FRESH: Information-Geometric Calibration of Patient-Level Models to Aggregate Evidence
Pith reviewed 2026-05-20 15:25 UTC · model grok-4.3
The pith
FRESH re-calibrates patient-level generative models to match specified aggregate statistics through minimal information-geometric adjustments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FRESH assumes access to a generative model trained on patient-level data and produces patient-level predictions from a re-calibrated model that matches a set of specified aggregate statistics for a target population. This is understood as a patient-level recapitulation of the aggregate source achieved with the key property that the recalibration is a minimal perturbation of the original joint distribution in a specific information-geometric sense. The resulting samples can be analyzed directly or used in a post-training procedure to update the original model.
What carries the argument
Information-geometric minimal perturbation recalibration that enforces match to aggregate statistics while preserving the original joint distribution as closely as possible.
If this is right
- Enables contextualizing single-arm trial results against recent standard-of-care summaries.
- Supports clinical-trial simulations for design and probability-of-technical-success estimation.
- Allows comparative-effectiveness analyses of on-market therapies using mixed data sources.
Where Pith is reading between the lines
- The same recalibration step could be applied repeatedly as new aggregate summaries are published without retraining the base model from scratch.
- The approach connects to other evidence-synthesis problems where one data source is granular and another is summarized at the population level.
- It could extend to settings outside medicine, such as combining individual transaction records with published economic aggregates.
Load-bearing premise
The method requires access to a generative model already trained on patient-level data that can be re-calibrated to match new aggregate statistics.
What would settle it
Applying the recalibration to a known generative model and target aggregates and finding that the output samples fail to reproduce the aggregates within sampling error or that the information-geometric distance exceeds that of a simpler adjustment.
Figures
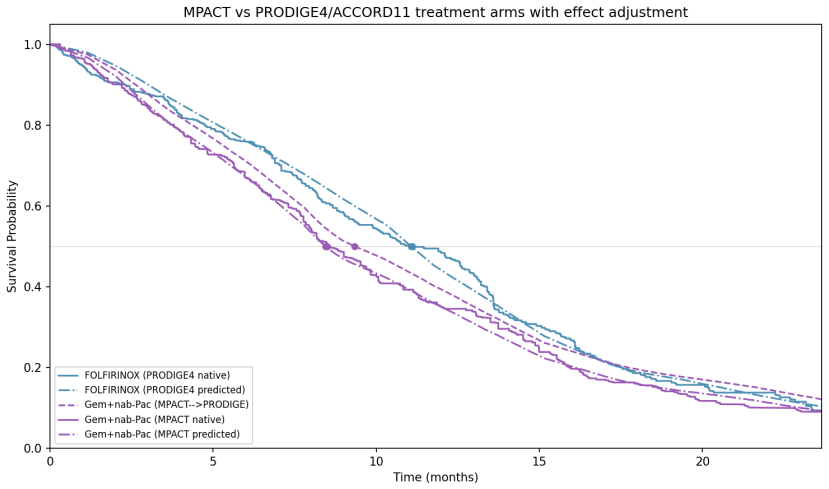

read the original abstract
This note introduces FRESH (Fusion of Recent Evidence and Subject Histories), a method for incorporating population-level summary results -- published clinical trials, registry summaries, prior natural-history studies, and peer-reviewed indirect comparisons -- into predictive models trained on patient-level data. This method provides a principled means of combining both patient-level and aggregate-level data types into a unified data-efficient model for clinical decision making. FRESH assumes access to a generative model trained on patient-level data sources (e.g. clinical trial or real-world data). The method produces patient-level predictions from a re-calibrated model that matches a set of specified aggregate statistics for a target population. This can be understood as a patient-level recapitulation of the aggregate source -- with the key property that the recalibration is a minimal perturbation of the original joint distribution in a specific information-geometric sense. The resulting samples can be analyzed directly or combined into a post-training procedure to update the original generative model. This approach enables several applications where rigorously incorporating patient-level data with summary information is valuable, including (i) contextualizing single-arm trial results with respect to recent standard-of-care, (ii) clinical-trial simulations for design and probability-of-technical-success estimation, and (iii) comparative-effectiveness analyses of on-market therapies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FRESH (Fusion of Recent Evidence and Subject Histories), a method that takes a generative model trained on patient-level data and performs an information-geometric recalibration so that the induced marginals on selected statistics match a target set of aggregate summaries (e.g., published trial results or registry data). The recalibration is framed as an I-projection that minimizes perturbation of the original joint distribution while producing usable patient-level samples for downstream clinical applications such as single-arm trial contextualization, trial simulation, and comparative-effectiveness analysis.
