Diff-ANO: Towards Fast High-Resolution Ultrasound Computed Tomography via Conditional Consistency Models and Adjoint Neural Operators
Pith reviewed 2026-05-19 04:00 UTC · model grok-4.3
The pith
Conditional consistency models paired with adjoint neural operators enable fast high-resolution ultrasound tomography even with sparse measurements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
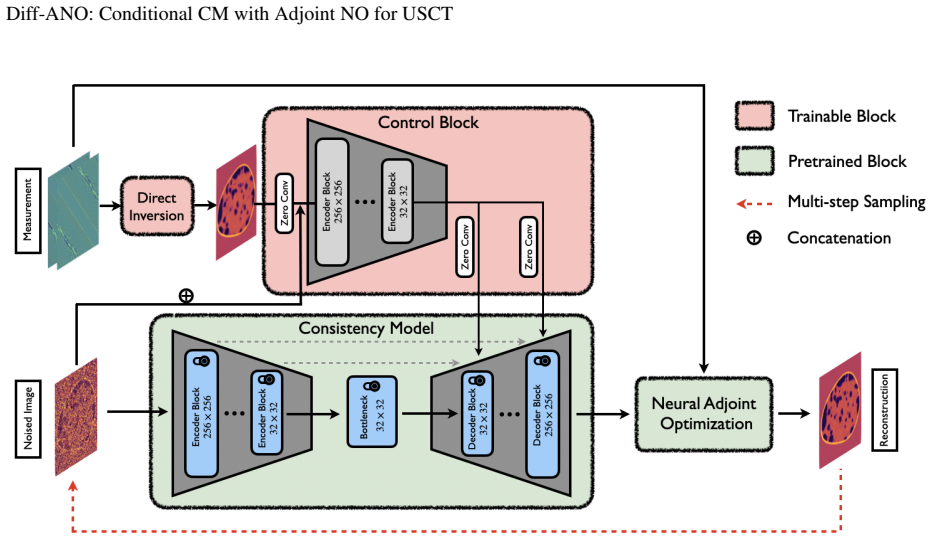
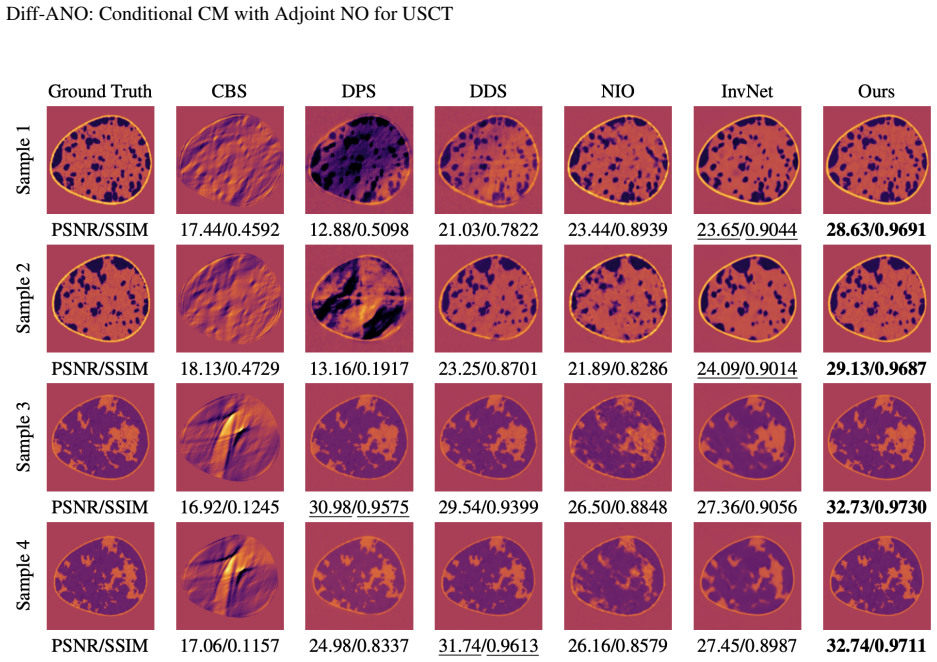
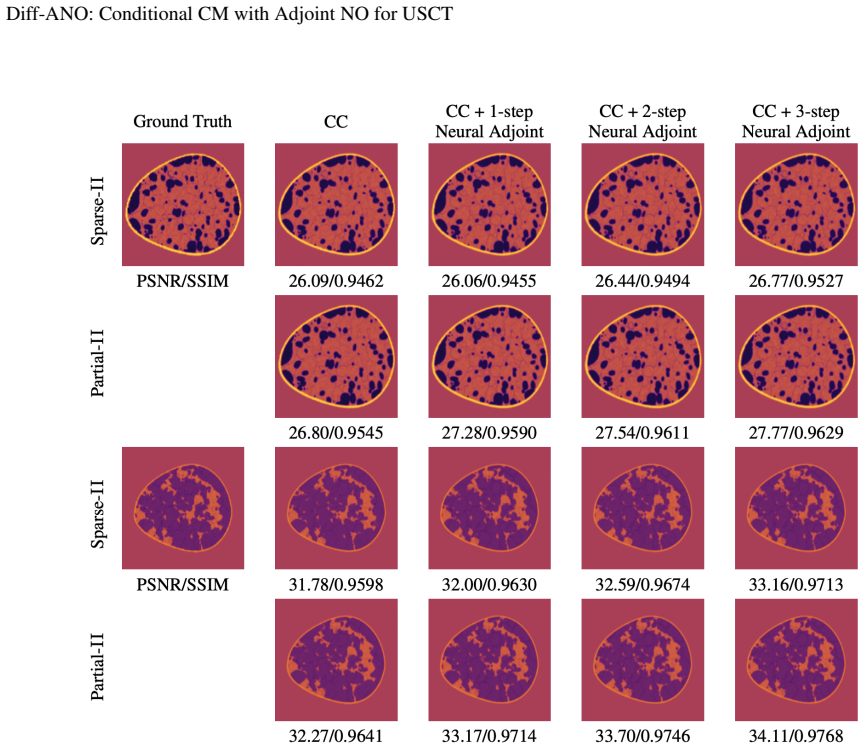
Diff-ANO combines a conditional consistency model that learns a self-consistent mapping along diffusion trajectories for few-step conditional sampling with an adjoint operator learning module that substitutes neural-operator surrogates for traditional PDE solvers in the gradient step. Training pairs for the operator are generated online via the memory-efficient batch-based Convergent Born Series. Experiments show the combined framework raises both speed and image quality relative to prior diffusion-regularized methods, most noticeably when measurements are sparse or partial.
What carries the argument
Adjoint operator learning module that supplies neural-operator surrogates for efficient adjoint-based gradient computation inside the diffusion-regularized inverse problem.
If this is right
- Gradient evaluations inside the reconstruction loop become far cheaper because no full numerical Helmholtz solve is required at each step.
- Diffusion sampling reduces to a handful of steps once the conditional consistency mapping is learned.
- Reconstruction quality remains stable or improves when the number of transducer views is reduced.
- Training data for the neural operator can be produced on the fly without storing large batches of full wave simulations.
Where Pith is reading between the lines
- The same surrogate-gradient trick could transfer to other wave-equation inverse problems such as photoacoustic or seismic imaging.
- Refining the consistency model might push the required sampling steps even lower than the current few-step regime.
- Real experimental ultrasound data would provide a direct test of whether discretization mismatches in the surrogate remain tolerable outside simulated settings.
Load-bearing premise
The learned adjoint neural operator must approximate the true PDE adjoint closely enough that the resulting gradients stay reliable and do not introduce errors that lower final reconstruction quality.
What would settle it
Run the same optimization loop once with the learned adjoint operator and once with an exact PDE adjoint; if the learned version produces visibly worse images or fails to converge while the exact version succeeds, the central claim is falsified.
