Statistical Proof as a Window into Human-AI Collaboration: Practical Insights and a Community Agenda
Pith reviewed 2026-06-26 01:42 UTC · model grok-4.3
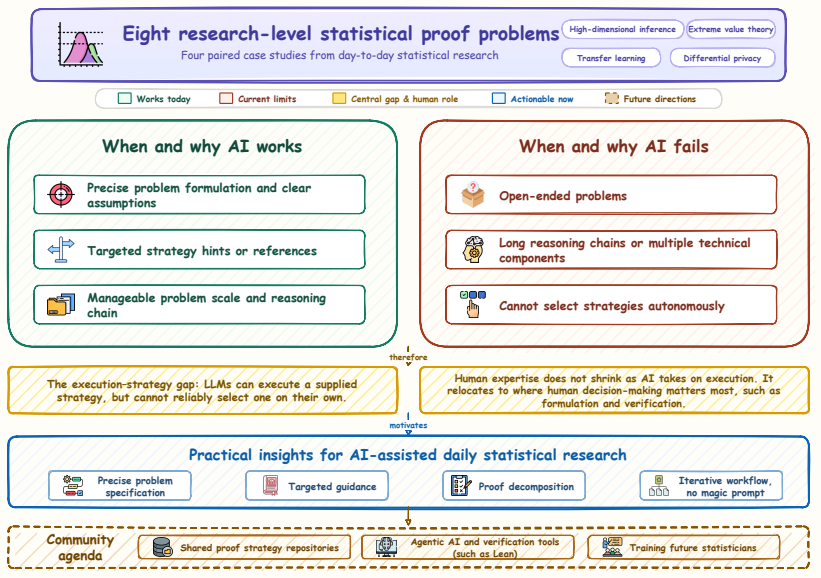
The pith
LLMs execute technical components of statistical proofs with guidance but become unreliable on open-ended problems or long interdependent reasoning chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Statistical proof requires first modeling a scientific question into a statistical framework with appropriate assumptions, and then identifying and adapting the right strategy from a repertoire of reusable domain-specific tools. Each step requires deep expertise in both the statistical literature and the real-world context being modeled. Current general-purpose LLMs occupy a useful but limited role: they can execute technical components given a precisely formulated problem and targeted guidance, but become unreliable when the problem is open-ended or requires a long reasoning chain with multiple interdependent steps. In such work, current AI assistance does not reduce the need for human expe
What carries the argument
The execution-strategy gap, in which LLMs perform execution of technical steps under guidance but cannot reliably handle the initial modeling and strategy-selection phases that define statistical proof.
If this is right
- Statisticians can structure AI-assisted workflows by reserving human effort for problem formulation, assumption setting, and verification of outputs.
- AI assistance relocates rather than replaces the expertise required for research-level statistical proof.
- Community resources such as shared prompt libraries and benchmark proof problems could improve consistent use of current tools.
- Training for the next generation of researchers should include skills for directing and checking AI contributions in technical domains.
- The pattern observed in statistical proof offers a model for how experts should structure human-AI collaboration in other structured cognitive fields.
Where Pith is reading between the lines
- The same execution-strategy distinction may appear in other modeling-heavy fields such as econometrics or epidemiology where domain context must be translated into formal assumptions before calculation begins.
- Specialized models fine-tuned on statistical literature and proof corpora might narrow the strategy-identification gap that general-purpose LLMs currently exhibit.
- If the relocation of expertise raises the skill threshold for effective use, then entry-level researchers may need more rather than less training to supervise AI outputs productively.
Load-bearing premise
Observations drawn from day-to-day proof problems are representative of the distinctive demands of statistical proof and generalize to LLM behavior in this domain.
What would settle it
A controlled test in which general-purpose LLMs, given only minimal prompts, successfully complete a representative set of open-ended statistical proof problems that require modeling choices and multi-step strategy adaptation would falsify the claim of unreliability in those cases.
