Technology Speed Limits
Pith reviewed 2026-06-28 15:43 UTC · model grok-4.3
The pith
An adaptive speed limit on technology growth gives regulators optimal worst-case guarantees across all learning processes and preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
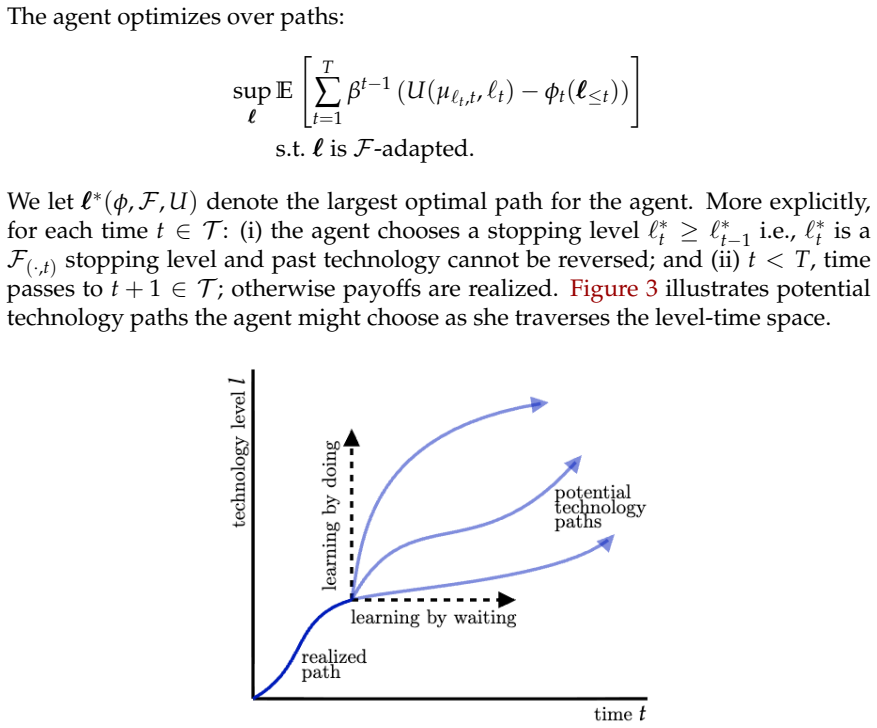
An adaptive speed limit -- a cap on the rate at which the technology can increase per-unit time -- delivers optimal worst-case guarantees over all learning processes and/or preferences, and is the only time-consistent mechanism that does so.
What carries the argument
The adaptive speed limit, a cap on the per-unit-time rate of technology increase, which enforces optimal worst-case performance while maintaining time-consistency.
If this is right
- Regulators obtain the best available guarantees without needing to model the precise form of private learning.
- The same speed limit rule applies uniformly no matter what preferences firms or society hold.
- Time-consistency ensures the policy stays credible and does not invite strategic delays or revisions.
- Alternative regulatory tools such as absolute caps or disclosure requirements cannot match both optimality and consistency simultaneously.
Where Pith is reading between the lines
- Rate-based caps could serve as a template for overseeing rapid capability growth in domains such as artificial intelligence.
- The dual-channel learning setup suggests similar rate rules might apply to other settings where agents improve through action and through time.
- Empirical tests could compare realized outcomes under speed limits versus other rules in controlled market simulations.
Load-bearing premise
The regulator seeks optimal worst-case guarantees over every possible learning process and set of preferences and requires the regulatory mechanism to remain time-consistent.
What would settle it
Identification of any other time-consistent mechanism that achieves strictly superior worst-case guarantees for at least one learning process and preference profile.
Figures




read the original abstract
We study optimal technology regulation when private learning occurs both through doing (scaling up the technology) and through waiting (as time passes). We show that an adaptive speed limit -- a cap on the rate at which the technology can increase per-unit time -- delivers optimal worst-case guarantees over all learning processes and/or preferences, and is the only time-consistent mechanism that does so.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies optimal technology regulation in a setting where private agents learn both by scaling up the technology ('learning by doing') and by the mere passage of time ('learning by waiting'). It claims to show that an adaptive speed limit—a cap on the per-period rate at which the technology level can increase—achieves optimal worst-case guarantees across all possible learning processes and preference structures, and that this mechanism is the unique time-consistent policy with that property.
Significance. If the characterization and uniqueness result hold, the paper supplies a robust, model-free policy instrument for regulating emerging technologies that remains dynamically consistent. This would be a useful contribution to the literature on dynamic mechanism design under Knightian uncertainty, particularly for applications such as AI or biotechnology where the regulator cannot commit to a specific learning model.
minor comments (2)
- The abstract states the optimality and uniqueness claims at a high level; the introduction or §2 should include a brief informal statement of the key assumptions on the learning processes (e.g., whether they are required to be monotone or to satisfy a particular continuity condition) so that readers can immediately assess the scope of the worst-case result.
- Notation for the adaptive cap (presumably defined in §3 or §4) should be introduced with an explicit functional form or recursive definition early in the text, rather than only in the formal statements, to improve readability for non-specialists.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee accurately captures the paper's focus on optimal technology regulation under dual learning channels and the role of adaptive speed limits as a robust, time-consistent mechanism.
Circularity Check
No significant circularity detected
full rationale
The abstract frames the adaptive speed limit result as a derived characterization of the regulator's robust optimization problem under time-consistency, with no equations or definitions supplied that reduce the claimed optimality or uniqueness to a fitted parameter, self-referential definition, or prior self-citation chain. No load-bearing steps of the enumerated kinds are visible from the given material, and the derivation is presented as self-contained against the stated worst-case and dynamic-consistency criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Private learning occurs both through doing (scaling up the technology) and through waiting (as time passes).
Reference graph
Works this paper leans on
-
[1]
Acta Math
Stochastic integrals in the plane , author=. Acta Math. , volume =
-
[2]
arXiv preprint arXiv:2408.17398 , year=
Robust Technology Regulation , author=. arXiv preprint arXiv:2408.17398 , year=
-
[3]
2006 , publisher=
Multiparameter processes: an introduction to random fields , author=. 2006 , publisher=
2006
-
[4]
Pause Giant AI Experiments: An Open Letter , year =
-
[5]
1998 , origyear =
Butler, Samuel , title =. 1998 , origyear =
1998
-
[6]
American Economic Review: Insights , volume=
Regulating transformative technologies , author=. American Economic Review: Insights , volume=. 2024 , publisher=
2024
-
[7]
Economic Policy , volume=
How learning about harms impacts the optimal rate of artificial intelligence adoption , author=. Economic Policy , volume=. 2025 , publisher=
2025
-
[8]
2023 , institution=
Regulating artificial intelligence , author=. 2023 , institution=
2023
-
[9]
American Economic Review: Insights , volume=
The AI dilemma: Growth versus existential risk , author=. American Economic Review: Insights , volume=. 2024 , publisher=
2024
-
[10]
2024 , institution=
Existential risk and growth , author=. 2024 , institution=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.