From Single to Multiple Attributes: Experimental Insights on Sampling-Based Distinct Combination Estimation in GROUP-BY Queries
Pith reviewed 2026-07-02 02:53 UTC · model grok-4.3
The pith
Sampling-based methods cannot reliably estimate distinct combinations in multi-attribute GROUP-BY queries because samples rarely preserve joint distributions across attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Joint distribution information recoverable from samples is usually insufficient for accurate multi-attribute GROUP-BY cardinality estimates; existing methods leave single-attribute statistics under-exploited; and filtered GROUP-BY queries are especially difficult to estimate, with the resulting errors directly affecting query-plan selection in PostgreSQL.
What carries the argument
A specialized workload generator that creates representative filtered and non-filtered multi-attribute GROUP-BY queries over real-world datasets, paired with an error-analysis pipeline that links estimation mistakes to absent joint distributions and measures their effect on PostgreSQL plan selection.
If this is right
- Joint distributions across attributes must be modeled explicitly rather than recovered from independent samples.
- Single-attribute statistics can be leveraged more aggressively to reduce multi-attribute estimation error.
- Errors in GROUP-BY cardinality estimates propagate to materially different execution plans in PostgreSQL.
- Future estimators should combine sampling with mechanisms that capture attribute correlations.
Where Pith is reading between the lines
- The observed limitations may extend to full SPJ queries once joins are added to the workload generator.
- Learned models trained only on SPJ workloads may need retraining on GROUP-BY-specific data to close the accuracy gap.
- Query optimizers could benefit from returning uncertainty ranges around GROUP-BY cardinalities instead of single point estimates.
Load-bearing premise
The specialized workload generator produces queries that are representative of real-world multi-attribute GROUP-BY usage patterns across the tested datasets.
What would settle it
Repeating the identical evaluation on a fresh real-world dataset whose attribute correlations differ substantially from the four used in the study would yield materially different error patterns and plan-selection impacts.
Figures








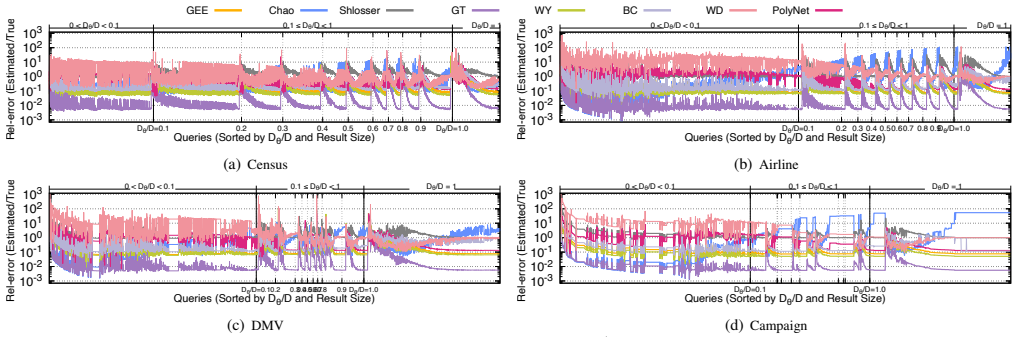



read the original abstract
Estimating the number of distinct combinations in multi-attribute GROUP-BY queries remains a significant yet underexplored challenge. Current cardinality estimation techniques primarily focus on SPJ queries (i.e., selections, projections, and joins) and neglect GROUP-BY operations; meanwhile, distinct value estimation research has mainly targeted the single-attribute setting. Although sampling-based methods, including recent approaches with learned models, can theoretically support multi-attribute estimation, their practical effectiveness remains unclear. A comprehensive empirical evaluation is thus lacking to address whether joint distribution information from samples alone is sufficient for accurate multi-attribute estimation, whether existing methods fully exploit single-attribute information and can be further optimized, and whether filtered GROUP-BY queries can be accurately estimated. To this end, we propose a specialized workload generator for multi-attribute GROUP-BY queries and generate both filtered and non-filtered queries over four real-world datasets. By evaluating existing methods across synthetic workloads and the multi-table TPC-H benchmark, we analyze the sources of GROUP-BY cardinality estimation errors and their impact on PostgreSQL's plan selection, offering key recommendations for future estimator design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical evaluation of sampling-based methods for estimating the number of distinct combinations in multi-attribute GROUP-BY queries. It introduces a specialized workload generator to produce both filtered and non-filtered queries over four real-world datasets, evaluates existing methods on these workloads and the TPC-H benchmark, analyzes sources of estimation errors and their impact on PostgreSQL's query plan selection, and provides recommendations for future estimator design.