Significance. If the central construction is shown to be correct and computationally tractable, the approach would supply a principled, data-efficient route for fusing patient-level and aggregate evidence in clinical modeling. The explicit appeal to information geometry and the promise of minimal distributional perturbation are attractive features that align with existing literature on I-projections; however, the absence of derivations, closed-form expressions, or empirical validation in the current draft leaves the practical significance difficult to assess.
major comments (2)
- [Abstract / Method] Abstract and Method section: the central claim that the recalibration constitutes a minimal perturbation of the original joint distribution rests on an unspecified I-projection construction. No optimization problem, Lagrangian, or closed-form solution is supplied, so it is impossible to verify that the procedure actually recovers the stated information-geometric property or that the resulting samples are consistent with the target aggregates.
- [Applications] Applications paragraph: the three listed use-cases (contextualizing single-arm trials, PTS estimation, comparative-effectiveness) are asserted without any simulation study, sensitivity analysis, or comparison against existing calibration or weighting methods, leaving the practical advantage of FRESH unsubstantiated.
minor comments (3)
- [Method] Notation for the aggregate statistics and the information projection should be introduced with explicit symbols and a small worked example.
- [Method] The manuscript would benefit from a short algorithmic box or pseudocode describing the recalibration step.
- [Discussion] A brief discussion of computational cost and convergence criteria for the projection would help readers evaluate feasibility for realistic clinical datasets.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. We agree that the I-projection requires explicit formalization and that the applications would be strengthened by empirical demonstrations. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method section: the central claim that the recalibration constitutes a minimal perturbation of the original joint distribution rests on an unspecified I-projection construction. No optimization problem, Lagrangian, or closed-form solution is supplied, so it is impossible to verify that the procedure actually recovers the stated information-geometric property or that the resulting samples are consistent with the target aggregates.
Authors: We agree that the current draft omits the explicit mathematical construction. In the revised manuscript we will add a Methods subsection that states the I-projection as the optimization problem min_Q KL(Q || P) subject to E_Q[s_j] = t_j for each target aggregate statistic s_j with value t_j, where P is the original generative model. We will present the Lagrangian, derive the stationarity condition, and show that the solution takes the closed-form exponential-tilting expression Q(x) = P(x) exp(λ · s(x)) / Z(λ), with the Lagrange multipliers λ obtained by solving the moment-matching equations. This derivation directly establishes both the minimal-perturbation property in the information-geometric sense and the consistency of samples drawn from Q with the supplied aggregates. revision: yes
-
Referee: [Applications] Applications paragraph: the three listed use-cases (contextualizing single-arm trials, PTS estimation, comparative-effectiveness) are asserted without any simulation study, sensitivity analysis, or comparison against existing calibration or weighting methods, leaving the practical advantage of FRESH unsubstantiated.
Authors: The listed use-cases are presented as direct consequences of the method’s ability to produce patient-level samples that respect both the original joint and the target aggregates. We acknowledge that concrete evidence of advantage is currently absent. In the revision we will add a Simulation Studies section that (i) generates synthetic patient-level data from a known ground-truth distribution, (ii) applies FRESH to match a set of aggregate statistics drawn from a shifted target population, and (iii) evaluates performance on single-arm trial contextualization and probability-of-technical-success estimation. We will report bias, variance, and coverage metrics and compare against importance weighting and direct sampling from the aggregate summaries, together with sensitivity analyses on the number and choice of constraining statistics. