Towards a Joint Task-Oriented and Generative Semantic Communication Framework for 6G Networks
Pith reviewed 2026-07-01 04:07 UTC · model grok-4.3
The pith
Graph-based scene representations enable dual safety inference and image reconstruction at 99.1% compression over 3GPP channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By encoding visual scenes as graphs of object features and relations, the framework supports simultaneous task-oriented inference via an ST-GNN module and generative reconstruction via a diffusion decoder, delivering up to 99.1 percent data reduction relative to pixel transmission while preserving collision-risk estimation performance and attaining superior perceptual fidelity under 3GPP vehicular channel conditions.
What carries the argument
Graph-based semantic representation of object-level features and relational structure that is extracted at the transmitter and recovered at the receiver to drive both ST-GNN inference and diffusion reconstruction.
If this is right
- The same transmitted graph supports both predictive safety tasks and visual output without separate streams.
- Performance holds across MIMO configurations and a range of SNR values in the evaluated vehicular setting.
- The compression level exceeds that of JPEG and HEVC while maintaining downstream inference quality.
- Diffusion reconstruction yields lower FID than prior semantic communication approaches.
Where Pith is reading between the lines
- The graph representation may generalize to other vision-based tasks if the extracted features prove task-agnostic.
- Replacing the diffusion decoder with lighter generative models could further reduce receiver complexity.
- Extending the framework to multi-user or multi-task scenarios would test whether one graph suffices for several inference heads.
Load-bearing premise
A graph of objects and their relations is assumed to contain enough scene information to support both accurate collision-risk estimates and high-fidelity image recovery after transmission over the modeled channel.
What would settle it
An experiment showing that the recovered scene graphs produce collision-risk predictions below a required accuracy threshold or diffusion reconstructions with FID scores no better than existing semantic baselines under the same 3GPP vehicular conditions would falsify the central performance claims.
Figures


read the original abstract
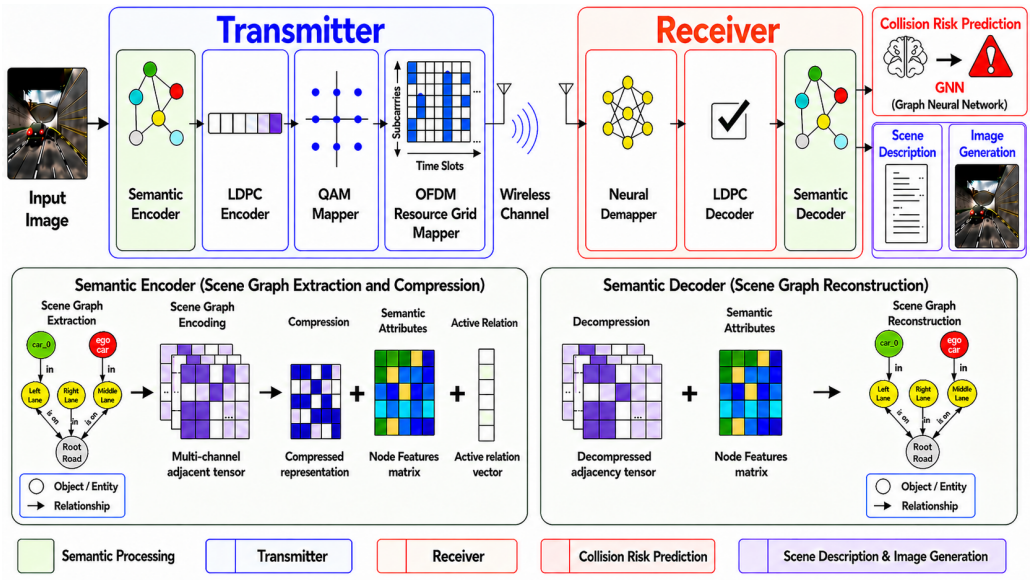
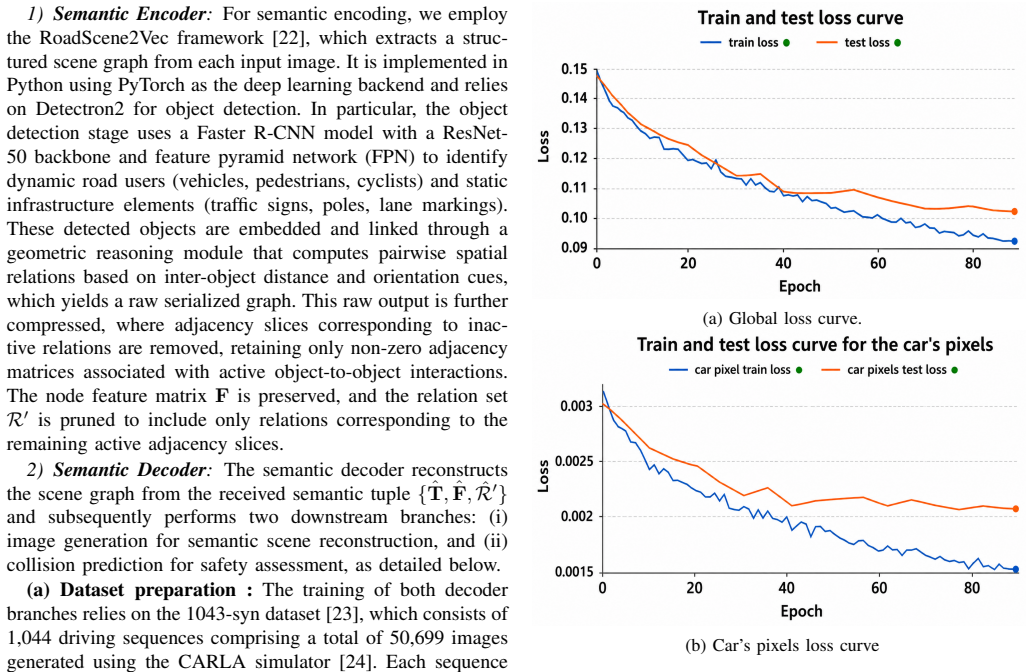
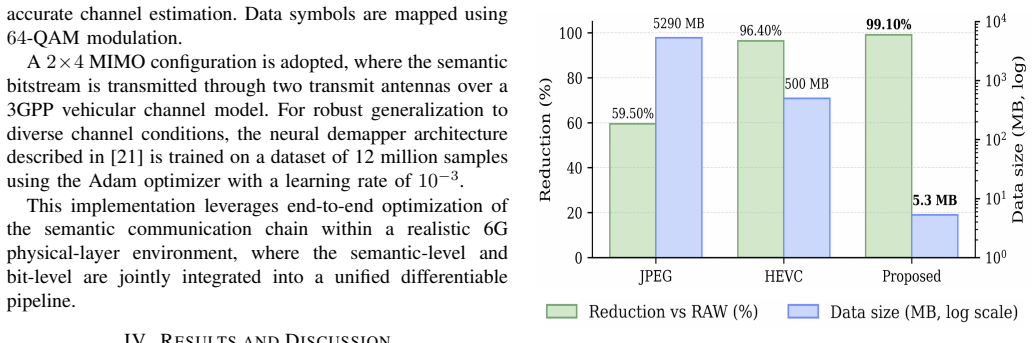
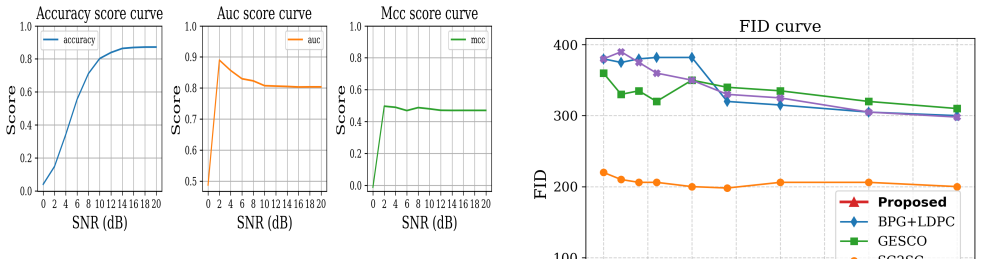
