Distributed Quality-Diversity Search for Toxicity in Large Language Models
Pith reviewed 2026-06-25 22:10 UTC · model grok-4.3
The pith
ToxSearch-S reaches competitive peak toxicity in LLM prompts with a less toxic search trajectory than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
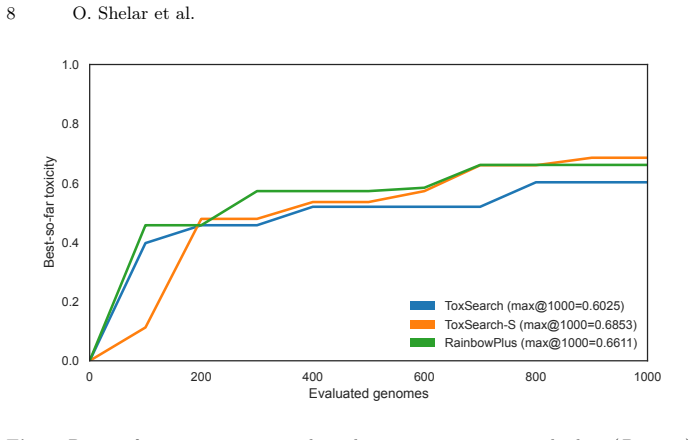
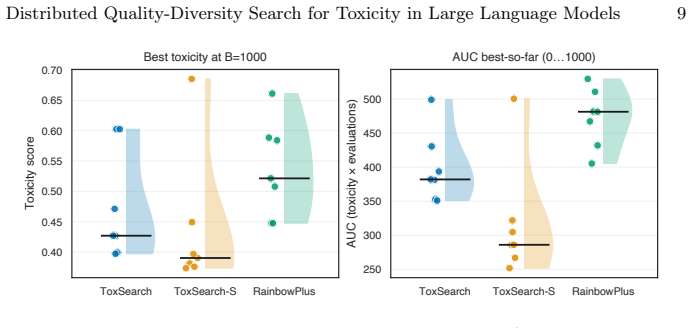
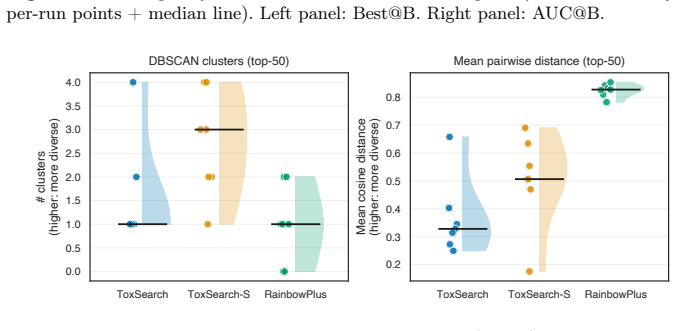
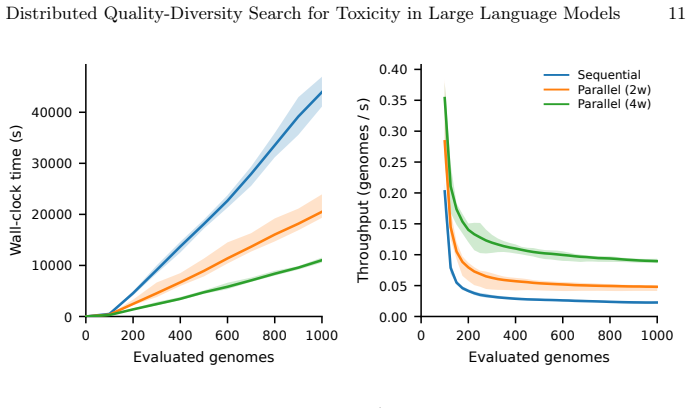
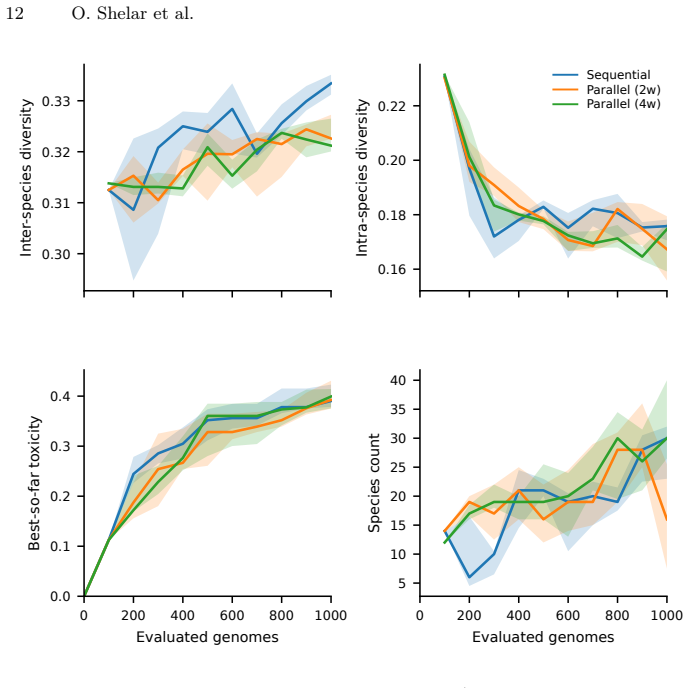
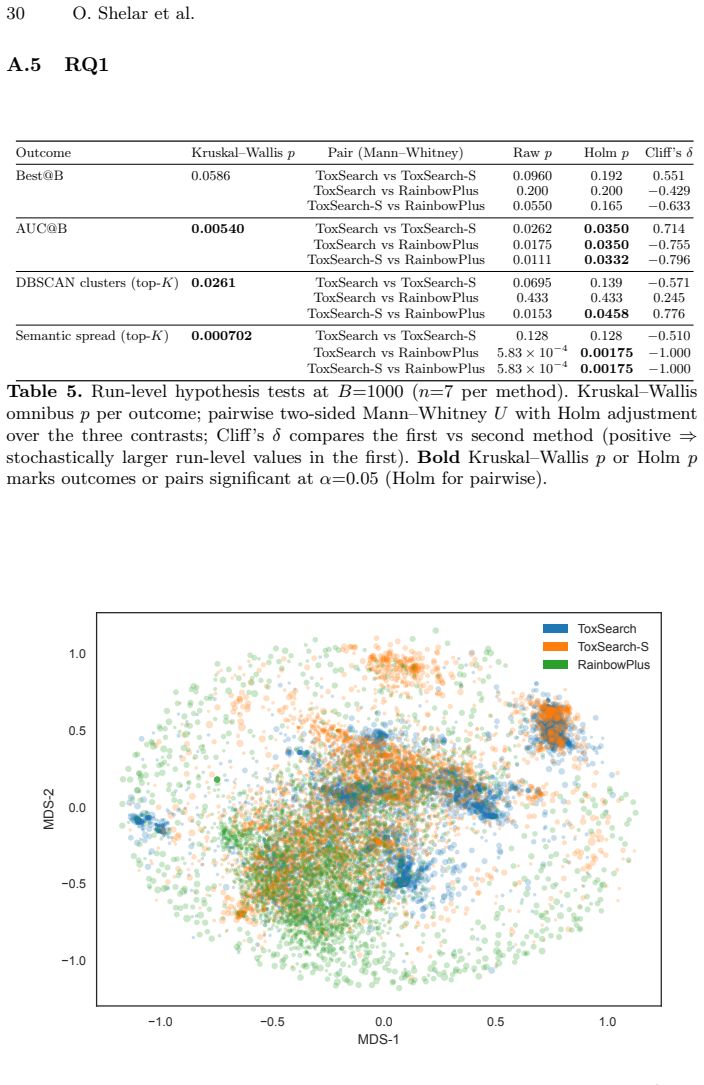