Significance. If the workload generator produces queries representative of real-world multi-attribute GROUP-BY usage, this work fills a notable gap in cardinality estimation research by providing practical insights into the sufficiency of sample-based joint distributions for multi-attribute estimation, the potential for optimizing single-attribute methods, and the estimability of filtered GROUP-BY queries. The analysis of downstream effects on plan selection adds significant practical value.
major comments (1)
- [Workload Generator] The central empirical claims depend on the specialized workload generator producing representative queries. However, the manuscript provides no external validation, such as comparisons to real query logs, selectivity histograms, or attribute-correlation statistics from production workloads, to confirm that the generated queries reproduce observed joint frequencies, filter selectivities, or correlation structures.
minor comments (1)
- [Abstract] The abstract outlines the evaluation design but lacks details on error metrics used, baseline comparisons, statistical significance testing, or data exclusion rules, which hinders immediate assessment of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study. We address the major comment point by point below and are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Workload Generator] The central empirical claims depend on the specialized workload generator producing representative queries. However, the manuscript provides no external validation, such as comparisons to real query logs, selectivity histograms, or attribute-correlation statistics from production workloads, to confirm that the generated queries reproduce observed joint frequencies, filter selectivities, or correlation structures.
Authors: We agree that external validation against production query logs would provide additional support for the representativeness of the generated workloads. Such logs are typically proprietary and unavailable for public research. Our generator was instead designed to enable systematic, controlled variation of key factors (number of GROUP-BY attributes, filter selectivities, and correlation structures) while grounding parameter ranges in statistics computed directly from the four real-world datasets used in the evaluation. We will revise the manuscript to expand the workload generator section with explicit justification of these design choices, including how dataset-derived statistics informed the parameter distributions, and to add an explicit limitations discussion acknowledging the absence of direct production-log comparisons. We believe this will clarify the scope of the claims without altering the core empirical findings. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential reductions
full rationale
The paper conducts an empirical study: it introduces a workload generator for multi-attribute GROUP-BY queries, generates synthetic workloads over four real datasets plus TPC-H, and evaluates existing sampling-based estimators for accuracy and impact on query planning. No equations, fitted parameters, predictions, or uniqueness theorems are present. The generator is a methodological tool whose outputs are tested against external benchmarks (real datasets and TPC-H); its representativeness is an assumption about experimental validity, not a self-definitional or fitted-input reduction. No self-citations are load-bearing for any derivation because none exist. The analysis is self-contained against external data and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tpc-h analyzed: Hidden mes- sages and lessons learned from an influential benchmark,
P. Boncz, T. Neumann, and O. Erling, “Tpc-h analyzed: Hidden mes- sages and lessons learned from an influential benchmark,” inTechnology Conference on Performance Evaluation and Benchmarking. Springer, 2013, pp. 61–76
2013
-
[2]
The making of tpc-ds
R. O. Nambiar and M. Poess, “The making of tpc-ds.” inVLDB, vol. 6, 2006, pp. 1049–1058
2006
-
[3]
Analyzing the impact of cardinality estimation on execution plans in microsoft sql server,
K. Lee, A. Dutt, V . Narasayya, and S. Chaudhuri, “Analyzing the impact of cardinality estimation on execution plans in microsoft sql server,” Proceedings of the VLDB Endowment, vol. 16, no. 11, pp. 2871–2883, 2023
2023
-
[4]
Postgresql,
“Postgresql,” https://github.com/postgres/postgres/blob/ 16a4e4aecd47da7a6c4e1ebc20f6dd1a13f9133b/src/backend/utils/ adt/selfuncs.c#L3044, 2025
2025
-
[5]
“Mysql,” https://github.com/mysql/mysql-server/blob/trunk/sql/join optimizer/cost model.cc, 2025
2025
-
[6]
A deep dive into statistics (pgconfeu),
L. Leinweber, “A deep dive into statistics (pgconfeu),” https://www.postgresql.eu/events/pgconfeu2024/sessions/session/5747/ slides/559/postgres statistics presentation.pdf, 2024
2024
-
[7]
Every row counts: Combining sketches and sampling for accurate group-by result estimates,
M. J. Freitag and T. Neumann, “Every row counts: Combining sketches and sampling for accurate group-by result estimates,” in 9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org, 2019. [Online]. Available: http://cidrdb.org/cidr2019/ papers/p23-freitag-cidr19.pdf
2019
-
[8]
Deepdb: Learn from data, not from queries!
