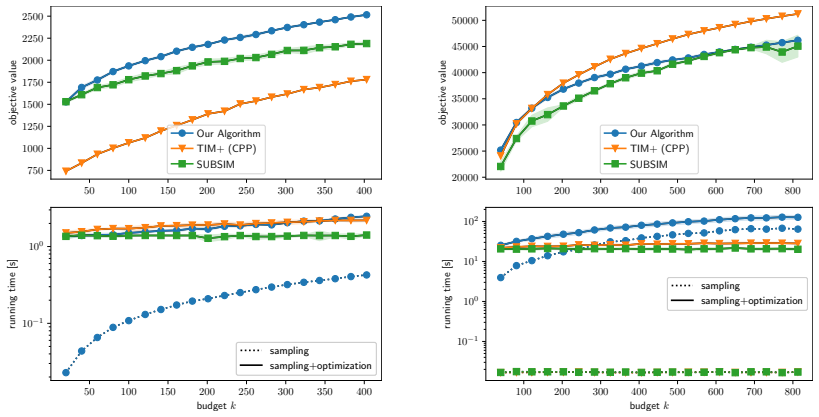
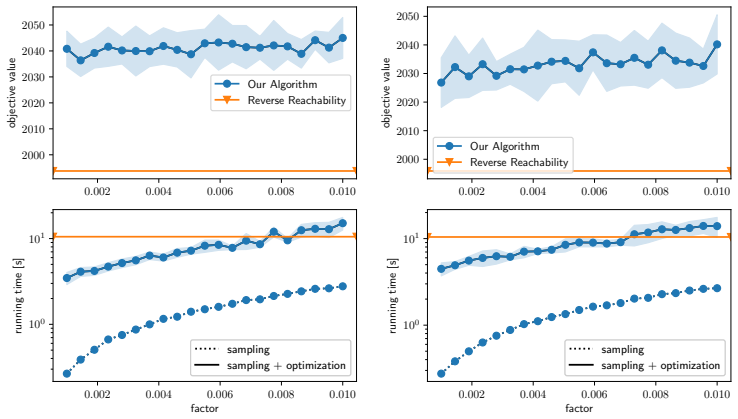
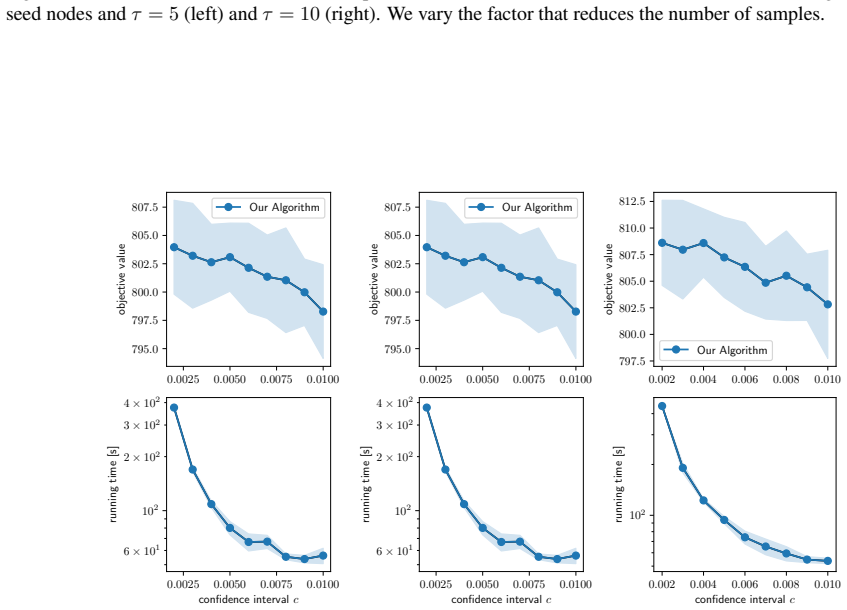
read the original abstract
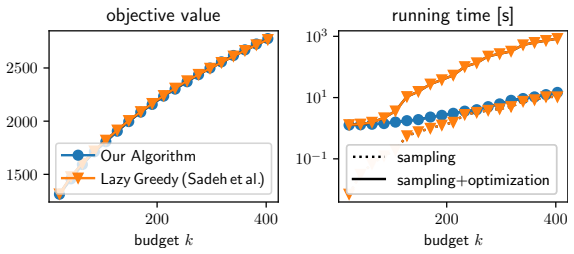
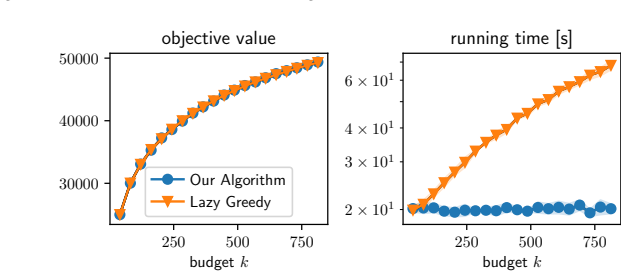
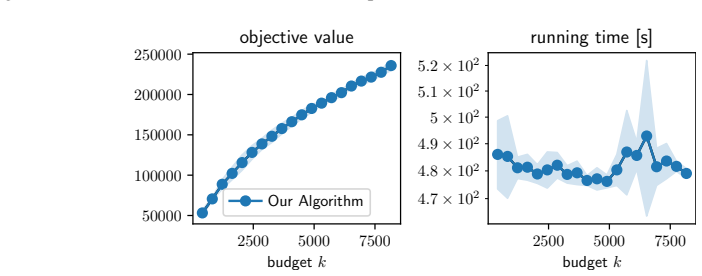
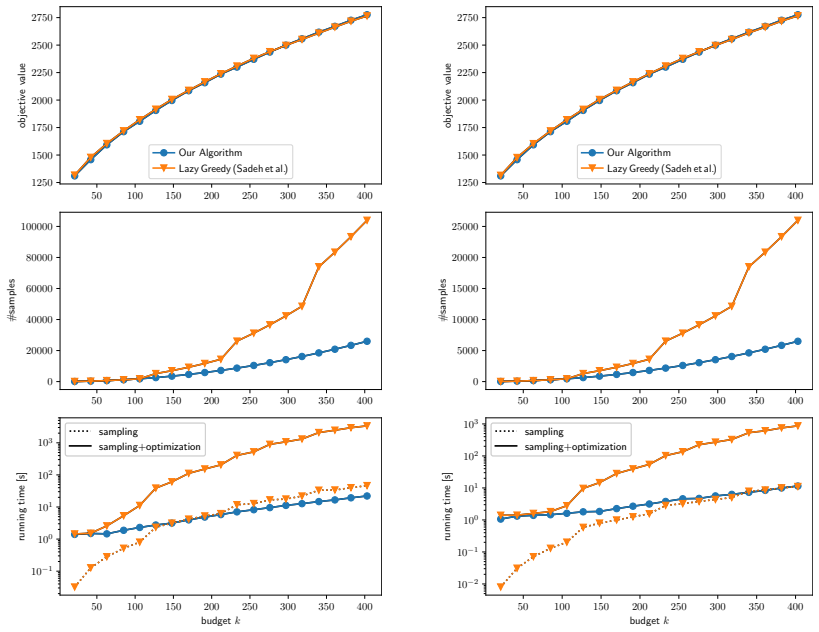
We study influence maximization in general stochastic models, the observed cascades model, and the independent cascade (IC) model. For general stochastic models with only black-box sample access, we introduce a low-adaptivity optimization framework that improves sample complexity and running time over Sadeh et al. (2020) and is instrumental to all our results. We further introduce an adaptive algorithm guided by empirical variance, avoiding pessimistic worst-case bounds. Combining our optimization framework with sketching, we obtain the first algorithm with provable guarantees and nearly-linear running time for influence maximization on observed cascades, optimal up to logarithmic factors. For IC, we prove a novel tail bound replacing a factor $n$ with $\tau$ (the number of diffusion steps) in sample complexity, improving over prior work when $\tau$ is small, as is common due to small-world phenomena. Experiments confirm substantial speedups while maintaining solution quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies influence maximization under general stochastic models with black-box sample access, the observed-cascades model, and the independent-cascade (IC) model. It introduces a low-adaptivity optimization framework that improves sample complexity and running time over Sadeh et al. (2020) and serves as the basis for the remaining results; an adaptive algorithm that uses empirical variance to avoid worst-case bounds; a sketching-based algorithm that yields the first provably correct nearly-linear-time solution for observed cascades (optimal up to logarithmic factors); and a new tail bound for the IC model that replaces an n-factor with τ (the number of diffusion steps). Experiments report substantial speed-ups while preserving solution quality.