Semantic Communication (SC) has emerged as a key enabler for 6G wireless systems by transmitting task-relevant meaning rather than raw data, thereby significantly reducing bandwidth consumption while preserving communication intent. In this work, we propose an end-to-end OFDM-based semantic communication framework that integrates a semantic encoder-decoder pipeline with a neural receiver operating over a 3GPP vehicular channel. The semantic encoder extracts the underlying meaning of a visual scene by transforming it into a graph-based representation consisting of object-level features and relational structure. At the receiver, the reconstructed scene graph is processed by a spatio-temporal graph neural network (ST-GNN)-based module for collision-risk estimation, enabling task-oriented inference. In parallel, a diffusion-based semantic decoder reconstructs the visual scene from the recovered semantics, providing dual functionality: safety prediction and image reconstruction. The proposed framework is evaluated in a MIMO configuration under varying SNR conditions. Experimental results show that it achieves up to 99.1% data compression relative to pixel-domain transmission, outperforming conventional compression-based methods (JPEG and HEVC) while preserving downstream inference performance. Furthermore, the diffusion-based reconstruction attains significantly lower frechet inception distance (FID) scores than existing semantic communication approaches, reflecting superior semantic and perceptual fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an end-to-end OFDM-based semantic communication framework for 6G that encodes visual scenes as graphs of object features and relations, decodes via a neural receiver over 3GPP vehicular MIMO channels, and supports dual tasks: collision-risk estimation with an ST-GNN and image reconstruction with a diffusion model. It claims up to 99.1% compression relative to pixel-domain transmission while outperforming JPEG/HEVC on downstream inference and achieving lower FID than prior semantic methods.
Significance. If the empirical claims hold under rigorous verification, the work would be significant for demonstrating a practical joint task-oriented/generative semantic system in a standardized channel model, with the graph representation enabling both safety-critical inference and perceptual reconstruction at high compression ratios.
major comments (2)
- [Abstract] Abstract: The 99.1% compression figure and the claim of outperforming JPEG/HEVC while preserving inference performance are stated without any accompanying derivation, table, or experimental protocol (dataset, baseline pixel count, SNR range, or MIMO configuration details). This is load-bearing for the central performance claim.
- [Abstract] Abstract: No ablation, sensitivity analysis, or bound is provided on graph reconstruction fidelity at the neural receiver and its separate impact on ST-GNN collision-risk accuracy versus diffusion FID under channel impairments (e.g., SNR variation or OFDM/MIMO effects). The dual-task performance rests on this untested assumption.
minor comments (1)
- [Abstract] The abstract refers to 'significantly lower FID scores' without numerical values or reference to the specific figure/table containing the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 99.1% compression figure and the claim of outperforming JPEG/HEVC while preserving inference performance are stated without any accompanying derivation, table, or experimental protocol (dataset, baseline pixel count, SNR range, or MIMO configuration details). This is load-bearing for the central performance claim.