B. Hilprecht, A. Schmidt, M. Kulessa, A. Molina, K. Kersting, and C. Binnig, “Deepdb: Learn from data, not from queries!”Proc. VLDB Endow., vol. 13, no. 7, pp. 992–1005, 2020. [Online]. Available: http://www.vldb.org/pvldb/vol13/p992-hilprecht.pdf
2020
-
[9]
FLAT: fast, lightweight and accurate method for cardinality estimation,
R. Zhu, Z. Wu, Y . Han, K. Zeng, A. Pfadler, Z. Qian, J. Zhou, and B. Cui, “FLAT: fast, lightweight and accurate method for cardinality estimation,”Proc. VLDB Endow., vol. 14, no. 9, pp. 1489–1502, 2021. [Online]. Available: http://www.vldb.org/pvldb/vol14/p1489-zhu.pdf
2021
-
[10]
Deep unsupervised cardinality estimation,
Z. Yang, E. Liang, A. Kamsetty, C. Wu, Y . Duan, P. Chen, P. Abbeel, J. M. Hellerstein, S. Krishnan, and I. Stoica, “Deep unsupervised cardinality estimation,”Proc. VLDB Endow., vol. 13, no. 3, pp. 279–292, 2019. [Online]. Available: http://www.vldb.org/pvldb/vol13/ p279-yang.pdf
2019
-
[11]
Variable skipping for autoregressive range density estimation,
E. Liang, Z. Yang, I. Stoica, P. Abbeel, Y . Duan, and P. Chen, “Variable skipping for autoregressive range density estimation,” inProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020, pp. 6040–6049. [Online]. Available: http://p...
2020
-
[12]
Neurocard: One cardinality estimator for all tables,
Z. Yang, A. Kamsetty, S. Luan, E. Liang, Y . Duan, P. Chen, and I. Stoica, “Neurocard: One cardinality estimator for all tables,”Proc. VLDB Endow., vol. 14, no. 1, pp. 61–73, 2020. [Online]. Available: http://www.vldb.org/pvldb/vol14/p61-yang.pdf
2020
-
[13]
Approximate distinct counts for billions of datasets,
W. Cai, M. Balazinska, and D. Suciu, “Pessimistic cardinality estimation: Tighter upper bounds for intermediate join cardinalities,” inProceedings of the 2019 International Conference on Management of Data, SIGMOD Conference 2019, Amsterdam, The Netherlands, June 30 - July 5, 2019, P. A. Boncz, S. Manegold, A. Ailamaki, A. Deshpande, and T. Kraska, Eds. A...
-
[14]
Factorjoin: A new cardinality estimation framework for join queries,
Z. Wu, P. Negi, M. Alizadeh, T. Kraska, and S. Madden, “Factorjoin: A new cardinality estimation framework for join queries,”Proceedings of the ACM on Management of Data, vol. 1, no. 1, pp. 1–27, 2023
2023
-
[15]
ALECE: an attention-based learned cardinality estimator for SPJ queries on dynamic workloads,
P. Li, W. Wei, R. Zhu, B. Ding, J. Zhou, and H. Lu, “ALECE: an attention-based learned cardinality estimator for SPJ queries on dynamic workloads,”Proc. VLDB Endow., vol. 17, no. 2, pp. 197–210,
-
[16]
Available: https://www.vldb.org/pvldb/vol17/p197-li.pdf
[Online]. Available: https://www.vldb.org/pvldb/vol17/p197-li.pdf
-
[17]
Efficiently approximating selectivity functions using low overhead regression models,
A. Dutt, C. Wang, V . R. Narasayya, and S. Chaudhuri, “Efficiently approximating selectivity functions using low overhead regression models,”Proc. VLDB Endow., vol. 13, no. 11, pp. 2215–2228, 2020. [Online]. Available: http://www.vldb.org/pvldb/vol13/p2215-dutt.pdf
2020
-
[18]
Learned cardinalities: Estimating correlated joins with deep learning,
A. Kipf, T. Kipf, B. Radke, V . Leis, P. A. Boncz, and A. Kemper, “Learned cardinalities: Estimating correlated joins with deep learning,” in9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org, 2019. [Online]. Available: http://cidrdb.org/cidr2019/ papers/p101-k...
