Distributional Portfolio Optimization (DPO): A Unified Framework for Distributions over Weights, Returns, and Parameters
Pith reviewed 2026-06-28 23:32 UTC · model grok-4.3
The pith
A joint coupling of weights, returns and parameters unifies multiple portfolio optimization approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
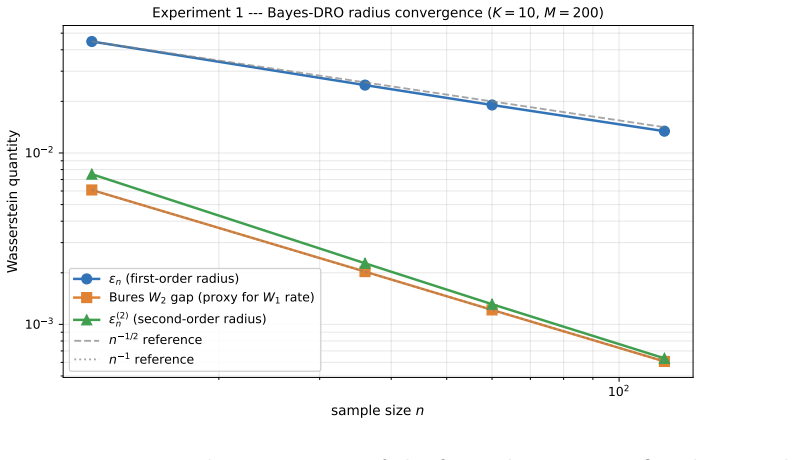
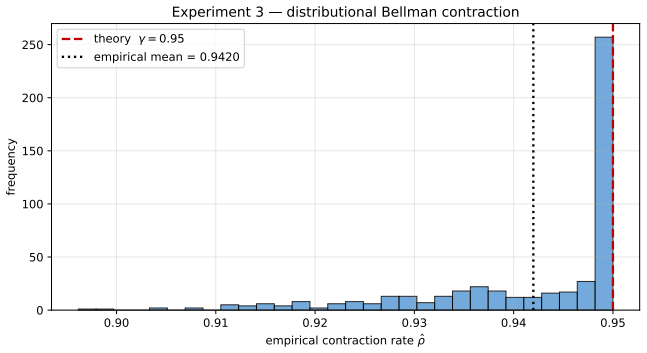
We call distributional portfolio optimization (DPO) the unified framework in which weights, returns, and parameters are all modeled as probability measures, organized around the joint coupling Gamma_theta(dw,dr) and its marginal triple (W,R,P). The contribution is synthetic and structural: we organize Bayesian, robust, chance-constrained, stochastic-allocation, and distributional reinforcement-learning portfolio methods through this coupling and prove boundary results connecting them, including a portfolio specialization of Wasserstein-CVaR duality, a static no-randomization theorem, a Bayesian credible-radius calibration of Wasserstein DRO, a Gaussian-isotropic second-order conservatism bou
What carries the argument
the joint coupling Gamma_theta(dw,dr) and its marginal triple (W,R,P) that links distributions over weights, returns, and parameters
If this is right
- A portfolio specialization of Wasserstein-CVaR duality holds under the framework.
- A static no-randomization theorem is established.
- Wasserstein DRO can be calibrated using Bayesian credible radii.
- Gaussian-isotropic second-order conservatism bounds apply.
- A risk-shifted distributional Bellman contraction governs the RL case.
Where Pith is reading between the lines
- The credible-radius approach could reduce the need for hold-out data in portfolio calibration across factor models.
- Connections between methods may enable hybrid algorithms that combine elements from Bayesian and robust optimization.
- Sample complexity results indicate that smoother distribution boundaries lead to faster convergence rates for Wasserstein distances.
Load-bearing premise
The joint coupling Gamma_theta(dw,dr) and its marginal triple (W,R,P) can serve as a complete organizing structure for Bayesian, robust, chance-constrained, stochastic-allocation, and distributional reinforcement-learning portfolio methods without material loss of structure or applicability for any of them.
What would settle it
A demonstration that any one of the listed portfolio methods cannot be faithfully represented by the joint coupling without losing key properties would falsify the central unification claim.
