ECHO-PPI: Trustworthy AI for Evidence-Bundled Detection of Overlapping Protein Modules in Protein-Protein Interaction Networks
Pith reviewed 2026-05-21 01:17 UTC · model grok-4.3
The pith
ECHO-PPI attaches topology, semantic, and Gene Ontology scores plus hierarchical labels to each overlapping protein-module assignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
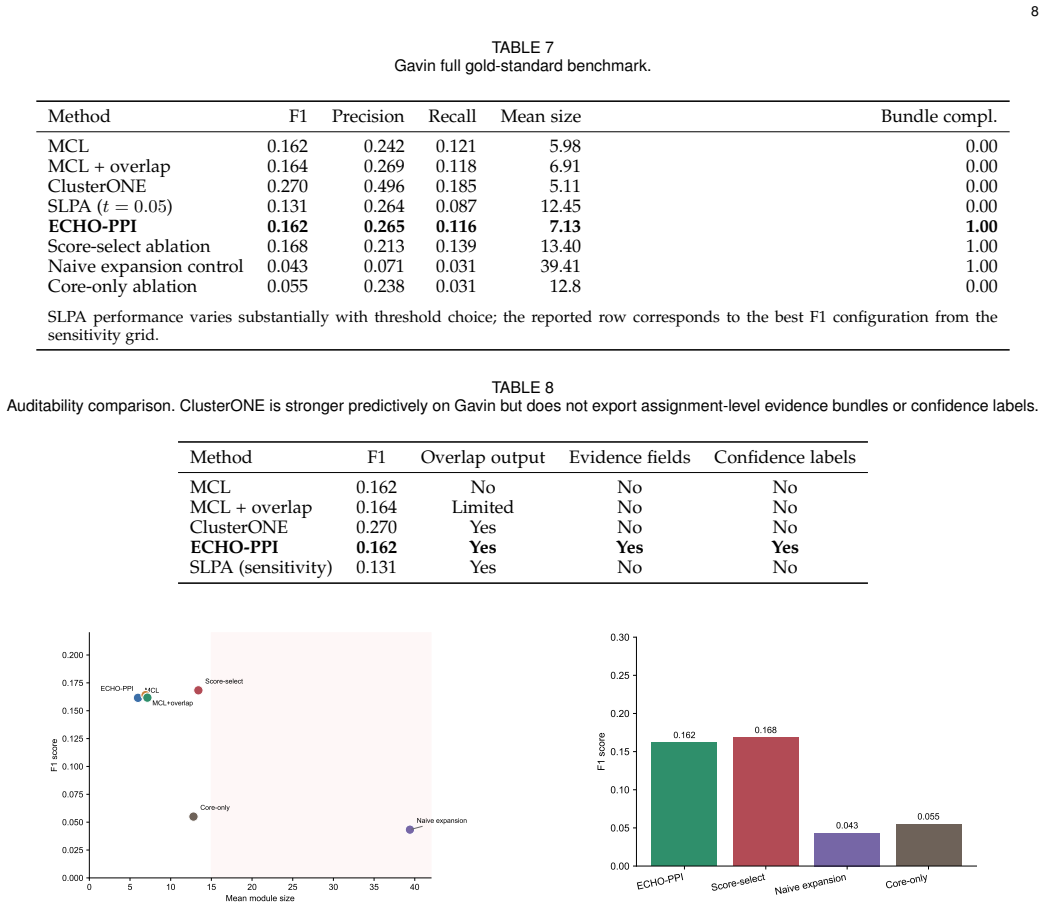
ECHO-PPI integrates weighted network topology, semantic protein profiles, and Gene Ontology evidence to identify evidence-potential nuclei, construct candidate modules, perform overlap-aware assignment, and export hierarchical confidence labels. Each protein-module assignment carries separate topology, semantic, and Gene Ontology evidence scores together with a hierarchical confidence label. This produces assignment-level interpretability that lets curators inspect, rank, and triage overlapping predictions while the underlying detection behavior matches strong baselines on yeast protein-interaction data.
What carries the argument
evidence-bundled assignment process that converts topology, semantic profiles, and Gene Ontology data into per-assignment scores and hierarchical confidence labels
If this is right
- Each protein-module assignment becomes inspectable at the individual level rather than only at the module level.
- Curators can rank and triage predictions using the hierarchical confidence labels.