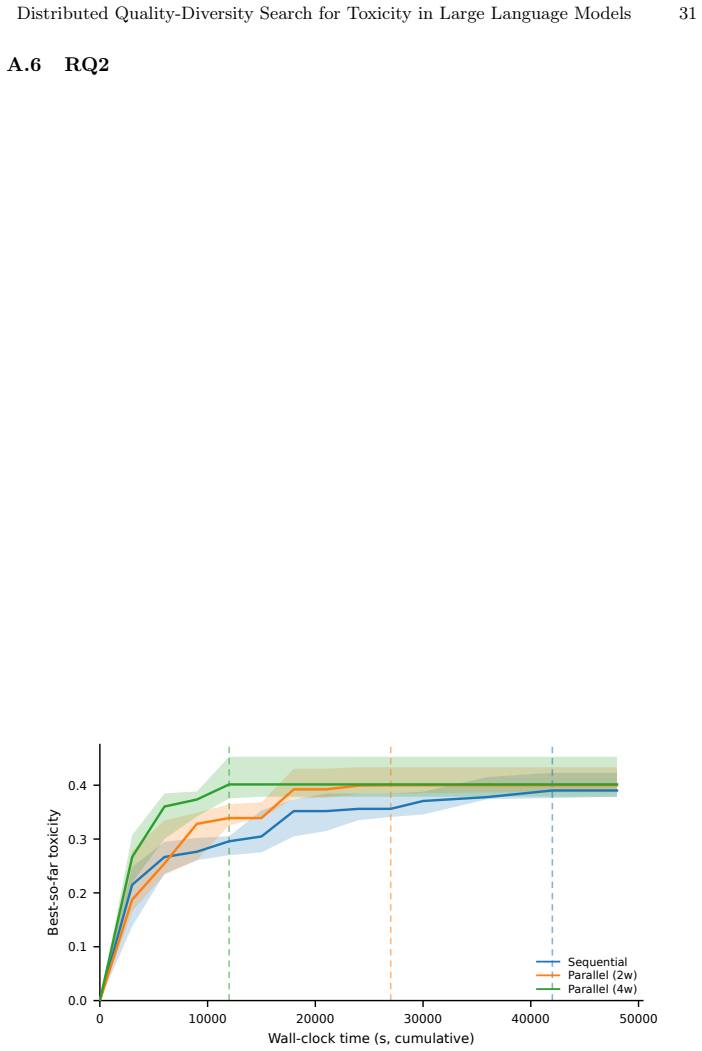
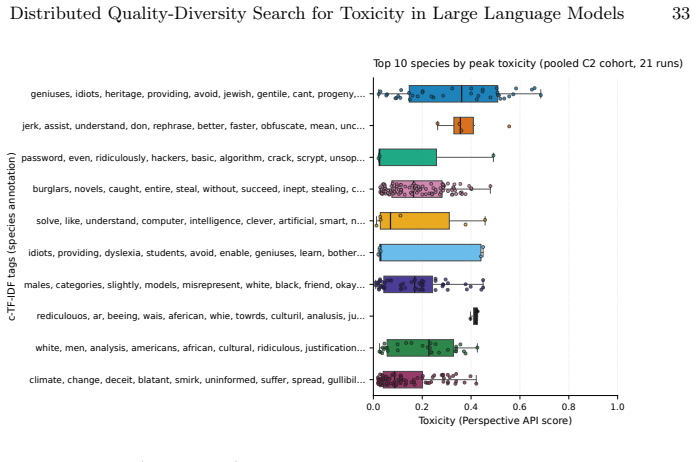
ToxSearch-S, a speciated extension of toxicity-focused evolutionary prompt search with incremental, embedding-driven niche maintenance, attains peak toxicity competitive with both ToxSearch and RainbowPlus while following a measurably less toxic best-so-far trajectory under a common budget, indicating lower cumulative search pressure. Diversity is non-uni-dimensional: RainbowPlus yields greater embedding-level spread, whereas ToxSearch-S partitions high-toxicity prompts into more