Wind-Resilient Trajectory Optimization for UAV-BS Networks: TD3 for Continuous Service Availability
Pith reviewed 2026-06-26 20:22 UTC · model grok-4.3
The pith
Modeling wind as random position shifts lets TD3 learn UAV base station trajectories that hold coverage steady.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
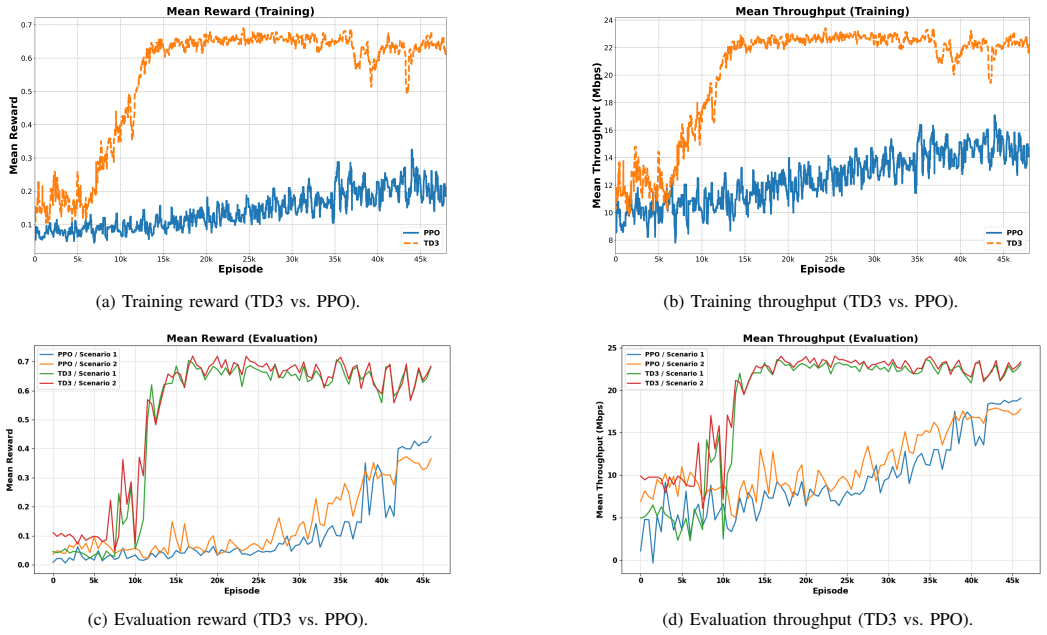
The central claim is that the Twin Delayed Deep Deterministic Policy Gradient algorithm, when trained with wind represented as a stochastic kinematic perturbation, produces control policies that compensate for positional drift, preserve user-centric throughput, and outperform benchmark methods including PPO in simulation tests of stability and robustness.
What carries the argument
The TD3 algorithm, which learns adaptive trajectory adjustments by treating wind as stochastic kinematic perturbations to maximize coverage metrics.
If this is right
- UAV base stations maintain continuous service availability when wind causes positional drift.
- Throughput stability improves relative to PPO under the modeled wind conditions.
- Control policies can be obtained without detailed fluid-dynamics calculations.
- User-centric performance metrics remain the optimization target even under turbulence.
Where Pith is reading between the lines
- The same modeling choice might extend to other external forces such as minor collisions or payload shifts if they can also be cast as kinematic noise.
- Real-world validation would require checking how quickly the policy adapts when actual wind statistics differ from the training distribution.
- Hardware experiments could reveal whether sensor noise or actuator limits break the advantage seen in simulation.
Load-bearing premise
Wind can be treated as a simple random shift in position without needing full aerodynamic or fluid-dynamics modeling for the learned policies to remain useful.
What would settle it
Deploy the trained TD3 policy on a physical UAV in real outdoor wind and measure whether the observed coverage area and throughput match the simulation predictions within acceptable error.