- The framework maintains the module recovery performance of strong overlap-aware baselines on yeast data.
- Predictions gain reproducibility for downstream biological interpretation through explicit evidence trails.
Where Pith is reading between the lines
- The same evidence-bundling pattern could be tested on human PPI networks to check whether the labels improve prioritization of disease-related modules.
- If the confidence labels align with independent functional coherence measures, they might serve as a signal to refine Gene Ontology annotations themselves.
- The approach suggests a template for adding auditability to other overlapping community detection tasks outside biology, such as social or citation networks.
Load-bearing premise
Bundling topology, semantic, and Gene Ontology evidence into per-assignment scores and hierarchical labels will produce trustworthy, actionable interpretability for biologists while preserving detection behavior of strong overlap-aware baselines.
What would settle it
A controlled test on new yeast or human PPI data in which biologists triage and validate module assignments using only the raw clusters versus the same clusters with ECHO-PPI evidence scores and labels would falsify the claim if the added labels show no measurable gain in triage speed, agreement with known complexes, or experimental follow-up success.
Figures










read the original abstract
Protein-protein interaction networks provide a graph-level view of cellular organization, yet their functional modules are overlapping, noisy, and difficult to interpret from cluster assignments alone. Existing community-detection methods can recover candidate protein complexes, but they rarely explain why an individual protein is assigned to a specific module or whether that assignment should be treated as core, peripheral, or uncertain. Here we introduce ECHO-PPI, an evidence-bundled framework for interpretable overlapping protein-module detection in protein-protein interaction networks. ECHO-PPI integrates weighted network topology, semantic protein profiles, and Gene Ontology evidence to identify evidence-potential nuclei, construct candidate modules, perform overlap-aware assignment, and export hierarchical confidence labels. The framework supports trustworthy computational decision support through assignment-level interpretability: each protein-module assignment is accompanied by topology, semantic, and Gene Ontology evidence scores and a hierarchical confidence label, enabling curators to inspect, rank, and triage overlapping module predictions. Evaluation on yeast protein-interaction data shows that ECHO-PPI preserves the behaviour of strong overlap-aware baselines while adding evidence-bundled auditability. Rather than claiming universal predictive superiority, ECHO-PPI addresses a complementary need: making overlapping protein-module predictions inspectable, confidence-aware, and reproducible for downstream biological interpretation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ECHO-PPI, an evidence-bundled framework for interpretable overlapping protein-module detection in PPI networks. It integrates weighted network topology, semantic protein profiles, and Gene Ontology evidence to identify evidence-potential nuclei, construct candidate modules, perform overlap-aware assignment, and export hierarchical confidence labels for each protein-module assignment. The central claim is that this approach preserves the detection behavior of strong overlap-aware baselines on yeast protein-interaction data while adding assignment-level interpretability, evidence scores, and auditability for curators and biologists.
Significance. If the preservation of baseline behavior is quantitatively verified, the work could meaningfully advance trustworthy AI applications in computational biology by addressing the need for inspectable, confidence-aware predictions rather than opaque cluster assignments. The bundling of multiple evidence types into per-assignment scores and hierarchical labels targets a practical gap in existing overlapping module detection methods. However, the current lack of reported metrics makes it difficult to gauge whether the framework delivers on its no-tradeoff promise or represents a substantive methodological advance.
major comments (2)
- [Abstract / Evaluation section] Abstract and evaluation description: the claim that 'evaluation on yeast protein-interaction data shows that ECHO-PPI preserves the behaviour of strong overlap-aware baselines' is presented without any quantitative metrics (e.g., module overlap Jaccard, NMI, or per-protein assignment agreement), baseline identities, or comparison tables. This directly undermines the central value proposition that interpretability is added without altering detection behavior.
- [Method / Evaluation] Framework description: the overlap-aware assignment step and hierarchical confidence labeling are described as preserving baseline outputs, yet no explicit verification (such as before/after module sets or agreement statistics) is supplied to confirm that these post-processing stages do not silently modify the recovered modules.
minor comments (2)
- [Abstract] The abstract would benefit from naming the specific strong overlap-aware baselines used and the key quantitative metrics employed to support the preservation claim.