Figures






read the original abstract
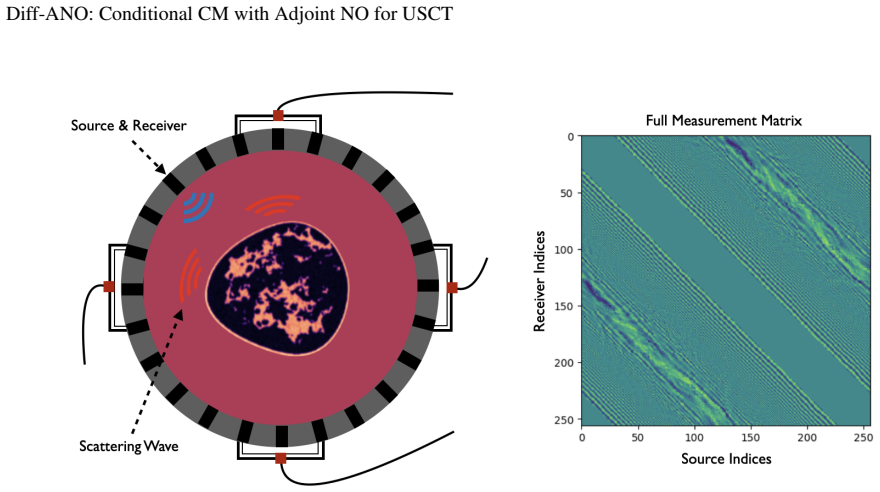
Ultrasound Computed Tomography (USCT) constitutes a nonlinear inverse problem with inherent ill-posedness that can benefit from regularization through diffusion generative priors. However, traditional approaches for solving Helmholtz equation-constrained USCT face three fundamental challenges when integrating these priors: PDE-constrained gradient computation, discretization-induced approximation errors, and computational imbalance between neural networks and numerical PDE solvers. In this work, we introduce \textbf{Diff-ANO} (\textbf{Diff}usion-based Models with \textbf{A}djoint \textbf{N}eural \textbf{O}perators), a novel framework that combines conditional consistency models with adjoint operator learning to address these limitations. Our two key innovations include: (1) a \textit{conditional consistency model} that enables measurement-conditional few-step sampling by directly learning a self-consistent mapping from diffusion trajectories, and (2) an \textit{adjoint operator learning} module that replaces traditional PDE solvers with neural operator surrogates for efficient adjoint-based gradient computation. To enable practical deployment, we introduce the batch-based Convergent Born Series (BCBS)--a memory-efficient strategy for online generation of neural operator training pairs. Comprehensive experiments demonstrate that Diff-ANO significantly improves both computational efficiency and reconstruction quality, especially under sparse-view and partial-view measurement scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Diff-ANO, a framework that integrates conditional consistency models with adjoint neural operator learning to solve the nonlinear, ill-posed Ultrasound Computed Tomography (USCT) inverse problem. It targets three challenges—PDE-constrained gradient computation, discretization errors, and computational imbalance—by replacing traditional Helmholtz solvers with neural operator surrogates for adjoint gradients and introducing batch-based Convergent Born Series (BCBS) for online generation of training pairs. The authors claim that this enables few-step conditional sampling and yields substantial gains in both speed and reconstruction quality, particularly for sparse-view and partial-view measurements.
Significance. If the adjoint neural operator surrogates prove sufficiently accurate, the work could provide a practical route to incorporating diffusion generative priors into PDE-constrained inverse problems, improving both efficiency and fidelity in high-resolution USCT. The BCBS strategy for memory-efficient training-pair generation and the conditional consistency model are concrete technical contributions that address real bottlenecks in scaling generative methods to large-scale imaging inverse problems.
major comments (2)
- [Experiments] The central claim that the adjoint neural operator produces gradients reliable enough for the conditional consistency model sampling rests on unverified surrogate accuracy. No quantitative comparison (e.g., operator-norm or pointwise error between the learned adjoint and a reference Helmholtz adjoint) or ablation isolating surrogate-induced gradient bias from other error sources is reported, even though the inverse problem is known to be sensitive to such bias under sparse-view conditions.