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description introduce FRESH as an information-geometric recalibration method that matches aggregate statistics while minimally perturbing the original patient-level distribution. No equations, derivation steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The central construction is presented as relying on standard properties of information projections (I-projection), which are external and well-studied mathematical facts rather than self-referential. The derivation chain is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recalibration is performed as a minimal perturbation of the original joint distribution in a specific information-geometric sense
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FRESH produces its surrogate Q∗(x)K∗(y|x) … by composing two I-projections … Stage 1 … Q∗ = arg min … DKL(q∥Q0) … Stage 2 … DKL(K∥K0;Q∗)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the I-projection … dμ∗/dμ0(ω)∝exp(∑λ∗j Tj(ω)) … exponential-tilt form
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Devon J. Boyne, Darren R. Brenner, Alind Gupta, Eric Mackay, Paul Arora, Radek Wasiak, Winson Y. Cheung, and Miguel A. Hernán. Head-to-head comparison of FOLFIRINOX versus gemcitabine plus nab-paclitaxel in advanced pancreatic cancer: a target trial emulation using real-world data.Annals of Epidemiology, 78: 28–34, 2023. doi: 10.1016/j.annepidem.2022.12.005
-
[2]
J. Jaime Caro and K. Jack Ishak. No head-to-head trial? Simulate the missing arms.PharmacoEconomics, 28 (10):957–967, 2010. doi: 10.2165/11537420-000000000-00000
-
[3]
Kwun Chuen Gary Chan, Sheung Chi Phillip Yam, and Zheng Zhang. Globally efficient non-parametric inference of average treatment effects by empirical balancing calibration weighting.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78(3):673–700, 2016. doi: 10.1111/rssb.12129
-
[4]
Thierry Conroy, Françoise Desseigne, Marc Ychou, Olivier Bouché, Rosine Guimbaud, Yves Bécouarn, Antoine Adenis, Jean-Luc Raphaël, Roland Mauvernay, Tan Yel, Cécile Lecaille, Patrick Texereau, Eric Maillard, Valérie Boige, Patrice Berthaud, Karine Bouhier-Leporrier, Pascal Hammel, Thierry Lecomte, Olivier Rosmorduc, Laurent Mineur, Yannick Mallédant, Jean...
work page 2011
-
[5]
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley-Interscience, 2 edition, 2006
work page 2006
-
[6]
Imre Csiszár. I-divergence geometry of probability distributions and minimization problems.Annals of Probability, 3(1):146–158, 1975
work page 1975
-
[7]
Imre Csiszár. Sanov property, generalizedI-projection and a conditional limit theorem.Annals of Probability, 12(3):768–793, 1984
work page 1984
-
[8]
Jean-Claude Deville and Carl-Erik Särndal. Calibration estimators in survey sampling.Journal of the American Statistical Association, 87(418):376–382, 1992
work page 1992
-
[9]
Miroslav Dudík, Steven J. Phillips, and Robert E. Schapire. Maximum entropy density estimation with generalized regularization and an application to species distribution modeling.Journal of Machine Learning Research, 8:1217–1260, 2007
work page 2007
-
[10]
Andrew Gelman and Donald B. Rubin. Inference from iterative simulation using multiple sequences. Statistical Science, 7(4):457–472, 1992
work page 1992
-
[11]
Gillian K. Gresham, George A. Wells, Sharlene Gill, Chris Cameron, and Derek J. Jonker. Chemotherapy regimens for advanced pancreatic cancer: a systematic review and network meta-analysis.BMC Cancer, 14 (1):471, 2014
work page 2014
-
[12]
Patricia Guyot, A. E. Ades, Mario J. N. M. Ouwens, and Nicky J. Welton. Enhanced secondary analysis of survival data: reconstructing the data from published kaplan–meier survival curves.BMC Medical Research Methodology, 12:9, 2012. doi: 10.1186/1471-2288-12-9
-
[13]
Jens Hainmueller. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies.Political Analysis, 20(1):25–46, 2012
work page 2012
-
[14]
Lars Peter Hansen. Large sample properties of generalized method of moments estimators.Econometrica, 50 (4):1029–1054, 1982. 20
work page 1982
-
[15]
Edwin T. Jaynes. Information theory and statistical mechanics.Physical Review, 106(4):620–630, 1957
work page 1957
-
[16]
Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the Fokker–Planck equation.SIAM Journal on Mathematical Analysis, 29(1):1–17, 1998
work page 1998
-
[17]
