Sensitivity Analysis of Generative Spatial Audio Metrics: A Study on Responsiveness, Smoothness, and Symmetry
Pith reviewed 2026-06-27 08:46 UTC · model grok-4.3
The pith
FAD with localization-specific embeddings and acoustic maps maintains high responsiveness, smoothness, and symmetry for spatial audio metrics even as scene complexity increases, while intensity vectors do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In controlled FOA scenes, Fréchet Audio Distance computed with localization-specific embeddings and acoustic maps exhibits high Responsiveness together with robust Smoothness and Symmetry across all tested conditions; intensity vectors, by contrast, degrade as scene complexity grows.
What carries the argument
The sensitivity analysis framework that measures metric behavior along continuous spatial trajectories according to the three desiderata of Responsiveness, Smoothness, and Symmetry.
If this is right
- Evaluators of generative spatial audio should prefer FAD variants using localization embeddings or acoustic maps over raw intensity vectors when scene complexity is high.
- Metric choice can now be guided by explicit checks against responsiveness, smoothness, and symmetry along spatial paths rather than aggregate scores alone.
- The same trajectory-based testing procedure can be reused to qualify new metrics before they are applied to generative tasks.
- Acoustic maps emerge as a stable alternative when embedding-based distances are unavailable.
Where Pith is reading between the lines
- The framework could be extended to non-synthetic recordings to check whether the observed ordering of metrics survives domain shift.
- If the three desiderata correlate with human judgments of spatial audio quality, the same analysis would supply a perceptual validation path.
- Similar sensitivity tests could be run on other ambisonics orders or on binaural renderings to see whether the metric ranking generalizes.
Load-bearing premise
Controlled synthetic First-Order Ambisonics scenes with increasing complexity stand in for the spatial variations that actually matter in real generative audio work.
What would settle it
A test on real recorded spatial audio scenes in which intensity vectors retain high responsiveness and symmetry while the favored FAD variants lose it would refute the reported ordering of metric behavior.
Figures
read the original abstract
Evaluating generative spatial audio for First-Order Ambisonics (FOA) remains challenging due to a limited understanding of how metrics respond to changes in spatial parameters such as azimuth and elevation. We propose a framework to analyze metric sensitivity along continuous spatial trajectories, drawing on principles of sensitivity analysis in parametric sound synthesis. Using controlled FOA scenes with increasing scene complexity, we define three desiderata for metric behavior: Responsiveness, Smoothness, and Symmetry. We assess standard distribution-based and sample-based metrics, including Fr\'echet Audio Distance (FAD), intensity vectors, and acoustic maps. Our findings show that FAD using localization-specific embeddings and acoustic maps yield high Responsiveness and robust Smoothness and Symmetry across conditions, while intensity vectors degrade with increasing scene complexity. This is the first step towards investigating the sensitivity of metrics for generative spatial audio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a sensitivity analysis framework for evaluating generative spatial audio metrics in First-Order Ambisonics (FOA). It defines three desiderata for metric behavior along continuous spatial trajectories—Responsiveness, Smoothness, and Symmetry—and empirically compares distribution-based metrics (e.g., FAD variants with different embeddings) and sample-based metrics (intensity vectors, acoustic maps) on controlled synthetic FOA scenes of increasing complexity. The central finding is that FAD using localization-specific embeddings and acoustic maps achieve high Responsiveness with robust Smoothness and Symmetry, while intensity vectors degrade as scene complexity increases.