- [Methods] The manuscript positions adjoint operator learning as simultaneously fixing PDE-constrained gradients and discretization errors, yet provides no error bounds, consistency metrics, or convergence analysis for the neural operator approximation when composed with the consistency-model sampling trajectory. This leaves open whether discretization errors are reduced or merely replaced by approximation errors that could accumulate in the ill-posed regime.
minor comments (1)
- [Abstract] The abstract refers to “comprehensive experiments” without citing specific figures, tables, or quantitative metrics (e.g., PSNR, SSIM, runtime, or gradient-error tables), which makes it difficult for readers to gauge the strength of the reported gains from the summary alone.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and careful reading of our manuscript. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Experiments] The central claim that the adjoint neural operator produces gradients reliable enough for the conditional consistency model sampling rests on unverified surrogate accuracy. No quantitative comparison (e.g., operator-norm or pointwise error between the learned adjoint and a reference Helmholtz adjoint) or ablation isolating surrogate-induced gradient bias from other error sources is reported, even though the inverse problem is known to be sensitive to such bias under sparse-view conditions.
Authors: We agree that a direct quantitative validation of the adjoint neural operator surrogate is important to substantiate the reliability of the gradients. The current experiments focus on end-to-end reconstruction quality rather than isolated surrogate metrics. In the revised manuscript we will add a dedicated subsection reporting operator-norm errors, relative L2 errors, and pointwise differences between the learned adjoint and the reference Helmholtz adjoint on held-out data. We will also include an ablation comparing reconstructions obtained with the neural-operator surrogate versus exact adjoints (where feasible) to isolate any gradient bias, with particular attention to sparse-view regimes. revision: yes
-
Referee: [Methods] The manuscript positions adjoint operator learning as simultaneously fixing PDE-constrained gradients and discretization errors, yet provides no error bounds, consistency metrics, or convergence analysis for the neural operator approximation when composed with the consistency-model sampling trajectory. This leaves open whether discretization errors are reduced or merely replaced by approximation errors that could accumulate in the ill-posed regime.
Authors: We acknowledge the absence of formal error bounds and convergence analysis for the composed operator. The manuscript prioritizes empirical demonstration of efficiency and quality gains. In the revision we will augment the methods and experiments sections with consistency metrics, including adjoint residual norms and empirical tracking of approximation error along sampling trajectories. We will also clarify how the batch-based Convergent Born Series reduces training-data discretization mismatch. A complete theoretical convergence analysis of the neural-operator approximation inside the consistency-model trajectory is a substantial undertaking that lies beyond the scope of the present work. revision: partial
- Rigorous theoretical error bounds and convergence analysis for the neural operator approximation composed with the consistency-model sampling trajectory.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents Diff-ANO as a framework combining conditional consistency models for measurement-conditional sampling and adjoint neural operator learning to replace PDE solvers for gradient computation, with BCBS introduced for generating training pairs. These are described as independent technical innovations addressing specific challenges in USCT inverse problems. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or summary text. The central claims rest on experimental demonstrations of efficiency and quality improvements rather than any derivation that reduces to its own inputs by construction. The derivation chain is self-contained against external benchmarks and does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural operator surrogates accurately approximate the adjoint of the forward Helmholtz operator for gradient computation.
Forward citations
Cited by 1 Pith paper
-
Harnessing AI for Inverse Partial Differential Equation Problems: Past, Present, and Prospects
A survey organizing AI methods for inverse PDE problems into inverse problems, inverse design, and control categories, covering applications and future challenges like physics-informed models and uncertainty quantification.