Figures
read the original abstract
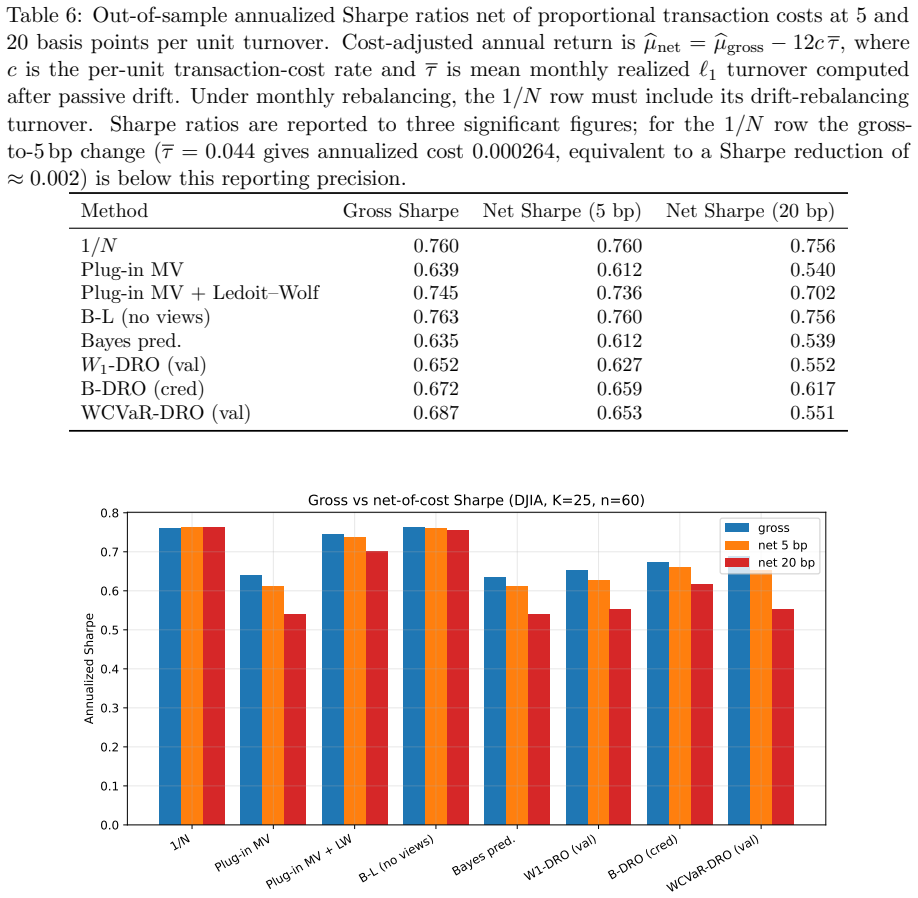
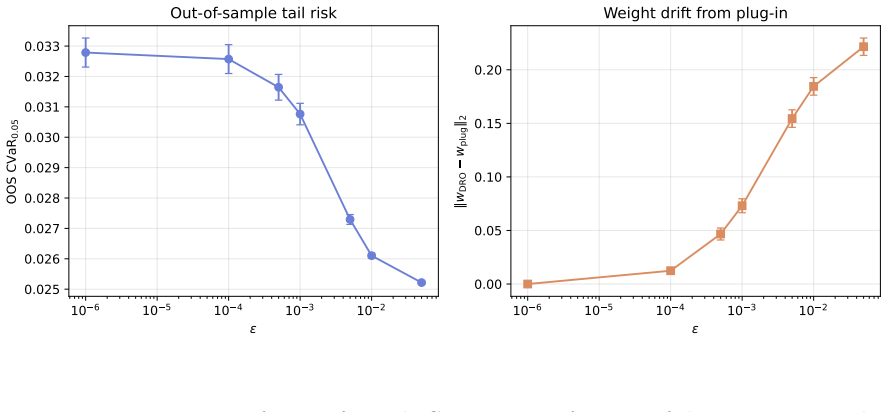
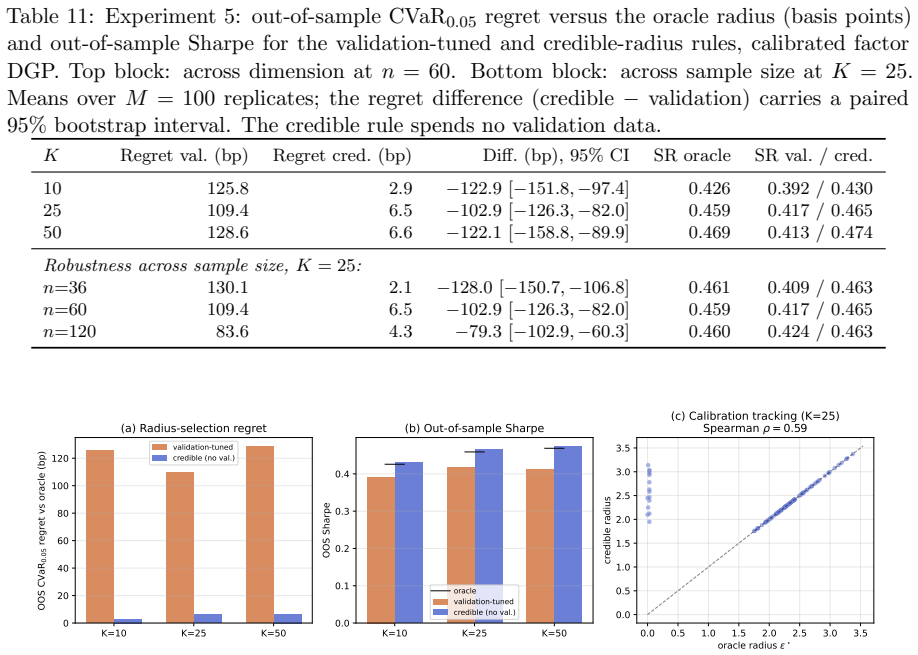
Classical portfolio optimization treats expected returns, covariances, and allocations as deterministic. Modern practice replaces at least one by a distribution: a posterior over parameters, a law of future returns, a stochastic allocation policy, or a distributional-robustness set. We call distributional portfolio optimization (DPO) the unified framework in which weights, returns, and parameters are all modeled as probability measures, organized around the joint coupling Gamma_theta(dw,dr) and its marginal triple (W,R,P). The contribution is synthetic and structural: we organize Bayesian, robust, chance-constrained, stochastic-allocation, and distributional reinforcement-learning portfolio methods through this coupling and prove boundary results connecting them, including a portfolio specialization of Wasserstein-CVaR duality, a static no-randomization theorem, a Bayesian credible-radius calibration of Wasserstein DRO, a Gaussian-isotropic second-order conservatism bound, a conditional two-sided rate W_1 = Theta(n^{-(1+alpha)/2}) governed by the local boundary Holder exponent alpha in [0,1], and a risk-shifted distributional Bellman contraction. A controlled experiment shows that across factor models at K in {10,25,50}, the credible-radius rule lands within 3-7 bp of the oracle out-of-sample tail risk and beats a 24-month validation-tuned radius while spending no validation data. On a K=25 DJIA backtest, equal-weight, no-view Black-Litterman, and Ledoit-Wolf shrinkage attain higher Sharpe than every distributional method; the operational claim is therefore confined to calibration-without-validation and turnover, not raw-return dominance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Distributional Portfolio Optimization (DPO) as a unified framework in which weights, returns, and parameters are modeled as probability measures, organized around the joint coupling