SSRLive: Live Streaming Recommendation with Dynamic Semantic ID
Pith reviewed 2026-06-27 20:57 UTC · model grok-4.3
The pith
A unified generative-discriminative model with dynamic semantic IDs improves live streaming recommendations by capturing changing content and user interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating a generative module using encoder-decoder for static and dynamic semantic IDs with a discriminative module that augments representations with user-streamer interaction signals enables timely content representation and better user intent modeling, resulting in tangible benefits in watch time, GMV, follower growth, and interaction volume in real-world deployment.
What carries the argument
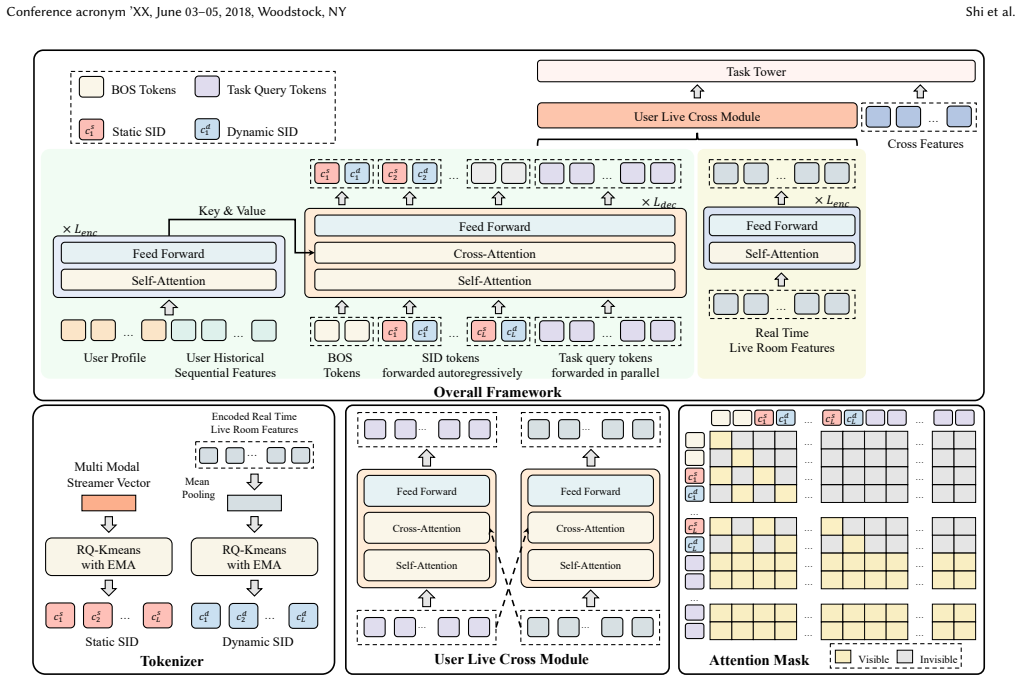
The encoder-decoder design in the generative module that produces both static and dynamic SIDs from multimodal information, combined with the discriminative module that combines SIDs with user features and augments them with interaction data for multi-task predictions.
If this is right
- Dynamic SIDs allow timely representation of live room content changes.
- User-streamer interaction signals improve modeling of user intent toward streamers and products.
- Online deployment shows gains of 3.38% in watch time, 0.72% in GMV, 3.12% in follower growth, and 2.92% in interaction volume.
- The framework is now fully deployed serving hundreds of millions of users.
Where Pith is reading between the lines
- Similar dynamic ID approaches could extend to other real-time recommendation domains like short-form video or news feeds.
- Combining generative and discriminative modules might reduce the computational limitations of low-FLOP models while enhancing performance.
- Multimodal information integration in SID generation could be tested for robustness across different live content types.
Load-bearing premise
That static semantic IDs cannot reflect the rapidly changing nature of live room content and that generative pipelines generally do not incorporate user-streamer interaction signals which are critical for modeling user intent.
What would settle it
A controlled experiment comparing recommendation performance with and without dynamic SIDs or user interaction signals in a live streaming platform, measuring if the reported metric improvements disappear.