Yuichi Kitamura and Michael Stutzer. An information-theoretic alternative to generalized method of moments estimation.Econometrica, 65(4):861–874, 1997
work page 1997
-
[18]
Solomon Kullback and Richard A. Leibler. On information and sufficiency.Annals of Mathematical Statistics, 22(1):79–86, 1951
work page 1951
-
[19]
Christian Léonard. Minimization of entropy functionals.Journal of Mathematical Analysis and Applications, 346(1):183–204, 2008. doi: 10.1016/j.jmaa.2008.04.048
-
[20]
Clement Ma, Sumera Bandukwala, Debika Burman, John Bryson, Dori Seccareccia, Subrata Banerjee, Jeff Myers, Gary Rodin, Deborah Dudgeon, and Camilla Zimmermann. Interconversion of three measures of performance status: an empirical analysis.European Journal of Cancer, 46(18):3175–3183, 2010. doi: 10.1016/j.ejca.2010.06.126
-
[21]
Jean-Michel Marin, Pierre Pudlo, Christian P. Robert, and Robin J. Ryder. Approximate Bayesian computa- tional methods.Statistics and Computing, 22(6):1167–1180, 2012
work page 2012
-
[22]
On maximum entropy density estimation with relaxed moment constraints.Entropy, 28(3):282, 2026
Thi Lich Nghiem and Pierre Maréchal. On maximum entropy density estimation with relaxed moment constraints.Entropy, 28(3):282, 2026. doi: 10.3390/e28030282
-
[23]
Felix Otto. The geometry of dissipative evolution equations: the porous medium equation.Communications in Partial Differential Equations, 26(1–2):101–174, 2001
work page 2001
- [24]
-
[25]
David M. Phillippo, A. E. Ades, Sofia Dias, Stephen Palmer, Keith R. Abrams, and Nicky J. Welton. NICE DSU technical support document 18: Methods for population-adjusted indirect comparisons in submissions to NICE. Technical report, National Institute for Health and Care Excellence Decision Support Unit, 2016. Last updated 2018
work page 2016
-
[26]
David M. Phillippo, A. E. Ades, Sofia Dias, Stephen Palmer, Keith R. Abrams, and Nicky J. Welton. Methods for population-adjusted indirect comparisons in health technology appraisal.Medical Decision Making, 38 (2):200–211, 2018
work page 2018
-
[27]
David M. Phillippo, Sofia Dias, A. E. Ades, Mark Belger, Alan Brnabic, Alexander Schacht, Daniel Saure, Zbigniew Kadziola, and Nicky J. Welton. Multilevel network meta-regression for population-adjusted treatment comparisons.Journal of the Royal Statistical Society Series A, 183(3):1189–1210, 2020
work page 2020
-
[28]
Aggarwal, Digambar Behera, and Navneet Singh
Kuruswamy Thurai Prasad, Harmandeep Kaur, Valliappan Muthu, Ashutosh N. Aggarwal, Digambar Behera, and Navneet Singh. Interconversion of two commonly used performance tools: an analysis of 5844 paired assessments in 1501 lung cancer patients.World Journal of Clinical Oncology, 9(7):140–147, 2018. doi: 10.5306/wjco.v9.i7.140
-
[29]
A stochastic approximation method.Annals of Mathematical Statistics, 22(3):400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.Annals of Mathematical Statistics, 22(3):400–407, 1951
work page 1951
-
[30]
Paul R. Rosenbaum and Donald B. Rubin. The central role of the propensity score in observational studies for causal effects.Biometrika, 70(1):41–55, 1983
work page 1983
-
[31]
James E. Signorovitch, Eric Q. Wu, Andrew P. Yu, Charles M. Gerrits, Evan Kantor, Yanjun Bao, Shiraz R. Gupta, and Parvez M. Mulani. Comparative effectiveness without head-to-head trials: a method for matching-adjusted indirect comparisons applied to psoriasis treatment with adalimumab or etanercept. PharmacoEconomics, 28(10):935–945, 2010
work page 2010
- [32]
-
[33]
Von Hoff, Thomas Ervin, Francis P
Daniel D. Von Hoff, Thomas Ervin, Francis P. Arena, E. Gabriela Chiorean, Jeffrey Infante, Malcolm Moore, Thomas Seay, Sergei A. Tjulandin, Wen Wee Ma, Mansoor N. Saleh, Marion Harris, Michele Reni, Scot Dowden, Daniel Laheru, Nathan Bahary, Ramesh K. Ramanathan, Josep Tabernero, Manuel Hidalgo, David Goldstein, Eric Van Cutsem, Xinyu Wei, Jose Iglesias, ...
work page 2013
-
[34]
Yixin Wang and José R. Zubizarreta. Minimal dispersion approximately balancing weights: Asymptotic properties and practical considerations.Biometrika, 107(1):93–105, 2020
work page 2020
-
[35]
José R. Zubizarreta. Stable weights that balance covariates for estimation with incomplete outcome data. Journal of the American Statistical Association, 110(511):910–922, 2015. A Proofs This appendix collects proofs of the propositions and theorems requiring derivation. Proofs Proof of Proposition 5.1. Standing regularity assumption.We assume that C (def...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.