Gamma_theta(dw,dr) and its marginal triple (W,R,P). It synthesizes Bayesian, robust, chance-constrained, stochastic-allocation, and distributional reinforcement-learning methods through this structure and proves several boundary results, including a portfolio specialization of Wasserstein-CVaR duality, a static no-randomization theorem, a Bayesian credible-radius calibration of Wasserstein DRO, a Gaussian-isotropic second-order conservatism bound, a conditional two-sided rate W_1 = Theta(n^{-(1+alpha)/2}) governed by the local boundary Holder exponent alpha, and a risk-shifted distributional Bellman contraction. A controlled experiment across factor models (K in {10,25,50}) shows the credible-radius rule approximates oracle out-of-sample tail risk within 3-7 bp and outperforms a 24-month validation-tuned radius without using validation data. On a K=25 DJIA backtest, equal-weight, no-view Black-Litterman, and Ledoit-Wolf shrinkage attain higher Sharpe ratios than distributional methods; the operational claim is limited to calibration-without-validation and turnover.
Significance. If the derivations and experimental controls hold, the paper delivers a synthetic unification of disparate portfolio optimization approaches under a common distributional coupling, together with several explicit boundary results that connect them. The concrete experimental demonstration of a validation-free calibration rule that stays within a few basis points of oracle tail risk is a practical contribution. The manuscript explicitly notes that distributional methods do not dominate traditional approaches on Sharpe ratio in the reported backtest, which strengthens the scope of the claims. No machine-checked proofs or open code are referenced in the provided text.
minor comments (3)
- The abstract and introduction would benefit from an explicit statement of the precise sense in which the joint coupling Gamma_theta serves as a 'complete organizing structure' for all listed methods (Bayesian, robust, chance-constrained, etc.), including any limitations on applicability.