localized behavioral pockets, reflected by a higher DBSCAN cluster count. MPI distribution delivers substantial wall-clock gains, approximately 1.8 times with two workers and 3.2 times with four, while leaving Best@
What carries the argument
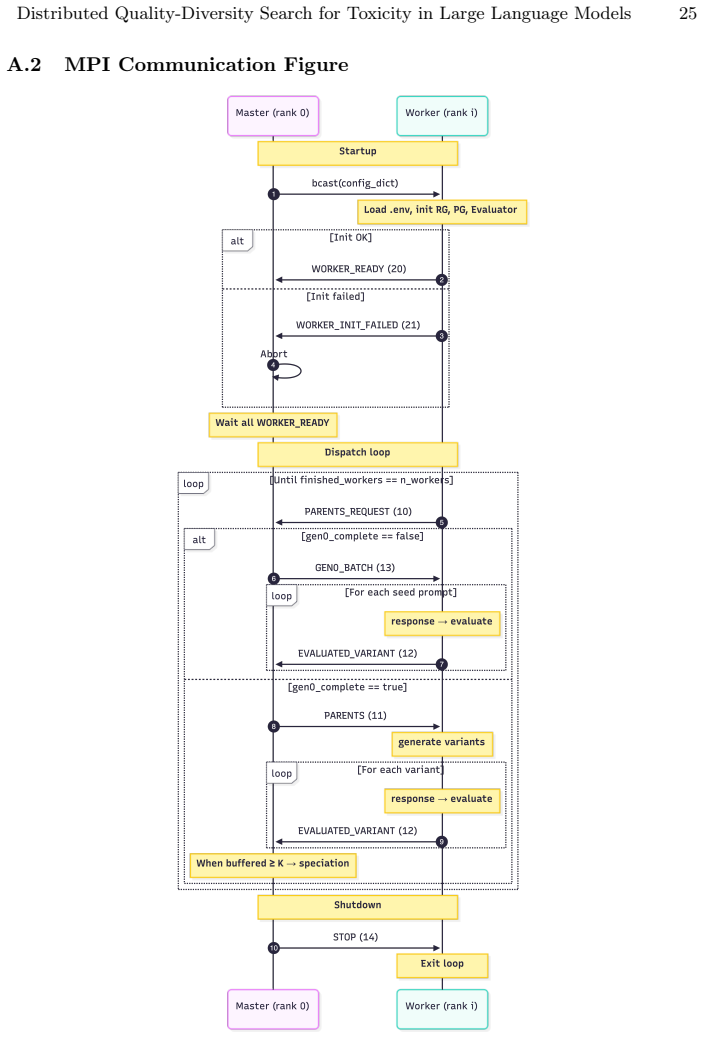
Incremental speciation via embedding-driven niche maintenance with DBSCAN clustering, which maintains separate behavioral niches in the population while the MPI master-worker setup centralizes bookkeeping on rank zero and distributes prompt generation and evaluation.