- [Method] Notation for evidence scores (topology, semantic, GO) and hierarchical labels should be defined more explicitly with an example assignment to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight the need for stronger quantitative support of our central claims. We address each major comment below and will revise the manuscript to incorporate the requested metrics and verifications.
read point-by-point responses
-
Referee: [Abstract / Evaluation section] Abstract and evaluation description: the claim that 'evaluation on yeast protein-interaction data shows that ECHO-PPI preserves the behaviour of strong overlap-aware baselines' is presented without any quantitative metrics (e.g., module overlap Jaccard, NMI, or per-protein assignment agreement), baseline identities, or comparison tables. This directly undermines the central value proposition that interpretability is added without altering detection behavior.
Authors: We agree that the current abstract and evaluation description would be strengthened by explicit quantitative metrics. In the revised manuscript we will expand the Evaluation section to include a comparison table reporting module overlap Jaccard indices, normalized mutual information (NMI), and per-protein assignment agreement rates between ECHO-PPI and the strong overlap-aware baselines used. The table will also identify the specific baseline methods. These additions will directly substantiate that the evidence-bundled post-processing preserves the core detection behavior while adding interpretability. revision: yes
-
Referee: [Method / Evaluation] Framework description: the overlap-aware assignment step and hierarchical confidence labeling are described as preserving baseline outputs, yet no explicit verification (such as before/after module sets or agreement statistics) is supplied to confirm that these post-processing stages do not silently modify the recovered modules.
Authors: We acknowledge the absence of explicit verification for the overlap-aware assignment and hierarchical labeling steps. In the revision we will add a new subsection (or supplementary material) that reports agreement statistics, such as the percentage of proteins retaining identical module assignments before and after these stages, together with illustrative before/after module-set examples on a subset of the yeast data. This will confirm that the post-processing layers do not alter the recovered modules. revision: yes
Circularity Check
No circularity: constructive framework with independent evidence integration
full rationale
The ECHO-PPI framework is presented as a constructive pipeline that combines weighted topology, semantic profiles, and Gene Ontology evidence to identify nuclei, build candidate modules, perform overlap-aware assignment, and attach hierarchical confidence labels. No equations, parameter fits, or derivation steps are shown that reduce outputs to inputs by construction, rename fitted quantities as predictions, or rely on self-citations for load-bearing uniqueness claims. The evaluation statement that the method preserves baseline behavior is a qualitative assertion rather than a mathematical reduction, and the overall method remains self-contained against external benchmarks without circular re-derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ECHO-PPI integrates weighted network topology, semantic protein profiles, and Gene Ontology evidence to identify evidence-potential nuclei, construct candidate modules, perform overlap-aware assignment, and export hierarchical confidence labels
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
String v11: protein– protein association networks with increased coverage,
D. Szklarczyk, A. L. Gable, D. Lyonet al., “String v11: protein– protein association networks with increased coverage,”Nucleic Acids Research, vol. 47, no. D1, pp. D607–D613, 2019
work page 2019
-
[2]
Proteome survey reveals modularity of the yeast cell machinery,
A.-C. Gavin, P . Aloy, P . Grandiet al., “Proteome survey reveals modularity of the yeast cell machinery,”Nature, vol. 440, no. 7084, pp. 631–636, 2006
work page 2006
-
[3]
Global landscape of protein complexes in the yeastSaccharomyces cerevisiae,
N. J. Krogan, G. Cagney, H. Yuet al., “Global landscape of protein complexes in the yeastSaccharomyces cerevisiae,”Nature, vol. 440, no. 7084, pp. 637–643, 2006
work page 2006