- The experiment section should report the precise definition of the 'oracle' tail-risk benchmark and the number of Monte Carlo replications used to obtain the 3-7 bp figure, to allow direct assessment of statistical variability.
- Notation for the marginal triple (W,R,P) and its relation to the coupling Gamma_theta(dw,dr) is introduced without a dedicated diagram or table; a small schematic would improve readability for readers unfamiliar with the coupling construction.
Simulated Author's Rebuttal
We thank the referee for the thorough summary and the recommendation of minor revision. The report correctly identifies the synthetic and structural contributions of the DPO framework, the boundary results, and the scope of the empirical claims (including the explicit note that distributional methods do not dominate on Sharpe ratio in the reported backtest). We address the single observation raised in the report below.
read point-by-point responses
-
Referee: No machine-checked proofs or open code are referenced in the provided text.
Authors: We agree that reproducibility would be strengthened by open code. In the revised manuscript we will add a dedicated reproducibility statement with a permanent link to a public repository containing (i) the full Python implementation of the factor-model experiments (K=10,25,50), (ii) the DJIA backtest, and (iii) the credible-radius calibration routine. Regarding machine-checked proofs, the derivations appear in the appendix and rely on standard results from optimal transport and distributionally robust optimization; while we have not employed a proof assistant, we believe the arguments are self-contained. We are prepared to supply any additional intermediate steps the referee may request. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and claims describe a synthetic unification of portfolio methods via the joint coupling Gamma_theta(dw,dr) and marginal triple (W,R,P), plus boundary results (Wasserstein-CVaR duality, no-randomization theorem, credible-radius calibration, conservatism bound, W_1 rate, Bellman contraction) and an experiment. No equations, self-citations, or derivations are provided that reduce any claimed prediction or result to its inputs by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop, no load-bearing self-citation chain). The credible-radius calibration is noted as Bayesian but exhibits no visible reduction to a fitted quantity on the target metric. The framework is presented as an organizing structure with independent content and external experimental validation, qualifying as self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Wasserstein distance and CVaR satisfy duality in the portfolio setting
invented entities (2)
-
Joint coupling Gamma_theta(dw,dr)
no independent evidence
-
Marginal triple (W,R,P)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Spectral measures of risk: A coherent representation of subjective risk aversion
Carlo Acerbi. Spectral measures of risk: A coherent representation of subjective risk aversion. Journal of Banking and Finance, 26 0 (7): 0 1505--1518, 2002
2002
-
[2]
Entropic value-at-risk: A new coherent risk measure
Amir Ahmadi-Javid. Entropic value-at-risk: A new coherent risk measure. Journal of Optimization Theory and Applications, 155 0 (3): 0 1105--1123, 2012
2012
-
[3]
u rich. Birkh \
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savar \'e . Gradient Flows in Metric Spaces and in the Space of Probability Measures. Lectures in Mathematics ETH Z \"u rich. Birkh \"a user, 2nd edition, 2008
2008
-
[4]
Coherent measures of risk
Philippe Artzner, Freddy Delbaen, Jean-Marc Eber, and David Heath. Coherent measures of risk. Mathematical Finance, 9 0 (3): 0 203--228, 1999
1999
-
[5]
Bayesian portfolio analysis
Doron Avramov and Guofu Zhou. Bayesian portfolio analysis. Annual Review of Financial Economics, 2: 0 25--47, 2010
2010
-
[6]
Markov decision processes with average-value-at-risk criteria
Nicole B\"auerle and Jonathan Ott. Markov decision processes with average-value-at-risk criteria. Mathematical Methods of Operations Research, 74 0 (3): 0 361--379, 2011
2011
-
[7]
Bellemare, Will Dabney, and R\'emi Munos
Marc G. Bellemare, Will Dabney, and R\'emi Munos. A distributional perspective on reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017