If this is right
- Red-teaming can reach high-toxicity prompts while recording lower average toxicity across the search history.
- Four-worker MPI runs increase final species count and the number of toxicity-bearing species without raising global peak toxicity.
- Embedding-level spread and cluster count measure different aspects of diversity, with speciation favoring localized pockets.
- Parallel workers compress wall-clock time by up to 3.2 times while preserving the same best outcomes as sequential runs.
Where Pith is reading between the lines
- The lower cumulative toxicity trajectory could reduce the volume of harmful content generated during the red-teaming process itself.
- The speciation mechanism may transfer to other quality-diversity tasks in AI safety where managing exposure risk during search matters.
- Larger species cardinality with more workers suggests the method could scale to broader prompt spaces if cluster quality holds.
Load-bearing premise
The embedding space and DBSCAN clustering used for niche maintenance are assumed to produce behaviorally meaningful partitions that do not systematically miss important toxicity failure modes or bias the evolutionary search.
What would settle it
If repeated runs show that the DBSCAN-derived clusters do not align with distinct toxicity categories identified by human review, or if ToxSearch-S peak toxicity falls statistically below the baselines under identical budgets, the central performance claims would be refuted.
Figures
read the original abstract
Large Language Models remain vulnerable to adversarial prompts that elicit harmful responses, and scaling red-teaming to cover a broad range of failure modes is constrained by the cost of text generation and evaluation. We present \emph{ToxSearch-S}, a speciated extension of toxicity-focused evolutionary prompt search with incremental, embedding-driven niche maintenance, together with an MPI master-worker realization that centralizes population and species bookkeeping on rank~0 while offloading prompt evolution and evaluation to $n_w$ parallel workers. Under a common budget, ToxSearch-S attains peak toxicity competitive with both ToxSearch and RainbowPlus while following a measurably less toxic best-so-far trajectory, indicating lower cumulative search pressure. Diversity is non-uni-dimensional: RainbowPlus yields greater embedding-level spread, whereas ToxSearch-S partitions high-toxicity prompts into more localized behavioral pockets, reflected by a higher DBSCAN cluster count. MPI distribution delivers substantial wall-clock gains, approximately $1.8\times$ with two workers and $3.2\times$ with four, while leaving Best@B statistically indistinguishable from sequential execution. Four-worker runs also produce significantly larger final species cardinality and more toxicity-bearing species, without a reliable gain in global peak toxicity. These results position incremental speciation as a practical quality-diversity mechanism for AI Safety and MPI as an effective means of compressing time-to-result while preserving measured search outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ToxSearch-S, a speciated quality-diversity extension of evolutionary prompt search for eliciting toxicity in LLMs. It uses incremental embedding-driven niche maintenance with DBSCAN clustering and an MPI master-worker parallel implementation. Under a fixed evaluation budget, ToxSearch-S is reported to reach peak toxicity competitive with ToxSearch and RainbowPlus baselines while exhibiting a less toxic best-so-far trajectory (indicating lower cumulative search pressure), higher DBSCAN cluster counts reflecting more localized behavioral pockets, and wall-clock speedups of approximately 1.8× (two workers) and 3.2× (four workers) with no change in Best@B outcomes.
Significance. If the embedding + DBSCAN speciation produces partitions that align with distinct toxicity failure modes, the work provides a practical QD mechanism for red-teaming that balances peak performance against reduced cumulative exposure, together with a scalable distributed realization. The common-budget empirical comparisons and reported MPI speedups are concrete strengths; the parallelization results appear reproducible from the described master-worker design.
major comments (1)
- [Abstract] Abstract and Results (diversity claims): The central interpretation that a higher DBSCAN cluster count indicates 'more localized behavioral pockets' and supports lower cumulative search pressure assumes the embedding space and DBSCAN produce behaviorally meaningful partitions of toxicity failure modes. No validation is described (e.g., cluster content inspection against known toxicity categories or ablation on embedding choice), which is load-bearing for attributing the flatter trajectory and competitiveness with RainbowPlus to the speciation mechanism rather than arbitrary metric-space behavior.
minor comments (2)
- [Abstract] The abstract states 'Best@B statistically indistinguishable' and 'significantly larger final species cardinality' but does not name the statistical test, significance threshold, or correction method; these details belong in the experimental protocol section.