Significance. If the stated guarantees and running-time claims hold, the work supplies the first nearly-linear-time algorithm with provable approximation guarantees for influence maximization on observed cascades, a setting directly relevant to large-scale network data. The low-adaptivity framework, the variance-guided adaptation, and the τ-based tail bound (exploiting the small-world regime common in practice) constitute concrete, usable improvements over the cited prior work. The combination of sketching with the optimization framework is a technically interesting contribution that could influence subsequent algorithmic design in submodular optimization under limited adaptivity.
minor comments (3)
- [Abstract / §1] The abstract and introduction should explicitly state the precise sample-complexity improvement (in big-O notation) achieved by the low-adaptivity framework relative to Sadeh et al. (2020) so that the claimed advance is immediately quantifiable.
- [IC-model tail bound] In the IC-model section, the new tail bound should be stated as a numbered theorem or lemma with the exact dependence on τ made visible, and the proof should be cross-referenced to the location where the n-to-τ replacement occurs.
- [Experiments] The experimental section would benefit from reporting the number of independent runs, standard deviations, and the precise network sizes used when claiming “substantial speedups,” to allow readers to assess reproducibility and effect size.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the main contributions of the low-adaptivity framework, variance-guided adaptation, sketching for observed cascades, and the τ-based tail bound.
Circularity Check
No significant circularity
full rationale
The paper introduces a low-adaptivity optimization framework and tail-bound improvements for influence maximization, explicitly building on and improving over the cited Sadeh et al. (2020) work without any equations or claims reducing by construction to fitted parameters, self-definitions, or unverified self-citation chains. Assumptions such as black-box sample access and small τ are stated as standard modeling choices rather than hidden premises that force the results. No load-bearing step in the described derivation equates a prediction or uniqueness claim to its own inputs, leaving the central nearly-linear runtime result with independent algorithmic content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The adaptive complexity of maximizing a submodular function
Eric Balkanski and Yaron Singer. The adaptive complexity of maximizing a submodular function. In STOC , pages 1138--1151. ACM , 2018
2018
-
[2]
The limitations of optimization from samples
Eric Balkanski, Aviad Rubinstein, and Yaron Singer. The limitations of optimization from samples. J. ACM , 69 0 (3): 0 21:1--21:33, 2022
2022
-
[3]
Chayes, and Brendan Lucier
Christian Borgs, Michael Brautbar, Jennifer T. Chayes, and Brendan Lucier. Maximizing social influence in nearly optimal time. In SODA , pages 946--957. SIAM , 2014
2014
-
[4]
Exact and efficient generation of geometric random variates and random graphs
Karl Bringmann and Tobias Friedrich. Exact and efficient generation of geometric random variates and random graphs. In ICALP (1) , Lecture Notes in Computer Science, pages 267--278. Springer, 2013
2013
-
[5]
Scalable influence maximization for prevalent viral marketing in large-scale social networks
Wei Chen, Chi Wang, and Yajun Wang. Scalable influence maximization for prevalent viral marketing in large-scale social networks. In KDD , pages 1029--1038. ACM , 2010
2010
-
[6]
Time-critical influence maximization in social networks with time-delayed diffusion process
Wei Chen, Wei Lu, and Ning Zhang. Time-critical influence maximization in social networks with time-delayed diffusion process. In AAAI , pages 591--598. AAAI Press, 2012
2012
-
[7]
Wei Chen, Laks V. S. Lakshmanan, and Carlos Castillo. Information and Influence Propagation in Social Networks. Synthesis Lectures on Data Management. Morgan & Claypool Publishers, 2013
2013
-
[8]
Network inference and influence maximization from samples
Wei Chen, Xiaoming Sun, Jialin Zhang, and Zhijie Zhang. Network inference and influence maximization from samples. In ICML , Proceedings of Machine Learning Research, pages 1707--1716. PMLR , 2021 a