Reference graph
Works this paper leans on
-
[1]
S. R. Arridge and J. C. Schotland. Optical tomography: forward and inverse problems. Inverse Problems, 25(12):123010, 2009
work page 2009
-
[2]
Inverse Acoustic and Electromagnetic Scattering Theory
David Colton and Rainer Kress. Inverse Acoustic and Electromagnetic Scattering Theory. Springer, 2013
work page 2013
-
[4]
Gauss–newton and full newton methods in frequency–space seismic waveform inversion
R Gerhard Pratt, Changsoo Shin, and GJ Hick. Gauss–newton and full newton methods in frequency–space seismic waveform inversion. Geophysical journal international, 133(2):341–362, 1998
work page 1998
-
[5]
Priors in bayesian deep learning: A review
Vincent Fortuin. Priors in bayesian deep learning: A review. arXiv preprint arXiv:2105.06868, 2021
-
[6]
Dongzhuo Li and Jerry M. Harris. Full waveform inversion with nonlocal similarity and model-derivative domain adaptive sparsity-promoting regularization. arXiv preprint arXiv:1803.11391, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Ulugbek S. Kamilov, Charles A. Bouman, Gregery T. Buzzard, and Brendt Wohlberg. Plug-and-play methods for integrating physical and learned models in computational imaging. arXiv preprint arXiv:2203.17061, 2022
-
[8]
Weicheng Yan, Qiude Zhang, Yun Wu, Zhaohui Liu, Liang Zhou, Mingyue Ding, Ming Yuchi, and Wu Qiu. A plug-and-play untrained neural network for full waveform inversion in reconstructing sound speed images of ultrasound computed tomography. arXiv preprint arXiv:2406.08523, 2024
-
[9]
A prior regularized full waveform inversion using generative diffusion models
Fu Wang, Xinquan Huang, and Tariq A Alkhalifah. A prior regularized full waveform inversion using generative diffusion models. IEEE transactions on geoscience and remote sensing, 61:1–11, 2023
work page 2023
-
[10]
Solving inverse problems using data-driven models
Simon Arridge, Peter Maass, Ozan Öktem, and Carola-Bibiane Schönlieb. Solving inverse problems using data-driven models. Acta Numerica, 28:1–174, 2019
work page 2019
-
[11]
Inverse problem theory and methods for model parameter estimation
Albert Tarantola. Inverse problem theory and methods for model parameter estimation. SIAM, 2005
work page 2005
-
[12]
Nonlinear total variation based noise removal algorithms
Leonid I Rudin, Stanley Osher, and Emad Fatemi. Nonlinear total variation based noise removal algorithms. Physica D: Nonlinear Phenomena, 60(1-4):259–268, 1992
work page 1992
-
[13]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[14]
Diffusion models: A comprehensive survey of methods and applications
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications. ACM Computing Surveys, 56(4):1–39, 2023
work page 2023
-
[15]
Hyung Jin Chung, Zizhao Dong, Benjamin Kress, Johannes Kopf, and William T. Freeman. Diffusion posterior sampling for inverse problems. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[16]
Improving diffusion models for inverse problems using manifold constraints
Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints. Advances in Neural Information Processing Systems, 35:25683–25696, 2022
work page 2022
-
[17]
Diffusion posterior sampling for linear inverse problem solving: A filtering perspective
Zehao Dou and Yang Song. Diffusion posterior sampling for linear inverse problem solving: A filtering perspective. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[18]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022
work page 2022
-
[19]
Srdiff: Single image super-resolution with diffusion probabilistic models
Haoying Li, Yifan Yang, Meng Chang, Shiqi Chen, Huajun Feng, Zhihai Xu, Qi Li, and Yueting Chen. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing, 479:47–59, 2022
work page 2022
-
[20]
Solving inverse problems in medical imaging with score-based generative models
Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving inverse problems in medical imaging with score-based generative models. In International Conference on Learning Representations, 2022
work page 2022
-
[21]
Score-based diffusion models for accelerated MRI
Hyungjin Chung and Jong Chul Ye. Score-based diffusion models for accelerated MRI. Medical Image Analysis, page 102479, 2022. 23 Diff-ANO: Conditional CM with Adjoint NO for USCT
work page 2022
-
[22]
Diffphase: Generative diffusion-based stft phase retrieval