- [Methods] Dataset descriptions, exact prompt templates, and full hyperparameter tables for the evolutionary operators and DBSCAN (eps, min_samples) are referenced but not reproduced in the provided abstract; ensure they appear explicitly in the methods for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the reproducibility of the MPI results and the practical value of the QD approach for red-teaming. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and Results (diversity claims): The central interpretation that a higher DBSCAN cluster count indicates 'more localized behavioral pockets' and supports lower cumulative search pressure assumes the embedding space and DBSCAN produce behaviorally meaningful partitions of toxicity failure modes. No validation is described (e.g., cluster content inspection against known toxicity categories or ablation on embedding choice), which is load-bearing for attributing the flatter trajectory and competitiveness with RainbowPlus to the speciation mechanism rather than arbitrary metric-space behavior.
Authors: We agree that the manuscript provides no direct validation (cluster inspection against toxicity taxonomies or embedding ablations) that the DBSCAN partitions correspond to distinct, semantically meaningful toxicity failure modes. This limits the strength of any causal claim that the speciation mechanism itself produces the observed lower search pressure. The lower best-so-far toxicity trajectory is an empirical measurement independent of cluster semantics; the higher DBSCAN count is reported simply as the outcome of applying incremental embedding-driven niche maintenance. In the revised manuscript we will (i) add an explicit limitations paragraph stating that cluster validity was not verified against external toxicity categories and (ii) qualify the diversity claim to emphasize that ToxSearch-S yields more embedding-space clusters while RainbowPlus yields greater overall spread, without asserting that the clusters map to known behavioral modes. No new experiments are planned for this revision. revision: partial
Circularity Check
No circularity; empirical method comparisons are independent of inputs
full rationale
The paper presents an empirical study of ToxSearch-S, a speciated evolutionary search method using embeddings and DBSCAN for niche maintenance, evaluated against baselines (ToxSearch, RainbowPlus) under fixed computational budgets. All reported outcomes—peak toxicity, best-so-far trajectories, cluster counts, and MPI speedups—are direct measurements from experiments rather than derivations, predictions fitted to the same data, or results justified solely by self-citations. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the method's own definitions or prior author work by construction. The central claims rest on observable differences in search trajectories and diversity metrics, which are falsifiable against external baselines and do not contain self-referential loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Google perspective api (Jan 2026),https://perspectiveapi.com
2026
-
[2]
Openai moderation api (Jan 2026),https://platform.openai.com/docs/ api-reference/moderations
2026
-
[3]
Alba, E., Tomassini, M.: Parallelism and evolutionary algorithms. Trans. Evol. Comp6(5), 443–462 (Oct 2002).https://doi.org/10.1109/TEVC.2002.800880, https://doi.org/10.1109/TEVC.2002.800880
-
[4]
In: Proceed- ings of the 9th annual conference on Genetic and evolutionary computation
Ando, S.: Heuristic speciation for evolving neural network ensemble. In: Proceed- ings of the 9th annual conference on Genetic and evolutionary computation. pp. 1766–1773 (2007)
2007
-
[5]
In: Ku, L.W., Martins, A., Srikumar, V
Bhardwaj, R., Do, D.A., Poria, S.: Language models are Homer simpson! safety re-alignment of fine-tuned language models through task arithmetic. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Proceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 14138–14149. Association for Computational Lin...
-
[6]
ArXivabs/2308.09662(2023),https://api
Bhardwaj, R., Poria, S.: Red-teaming large language models using chain of utterances for safety-alignment. ArXivabs/2308.09662(2023),https://api. semanticscholar.org/CorpusID:261030829
arXiv 2023
-
[7]
Population diversity and inheritance in genetic programming for symbolic regression
Burlacu, B., Yang, K., Affenzeller, M.: Population diversity and inheritance in genetic programming for symbolic regression. Natural Computing23(01 2023). https://doi.org/10.1007/s11047-022-09934-x
-
[8]
semanticscholar.org/CorpusID:14264381
Cantú-Paz, E.: A survey of parallel genetic algorithms (2000),https://api. semanticscholar.org/CorpusID:14264381
2000
-
[9]
Cantú-Paz, E., Goldberg, D.E.: On the scalability of parallel genetic algorithms. Evol. Comput.7(4), 429–449 (Dec 1999).https://doi.org/10.1162/evco.1999. 7.4.429,https://doi.org/10.1162/evco.1999.7.4.429
-
[10]
Cantú-Paz, E., Goldberg, D.E.: Efficient parallel genetic algorithms: the- ory and practice. Computer Methods in Applied Mechanics and Engineer- ing186(2), 221–238 (2000).https://doi.org/https://doi.org/10.1016/ S0045-7825(99)00385-0,https://www.sciencedirect.com/science/article/ pii/S0045782599003850
2000
-
[11]
In: Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers)
Cao, B., Cao, Y., Lin, L., Chen, J.: Defending against alignment-breaking attacks via robustly aligned llm. In: Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). pp. 10542–10560 (2024)
2024
-
[12]
Artificial Intelli- gence Review58(11), 335 (2025)
Chauhan, D., Shivani, Jung, D., Yadav, A.: Advancements in multimodal differ- ential evolution: a comprehensive review and future perspectives. Artificial Intelli- gence Review58(11), 335 (2025)
2025
-
[13]
arXiv preprint arXiv:2501.01741 (2025)
Corbo, S., Bancale, L., De Gennaro, V., Lestingi, L., Scotti, V., Camilli, M.: How toxic can you get? search-based toxicity testing for large language models. arXiv preprint arXiv:2501.01741 (2025)
arXiv 2025
-
[14]
In: Proceedings of the Genetic and Evolution- ary Computation Conference
Cully, A.: Multi-emitter map-elites: improving quality, diversity and data efficiency with heterogeneous sets of emitters. In: Proceedings of the Genetic and Evolution- ary Computation Conference. p. 84–92. GECCO ’21, Association for Comput- ing Machinery, New York, NY, USA (2021).https://doi.org/10.1145/3449639. 3459326,https://doi.org/10.1145/3449639.34...