Significance. If the empirical observations hold under the reported conditions, the work provides a useful initial characterization of how existing metrics respond to parametric spatial changes, which could inform metric selection for generative spatial audio tasks. The controlled trajectory-based design isolates effects cleanly and avoids circularity in the desiderata definitions. However, the modest scope as a 'first step' and reliance on synthetic scenes limit broader claims about real generative audio evaluation.
major comments (1)
- [Experimental Setup] The experimental setup description provides no information on the number of independent trials, statistical significance testing (e.g., p-values or confidence intervals on the reported metric differences), or the precise parameterization used to quantify 'increasing scene complexity' (e.g., source count, angular separation, or reverberation). These details are load-bearing for verifying the claim that intensity vectors degrade while FAD variants remain robust.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the experimental setup. We agree that additional details are needed for reproducibility and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The experimental setup description provides no information on the number of independent trials, statistical significance testing (e.g., p-values or confidence intervals on the reported metric differences), or the precise parameterization used to quantify 'increasing scene complexity' (e.g., source count, angular separation, or reverberation). These details are load-bearing for verifying the claim that intensity vectors degrade while FAD variants remain robust.
Authors: We agree this information is essential. In the revised manuscript we will add: (i) all reported results are averaged over 20 independent trials with distinct random seeds for source placement and signal generation; (ii) 95% confidence intervals computed via bootstrapping on the metric values, with pairwise differences tested for significance at p<0.05; (iii) explicit parameterization of scene complexity as the number of simultaneous sources (1, 2, 3, or 4), with minimum angular separation fixed at 45° and zero reverberation (anechoic synthetic FOA). These clarifications will appear in Section 3 and the results figures will be updated with error bars. revision: yes
Circularity Check
No significant circularity; empirical evaluation of existing metrics against defined desiderata
full rationale
The paper is an empirical study that defines three desiderata (Responsiveness, Smoothness, Symmetry) for metric behavior and then measures how standard metrics (FAD variants, intensity vectors, acoustic maps) perform on controlled synthetic FOA trajectories of increasing complexity. No equations, parameter fits, or derivations are present that reduce reported performance numbers to quantities defined or fitted inside the paper. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The argument is scoped to the paper's own experimental conditions and is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The spatial and multi-channel nature of these sounds makes the gen- erative modelling task significantly harder compared to mono- phonic sounds
Introduction Spatial audio generation for First-Order Ambisonics (FOA) has recently attracted growing interest, driven by applications in im- mersive media and interactive machine listening [1, 2]. The spatial and multi-channel nature of these sounds makes the gen- erative modelling task significantly harder compared to mono- phonic sounds. Specifically i...
-
[2]
Method: Responsiveness, Smoothness, and Symmetry By sensitivity, we mean the degree to which a metric reflects changes in the signal as synthesis parameters vary sequentially. Sensitivity measures should indicate how granularly a metric distinguishes between a generated scene and a reference, with distances approaching zero as the generation matches the r...
Pith/arXiv arXiv 2026
-
[3]
Experimental Design We conduct experiments to understand two things: (1) the sen- sitivity of the metrics as spatial parameters vary along a control trajectory, and (2) their robustness to increasing scene complex- ity and noise. To this end, we create a large set of precisely con- trolled synthetic scene variations, deploy a representative set of metrics...