Figures
read the original abstract
Large language models (LLMs) are increasingly woven into expert cognitive work in daily research, yet we know little about how human expertise should adapt when an AI system can execute substantial technical reasoning on its own. Here we use statistical proof development, a demanding and structured form of expert reasoning, as a window into this broader question. Drawing on day-to-day proof problems, we find that current general-purpose LLMs occupy a useful but limited role: they can execute technical components given a precisely formulated problem and targeted guidance, but become unreliable when the problem is open-ended or requires a long reasoning chain with multiple interdependent steps. This execution-strategy gap is rooted in what makes research-level statistical proof distinctive: unlike pure mathematics, where problems arrive pre-formulated and often demand novel techniques, statistical proof requires first modeling a scientific question into a statistical framework with appropriate assumptions, and then identifying and adapting the right strategy from a repertoire of reusable domain-specific tools. Each step requires deep expertise in both the statistical literature and the real-world context being modeled. In such work, current AI assistance does not reduce the need for human expertise; it relocates that expertise to where human decision-making matters most, such as problem formulation and verification of AI-generated results, and may raise the bar for both. These findings yield practical suggestions for how statisticians can structure AI-assisted proof workflows, and point to a broader community agenda for shared resources, better AI tools, and training the next generation of researchers. Using statistical proof as a window, our study has implications for how experts structure human-AI collaboration in technical cognitive domains more broadly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that observations from unspecified 'day-to-day proof problems' show current general-purpose LLMs can execute technical components of statistical proofs when given a precisely formulated problem and targeted guidance, but become unreliable for open-ended problems or those requiring long chains of interdependent reasoning. It argues this 'execution-strategy gap' stems from statistical proof's distinctive demands—formulating scientific questions into statistical models with domain assumptions and selecting/adapting from reusable domain-specific tools—unlike pure mathematics. Consequently, AI assistance does not reduce the need for human expertise but relocates it to problem formulation and verification of AI outputs, yielding practical workflow suggestions and a community agenda for shared resources, better tools, and researcher training, with broader implications for human-AI collaboration in technical domains.
Significance. If the observations hold and generalize, the paper would provide timely practical guidance on structuring AI-assisted statistical workflows and identify concrete areas (formulation, verification, training) where human expertise remains central. It could stimulate community efforts around shared benchmarks or tools. However, the absence of any concrete examples, sample details, or evaluation protocol means the claimed distinction between statistical proof and other domains cannot be assessed, limiting the work's contribution to an unverified perspective rather than actionable evidence.
major comments (1)
- [Abstract] Abstract: The central claim rests on findings 'drawn on day-to-day proof problems,' yet the manuscript supplies no sample size, selection criteria, evaluation protocol, specific problem statements, prompts, LLM outputs, success/failure criteria, or error analysis. Without these, it is impossible to determine whether the reported behaviors reflect distinctive features of statistical proof (modeling scientific questions with domain assumptions and selecting reusable tools) or generic LLM limitations already documented elsewhere, rendering the 'window into human-AI collaboration' claim unevaluable.
Simulated Author's Rebuttal
We thank the referee for their detailed reading and for identifying the need to clarify the evidentiary basis of the manuscript. We agree that the current presentation risks implying a more systematic empirical study than was intended, and we will revise accordingly to strengthen the work as a perspective piece.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim rests on findings 'drawn on day-to-day proof problems,' yet the manuscript supplies no sample size, selection criteria, evaluation protocol, specific problem statements, prompts, LLM outputs, success/failure criteria, or error analysis. Without these, it is impossible to determine whether the reported behaviors reflect distinctive features of statistical proof (modeling scientific questions with domain assumptions and selecting reusable tools) or generic LLM limitations already documented elsewhere, rendering the 'window into human-AI collaboration' claim unevaluable.