Figures


read the original abstract
Live streaming has emerged as one of the fastest-growing forms of online media, enabling instant content broadcasting and real-time engagement between users and streamers. Despite the effectiveness of existing recommendation algorithms in this domain, they often suffer from limited utilization of computational resources, with low FLOPs that hinder further performance enhancement. Generative recommendation techniques, which have gained traction in various industrial tasks, offer a promising avenue for improving live streaming recommendations. However, directly applying generative methods to live streaming is non-trivial due to two major challenges: (1) static semantic IDs (SIDs) cannot reflect the rapidly changing nature of live room content; and (2) generative pipelines generally do not incorporate user--streamer interaction signals (e.g., likes, orders), which are critical for modeling user intent toward both the streamer and showcased products. To address these challenges, we introduce SSRLive: Dynamic Semantic ID-guided Streaming Recommendation for Live platforms. The proposed framework integrates a generative module and a discriminative module in a unified architecture. The generative component employs an encoder-decoder design to produce both static and dynamic SIDs, enabling timely representation of live room content while leveraging multimodal information. The discriminative component refines task-specific representations by combining SIDs with user features, augments them with user-streamer interaction data, and performs multi-task predictions. Online A/B tests in real-world deployment demonstrate tangible benefits: watch time (+3.38%), GMV (+0.72%), follower growth (+3.12%), and interaction volume (+2.92%). These improvements highlight the effectiveness and business value of SSRLive, which is now fully deployed, serving hundreds of millions of active users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SSRLive, a unified generative-discriminative architecture for live streaming recommendation. The generative module uses an encoder-decoder to produce static and dynamic semantic IDs (SIDs) from multimodal information to address rapidly changing live room content. The discriminative module combines SIDs with user features, augments them with user-streamer interaction signals (likes, orders), and performs multi-task predictions. Online A/B tests in real-world deployment report gains of +3.38% watch time, +0.72% GMV, +3.12% follower growth, and +2.92% interaction volume, with the system now serving hundreds of millions of users.
Significance. If the A/B results hold under scrutiny, the work would be significant for industrial recommendation systems by extending generative methods to dynamic live-streaming settings and explicitly incorporating user-streamer interaction signals, which are often omitted in standard generative pipelines. The deployment scale provides a strong real-world testbed for such techniques.
major comments (2)
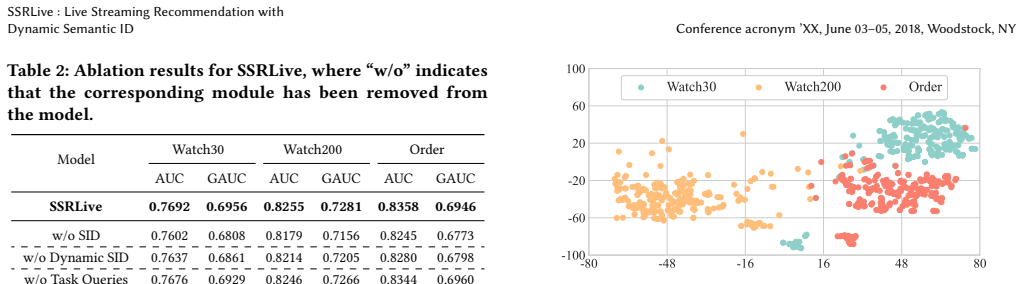
- [Abstract] Abstract (and presumably §4 or §5 on experiments): the central claim of tangible benefits rests on the reported A/B test gains, yet no baselines, statistical significance tests, experiment duration, traffic split, or controls for selection effects are supplied. This information is load-bearing for assessing whether the dynamic-SID and interaction-signal components drive the observed lifts.
- [Abstract] Abstract (and generative module description): the claim that static SIDs cannot reflect changing live content and that generative pipelines omit user-streamer signals is presented as motivation, but without equations or ablation results it is unclear whether the encoder-decoder design for dynamic SIDs or the interaction augmentation actually resolves these issues beyond what a standard multimodal encoder would achieve.
minor comments (1)
- The abstract mentions 'low FLOPs' as a limitation of existing methods but does not quantify this or compare computational cost of SSRLive.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to supply the requested details and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract (and presumably §4 or §5 on experiments): the central claim of tangible benefits rests on the reported A/B test gains, yet no baselines, statistical significance tests, experiment duration, traffic split, or controls for selection effects are supplied. This information is load-bearing for assessing whether the dynamic-SID and interaction-signal components drive the observed lifts.