2019
-
[19]
Pre-training summarization models of structured datasets for cardinality estimation,
Y . Lu, S. Kandula, A. C. K ¨onig, and S. Chaudhuri, “Pre-training summarization models of structured datasets for cardinality estimation,” Proc. VLDB Endow., vol. 15, no. 3, pp. 414–426, 2021. [Online]. Available: http://www.vldb.org/pvldb/vol15/p414-lu.pdf
2021
-
[20]
Z. Meng, P. Wu, G. Cong, R. Zhu, and S. Ma, “Unsupervised selectivity estimation by integrating gaussian mixture models and an autoregressive model,” inProceedings of the 25th International Conference on Extending Database Technology, EDBT 2022, Edinburgh, UK, March 29 - April 1, 2022, J. Stoyanovich, J. Teubner, P. Guagliardo, M. Nikolic, A. Pieris, J. M...
-
[21]
A unified deep model of learning from both data and queries for cardinality estimation,
P. Wu and G. Cong, “A unified deep model of learning from both data and queries for cardinality estimation,” inSIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, G. Li, Z. Li, S. Idreos, and D. Srivastava, Eds. ACM, 2021, pp. 2009–2022. [Online]. Available: https://doi.org/10.1145/3448016.3452830
-
[22]
Speeding up end-to-end query execution via learning-based progressive cardinality estimation,
F. Wang, X. Yan, M. L. Yiu, S. Li, Z. Mao, and B. Tang, “Speeding up end-to-end query execution via learning-based progressive cardinality estimation,”Proc. ACM Manag. Data, vol. 1, no. 1, pp. 28:1–28:25,
-
[23]
Available: https://doi.org/10.1145/3588708
[Online]. Available: https://doi.org/10.1145/3588708
-
[24]
Lightweight and accurate cardinality estimation by neural network gaussian process,
K. Zhao, J. X. Yu, Z. He, R. Li, and H. Zhang, “Lightweight and accurate cardinality estimation by neural network gaussian process,” inSIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Z. G. Ives, A. Bonifati, and A. E. Abbadi, Eds. ACM, 2022, pp. 973–987. [Online]. Available: https://doi.org/10.1145/35...
-
[25]
Fauce: Fast and accurate deep ensembles with uncertainty for cardinality estimation,
J. Liu, W. Dong, D. Li, and Q. Zhou, “Fauce: Fast and accurate deep ensembles with uncertainty for cardinality estimation,”Proc. VLDB Endow., vol. 14, no. 11, pp. 1950–1963, 2021. [Online]. Available: http://www.vldb.org/pvldb/vol14/p1950-liu.pdf
1950
-
[26]
Learned cardinality estimation for similarity queries,
J. Sun, G. Li, and N. Tang, “Learned cardinality estimation for similarity queries,” inSIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, G. Li, Z. Li, S. Idreos, and D. Srivastava, Eds. ACM, 2021, pp. 1745–1757. [Online]. Available: https://doi.org/10.1145/3448016.3452790
-
[27]
Bayescard: A unified bayesian framework for cardinality estimation,
Z. Wu and A. Shaikhha, “Bayescard: A unified bayesian framework for cardinality estimation,”CoRR, vol. abs/2012.14743, 2020. [Online]. Available: https://arxiv.org/abs/2012.14743
-
[28]
Learned cardinality estimation: A design space exploration and A comparative evaluation,
J. Sun, J. Zhang, Z. Sun, G. Li, and N. Tang, “Learned cardinality estimation: A design space exploration and A comparative evaluation,” Proc. VLDB Endow., vol. 15, no. 1, pp. 85–97, 2021. [Online]. Available: http://www.vldb.org/pvldb/vol15/p85-li.pdf
2021
-
[29]
An approach based on bayesian networks for query selectivity estimation,
M. Halford, P. Saint-Pierre, and F. Morvan, “An approach based on bayesian networks for query selectivity estimation,” inDatabase Systems for Advanced Applications - 24th International Conference, DASFAA 2019, Chiang Mai, Thailand, April 22-25, 2019, Proceedings, Part II, ser. Lecture Notes in Computer Science, G. Li, J. Yang, J. Gama, J. Natwichai, and Y...