Authors: We accept this critique. The manuscript is a perspective article that synthesizes qualitative observations from the authors' routine statistical research practice rather than reporting a formal empirical study. No sample size, protocol, or error analysis exists because none was conducted; the text presents practitioner insights intended to motivate community discussion and agenda-setting. We will revise the abstract, introduction, and add an explicit 'Scope and Limitations' subsection to state that the claims are illustrative and experience-based, not generalizable empirical findings. This framing will also distinguish the statistical-proof context from generic LLM limitations while preserving the practical workflow suggestions and community agenda. revision: yes
Circularity Check
No circularity: observational claims with no derivations or self-referential loops
full rationale
The manuscript contains no equations, fitted parameters, or derivation chains. Its central claims are presented as direct observational statements drawn from unspecified day-to-day proof problems rather than quantities defined in terms of the paper's own outputs or reduced via self-citation. No load-bearing steps invoke prior author work as an unverified uniqueness theorem or smuggle an ansatz through citation. The paper is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blumberg, Martin Hairer, Joe Kileel, Tamara G
Mohammed Abouzaid, Andrew J. Blumberg, Martin Hairer, Joe Kileel, Tamara G. Kolda, Paul D. Nelson, Daniel Spielman, Nikhil Srivastava, Rachel Ward, Shmuel Weinberger, and Lauren Williams. First proof.arXiv preprint arXiv:2602.05192,
-
[2]
The 2020 census disclosure avoidance system topdown algorithm.Harvard Data Science Review, 2:1–72,
John M Abowd, Robert Ashmead, Ryan Cumings-Menon, Simson Garfinkel, Micah Heineck, Christine Heiss, Robert Johns, Daniel Kifer, Philip Leclerc, Ashwin Machanavajjhala, et al. The 2020 census disclosure avoidance system topdown algorithm.Harvard Data Science Review, 2:1–72,
2020
-
[3]
Kaito Baba, Chaoran Liu, Shuhei Kurita, and Akiyoshi Sannai. Prover agent: An agent-based framework for formal mathematical proofs.arXiv preprint arXiv:2506.19923,
-
[4]
Jae Ho Chang, Massimiliano Russo, and Subhadeep Paul. Heterogeneous transfer learning for high-dimensional regression with feature mismatch.arXiv preprint arXiv:2412.18081,
-
[5]
Seed-prover: Deep and broad reasoning for automated theorem proving.arXiv preprint arXiv:2507.23726,
Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, et al. Seed-prover: Deep and broad reasoning for automated theorem proving.arXiv preprint arXiv:2507.23726,
-
[6]
Cl-bench: A benchmark for context learning
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587,
-
[7]
Our data, ourselves: Privacy via distributed noise generation
Cynthia Dwork, Krishnaram Kenthapadi, Frank McSherry, Ilya Mironov, and Moni Naor. Our data, ourselves: Privacy via distributed noise generation. InAnnual international conference on the theory and applications of cryptographic techniques, pages 486–503. Springer, 2006a. Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sen...
-
[8]
Ai for mathematics: Progress, challenges, and prospects.arXiv preprint arXiv:2601.13209,
Haocheng Ju and Bin Dong. Ai for mathematics: Progress, challenges, and prospects.arXiv preprint arXiv:2601.13209,
-
[9]
Yuchen Lu, Run Yang, Yichen Zhang, Shuguang Yu, Runpeng Dai, Ziwei Wang, Jiayi Xiang, Siran Gao, Xinyao Ruan, Yirui Huang, et al. Stateval: A comprehensive benchmark for large language models in statistics.arXiv preprint arXiv:2510.09517,
-
[10]
ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801,
-
[11]
Su, and Chendi Wang
Buxin Su, Weijie J. Su, and Chendi Wang. The 2020 US Decennial Census is more private than you (might) think.Proceedings of the National Academy of Sciences, 122(45):e2500337122,
2020
-
[12]
David P. Woodruff et al. Accelerating scientific research with gemini: Case studies and common techniques.arXiv preprint arXiv:2602.03837,
-
[13]
Gomes, Bart Selman, and Stefan Szeider
30 Hai Xia, Carla P. Gomes, Bart Selman, and Stefan Szeider. Agentic neurosymbolic collab- oration for mathematical discovery: A case study in combinatorial design.arXiv preprint arXiv:2603.08322,
-
[14]
High-dimensional statistical inference for linkage disequilibrium score regression and its cross-ancestry extensions.The Annals of Statistics, 53(5):1913–1937,
Fei Xue and Bingxin Zhao. High-dimensional statistical inference for linkage disequilibrium score regression and its cross-ancestry extensions.The Annals of Statistics, 53(5):1913–1937,
1913
-
[15]
Ai co-mathematician: Accelerating mathematicians with agentic ai.arXiv preprint arXiv:2605.06651,
Daniel Zheng, Ingrid von Glehn, Yori Zwols, Iuliya Beloshapka, Lars Buesing, Daniel M Roy, Martin Wattenberg, Bogdan Georgiev, Tatiana Schmidt, Andrew Cowie, et al. Ai co-mathematician: Accelerating mathematicians with agentic ai.arXiv preprint arXiv:2605.06651,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.