Authors: We agree that the A/B test description requires additional rigor. In the revised manuscript we will expand §5 (and the abstract) to report the baseline models, statistical significance tests with p-values, experiment duration, traffic allocation, and any stratification or other controls used to mitigate selection effects. revision: yes
-
Referee: [Abstract] Abstract (and generative module description): the claim that static SIDs cannot reflect changing live content and that generative pipelines omit user-streamer signals is presented as motivation, but without equations or ablation results it is unclear whether the encoder-decoder design for dynamic SIDs or the interaction augmentation actually resolves these issues beyond what a standard multimodal encoder would achieve.
Authors: We accept that the motivation would be strengthened by formalization and empirical isolation. The revised manuscript will include explicit equations for the encoder-decoder that produces dynamic SIDs and will add ablation studies that compare against a standard multimodal encoder baseline as well as a variant without the user-streamer interaction signals. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract (and by extension the paper's described claims) presents a generative-discriminative architecture for dynamic SIDs in live streaming recommendation, along with reported A/B test gains, but contains no equations, parameter-fitting procedures, self-citations, or derivation steps that reduce to inputs by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations are present in the text. The central claims rest on empirical deployment results and multimodal integration rather than any internally circular mathematical chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023). SSRLive : Live Streaming Recommendation with Dynamic Semantic ID Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
Pith/arXiv arXiv 2023
-
[2]
Xingyan Bin, Jianfei Cui, Wujie Yan, Zhichen Zhao, Xintian Han, Chongyang Yan, Feng Zhang, Xun Zhou, Xiao Yang, and Zuotao Liu. 2025. Real-time Indexing for Large-scale Recommendation by Streaming Vector Quantization Retriever. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4273–4283
2025
-
[3]
Jiangxia Cao, Shen Wang, Yue Li, Shenghui Wang, Jian Tang, Shiyao Wang, Shuang Yang, Zhaojie Liu, and Guorui Zhou. 2024. Moment&Cross: Next- Generation Real-Time Cross-Domain CTR Prediction for Live-Streaming Recom- mendation at Kuaishou.arXiv preprint arXiv:2408.05709(2024)
arXiv 2024
-
[4]
Jianxin Chang, Chenbin Zhang, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, and Kun Gai. 2023. Pepnet: Parameter and embedding personalized network for infusing with personalized prior information. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3795–3804
2023
-
[5]
Ben Chen, Xian Guo, Siyuan Wang, Zihan Liang, Yue Lv, Yufei Ma, Xinlong Xiao, Bowen Xue, Xuxin Zhang, Ying Yang, et al . 2025. Onesearch: A preliminary exploration of the unified end-to-end generative framework for e-commerce search.arXiv preprint arXiv:2509.03236(2025)
arXiv 2025
-
[6]
Sunhao Dai, Jiakai Tang, Jiahua Wu, Kun Wang, Yuxuan Zhu, Bingjun Chen, Bangyang Hong, Yu Zhao, Cong Fu, Kangle Wu, et al. 2025. OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System.arXiv preprint arXiv:2509.18091(2025)
arXiv 2025
-
[7]
Jiaxin Deng, Dong Shen, Shiyao Wang, Xiangyu Wu, Fan Yang, Guorui Zhou, and Gaofeng Meng. 2023. ContentCTR: Frame-level live streaming click-through rate prediction with multimodal transformer.arXiv preprint arXiv:2306.14392 (2023)
arXiv 2023
-
[8]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
Pith/arXiv arXiv 2025
-
[9]
Jiaxin Deng, Shiyao Wang, Dong Shen, Liqin Zhao, Fan Yang, Guorui Zhou, and Gaofeng Meng. 2024. A Multimodal Transformer for Live Streaming Highlight Prediction. In2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
2024
-
[10]
Kairui Fu, Tao Zhang, Shuwen Xiao, Ziyang Wang, Xinming Zhang, Chenchi Zhang, Yuliang Yan, Junjun Zheng, Yu Li, Zhihong Chen, et al . 2025. Forge: Forming semantic identifiers for generative retrieval in industrial datasets.arXiv preprint arXiv:2509.20904(2025)
Pith/arXiv arXiv 2025