-
[4]
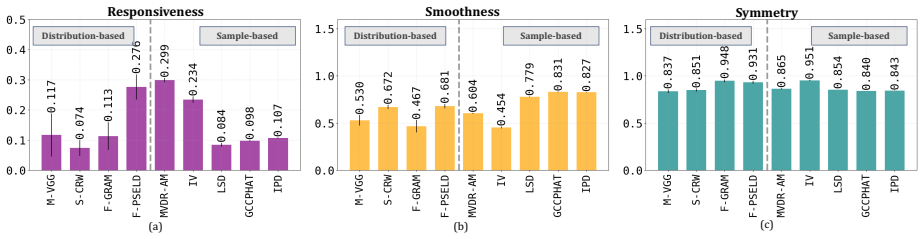
2 (a–c) summarizes Responsiveness, Smoothness, and Symmetry across all experimental conditions
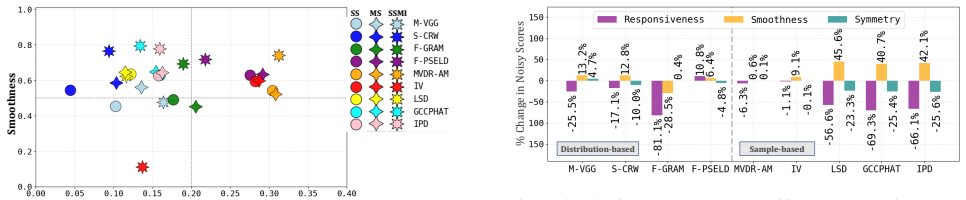
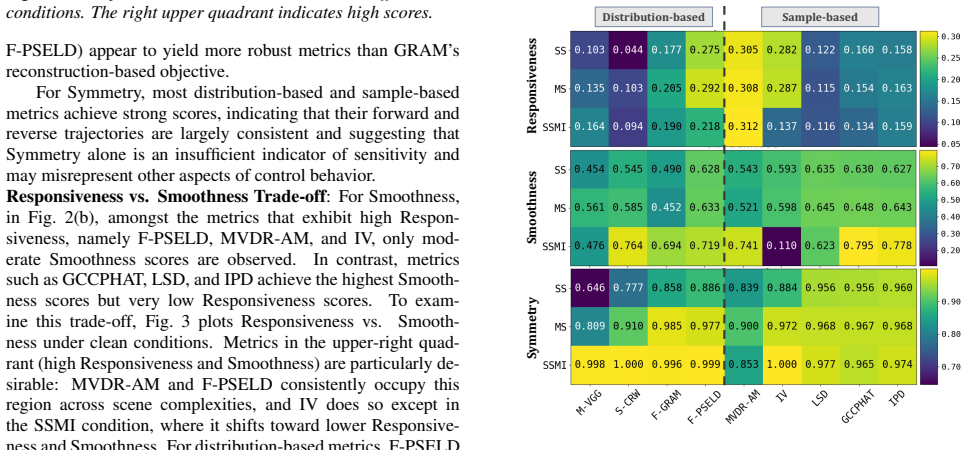
Results & Discussion Main Comparisons:Fig. 2 (a–c) summarizes Responsiveness, Smoothness, and Symmetry across all experimental conditions. Each bar plot shows the mean scores across azimuth and eleva- tion sweeps, averaged across all conditions. For sample-based metrics, the Responsiveness plot shows that MVDR-AM achieves the highest scores, followed by I...
-
[5]
Conclusion In this work, we defined sensitivity as the Responsiveness, Smoothness, and Symmetry of evaluation metrics under con- trolled spatial parameter changes and conducted an empiri- cal study of their behavior. Localization-based metrics such as F-PSELD, IV , and MVDR-AM showed strong Responsive- ness with good Smoothness trade-off, and were robust ...
-
[6]
Acknowledgments This work is partially funded by the NYU / SONY Audio Insti- tute for Music Business and Technology
-
[7]
The authors accept full responsibility for the content in this publication
Use of Generative AI Disclosure In preparing this work, the authors used Claude Code and Per- plexity AI as tools for literature exploration, sentence para- phrasing, and drafting code, after which they carefully reviewed and revised the content before using it within their framework and manuscript. The authors accept full responsibility for the content i...