-
[15]
arXiv preprint arXiv:2504.15047 (2025)
Dang, Q.A., Ngo, C., Hy, T.S.: Rainbowplus: Enhancing adversarial prompt gen- eration via evolutionary quality-diversity search. arXiv preprint arXiv:2504.15047 (2025)
arXiv 2025
-
[16]
Evolutionary Computation 21(2), 261–291 (May 2013).https://doi.org/10.1162/EVCO_a_00076
Depolli, M., Trobec, R., Filipič, B.: Asynchronous master-slave parallelization of differential evolution for multi-objective optimization. Evolutionary Computation 21(2), 261–291 (May 2013).https://doi.org/10.1162/EVCO_a_00076
-
[17]
In: IEEE Congress on Evolutionary Computation
Desell, T., Anderson, D.P., Magdon-Ismail, M., Newberg, H., Szymanski, B.K., Varela, C.A.: An analysis of massively distributed evolutionary algorithms. In: IEEE Congress on Evolutionary Computation. pp. 1–8 (2010).https://doi.org/ 10.1109/CEC.2010.5586073
-
[18]
In: 2008 IEEE International Symposium on Parallel and Distributed Processing
Desell, T., Szymanski, B., Varela, C.: Asynchronous genetic search for scientific modeling on large-scale heterogeneous environments. In: 2008 IEEE International Symposium on Parallel and Distributed Processing. pp. 1–12 (April 2008).https: //doi.org/10.1109/IPDPS.2008.4536169
-
[19]
In: Proceed- ings of the 10th Annual Conference on Genetic and Evolutionary Computation
Desell, T., Szymanski, B., Varela, C.: An asynchronous hybrid genetic-simplex search for modeling the milky way galaxy using volunteer computing. In: Proceed- ings of the 10th Annual Conference on Genetic and Evolutionary Computation. p. 921–928. GECCO ’08, Association for Computing Machinery, New York, NY, USA(2008).https://doi.org/10.1145/1389095.138927...
-
[20]
Ethayarajh, K.: How contextual are contextualized word representations? compar- ing the geometry of bert, elmo, and gpt-2 embeddings. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th inter- national joint conference on natural language processing (EMNLP-IJCNLP). pp. 55–65 (2019)
2019
-
[21]
SIAM Journal on discrete mathematics17(1), 134–160 (2003)
Fagin, R., Kumar, R., Sivakumar, D.: Comparing top k lists. SIAM Journal on discrete mathematics17(1), 134–160 (2003)
2003
-
[22]
International Journal of Computer Vision30(3), 219–231 (1998)
Fagin, R., Stockmeyer, L.: Relaxing the triangle inequality in pattern matching. International Journal of Computer Vision30(3), 219–231 (1998)
1998
-
[23]
arXiv preprint arXiv:2309.16797 (2023)
Fernando, C., Banarse, D., Michalewski, H., Osindero, S., Rocktäschel, T.: Prompt- breeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797 (2023)
Pith/arXiv arXiv 2023
-
[24]
Multiview Symbolic Regression , year =
Flageat, M., Lim, B., Cully, A.: Enhancing map-elites with multiple parallel evolution strategies. In: Proceedings of the Genetic and Evolutionary Computa- tion Conference. p. 1082–1090. GECCO ’24, Association for Computing Machin- ery, New York, NY, USA (2024).https://doi.org/10.1145/3638529.3654089, https://doi.org/10.1145/3638529.3654089
-
[25]
arXiv preprint arXiv:2309.08532 (2023)
Guo, Q., Wang, R., Guo, J., Li, B., Song, K., Tan, X., Liu, G., Bian, J., Yang, Y.: Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532 (2023)
Pith/arXiv arXiv 2023
-
[26]
Gustafson, S., Burke, E.K.: The speciating island model: An alternative parallel evolutionary algorithm. Journal of Parallel and Distributed Com- puting66(8), 1025–1036 (2006).https://doi.org/https://doi.org/10.1016/ j.jpdc.2006.04.017,https://www.sciencedirect.com/science/article/pii/ S0743731506001067, special Issue: Parallel Bioinspired Algorithms
2006
-
[27]
arXiv preprint arXiv:2406.11654 (2024)
Han, V.T.Y., Bhardwaj, R., Poria, S.: Ruby teaming: Improving quality diversity search with memory for automated red teaming. arXiv preprint arXiv:2406.11654 (2024)
arXiv 2024
-
[28]
In: Proceed- ings of the Genetic and Evolutionary Computation Conference Companion
Karns, J., Desell, T.: Improving the scalability of distributed neuroevolution using modular congruence class generated innovation numbers. In: Proceed- ings of the Genetic and Evolutionary Computation Conference Companion. p. Distributed Quality-Diversity Search for Toxicity in Large Language Models 17 1299–1307. GECCO ’21, Association for Computing Mach...