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[12]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
-
[13]
Yanhua Huang, Yuqi Chen, Xiong Cao, Rui Yang, Mingliang Qi, Yinghao Zhu, Qingchang Han, Yaowei Liu, Zhaoyu Liu, Xuefeng Yao, et al . 2025. Towards Large-scale Generative Ranking.arXiv preprint arXiv:2505.04180(2025)
arXiv 2025
-
[14]
Jiarui Jin, Xianyu Chen, Yuanbo Chen, Weinan Zhang, Renting Rui, Zaifan Jiang, Zhewen Su, and Yong Yu. 2022. Who to watch next: Two-side interactive networks for live broadcast recommendation. InProceedings of the ACM Web Conference
2022
-
[15]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE International Conference on Data Mining (ICDM). IEEE, 197–206
2018
-
[16]
Hsu-Chao Lai, Philip S Yu, and Jiun-Long Huang. 2023. Learning the Co-evolution Process on Live Stream Platforms with Dual Self-attention for Next-topic Recom- mendations. InProceedings of the 32nd ACM International Conference on Informa- tion and Knowledge Management. 1158–1167
2023
-
[17]
Xiaodong Li, Ruochen Yang, Shuang Wen, Shen Wang, Yueyang Liu, Guoquan Wang, Weisong Hu, Qiang Luo, Jiawei Sheng, Tingwen Liu, et al. 2025. FARM: Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation. arXiv preprint arXiv:2502.09375(2025)
arXiv 2025
-
[18]
Fengqi Liang, Baigong Zheng, Liqin Zhao, Guorui Zhou, Qian Wang, and Yanan Niu. 2024. Ensure Timeliness and Accuracy: A Novel Sliding Window Data Stream Paradigm for Live Streaming Recommendation.arXiv preprint arXiv:2402.14399 (2024)
arXiv 2024
-
[19]
Zida Liang, Changfa Wu, Dunxian Huang, Weiqiang Sun, Ziyang Wang, Yuliang Yan, Jian Wu, Yuning Jiang, Bo Zheng, Ke Chen, et al. 2025. Tbgrecall: A generative retrieval model for e-commerce recommendation scenarios. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5863–5870
2025
-
[20]
Yueyang Liu, Jiangxia Cao, Shen Wang, Shuang Wen, Xiang Chen, Xiangyu Wu, Shuang Yang, Zhaojie Liu, Kun Gai, and Guorui Zhou. 2025. LLM-Alignment Live-Streaming Recommendation.arXiv preprint arXiv:2504.05217(2025)
arXiv 2025
-
[21]
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al
-
[22]
Onerec-think: In-text reasoning for generative recommendation.arXiv preprint arXiv:2510.11639(2025)
arXiv 2025
-
[23]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
Pith/arXiv arXiv 2017
-
[24]
Yucheng Lu, Jiangxia Cao, Xu Kuan, Wei Cheng, Wei Jiang, Jiaming Zhang, Yang Shuang, Liu Zhaojie, and Liyin Hong. 2025. LiveForesighter: Generating Future Information for Live-Streaming Recommendations at Kuaishou.arXiv preprint arXiv:2502.06557(2025)
arXiv 2025
-
[25]
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al . 2025. Qarm: Quantitative alignment multi-modal recommendation at kuaishou. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5915– 5922
2025
-
[26]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole- Jean Wu, Alisson G Azzolini, et al. 2019. Deep learning recommendation model for personalization and recommendation systems.arXiv preprint arXiv:1906.00091 (2019)
Pith/arXiv arXiv 2019
-
[27]
Changle Qu, Sunhao Dai, Ke Guo, Liqin Zhao, Yanan Niu, Xiao Zhang, and Jun Xu. 2025. KuaiLive: A Real-time Interactive Dataset for Live Streaming Recommendation.arXiv preprint arXiv:2508.05633(2025)
Pith/arXiv arXiv 2025
-
[28]
Changle Qu, Liqin Zhao, Yanan Niu, Xiao Zhang, and Jun Xu. 2025. Bridging Short Videos and Streamers with Multi-Graph Contrastive Learning for Live Streaming Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2059–2069
2025
-
[29]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[30]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[31]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[32]
Jiakai Tang, Sunhao Dai, Teng Shi, Jun Xu, Xu Chen, Wen Chen, Jian Wu, and Yuning Jiang. 2025. Think before recommend: Unleashing the latent reasoning power for sequential recommendation.arXiv preprint arXiv:2503.22675(2025)
arXiv 2025
-
[33]
Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning.Advances in neural information processing systems30 (2017)
2017
-
[34]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, 11 (2008)
2008
-
[35]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
-
[36]