2017
-
[8]
Robust solutions of optimization problems affected by uncertain probabilities
Aharon Ben-Tal, Dick Den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust solutions of optimization problems affected by uncertain probabilities. Management Science, 59 0 (2): 0 341--357, 2013
2013
-
[9]
Kolm, and Gordon Ritter
Jerome Benveniste, Petter N. Kolm, and Gordon Ritter. Untangling universality and dispelling myths in mean--variance optimization. The Journal of Portfolio Management, 50 0 (8): 0 90--116, 2024
2024
-
[10]
On the bures--wasserstein distance between positive definite matrices
Rajendra Bhatia, Tanvi Jain, and Yongdo Lim. On the bures--wasserstein distance between positive definite matrices. Expositiones Mathematicae, 37 0 (2): 0 165--191, 2019
2019
-
[11]
Probability and Measure
Patrick Billingsley. Probability and Measure. Wiley, anniversary edition, 2012
2012
-
[12]
Global portfolio optimization
Fischer Black and Robert Litterman. Global portfolio optimization. Financial Analysts Journal, 48 0 (5): 0 28--43, 1992
1992
-
[13]
V. I. Bogachev. Measure Theory. Springer, 2007
2007
-
[14]
Brown, William Goetzmann, Roger G
Stephen J. Brown, William Goetzmann, Roger G. Ibbotson, and Stephen A. Ross. Survivorship bias in performance studies. Review of Financial Studies, 5 0 (4): 0 553--580, 1992
1992
-
[15]
Random portfolios for evaluating trading strategies
Patrick Burns. Random portfolios for evaluating trading strategies. Technical report, Burns Statistics, 2007
2007
-
[16]
Giuseppe Calafiore and Marco C. Campi. Uncertain convex programs: Randomized solutions and confidence levels. Mathematical Programming, 102 0 (1): 0 25--46, 2005
2005
-
[17]
Campi and Simone Garatti
Marco C. Campi and Simone Garatti. The exact feasibility of randomized solutions of uncertain convex programs. SIAM Journal on Optimization, 19 0 (3): 0 1211--1230, 2008
2008
-
[18]
Abraham Charnes and William W. Cooper. Chance-constrained programming. Management Science, 6 0 (1): 0 73--79, 1959
1959
-
[19]
Alexander S. Cherny. Weighted v@r and its properties. Finance and Stochastics, 10 0 (3): 0 367--393, 2006
2006
-
[20]
Implicit quantile networks for distributional reinforcement learning
Will Dabney, Georg Ostrovski, David Silver, and R\'emi Munos. Implicit quantile networks for distributional reinforcement learning. In Proceedings of the 35th International Conference on Machine Learning (ICML), 2018 a
2018
-
[21]
Bellemare, and R\'emi Munos
Will Dabney, Mark Rowland, Marc G. Bellemare, and R\'emi Munos. Distributional reinforcement learning with quantile regression. In AAAI Conference on Artificial Intelligence, 2018 b
2018
-
[22]
Distributionally robust optimization under moment uncertainty with application to data-driven problems
Erick Delage and Yinyu Ye. Distributionally robust optimization under moment uncertainty with application to data-driven problems. Operations Research, 58 0 (3): 0 595--612, 2010
2010
-
[23]
Optimal versus naive diversification: How inefficient is the 1/n portfolio strategy? Review of Financial Studies, 22 0 (5): 0 1915--1953, 2009
Victor DeMiguel, Lorenzo Garlappi, and Raman Uppal. Optimal versus naive diversification: How inefficient is the 1/n portfolio strategy? Review of Financial Studies, 22 0 (5): 0 1915--1953, 2009
1915
-
[24]
Stochastic Finance: An Introduction in Discrete Time
Hans F\"ollmer and Alexander Schied. Stochastic Finance: An Introduction in Discrete Time. De Gruyter, 3 edition, 2011
2011
-
[25]
On the rate of convergence in Wasserstein distance of the empirical measure
Nicolas Fournier and Arnaud Guillin. On the rate of convergence in Wasserstein distance of the empirical measure. Probability Theory and Related Fields, 162 0 (3-4): 0 707--738, 2015
2015
-
[26]
On a formula for the L^2 Wasserstein metric between measures on Euclidean and Hilbert spaces
Matthias Gelbrich. On a formula for the L^2 Wasserstein metric between measures on Euclidean and Hilbert spaces. Mathematische Nachrichten, 147 0 (1): 0 185--203, 1990
1990
-
[27]
Horowitz, and Bing-Yi Jing
Peter Hall, Joel L. Horowitz, and Bing-Yi Jing. On blocking rules for the bootstrap with dependent data. Biometrika, 82 0 (3): 0 561--574, 1995
1995
-
[28]
Bayes--stein estimation for portfolio analysis