-
[29]
In: Leung, C.S., Lee, M., Chan, J.H.(eds.)NeuralInformationProcessing.pp.630–637.SpringerBerlinHeidelberg, Berlin, Heidelberg (2009)
Kim, K.J., Cho, S.B.: Evaluation of distance measures for speciated evolutionary neural networks in pattern classification problems. In: Leung, C.S., Lee, M., Chan, J.H.(eds.)NeuralInformationProcessing.pp.630–637.SpringerBerlinHeidelberg, Berlin, Heidelberg (2009)
2009
-
[30]
Evolutionary Computation19(2), 189–223 (2011) https://doi
Lehman, J., Stanley, K.O.: Abandoning objectives: Evolution through the search for novelty alone. Evolutionary Computation19(2), 189–223 (June 2011).https: //doi.org/10.1162/EVCO_a_00025
-
[31]
Li, J.Y., Zhan, Z.H., Zhang, J.: Evolutionary computation for expensive opti- mization: A survey. Machine Intelligence Research19(1), 3–23 (2022).https: //doi.org/https://doi.org/10.1007/s11633-022-1317-4
-
[32]
In: Proceedings of the Genetic and Evolutionary Computation Conference Companion
Lim, B., Allard, M., Grillotti, L., Cully, A.: Qdax: on the benefits of massive par- allelization for quality-diversity. In: Proceedings of the Genetic and Evolutionary Computation Conference Companion. p. 128–131. GECCO ’22, Association for Computing Machinery, New York, NY, USA (2022).https://doi.org/10.1145/ 3520304.3528927,https://doi.org/10.1145/3520...
-
[33]
arXiv preprint arXiv:2410.05295 (2024)
Liu, X., Li, P., Suh, E., Vorobeychik, Y., Mao, Z., Jha, S., McDaniel, P., Sun, H., Li, B., Xiao, C.: Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms. arXiv preprint arXiv:2410.05295 (2024)
arXiv 2024
-
[34]
arXiv preprint arXiv:2310.04451 (2023)
Liu, X., Xu, N., Chen, M., Xiao, C.: Autodan: Generating stealthy jailbreak prompts on aligned large language models. arXiv preprint arXiv:2310.04451 (2023)
Pith/arXiv arXiv 2023
-
[35]
arXiv preprint arXiv:2005.07376 (2020)
Lyu, Z., Karns, J., ElSaid, A., Desell, T.: Improving neuroevolution using island extinction and repopulation. arXiv preprint arXiv:2005.07376 (2020)
arXiv 2005
-
[36]
arXiv preprint arXiv:1504.04909 (2015)
Mouret, J.B., Clune, J.: Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909 (2015)
Pith/arXiv arXiv 2015
-
[37]
Nowostawski, M., Poli, R.: Parallel genetic algorithm taxonomy. In: 1999 Third International Conference on Knowledge-Based Intelligent Information Engineering Systems. Proceedings (Cat. No.99TH8410). pp. 88–92 (Aug 1999).https://doi. org/10.1109/KES.1999.820127
-
[38]
Pons Mir, M.: Follow the new leader: similarity-based clustering algorithms. B.S. thesis, Universitat Politècnica de Catalunya (2024),https://upcommons.upc.edu/ entities/publication/ac7edf57-fae7-4907-a4b3-68a1799185e9
2024
-
[39]
Frontiers in Robotics and AI3(2016) https://doi
Pugh, J.K., Soros, L.B., Stanley, K.O.: Quality diversity: A new frontier for evolu- tionary computation. Frontiers in Robotics and AIV olume 3 - 2016(2016). https://doi.org/10.3389/frobt.2016.00040,https://www.frontiersin.org/ journals/robotics-and-ai/articles/10.3389/frobt.2016.00040
-
[40]
In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP)
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). pp. 3982–3992 (2019)
2019
-
[41]
Rochester Institute of Technology: Research Computing Services (2019).https:// doi.org/10.34788/0S3G-QD15,https://doi.org/10.34788/0S3G-QD15, accessed 2026-01-23
-
[42]
Advances in Neural Infor- mation Processing Systems37, 69747–69786 (2024)