Authors: The full experimental protocol, dataset details, baseline pixel counts, SNR ranges, and MIMO configuration are described in Sections IV and V. We agree the abstract would be improved by briefly referencing these elements to support the claims. We will revise the abstract to include a concise summary of the evaluation setup. revision: yes
-
Referee: [Abstract] Abstract: No ablation, sensitivity analysis, or bound is provided on graph reconstruction fidelity at the neural receiver and its separate impact on ST-GNN collision-risk accuracy versus diffusion FID under channel impairments (e.g., SNR variation or OFDM/MIMO effects). The dual-task performance rests on this untested assumption.
Authors: The manuscript reports end-to-end performance across SNR and channel conditions in Section V, but does not include an explicit ablation isolating graph reconstruction fidelity effects on each task. We agree this would strengthen the dual-task claims and will add a sensitivity analysis or ablation study in the revised version. revision: yes
Circularity Check
No circularity; empirical claims only
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters presented as predictions, or self-citations. All reported outcomes (99.1% compression, FID scores, downstream inference) are framed as experimental results from simulation under 3GPP channels. No load-bearing step reduces by construction to its own inputs, satisfying the criteria for a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Big communi- cations: Connect the unconnected,
C. Zhang, S. Dang, M.-S. Alouini, and B. Shihada, “Big communi- cations: Connect the unconnected,”Frontiers in Communications and Networks, vol. 3, p. 785933, 2022
2022
-
[2]
Wireless 6g connectivity for massive number of devices and critical services,
A. E. Kalor, G. Durisi, S. Coleri, S. Parkvall, W. Yu, A. Mueller, and P. Popovski, “Wireless 6g connectivity for massive number of devices and critical services,”Proceedings of the IEEE, 2024
2024
-
[3]
Multiple sequential constraint removal algorithm for channel estimation in vehicular environment,
S. Ribouh, Y . Elhillali, and A. Rivenq, “Multiple sequential constraint removal algorithm for channel estimation in vehicular environment,” in 2020 International Symposium On Networks, Computers And Commu- nications (ISNCC). IEEE, 2020, pp. 1–7
2020
-
[4]
Toward the age of intelligent vehicular networks for connected and autonomous vehicles in 6g,
V .-L. Nguyen, R.-H. Hwang, P.-C. Lin, A. Vyas, and V .-T. Nguyen, “Toward the age of intelligent vehicular networks for connected and autonomous vehicles in 6g,”IEEE Network, vol. 37, no. 3, pp. 44–51, 2022
2022
-
[5]
Is semantic communication for autonomous driving secured against adversarial attacks?