-
[8]
Spatial audio in virtual reality: a systematic review,
G. Corr ˆea De Almeida, V . Costa de Souza, L. G. Da Sil- veira J´unior, and M. R. Veronez, “Spatial audio in virtual reality: a systematic review,” inProceedings of the 25th symposium on virtual and augmented reality, 2023, pp. 264–268
2023
-
[9]
L3das23: Learning 3d audio sources for audio-visual extended reality,
R. F. Gramaccioni, C. Marinoni, C. Chen, A. Uncini, and D. Com- miniello, “L3das23: Learning 3d audio sources for audio-visual extended reality,”IEEE Open Journal of Signal Processing, vol. 5, pp. 632–640, 2024
2024
-
[10]
Immersed- iffusion: A generative spatial audio latent diffusion model,
M. Heydari, M. Souden, B. Conejo, and J. Atkins, “Immersed- iffusion: A generative spatial audio latent diffusion model,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[11]
Diff-SAGe: End-to-End Spatial Audio Generation Using Diffu- sion Models,
S. S. Kushwaha, J. Ma, M. R. P. Thomas, Y . Tian, and A. Bruni, “Diff-SAGe: End-to-End Spatial Audio Generation Using Diffu- sion Models,” in2025 IEEE International Conference on Acous- tics, Speech and Signal Processing, ICASSP 2025. IEEE, 2025, pp. 1–5
2025
-
[12]
Both Ears Wide Open: Towards Language-Driven Spa- tial Audio Generation,
P. Sun, S. Cheng, X. Li, Z. Ye, H. Liu, H. Zhang, W. Xue, and Y . Guo, “Both Ears Wide Open: Towards Language-Driven Spa- tial Audio Generation,” inThe Thirteenth International Confer- ence on Learning Representations, 2025
2025
-
[13]
ViSAGe: Video-to-Spatial Au- dio Generation,
J. Kim, H. Yun, and G. Kim, “ViSAGe: Video-to-Spatial Au- dio Generation,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[14]
ASAudio: A survey of advanced spatial audio research,
Z. Zhu, Y . Zhang, W. Guo, C. Pan, and Z. Zhao, “ASAudio: A survey of advanced spatial audio research,” inProceedings of the 14th International Joint Conference on Natural Language Pro- cessing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, Dec. 2025, pp. 417– 442
2025
-
[15]
Fr ´echet Au- dio Distance: A Reference-Free Metric for Evaluating Music En- hancement Algorithms,
K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi, “Fr ´echet Au- dio Distance: A Reference-Free Metric for Evaluating Music En- hancement Algorithms,” inInterspeech, 2019, pp. 2350–2354
2019
-
[16]
Adapt- ing Fr ´echet Audio Distance for generative music evaluation,
A. Gui, H. Gamper, S. Braun, and D. Emmanouilidou, “Adapt- ing Fr ´echet Audio Distance for generative music evaluation,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 1331– 1335
2024
-
[17]
KAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation,
Y . Chung, P. Eu, J. Lee, K. Choi, J. Nam, and B. S. Chon, “KAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation,”arXiv:2502.15602, 2025
arXiv 2025
-
[18]
Diffstereo: End-to-end mono-to-stereo audio generation with diffusion trans- former,
S. Zhang, Z. Dai, Y . Zang, Y . Cao, and Q. Kong, “Diffstereo: End-to-end mono-to-stereo audio generation with diffusion trans- former,” inProc. Interspeech 2025, 2025, pp. 3150–3154
2025
-
[19]
Pa- rameter sensitivity of deep-feature based evaluation metrics for audio textures,
C. Gupta, Y . Wei, Z. Gong, P. Kamath, Z. Li, and L. Wyse, “Pa- rameter sensitivity of deep-feature based evaluation metrics for audio textures,” inProceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022, 2022, pp. 462–468
2022
-
[20]
Spectral modeling synthesis: A sound analysis/synthesis system based on a deterministic plus stochastic decomposition,
X. Serra and J. Smith, “Spectral modeling synthesis: A sound analysis/synthesis system based on a deterministic plus stochastic decomposition,”Computer Music Journal, vol. 14, no. 4, pp. 12– 24, 1990
1990
-
[21]
Sound Designer-Generative AI Interactions: Towards Designing Creative Support Tools for Professional Sound Designers,
P. Kamath, F. Morreale, P. L. Bagaskara, Y . Wei, and S. Nanayakkara, “Sound Designer-Generative AI Interactions: Towards Designing Creative Support Tools for Professional Sound Designers,” inProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024
2024
-
[22]
Sound model factory: An integrated system architecture for generative audio modelling,