-
[4]
The EBI Complex Portal: a resource of macromolecular complexes,
B. H. M. Meldal, H. Bye-A-Jee, L. Gajdo ˇset al., “The EBI Complex Portal: a resource of macromolecular complexes,”Nucleic Acids Research, vol. 50, no. D1, pp. D578–D586, 2022
work page 2022
-
[5]
Uncovering the overlapping community structure of complex networks in nature and society,
G. Palla, I. Der ´enyi, I. J. Farkas, and T. Vicsek, “Uncovering the overlapping community structure of complex networks in nature and society,”Nature, vol. 435, no. 7043, pp. 814–818, 2005
work page 2005
-
[6]
Link communities reveal multiscale complexity in networks,
Y.-Y. Ahn, J. P . Bagrow, and S. Lehmann, “Link communities reveal multiscale complexity in networks,”Nature, vol. 466, no. 7307, pp. 761–764, 2010
work page 2010
-
[7]
Graph clustering by flow simulation,
S. van Dongen, “Graph clustering by flow simulation,” Ph.D. dissertation, University of Utrecht, 2000
work page 2000
-
[8]
An efficient algorithm for large-scale detection of protein families,
A. J. Enright, S. Van Dongen, and C. A. Ouzounis, “An efficient algorithm for large-scale detection of protein families,”Nucleic Acids Research, vol. 30, no. 7, pp. 1575–1584, 2002
work page 2002
-
[9]
CFinder: locating cliques and overlapping modules in biological networks,
B. Adamcsek, G. Palla, I. J. Farkas, I. Der ´enyi, and T. Vicsek, “CFinder: locating cliques and overlapping modules in biological networks,”Bioinformatics, vol. 22, no. 8, pp. 1021–1023, 2006
work page 2006
-
[10]
Detecting overlapping protein complexes from protein–protein interaction networks,
T. Nepusz, H. Yu, and A. Paccanaro, “Detecting overlapping protein complexes from protein–protein interaction networks,” Bioinformatics, vol. 28, no. 18, pp. i429–i437, 2012
work page 2012
-
[11]
An automated method for find- ing molecular complexes in large protein interaction networks,
G. D. Bader and C. W. V . Hogue, “An automated method for find- ing molecular complexes in large protein interaction networks,” BMC Bioinformatics, vol. 4, p. 2, 2003
work page 2003
-
[12]
Sentence-BERT: Sentence embed- dings using siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embed- dings using siamese BERT-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019, pp. 3982–3992
work page 2019
-
[13]
Gene ontology: tool for the unification of biology,
M. Ashburner, C. A. Ball, J. A. Blakeet al., “Gene ontology: tool for the unification of biology,”Nature Genetics, vol. 25, no. 1, pp. 25–29, 2000
work page 2000
-
[14]
The gene ontology resource: enriching a GOLD mine,
G. O. Consortiumet al., “The gene ontology resource: enriching a GOLD mine,”Nucleic Acids Research, vol. 49, no. D1, pp. D325– D334, 2021
work page 2021
-
[15]
M. Jalali, A. D. D. Wonanke, P . Friederich, and C. W¨oll, “The black hole strategy: Gravity-based representative sampling for frugal graph learning on metal–organic framework networks,”Journal of Chemical Information and Modeling, vol. 65, no. 20, pp. 10 885–10 902, 2025
work page 2025
-
[16]
Comparative assessment of large-scale data sets of protein–protein interactions,
C. von Mering, R. Krause, B. Snel, M. Cornell, S. G. Oliver, S. Fields, and P . Bork, “Comparative assessment of large-scale data sets of protein–protein interactions,”Nature, vol. 417, no. 6887, pp. 399–403, 2002
work page 2002
-
[17]
BioGRID: a general repository for interaction datasets,
C. Stark, B.-J. Breitkreutz, T. Reguly, L. Boucher, A. Breitkreutz, and M. Tyers, “BioGRID: a general repository for interaction datasets,” Nucleic Acids Research, vol. 34, no. Database issue, pp. D535–D539, 2006
work page 2006
-
[18]
Up-to-date catalogues of yeast protein complexes,
S. Pu, J. Wong, B. Turner, E. Cho, and S. J. Wodak, “Up-to-date catalogues of yeast protein complexes,”Nucleic Acids Research, vol. 37, no. 3, pp. 825–831, 2009
work page 2009
-
[19]
CORUM: the comprehensive resource of mammalian protein complexes–2019,
M. Giurgiu, J. Reinhard, B. Brauner, I. Dunger-Kaltenbach, G. Fobo, G. Frishman, C. Montrone, and A. Ruepp, “CORUM: the comprehensive resource of mammalian protein complexes–2019,” Nucleic Acids Research, vol. 47, no. D1, pp. D559–D563, 2019
work page 2019
-
[20]
Evaluation of clustering algorithms for protein–protein interaction networks,
S. Brohee and J. van Helden, “Evaluation of clustering algorithms for protein–protein interaction networks,”BMC Bioinformatics, vol. 7, p. 488, 2006