2021
-
[9]
Best of both worlds: Practical and theoretically optimal submodular maximization in parallel
Yixin Chen, Tonmoy Dey, and Alan Kuhnle. Best of both worlds: Practical and theoretically optimal submodular maximization in parallel. In NeurIPS, pages 25528--25539, 2021 b
2021
-
[10]
Size-estimation framework with applications to transitive closure and reachability
Edith Cohen. Size-estimation framework with applications to transitive closure and reachability. J. Comput. Syst. Sci., 55 0 (3): 0 441--453, 1997
1997
-
[11]
Summarizing data using bottom-k sketches
Edith Cohen and Haim Kaplan. Summarizing data using bottom-k sketches. In PODC , pages 225--234. ACM , 2007
2007
-
[12]
Tighter estimation using bottom k sketches
Edith Cohen and Haim Kaplan. Tighter estimation using bottom k sketches. Proc. VLDB Endow. , 1 0 (1): 0 213--224, 2008
2008
-
[13]
Edith Cohen, Daniel Delling, Thomas Pajor, and Renato F. Werneck. Sketch-based influence maximization and computation: Scaling up with guarantees. In CIKM , pages 629--638. ACM , 2014 a
2014
-
[14]
Edith Cohen, Daniel Delling, Thomas Pajor, and Renato F. Werneck. Timed influence: Computation and maximization. CoRR, abs/1410.6976, 2014 b
Pith/arXiv arXiv 2014
-
[15]
Scalable influence estimation in continuous-time diffusion networks
Nan Du, Le Song, Manuel Gomez - Rodriguez, and Hongyuan Zha. Scalable influence estimation in continuous-time diffusion networks. In NIPS , pages 3147--3155, 2013
2013
-
[16]
Uncovering the temporal dynamics of diffusion networks
Manuel Gomez - Rodriguez, David Balduzzi, and Bernhard Sch \" o lkopf. Uncovering the temporal dynamics of diffusion networks. In ICML , pages 561--568. Omnipress, 2011
2011
-
[17]
Threshold models of collective behavior
Mark Granovetter. Threshold models of collective behavior. American journal of sociology, 83 0 (6): 0 1420--1443, 1978
1978
-
[18]
Influence maximization revisited: Efficient sampling with bound tightened
Qintian Guo, Sibo Wang, Zhewei Wei, Wenqing Lin, and Jing Tang. Influence maximization revisited: Efficient sampling with bound tightened. ACM Trans. Database Syst. , 47 0 (3): 0 12:1--12:45, 2022
2022
-
[19]
Bevilacqua, Xiaokui Xiao, and Laks V
Keke Huang, Sibo Wang, Glenn S. Bevilacqua, Xiaokui Xiao, and Laks V. S. Lakshmanan. Revisiting the stop-and-stare algorithms for influence maximization. Proc. VLDB Endow. , 10 0 (9): 0 913--924, 2017
2017
-
[20]
Kleinberg, and \' E va Tardos
David Kempe, Jon M. Kleinberg, and \' E va Tardos. Maximizing the spread of influence through a social network. Theory Comput., 11: 0 105--147, 2015
2015
-
[21]
Influence maximization from cascade information traces in complex networks in the absence of network structure
Naimisha Kolli and Balakrishnan Narayanaswamy. Influence maximization from cascade information traces in complex networks in the absence of network structure. IEEE Trans. Comput. Soc. Syst. , 6 0 (6): 0 1147--1155, 2019
2019
-
[22]
SNAP Datasets : Stanford large network dataset collection
Jure Leskovec and Andrej Krevl. SNAP Datasets : Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014
2014
-
[23]
VanBriesen, and Natalie S
Jure Leskovec, Andreas Krause, Carlos Guestrin, Christos Faloutsos, Jeanne M. VanBriesen, and Natalie S. Glance. Cost-effective outbreak detection in networks. In KDD , pages 420--429. ACM , 2007 a
2007
-
[24]
Glance, and Matthew Hurst
Jure Leskovec, Mary McGlohon, Christos Faloutsos, Natalie S. Glance, and Matthew Hurst. Patterns of cascading behavior in large blog graphs. In SDM , pages 551--556. SIAM , 2007 b
2007
-
[25]
A survey on influence maximization: From an ml-based combinatorial optimization
Yandi Li, Haobo Gao, Yunxuan Gao, Jianxiong Guo, and Weili Wu. A survey on influence maximization: From an ml-based combinatorial optimization. ACM Trans. Knowl. Discov. Data , 17 0 (9): 0 133:1--133:50, 2023
2023
-
[26]
Thai, Renhao Xue, James Song, Meikang Qiu, and Liang Zhao
Chen Ling, Junji Jiang, Junxiang Wang, My T. Thai, Renhao Xue, James Song, Meikang Qiu, and Liang Zhao. Deep graph representation learning and optimization for influence maximization. In ICML , Proceedings of Machine Learning Research, pages 21350--21361. PMLR , 2023
2023
-
[27]
Time constrained influence maximization in social networks