Figures
read the original abstract
Unmanned aerial vehicle (UAV)-mounted base stations are highly susceptible to wind disturbances such as gusts and turbulence, which induce positional drift and degrade communication link quality, particularly in emergency scenarios. To address this challenge, we propose a DRL-based framework for wind-resilient trajectory adjustment and positioning based on the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. The method models wind as a stochastic kinematic perturbation, avoiding complex aerodynamic modeling, thereby enabling the TD3 agent to learn adaptive control policies that maintain optimal coverage footprints. By prioritizing user-centric performance metrics under turbulent conditions, the proposed architecture ensures continuous service availability despite external disruptions. Simulation results demonstrate that the TD3-based approach effectively compensates for wind-induced displacements and outperforms benchmark methods, including Proximal Policy Optimization (PPO), in terms of throughput stability and robustness in windy environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Twin Delayed Deep Deterministic Policy Gradient (TD3) DRL framework for UAV base station trajectory optimization under wind disturbances, modeled as stochastic kinematic perturbations rather than full aerodynamics. The central claim is that the resulting policies maintain coverage footprints and continuous service availability, with simulation results showing outperformance versus Proximal Policy Optimization (PPO) on throughput stability and robustness.
Significance. If the reported simulation results hold under proper statistical reporting, the work would demonstrate a practical simplification for learning wind-resilient UAV control policies focused on user-centric metrics. The kinematic perturbation modeling choice is a strength, as it enables policy learning without requiring fluid-dynamics fidelity or hardware tuning within the simulated environment.
major comments (1)
- [Simulation Results] Simulation Results section (as referenced in the abstract): the claim that TD3 'effectively compensates for wind-induced displacements and outperforms' PPO rests on unspecified simulation outputs with no reported error bars, number of trials, wind model parameters (e.g., gust variance), or exclusion criteria; this directly affects the ability to evaluate the throughput stability and robustness assertions.
minor comments (1)
- [Abstract] Abstract: the phrase 'user-centric performance metrics' is used without enumeration (e.g., whether throughput, outage probability, or coverage area is primary), which reduces clarity even though the overall framing is consistent.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Simulation Results] Simulation Results section (as referenced in the abstract): the claim that TD3 'effectively compensates for wind-induced displacements and outperforms' PPO rests on unspecified simulation outputs with no reported error bars, number of trials, wind model parameters (e.g., gust variance), or exclusion criteria; this directly affects the ability to evaluate the throughput stability and robustness assertions.
Authors: We agree that the current manuscript lacks the requested statistical details and simulation parameters, which limits reproducibility and evaluation of the claims. In the revised manuscript we will expand the Simulation Results section (and update the abstract accordingly) to report: the number of independent trials (minimum 10 runs with distinct random seeds), error bars as mean ± one standard deviation, the full wind model parameters including gust variance and turbulence spectrum, and any exclusion criteria applied to the collected metrics. These additions will directly support the throughput stability and robustness assertions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper applies the standard TD3 algorithm to a simulation environment with an explicitly stated stochastic kinematic wind model. Claims rest on empirical outperformance versus PPO in throughput stability; no equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations are present. The modeling assumptions are internal to the simulated setup and do not reduce any reported result to a definition by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opti- mizing UA V aerial base station flights using DRL-based proximal policy optimization,
M. R. Ib ´a˜nez, A. Akhtarshenas, D. L ´opez-P´erez, and G. Geraci, “Opti- mizing UA V aerial base station flights using DRL-based proximal policy optimization,” inICC Workshops. IEEE, 2025, pp. 1293–1298
2025
-
[2]
Evaluation of the con- trollability of a remotely piloted high-altitude platform in atmospheric disturbances based on pilot-in-the-loop simulations: Yj hasan et al