Dinghao Xi, Liumin Tang, Runyu Chen, and Wei Xu. 2023. A multimodal time- series method for gifting prediction in live streaming platforms.Information Processing & Management60, 3 (2023), 103254
2023
-
[37]
Guang Xu, Ming Ren, Zhenhua Wang, and Guozhi Li. 2024. MEMF: Multi-entity multimodal fusion framework for sales prediction in live streaming commerce. Decision Support Systems184 (2024), 114277
2024
-
[38]
Xiaoyong Yang, Yadong Zhu, Yi Zhang, Xiaobo Wang, and Quan Yuan. 2020. Large scale product graph construction for recommendation in e-commerce. arXiv preprint arXiv:2010.05525(2020)
arXiv 2020
-
[39]
Yuhao Yang, Zhi Ji, Zhaopeng Li, YI LI, Zhonglin Mo, Yue Ding, Kai Chen, Zijian Zhang, Jie Li, shuanglong li, and LIU LIN. 2025. Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[40]
Sanshi Yu, Zhuoxuan Jiang, Dong-Dong Chen, Shanshan Feng, Dongsheng Li, Qi Liu, and Jinfeng Yi. 2021. Leveraging tripartite interaction information from live stream e-commerce for improving product recommendation. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 3886–3894
2021
-
[41]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Jiayuan He, et al. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. In International Conference on Machine Learning. PMLR, 58484–58509
2024
-
[42]
Jun Zhang, Yi Li, Yue Liu, Changping Wang, Yuan Wang, Yuling Xiong, Xun Liu, Haiyang Wu, Qian Li, Enming Zhang, et al. 2025. GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation. arXiv preprint arXiv:2511.10138(2025)
arXiv 2025
-
[43]
Shuai Zhang, Hongyan Liu, Jun He, Sanpu Han, and Xiaoyong Du. 2021. A deep bi-directional prediction model for live streaming recommendation.Information Processing & Management58, 2 (2021), 102453
2021
-
[44]
Shuai Zhang, Hongyan Liu, Lang Mei, Jun He, and Xiaoyong Du. 2022. Predict- ing viewer’s watching behavior and live streaming content change for anchor recommendation.Applied Intelligence52, 3 (2022), 2480–2495
2022
-
[45]
Yixin Zhang, Yong Liu, Hao Xiong, Yi Liu, Fuqiang Yu, Wei He, Yonghui Xu, Lizhen Cui, and Chunyan Miao. 2023. Cross-domain disentangled learning for e-commerce live streaming recommendation. In2023 IEEE 39th International Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Shi et al. Conference on Data Engineering (ICDE). IEEE, 2955–2968
2023
-
[46]
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. 2025. OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender.arXiv preprint arXiv:2510.26104(2025)
arXiv 2025
-
[47]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.182231, 2 (2023)
Pith/arXiv arXiv 2023
-
[48]
Yang Zhao, Xuan Lin, Wenqiang Xu, Maozong Zheng, Zhengyong Liu, and Zhou Zhao. 2022. Antpivot: Livestream highlight detection via hierarchical attention mechanism.arXiv preprint arXiv:2206.04888(2022)
arXiv 2022
-
[49]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
2024
-
[50]
Jiawei Zheng, Hao Gu, Chonggang Song, Dandan Lin, Lingling Yi, and Chuan Chen. 2023. Dual interests-aligned graph auto-encoders for cross-domain recom- mendation in wechat. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4988–4994
2023
-
[51]
Zuowu Zheng, Ze Wang, Fan Yang, Jiangke Fan, Teng Zhang, and Xingxing Wang. 2025. EGA: A Unified End-to-End Generative Framework for Industrial Advertising Systems.arXiv preprint arXiv:2505.17549(2025)
arXiv 2025
-
[52]
Guorui Zhou, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Qiang Luo, Qian- qian Wang, Qigen Hu, Rui Huang, Shiyao Wang, et al. 2025. OneRec Technical Report.arXiv preprint arXiv:2506.13695(2025)
arXiv 2025
-
[53]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900(2025)
Pith/arXiv arXiv 2025
-
[54]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[55]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
2025
-
[56]
Mengxiao Zhu, Qi Shu, Shuanghong Shen, Li Feng, Jiancan Wu, and Zhenya Huang. 2025. Live Streaming Recommendation Based on Multiple Types of Repeated Behaviors.Expert Systems with Applications(2025), 128217. A Experimental Details A.1 Baselines We provide more details about the baselines: DLRM(Production Baseline in the Taobao Live Streaming Sce- nario): ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.