S. Ribouh and A. Hadid, “Is semantic communication for autonomous driving secured against adversarial attacks?” in2024 IEEE 6th Interna- tional Conference on AI Circuits and Systems (AICAS). IEEE, 2024, pp. 139–143
2024
-
[6]
Semantic communication: A survey on research landscape, challenges, and future directions,
T. M. Getu, G. Kaddoum, and M. Bennis, “Semantic communication: A survey on research landscape, challenges, and future directions,” Proceedings of the IEEE, vol. 112, no. 11, pp. 1649–1685, 2025
2025
-
[7]
Large language model-based seman- tic communication system for image transmission,
S. Ribouh and O. Saleem, “Large language model-based seman- tic communication system for image transmission,”arXiv preprint arXiv:2501.12988, 2025
-
[8]
Embracing ai in 5g-advanced toward 6g: A joint 3gpp and o-ran perspective,
X. Lin, L. Kundu, C. Dick, and S. Velayutham, “Embracing ai in 5g-advanced toward 6g: A joint 3gpp and o-ran perspective,”IEEE Communications Standards Magazine, vol. 7, no. 4, pp. 76–83, 2023
2023
-
[9]
Wireless end-to-end image transmis- sion system using semantic communications,
M. U. Lokumarambage, V . S. S. Gowrisetty, H. Rezaei, T. Sivalingam, N. Rajatheva, and A. Fernando, “Wireless end-to-end image transmis- sion system using semantic communications,”IEEE Access, vol. 11, pp. 37 149–37 163, 2023
2023
-
[10]
Toward semantic communications: Deep learning-based image semantic coding,
D. Huang, F. Gao, X. Tao, Q. Du, and J. Lu, “Toward semantic communications: Deep learning-based image semantic coding,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 55– 71, 2022
2022
-
[11]
Federated learning based audio semantic communication over wireless networks,
H. Tong, Z. Yang, S. Wang, Y . Hu, W. Saad, and C. Yin, “Federated learning based audio semantic communication over wireless networks,” in2021 IEEE Global Communications Conference (GLOBECOM). IEEE, 2021, pp. 1–6
2021
-
[12]
Semantic communication for the internet of sounds: Architecture, design princi- ples, and challenges,
C. Liang, Y . Sun, C. K. Thomas, L. Mohjazi, and W. Saad, “Semantic communication for the internet of sounds: Architecture, design princi- ples, and challenges,”IEEE Wireless Communications, 2025
2025
-
[13]
Task-oriented scene graph- based semantic communications with adaptive channel coding,
S. Sun, Z. Qin, H. Xie, and X. Tao, “Task-oriented scene graph- based semantic communications with adaptive channel coding,”IEEE Transactions on Wireless Communications, vol. 23, no. 11, pp. 17 070– 17 083, 2024
2024
-
[14]
Explicit semantic-base-empowered communications for 6g mobile networks,
F. Wang, Y . Zheng, W. Xu, J. Liang, P. Zhang, and Z. Han, “Explicit semantic-base-empowered communications for 6g mobile networks,” Engineering, 2025
2025
-
[15]
Cognitive semantic communication systems driven by knowl- edge graph: Principle, implementation, and performance evaluation,
F. Zhou, Y . Li, M. Xu, L. Yuan, Q. Wu, R. Q. Hu, and N. Al- Dhahir, “Cognitive semantic communication systems driven by knowl- edge graph: Principle, implementation, and performance evaluation,” IEEE Transactions on Communications, vol. 72, no. 1, pp. 193–208, 2023
2023
-
[16]
A unified multi-task semantic communication system for multimodal data,
G. Zhang, Q. Hu, Z. Qin, Y . Cai, G. Yu, and X. Tao, “A unified multi-task semantic communication system for multimodal data,”IEEE Transactions on Communications, vol. 72, no. 7, pp. 4101–4116, 2024
2024
-
[17]