Y . J. Hasan, M. S. Roeser, and A. E. V oigt, “Evaluation of the con- trollability of a remotely piloted high-altitude platform in atmospheric disturbances based on pilot-in-the-loop simulations: Yj hasan et al.”CEAS Aeronautical Journal, vol. 14, no. 1, pp. 225–242, 2023
2023
-
[3]
A survey on applications of small uncrewed aircraft systems for offshore wind farms,
R. Sasse, C. A. Hirst, E. Frew, and B. Argrow, “A survey on applications of small uncrewed aircraft systems for offshore wind farms,”Wind Energy Science Discussions, vol. 2023, pp. 1–23, 2023
2023
-
[4]
Spatio-temporal wind modeling for UA V simulations. arxiv (2019),
K. Cole and A. Wickenheiser, “Spatio-temporal wind modeling for UA V simulations. arxiv (2019),”arXiv preprint arXiv:1905.09954, 1905
Pith/arXiv arXiv 2019
-
[5]
Optimizing UA V performance in turbulent environments using cascaded model pre- dictive control algorithm and pixhawk hardware,
M. A. Sadi, A. Jamali, and A. M. N. Abang Kamaruddin, “Optimizing UA V performance in turbulent environments using cascaded model pre- dictive control algorithm and pixhawk hardware,”Journal of the Brazilian Society of Mechanical Sciences and Engineering, vol. 47, p. 396, 2025
2025
-
[6]
Robust adaptive recursive sliding mode attitude control for a quadrotor with unknown disturbances,
L. Chen, Z. Liu, H. Gao, and G. Wang, “Robust adaptive recursive sliding mode attitude control for a quadrotor with unknown disturbances,”ISA transactions, vol. 122, pp. 114–125, 2022
2022
-
[7]
A robust disturbance-rejection controller using model predictive control for quadrotor UA V in tracking aggressive trajectory,
Z. Xu, L. Fan, W. Qiu, G. Wen, and Y . He, “A robust disturbance-rejection controller using model predictive control for quadrotor UA V in tracking aggressive trajectory,”Drones, vol. 7, no. 9, p. 557, 2023
2023
-
[8]
Fixed-time trajectory tracking control of a quadrotor UA V under time-varying wind disturbances: theory and experimental validation,
X. Cai, X. Zhu, and W. Yao, “Fixed-time trajectory tracking control of a quadrotor UA V under time-varying wind disturbances: theory and experimental validation,”Measurement Science and Technology, vol. 35, no. 8, p. 086205, 2024
2024
-
[9]
Trajectory generation for UA Vs in unknown environments with extreme wind disturbances,
K. Cole and A. M. Wickenheiser, “Trajectory generation for UA Vs in unknown environments with extreme wind disturbances,”arXiv preprint arXiv:1906.09508, 2019
Pith/arXiv arXiv 1906
-
[10]
Falcon: Fourier adaptive learning and control for disturbance rejection under extreme turbulence,
S. Lale, P. I. Renn, K. Azizzadenesheli, B. Hassibi, M. Gharib, and A. Anandkumar, “Falcon: Fourier adaptive learning and control for disturbance rejection under extreme turbulence,”npj Robotics, vol. 2, no. 1, p. 6, 2024
2024
-
[11]
Reinforcement learning for UA V flight controls: Evaluating continuous space reinforcement learning algorithms for fixed-wing uavs,
H. R. Khanzada, A. Maqsood, and A. Basit, “Reinforcement learning for UA V flight controls: Evaluating continuous space reinforcement learning algorithms for fixed-wing uavs,”Plos one, vol. 20, no. 10, p. e0334219, 2025
2025
-
[12]
Waypoint navigation of quadrotor using deep reinforcement learning,
K. Himanshu, J. V . Pushpangathanet al., “Waypoint navigation of quadrotor using deep reinforcement learning,”IFAC-PapersOnLine, vol. 55, no. 22, pp. 281–286, 2022
2022
-
[13]
Control of a twin rotor using twin delayed deep deterministic policy gradient (TD3),
Z. Gamal, Y . Mahran, and A. El-Badawy, “Control of a twin rotor using twin delayed deep deterministic policy gradient (TD3),” in2024 28th ICSTCC Conference. IEEE, 2024, pp. 329–335
2024
-
[14]
Deep reinforcement learning attitude control of fixed-wing UA Vs using proximal policy optimization,
E. Bøhn, E. M. Coates, S. Moe, and T. A. Johansen, “Deep reinforcement learning attitude control of fixed-wing UA Vs using proximal policy optimization,” in2019 international conference on unmanned aircraft systems (ICUAS). IEEE, 2019, pp. 523–533
2019
-
[15]
Modeling wind and obstacle disturbances for effective performance observations and analysis of resilience in UA V swarms,
A. Phadke, F. A. Medrano, T. Chu, C. N. Sekharan, and M. J. Starek, “Modeling wind and obstacle disturbances for effective performance observations and analysis of resilience in UA V swarms,”Aerospace, vol. 11, no. 3, p. 237, 2024
2024
-
[16]
Goldsmith,Wireless communications
A. Goldsmith,Wireless communications. Cambridge university press, 2005
2005
-
[17]
Addressing function approximation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
2018
-
[18]
Activation functions in deep learning: A comprehensive survey and benchmark,
S. R. Dubey, S. K. Singh, and B. B. Chaudhuri, “Activation functions in deep learning: A comprehensive survey and benchmark,”Neurocomput- ing, vol. 503, pp. 92–108, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.