Philippe Jorion. Bayes--stein estimation for portfolio analysis. Journal of Financial and Quantitative Analysis, 21 0 (3): 0 279--292, 1986
1986
-
[29]
Joseph B. Kadane. Prime time for Bayes . Controlled Clinical Trials, 16 0 (5): 0 313--318, 1995
1995
-
[30]
B. J. K. Kleijn and A. W. van der Vaart. The Bernstein--von-Mises theorem under misspecification. Electronic Journal of Statistics, 6: 0 354--381, 2012
2012
-
[31]
On law-invariant coherent risk measures
Shigeo Kusuoka. On law-invariant coherent risk measures. Advances in Mathematical Economics, 3: 0 83--95, 2001
2001
-
[32]
Improved estimation of the covariance matrix of stock returns with an application to portfolio selection
Olivier Ledoit and Michael Wolf. Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. Journal of Empirical Finance, 10 0 (5): 0 603--621, 2003
2003
-
[33]
A well-conditioned estimator for large-dimensional covariance matrices
Olivier Ledoit and Michael Wolf. A well-conditioned estimator for large-dimensional covariance matrices. Journal of Multivariate Analysis, 88 0 (2): 0 365--411, 2004
2004
-
[34]
Building diversified portfolios that outperform out of sample
Marcos L\'opez de Prado. Building diversified portfolios that outperform out of sample. Journal of Portfolio Management, 42 0 (4): 0 59--69, 2016
2016
-
[35]
Portfolio selection
Harry Markowitz. Portfolio selection. Journal of Finance, 7 0 (1): 0 77--91, 1952
1952
-
[36]
Richard O. Michaud. Efficient Asset Management. Harvard Business School Press, 1998
1998
-
[37]
Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations
Peyman Mohajerin Esfahani and Daniel Kuhn. Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations. Mathematical Programming, 171 0 (1-2): 0 115--166, 2018
2018
-
[38]
Return-adjusted hierarchical risk parity and Schur portfolios: A comprehensive theoretical and empirical study, July 2025
Miquel Noguer i Alonso. Return-adjusted hierarchical risk parity and Schur portfolios: A comprehensive theoretical and empirical study, July 2025. Available at SSRN: https://ssrn.com/abstract=5370624
2025
-
[39]
Reinforcement learning portfolio optimization ( RLPO ): From Markowitz to risk-sensitive control, March 2026
Miquel Noguer i Alonso. Reinforcement learning portfolio optimization ( RLPO ): From Markowitz to risk-sensitive control, March 2026. Available at SSRN: https://ssrn.com/abstract=6447220
2026
-
[40]
Politis, and Halbert White
Andrew Patton, Dimitris N. Politis, and Halbert White. Correction to ``automatic block-length selection for the dependent bootstrap'' by d. politis and h. white. Econometric Reviews, 28 0 (4): 0 372--375, 2009
2009
-
[41]
Pflug and Alois Pichler
Georg Ch. Pflug and Alois Pichler. Multistage Stochastic Optimization. Springer Series in Operations Research and Financial Engineering. Springer International Publishing, Cham, 2014
2014
-
[42]
Politis and Joseph P
Dimitris N. Politis and Joseph P. Romano. The stationary bootstrap. Journal of the American Statistical Association, 89 0 (428): 0 1303--1313, 1994
1994
-
[43]
Polson and Bernard T
Nicholas G. Polson and Bernard T. Tew. Bayesian portfolio selection: An empirical analysis of the S&P 500 index 1970--1996. Journal of Business and Economic Statistics, 18 0 (2): 0 164--173, 2000
1970
-
[44]
Stochastic Programming
Andr\'as Pr\'ekopa. Stochastic Programming. Kluwer Academic Publishers, 1995
1995
-
[45]
Tyrrell Rockafellar and Stanislav Uryasev
R. Tyrrell Rockafellar and Stanislav Uryasev. Optimization of conditional value-at-risk. Journal of Risk, 2 0 (3): 0 21--41, 2000
2000
-
[46]
Risk-averse dynamic programming for Markov decision processes
Andrzej Ruszczy\'nski. Risk-averse dynamic programming for Markov decision processes. Mathematical Programming, 125 0 (2): 0 235--261, 2010
2010
-
[47]
A. W. van der Vaart. Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2000
2000
-
[48]
Optimal Transport: Old and New
C\'edric Villani. Optimal Transport: Old and New. Springer, 2009
2009
-
[49]
Wainwright
Martin J. Wainwright. High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2019
2019
-
[50]
Shaun S. Wang. A class of distortion operators for pricing financial and insurance risks. Journal of Risk and Insurance, 67 0 (1): 0 15--36, 2000
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.