Bo Liu, Gao Cong, Dong Xu, and Yifeng Zeng. Time constrained influence maximization in social networks. In ICDM , pages 439--448. IEEE Computer Society, 2012
2012
-
[28]
Empirical bernstein bounds and sample-variance penalization
Andreas Maurer and Massimiliano Pontil. Empirical bernstein bounds and sample-variance penalization. In COLT , 2009
2009
-
[29]
Lazier than lazy greedy
Baharan Mirzasoleiman, Ashwinkumar Badanidiyuru, Amin Karbasi, Jan Vondr \' a k, and Andreas Krause. Lazier than lazy greedy. In AAAI , pages 1812--1818. AAAI Press, 2015
2015
-
[30]
On the submodularity of influence in social networks
Elchanan Mossel and S \' e bastien Roch. On the submodularity of influence in social networks. In STOC , pages 128--134. ACM , 2007
2007
-
[31]
Parkes, and Yaron Singer
Harikrishna Narasimhan, David C. Parkes, and Yaron Singer. Learnability of influence in networks. In NIPS , pages 3186--3194, 2015
2015
-
[32]
Nemhauser, Laurence A
George L. Nemhauser, Laurence A. Wolsey, and Marshall L. Fisher. An analysis of approximations for maximizing submodular set functions - I . Math. Program., 14 0 (1): 0 265--294, 1978
1978
-
[33]
Learning the graph of epidemic cascades
Praneeth Netrapalli and Sujay Sanghavi. Learning the graph of epidemic cascades. In SIGMETRICS , pages 211--222. ACM , 2012
2012
-
[34]
Nguyen, My T
Hung T. Nguyen, My T. Thai, and Thang N. Dinh. Stop-and-stare: Optimal sampling algorithms for viral marketing in billion-scale networks. In SIGMOD Conference , pages 695--710. ACM , 2016
2016
-
[35]
Nguyen, Thang N
Hung T. Nguyen, Thang N. Dinh, and My T. Thai. Revisiting of 'revisiting the stop-and-stare algorithms for influence maximization'. In CSoNet, Lecture Notes in Computer Science, pages 273--285. Springer, 2018
2018
-
[36]
Inferring graphs from cascades: A sparse recovery framework
Jean Pouget - Abadie and Thibaut Horel. Inferring graphs from cascades: A sparse recovery framework. In ICML , JMLR Workshop and Conference Proceedings, pages 977--986. JMLR.org, 2015
2015
-
[37]
Domingos
Matthew Richardson and Pedro M. Domingos. Mining knowledge-sharing sites for viral marketing. In KDD , pages 61--70. ACM , 2002
2002
-
[38]
Sample complexity bounds for influence maximization
Gal Sadeh, Edith Cohen, and Haim Kaplan. Sample complexity bounds for influence maximization. In ITCS , LIPIcs, pages 29:1--29:36. Schloss Dagstuhl - Leibniz-Zentrum f \" u r Informatik, 2020
2020
-
[39]
Online processing algorithms for influence maximization
Jing Tang, Xueyan Tang, Xiaokui Xiao, and Junsong Yuan. Online processing algorithms for influence maximization. In SIGMOD Conference , pages 991--1005. ACM , 2018
2018
-
[40]
Influence maximization: near-optimal time complexity meets practical efficiency
Youze Tang, Xiaokui Xiao, and Yanchen Shi. Influence maximization: near-optimal time complexity meets practical efficiency. In SIGMOD Conference , pages 75--86. ACM , 2014
2014
-
[41]
Influence maximization in near-linear time: A martingale approach
Youze Tang, Yanchen Shi, and Xiaokui Xiao. Influence maximization in near-linear time: A martingale approach. In SIGMOD Conference , pages 1539--1554. ACM , 2015
2015
-
[42]
Depth-first search and linear graph algorithms
Robert Endre Tarjan. Depth-first search and linear graph algorithms. SIAM J. Comput. , 1 0 (2): 0 146--160, 1972
1972
-
[43]
An experimental study of the small world problem, pages 130--148
Jeffrey Travers and Stanley Milgram. An experimental study of the small world problem, pages 130--148. Princeton University Press, Princeton, 2006. ISBN 9781400841356. doi:doi:10.1515/9781400841356.130
-
[44]
A note on concentration of submodular functions
Jan Vondr \' a k. A note on concentration of submodular functions. CoRR, abs/1005.2791, 2010
Pith/arXiv arXiv 2010
-
[45]
Modeling the spread of infectious diseases through influence maximization
Shunyu Yao, Neng Fan, and Jie Hu. Modeling the spread of infectious diseases through influence maximization. Optim. Lett., 16 0 (5): 0 1563--1586, 2022
2022
-
[46]
Information diffusion meets invitation mechanism
Shiqi Zhang, Jiachen Sun, Wenqing Lin, Xiaokui Xiao, Yiqian Huang, and Bo Tang. Information diffusion meets invitation mechanism. In WWW (Companion Volume) , pages 383--392. ACM , 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.