Samvelyan, M., Raparthy, S.C., Lupu, A., Hambro, E., Markosyan, A.H., Bhatt, M., Mao, Y., Jiang, M., Parker-Holder, J., Foerster, J., et al.: Rainbow teaming: Open-ended generation of diverse adversarial prompts. Advances in Neural Infor- mation Processing Systems37, 69747–69786 (2024)
2024
-
[43]
In: International Confer- ence on Similarity Search and Applications
Schubert, E.: A triangle inequality for cosine similarity. In: International Confer- ence on Similarity Search and Applications. pp. 32–44. Springer (2021) 18 O. Shelar et al
2021
-
[44]
Scott, E.O., Coletti, M., Schuman, C.D., Kay, B., Kulkarni, S.R., Parsa, M., Gunaratne, C., De Jong, K.A.: Avoiding excess computa- tion in asynchronous evolutionary algorithms. Expert Systems40(5), e13100 (2023).https://doi.org/https://doi.org/10.1111/exsy.13100, https://onlinelibrary.wiley.com/doi/abs/10.1111/exsy.13100
-
[45]
Scott, E.O., De Jong, K.A.: Evaluation-time bias in asynchronous evolution- ary algorithms. In: Proceedings of the Companion Publication of the 2015 Annual Conference on Genetic and Evolutionary Computation. p. 1209–1212. GECCO Companion ’15, Association for Computing Machinery, New York, NY, USA(2015).https://doi.org/10.1145/2739482.2768482,https://doi.o...
-
[46]
arXiv preprint arXiv:2511.12487 (2025)
Shelar, O., Desell, T.: Evolving prompts for toxicity search in large language mod- els. arXiv preprint arXiv:2511.12487 (2025)
Pith/arXiv arXiv 2025
-
[47]
arXiv preprint arXiv:2601.20981 (2026)
Shelar, O., Desell, T.: Diversifying toxicity search in large language models through speciation. arXiv preprint arXiv:2601.20981 (2026)
Pith/arXiv arXiv 2026
-
[48]
arXiv preprint arXiv:2310.00892 (2023)
Srivastava, A., Ahuja, R., Mukku, R.: No offense taken: Eliciting offensiveness from language models. arXiv preprint arXiv:2310.00892 (2023)
arXiv 2023
-
[49]
Stanley, K.O., Miikkulainen, R.: Evolving neural networks through augmenting topologies. Evolutionary Computation10(2), 99–127 (06 2002).https://doi.org/ 10.1162/106365602320169811,https://doi.org/10.1162/106365602320169811
-
[50]
Oxford Univer- sity Press (2009)
Sutherland, W.A.: Introduction to metric and topological spaces. Oxford Univer- sity Press (2009)
2009
-
[51]
RSC Adv.2, 5337–5348 (2012).https://doi.org/10
Tan, S.T., Chew, W.: Applications of the improved leader-follower cluster analysis (ilfca) algorithm on large array (la) and very large array (vla) hyperspectral mid- infrared imaging datasets. RSC Adv.2, 5337–5348 (2012).https://doi.org/10. 1039/C2RA20495A,http://dx.doi.org/10.1039/C2RA20495A
-
[52]
arXiv preprint arXiv:2506.07121 (2025)
Wang, R.J., Xue, K., Qin, Z., Li, Z., Tang, S., Li, H.T., Liu, S., Qian, C.: Quality- diversity red-teaming: Automated generation of high-quality and diverse attackers for large language models. arXiv preprint arXiv:2506.07121 (2025)
arXiv 2025
-
[53]
Wei, F.F., Chen, W.N., Zhao, T.F., Tan, K.C., Zhang, J.: A survey on distributed evolutionary computation. IEEE Computational Intelligence Magazine20(3), 41– 62 (2025).https://doi.org/10.1109/MCI.2025.3563425
-
[54]
In- formation Sciences700, 121842 (2025).https://doi.org/https://doi.org/10
Zhou, X., Li, N., Fan, L., Li, H., Cheng, B., Wang, M.: Adaptive niching differen- tial evolution algorithm with landscape analysis for multimodal optimization. In- formation Sciences700, 121842 (2025).https://doi.org/https://doi.org/10. 1016/j.ins.2024.121842,https://www.sciencedirect.com/science/article/ pii/S0020025524017560 Distributed Quality-Diversi...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.