Diffusion- driven semantic communication for generative models with bandwidth constraints,
L. Guo, W. Chen, Y . Sun, B. Ai, N. Pappas, and T. Quek, “Diffusion- driven semantic communication for generative models with bandwidth constraints,”IEEE Transactions on Wireless Communications, 2025
2025
-
[18]
Ofdm-based digital semantic communication with importance awareness,
C. Liu, C. Guo, Y . Yang, W. Ni, and T. Q. Quek, “Ofdm-based digital semantic communication with importance awareness,”IEEE Transactions on Communications, vol. 72, no. 10, pp. 6301–6315, 2024
2024
-
[19]
Aligning task-and reconstruction-oriented communications for edge intelligence,
Y . Diao, Y . Zhang, C. She, P. G. Zhao, and E. L. Li, “Aligning task-and reconstruction-oriented communications for edge intelligence,”IEEE Journal on Selected Areas in Communications, 2025
2025
-
[20]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[21]
A neural receiver for 5g nr multi-user mimo,
S. Cammerer, F. A ¨ıt Aoudia, J. Hoydis, A. Oeldemann, A. Roessler, T. Mayer, and A. Keller, “A neural receiver for 5g nr multi-user mimo,” in2023 IEEE Globecom Workshops (GC Wkshps). IEEE, 2023, pp. 329–334
2023
-
[22]
roadscene2vec: A tool for extracting and embedding road scene-graphs,
A. V . Malawade, S.-Y . Yu, B. Hsu, H. Kaeley, A. Karra, and M. A. Al Faruque, “roadscene2vec: A tool for extracting and embedding road scene-graphs,”Knowledge-Based Systems, vol. 242, p. 108245, 2022
2022
-
[23]
Scenegraph-risk-assessment dataset,
B. Hsu, S.-Y . Yu, A. Malawade, D. Muthirayan, P. P. Khargonekar, and M. A. A. Faruque, “Scenegraph-risk-assessment dataset,” 2021. [Online]. Available: https://dx.doi.org/10.21227/c0z9-1p30
-
[24]
” carla: An open urban driving simulator
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “” carla: An open urban driving simulator”, conference on robot learning, pmlr,” 2017
2017
-
[25]
Sionna: An Open-Source Li- brary for Next-Generation Physical Layer Research,
J. Hoydis, S. Cammerer, F. A. Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,”arXiv preprint arXiv:2203.11854, 2022
-
[26]
Making sense of meaning: A survey on metrics for semantic and goal-oriented communication,
T. M. Getu, G. Kaddoum, and M. Bennis, “Making sense of meaning: A survey on metrics for semantic and goal-oriented communication,” IEEE Access, vol. 11, pp. 45 456–45 492, 2023
2023
-
[27]
Y . Wu, F. Liu, R. Yilmaz, H. Konermann, P. Walter, and J. Stegmaier, “A pragmatic note on evaluating generative models with fr\’echet inception distance for retinal image synthesis,”arXiv preprint arXiv:2502.17160, 2025
-
[28]
Sg2sc: A generative semantic communication framework for scene understanding- oriented image transmission,
M. Yang, D. Gao, F. Xie, J. Li, X. Song, and G. Shi, “Sg2sc: A generative semantic communication framework for scene understanding- oriented image transmission,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13 486–13 490
2024
-
[29]
Generative Semantic Communication: Diffusion Models Beyond Bit Recovery
E. Grassucci, S. Barbarossa, and D. Comminiello, “Generative semantic communication: Diffusion models beyond bit recovery,”arXiv preprint arXiv:2306.04321, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Witt: A wireless image transmission transformer for semantic communications,
K. Yang, S. Wang, J. Dai, K. Tan, K. Niu, and P. Zhang, “Witt: A wireless image transmission transformer for semantic communications,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.