-
[30]
Ultraloglog: A practical and more space-efficient alternative to hyperloglog for approximate distinct counting,
O. Ertl, “Ultraloglog: A practical and more space-efficient alternative to hyperloglog for approximate distinct counting,”Proc. VLDB Endow., vol. 17, no. 7, pp. 1655–1668, 2024. [Online]. Available: https://www.vldb.org/pvldb/vol17/p1655-ertl.pdf
2024
-
[31]
Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm,
P. Flajolet, ´E. Fusy, O. Gandouet, and F. Meunier, “Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm,”Discrete mathematics & theoretical computer science, no. Proceedings, 2007
2007
-
[32]
Towards estimation error guarantees for distinct values,
M. Charikar, S. Chaudhuri, R. Motwani, and V . Narasayya, “Towards estimation error guarantees for distinct values,” inProceedings of the nineteenth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, 2000, pp. 268–279
2000
-
[33]
Nonparametric estimation of the number of classes in a population,
A. Chao, “Nonparametric estimation of the number of classes in a population,”Scandinavian Journal of statistics, pp. 265–270, 1984
1984
-
[34]
Estimating the number of classes via sample coverage,
A. Chao and S.-M. Lee, “Estimating the number of classes via sample coverage,”Journal of the American statistical Association, vol. 87, no. 417, pp. 210–217, 1992
1992
-
[35]
Estimating the number of classes in a finite population,
P. J. Haas and L. Stokes, “Estimating the number of classes in a finite population,”Journal of the American Statistical Association, vol. 93, no. 444, pp. 1475–1487, 1998
1998
-
[36]
On estimation of the size of the dictionary of a long text on the basis of a sample,
A. Shlosser, “On estimation of the size of the dictionary of a long text on the basis of a sample,”Engineering Cybernetics, vol. 19, no. 1, pp. 97–102, 1981
1981
-
[37]
The number of new species, and the increase in population coverage, when a sample is increased,
I. J. Good and G. H. Toulmin, “The number of new species, and the increase in population coverage, when a sample is increased,” Biometrika, vol. 43, no. 1-2, pp. 45–63, 1956
1956
-
[38]
Chebyshev polynomials, moment matching, and optimal estimation of the unseen,
Y . Wu and P. Yang, “Chebyshev polynomials, moment matching, and optimal estimation of the unseen,”The Annals of Statistics, vol. 47, no. 2, pp. 857–883, 2019
2019
-
[39]
Learning to be a statistician: Learned estimator for number of distinct values,
R. Wu, B. Ding, X. Chu, Z. Wei, X. Dai, T. Guan, and J. Zhou, “Learning to be a statistician: Learned estimator for number of distinct values,”Proc. VLDB Endow., vol. 15, no. 2, pp. 272–284, 2021. [Online]. Available: http://www.vldb.org/pvldb/vol15/p272-wu.pdf
2021
-
[40]
Learning-based property estimation with polynomials,
J. Li, R. Lei, S. Wang, Z. Wei, and B. Ding, “Learning-based property estimation with polynomials,”Proc. ACM Manag. Data, vol. 2, no. 3, p. 148, 2024. [Online]. Available: https://doi.org/10.1145/3654994
-
[41]
Sampling-based estimation of the number of distinct values in distributed environment,
J. Li, Z. Wei, B. Ding, X. Dai, L. Lu, and J. Zhou, “Sampling-based estimation of the number of distinct values in distributed environment,” inKDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, A. Zhang and H. Rangwala, Eds. ACM, 2022, pp. 893–903. [Online]. Available: https://doi.org...
-
[42]
Adandv: Adaptive number of distinct value estimation via learning to select and fuse estimators,
X. Xu, T. Zhang, X. He, H. Li, R. Kang, S. Wang, L. Xu, Z. Liang, S. Luo, L. Zhang, and J. Chen, “Adandv: Adaptive number of distinct value estimation via learning to select and fuse estimators,”CoRR, vol. abs/2502.16190, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.16190
-
[43]
Approximate distinct counts for billions of datasets,
D. Ting, “Approximate distinct counts for billions of datasets,” in Proceedings of the 2019 International Conference on Management of Data, SIGMOD Conference 2019, Amsterdam, The Netherlands, June 30 - July 5, 2019, P. A. Boncz, S. Manegold, A. Ailamaki, A. Deshpande, and T. Kraska, Eds. ACM, 2019, pp. 69–86. [Online]. Available: https://doi.org/10.1145/3...