work page 2006
-
[21]
Evaluation of network clustering methods for protein–protein interaction networks,
S. Pu, J. Wong, B. Turner, E. Cho, and S. J. Wodak, “Evaluation of network clustering methods for protein–protein interaction networks,”BMC Bioinformatics, vol. 20, p. 58, 2019
work page 2019
-
[22]
S. Patra and T. R. Sahoo, “A review on efficient and scalable graph- based clustering algorithms for protein complex identification in PPI networks,”Proteins: Structure, Function, and Bioinformatics, vol. 94, pp. 477–501, 2026
work page 2026
-
[23]
PRING: Rethinking protein-protein interaction prediction from pairs to graphs,
X. Zheng, H. Du, F. Xu, J. Li, Z. Liu, W. Wang, T. Chen, W. Ouyang, S. Z. Li, Y. Lu, N. Dong, and Y. Zhang, “PRING: Rethinking protein-protein interaction prediction from pairs to graphs,” in Advances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2025
work page 2025
-
[24]
Fast unfolding of communities in large networks,
V . D. Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2008, no. 10, p. P10008, 2008
work page 2008
-
[25]
From Louvain to Leiden: guaranteeing well-connected communities,
V . A. Traag, L. Waltman, and N. J. van Eck, “From Louvain to Leiden: guaranteeing well-connected communities,”Scientific Reports, vol. 9, p. 5233, 2019
work page 2019
-
[26]
Detecting the overlapping and hierarchical community structure in complex networks,
A. Lancichinetti, S. Fortunato, and J. Kert ´esz, “Detecting the overlapping and hierarchical community structure in complex networks,”New Journal of Physics, vol. 11, no. 3, p. 033015, 2009
work page 2009
-
[27]
J. Xie, B. K. Szymanski, and X. Liu, “SLPA: Uncovering overlap- ping communities in social networks via a speaker-listener inter- action dynamic process,” inProceedings of the IEEE International Conference on Data Mining Workshops, 2011, pp. 344–349
work page 2011
-
[28]
Extending the definition of modularity to directed graphs with overlapping communities,
V . Nicosia, G. Mangioni, V . Carchiolo, and M. Malgeri, “Extending the definition of modularity to directed graphs with overlapping communities,”Journal of Statistical Mechanics: Theory and Experi- ment, vol. 2009, no. 03, p. P03024, 2009
work page 2009
-
[29]
RDS: A ReCIPE for overlapping community detection in biological networks,
F. Ocitti, C. Versavel, S. Sledzieski, and L. Cowen, “RDS: A ReCIPE for overlapping community detection in biological networks,” in Proceedings of the 16th ACM International Conference on Bioinformat- ics, Computational Biology, and Health Informatics, 2025, pp. 1–6
work page 2025
-
[30]
A survey on overlapping commu- nity detection: label propagation,
S. Goswami and A. K. Singh, “A survey on overlapping commu- nity detection: label propagation,”Multimedia Tools and Applica- tions, vol. 84, pp. 32 563–32 592, 2025
work page 2025
-
[31]
Overlapping community detection with a new modularity measure in directed weighted networks,
A. Kumar, A. Kumari, P . Kumar, and R. Dohare, “Overlapping community detection with a new modularity measure in directed weighted networks,”Data Mining and Knowledge Discovery, vol. 39, no. 6, p. 77, 2025
work page 2025
-
[32]
H. N. Chua, W.-K. Sung, and L. Wong, “Exploiting indirect neigh- bours and topological weight to predict protein function from protein–protein interactions,”Bioinformatics, vol. 22, no. 13, pp. 1623–1630, 2006
work page 2006
-
[33]
M. Abbas, D. Broneske, and G. Saake, “Improving the perfor- mance of evolutionary-based complex detection models using gene ontology-based mutation operator in protein-protein interac- tion networks,” inIntelligent Systems and Applications, ser. Lecture Notes in Networks and Systems, K. Arai, Ed. Cham: Springer, 2025, vol. 1553, pp. 512–528
work page 2025
-
[34]
J. Tu, R. Li, X. Gao, and L. Ma, “A novel GAER-GMM framework for overlapping protein complex detection in protein interaction networks,”IEEE Transactions on Computational Biology and Bioinfor- matics, vol. 22, no. 6, pp. 3486–3499, 2025
work page 2025
-
[35]
On the permanence of vertices in network com- munities,
T. Chakraborty, S. Srinivasan, N. Ganguly, A. Mukherjee, and S. Bhowmick, “On the permanence of vertices in network com- munities,” inProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2014, pp. 1396– 1405
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.