L. Wyse, P. Kamath, and C. Gupta, “Sound model factory: An integrated system architecture for generative audio modelling,” in International Conference on Computational Intelligence in Mu- sic, Sound, Art and Design (Part of EvoStar). Springer, 2022, pp. 308–322
2022
-
[23]
Soundspaces: Audio- visual navigation in 3d environments,
C. Chen, U. Jain, C. Schissler, S. V . A. Gari, Z. Al-Halah, V . K. Ithapu, P. Robinson, and K. Grauman, “Soundspaces: Audio- visual navigation in 3d environments,” inEuropean Conference on Computer Vision ECCV, 2020
2020
-
[24]
Spatial scaper: a library to simulate and augment soundscapes for sound event localization and detection in realistic rooms,
I. R. Roman, C. Ick, S. Ding, A. S. Roman, B. McFee, and J. P. Bello, “Spatial scaper: a library to simulate and augment soundscapes for sound event localization and detection in realistic rooms,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 1221–1225
2024
-
[25]
FSD50k: an open dataset of human-labeled sound events,
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “FSD50k: an open dataset of human-labeled sound events,”IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, vol. 30, pp. 829–852, 2021
2021
-
[26]
PSELDNets: Pre-trained neural networks on a large-scale synthetic dataset for sound event localization and detection,
J. Hu, Y . Cao, M. Wu, F. Kang, F. Yang, W. Wang, M. D. Plumb- ley, and J. Yang, “PSELDNets: Pre-trained neural networks on a large-scale synthetic dataset for sound event localization and detection,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 2845–2860, 2025
2025
-
[27]
CNN architectures for large-scale audio classification,
S. Hershey, S. Chaudhuri, D. P. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seyboldet al., “CNN architectures for large-scale audio classification,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP. IEEE, 2017, pp. 131–135
2017
-
[28]
Sound localization by self-supervised time delay estimation,
Z. Chen, D. F. Fouhey, and A. Owens, “Sound localization by self-supervised time delay estimation,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 489–508
2022
-
[29]
GRAM: Spa- tial general-purpose audio representations for real-world environ- ments,
G. Yuksel, M. van Gerven, and K. van der Heijden, “GRAM: Spa- tial general-purpose audio representations for real-world environ- ments,”arXiv preprint arXiv:2602.03307, 2026
arXiv 2026
-
[30]
SoundReactor: Frame-level Online Video-to-Audio Generation,
K. Saito, J. Tanke, C. Simon, M. Ishii, K. Shimada, Z. No- vack, Z. Zhong, A. Hayakawa, T. Shibuya, and Y . Mitsufuji, “SoundReactor: Frame-level Online Video-to-Audio Generation,” arXiv preprint arXiv:2510.02110, 2025
arXiv 2025
-
[31]
HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dub- nov, “HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 646–650
2022
-
[32]
Multi-ACCDOA: Localizing And Detecting Overlapping Sounds From The Same Class With Auxiliary Du- plicating Permutation Invariant Training,
K. Shimada, Y . Koyama, S. Takahashi, N. Takahashi, E. Tsunoo, and Y . Mitsufuji, “Multi-ACCDOA: Localizing And Detecting Overlapping Sounds From The Same Class With Auxiliary Du- plicating Permutation Invariant Training,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 316–320
2022
-
[33]
Parametric acoustic camera for real-time sound capture, analysis and track- ing,
L. McCormack, S. Delikaris-Manias, and V . Pulkki, “Parametric acoustic camera for real-time sound capture, analysis and track- ing,” inProceedings of the 20th International Conference on Dig- ital Audio Effects (DAFx-17), 2017, pp. 412–419
2017
-
[34]
SPARTA & COMPASS: Real- time implementations of linear and parametric spatial audio repro- duction and processing methods,
L. McCormack and A. Politis, “SPARTA & COMPASS: Real- time implementations of linear and parametric spatial audio repro- duction and processing methods,” inAudio Engineering Society Conference: 2019 AES International Conference on Immersive and Interactive Audio. Audio Engineering Society, 2019
2019
-
[35]
The unreasonable effectiveness of deep features as a perceptual met- ric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual met- ric,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.