-
[44]
Cardinality estimation: an experimental survey,
H. Harmouch and F. Naumann, “Cardinality estimation: an experimental survey,”Proc. VLDB Endow., vol. 11, no. 4, p. 499–512, Dec. 2017. [Online]. Available: https://doi.org/10.1145/3186728.3164145
-
[45]
Why go logarithmic if we can go linear?: Towards effective distinct counting of search traffic,
A. Metwally, D. Agrawal, and A. E. Abbadi, “Why go logarithmic if we can go linear?: Towards effective distinct counting of search traffic,” inEDBT 2008, 11th International Conference on Extending Database Technology, Nantes, France, March 25-29, 2008, Proceedings, ser. ACM International Conference Proceeding Series, A. Kemper, P. Valduriez, N. Mouaddib, ...
-
[46]
Half-xor: A fully-dynamic sketch for estimating the number of distinct values in big tables,
P. Wang, D. Xie, J. Zhao, J. Li, Z. Li, R. Li, Y . Ren, and J. Di, “Half-xor: A fully-dynamic sketch for estimating the number of distinct values in big tables,”IEEE Trans. Knowl. Data Eng., vol. 36, no. 7, pp. 3111–3125, 2024. [Online]. Available: https://doi.org/10.1109/TKDE.2024.3359710
-
[47]
Information theoretic limits of cardinality estimation: Fisher meets shannon,
S. Pettie and D. Wang, “Information theoretic limits of cardinality estimation: Fisher meets shannon,” inSTOC ’21: 53rd Annual ACM SIGACT Symposium on Theory of Computing, Virtual Event, Italy, June 21-25, 2021, S. Khuller and V . V . Williams, Eds. ACM, 2021, pp. 556–569. [Online]. Available: https://doi.org/10.1145/3406325.3451032
-
[48]
Hyperloglog in practice: Algo- rithmic engineering of a state of the art cardinality estimation algorithm,
S. Heule, M. Nunkesser, and A. Hall, “Hyperloglog in practice: Algo- rithmic engineering of a state of the art cardinality estimation algorithm,” inProceedings of the 16th International Conference on Extending Database Technology, 2013, pp. 683–692
2013
-
[49]
Multi ndv,
“Multi ndv,” https://github.com/gloriaaaa/Multi Ndv, 2026
2026
-
[50]
Multivariate statistics examples,
“Multivariate statistics examples,” https://www.postgresql.org/docs/ current/multivariate-statistics-examples.html, 2025
2025
-
[51]
Estimating filtered group-by queries is hard: Deep learning to the rescue,
A. Kipf, M. Freitag, D. V orona, P. Boncz, T. Neumann, and A. Kemper, “Estimating filtered group-by queries is hard: Deep learning to the rescue,” in1st International Workshop on Applied AI for Database Systems and Applications, 2019
2019
-
[52]
Sampling for big data profiling: A survey,
Z. Liu and A. Zhang, “Sampling for big data profiling: A survey,”IEEE access, vol. 8, pp. 72 713–72 726, 2020
2020
-
[53]
Profiling relational data: a survey,
Z. Abedjan, L. Golab, and F. Naumann, “Profiling relational data: a survey,”The VLDB Journal, vol. 24, pp. 557–581, 2015
2015
-
[54]
H. Lan, Z. Bao, and Y . Peng, “A survey on advancing the DBMS query optimizer: Cardinality estimation, cost model, and plan enumeration,” Data Sci. Eng., vol. 6, no. 1, pp. 86–101, 2021. [Online]. Available: https://doi.org/10.1007/s41019-020-00149-7
-
[55]
U. M. L. Repository, “US Census Data (1990),” https://doi.org/10.24432/C5VP42, 2001
-
[56]
Airlines departure delay,
“Airlines departure delay,” https://www.openml.org/d/42728, 2020
2020
-
[57]
Vehicle, snowmobile, and boat registrations,
“Vehicle, snowmobile, and boat registrations,” https://catalog.data.gov/ dataset/vehicle-snowmobile-and-boat-registrations, 2020
2020
-
[58]
Campaign finance data,
“Campaign finance data,” https://www.fec.gov/data/, 2020
2020
-
[59]
Are we ready for learned cardinality estimation?
X. Wang, C. Qu, W. Wu, J. Wang, and Q. Zhou, “Are we ready for learned cardinality estimation?”Proc. VLDB Endow., vol. 14, no. 9, pp. 1640–1654, 2021. [Online]. Available: http: //www.vldb.org/pvldb/vol14/p1640-wang.pdf
2021
-
[60]
Algorithmic techniques for independent query sampling,
Y . Tao, “Algorithmic techniques for independent query sampling,” in Proceedings of the 41st ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, ser. PODS ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 129–138. [Online]. Available: https://doi.org/10.1145/3517804.3526068
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.