Tal Peer, Simon Welker, and Timo Gerkmann. Diffphase: Generative diffusion-based stft phase retrieval. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[23]
Morteza Mardani, Jiaming Song, Jan Kautz, and Arash Vahdat. A variational perspective on solving inverse problems with diffusion models. arXiv preprint arXiv:2305.04391, 2023
-
[24]
Frank Ihlenburg and Ivo Babuška. Finite element solution of the helmholtz equation with high wave number part i: The h-version of the fem. Computers & Mathematics with Applications, 30(9):9–37, 1995
work page 1995
-
[25]
High-order finite difference methods for the helmholtz equation
Ido Singer and Eli Turkel. High-order finite difference methods for the helmholtz equation. Computer methods in applied mechanics and engineering, 163(1-4):343–358, 1998
work page 1998
-
[26]
Subspace diffusion posterior sampling for travel-time tomography
Xiang Cao and Xiaoqun Zhang. Subspace diffusion posterior sampling for travel-time tomography. Inverse Problems, 41(5):055010, 2025
work page 2025
- [27]
-
[28]
Cosign: Few-step guidance of consistency model to solve general inverse problems
Jiankun Zhao, Bowen Song, and Liyue Shen. Cosign: Few-step guidance of consistency model to solve general inverse problems. In European Conference on Computer Vision, pages 108–126. Springer, 2024
work page 2024
-
[29]
An empirical bayes approach to statistics
Herbert E Robbins. An empirical bayes approach to statistics. In Breakthroughs in Statistics: Foundations and basic theory, pages 388–394. Springer, 1992
work page 1992
-
[30]
Stochastic solutions for linear inverse problems using the prior implicit in a denoiser
Zahra Kadkhodaie and Eero Simoncelli. Stochastic solutions for linear inverse problems using the prior implicit in a denoiser. Advances in Neural Information Processing Systems, 34:13242–13254, 2021
work page 2021
-
[31]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. In International Conference on Learning Representations, 2023
work page 2023
-
[32]
Yinhuai Wang, Jiwen Yu, and Jian Zhang. Zero-shot image restoration using denoising diffusion null-space model. arXiv preprint arXiv:2212.00490, 2022
-
[33]
Hyungjin Chung, Suhyeon Lee, and Jong Chul Ye. Decomposed diffusion sampler for accelerating large-scale inverse problems. arXiv preprint arXiv:2303.05754, 2023
-
[34]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In 9th International Conference on Learning Representations, ICLR, 2021
work page 2021
-
[35]
The little engine that could: Regularization by denoising (red)
Yaniv Romano, Michael Elad, and Peyman Milanfar. The little engine that could: Regularization by denoising (red). SIAM Journal on Imaging Sciences, 10(4):1804–1844, 2017
work page 2017
-
[36]
Deblurring via stochastic refinement
Jay Whang, Mauricio Delbracio, Hossein Talebi, Chitwan Saharia, Alexandros G Dimakis, and Peyman Milanfar. Deblurring via stochastic refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16293–16303, 2022
work page 2022
-
[37]
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation. arXiv preprint arXiv:2206.13397, 2022
-
[38]
A Survey on Diffusion Models for Inverse Problems
Giannis Daras, Hyungjin Chung, Chieh-Hsin Lai, Yuki Mitsufuji, Jong Chul Ye, Peyman Milanfar, Alexan- dros G Dimakis, and Mauricio Delbracio. A survey on diffusion models for inverse problems. arXiv preprint arXiv:2410.00083, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models
Fan Bao, Chongxuan Li, Jun Zhu, and Bo Zhang. Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. arXiv preprint arXiv:2201.06503, 2022
-
[40]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. In A. Beygelz- imer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
work page 2021
- [41]
-
[42]
Subspace diffusion generative models
Bowen Jing, Gabriele Corso, Renato Berlinghieri, and Tommi Jaakkola. Subspace diffusion generative models. In European Conference on Computer Vision, pages 274–289. Springer, 2022
work page 2022
-
[43]
Score-based generative modeling in latent space
Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space. Advances in neural information processing systems, 34:11287–11302, 2021
work page 2021
-
[44]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. arXiv preprint arXiv:2303.01469, 2023. 24 Diff-ANO: Conditional CM with Adjoint NO for USCT
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
work page 2023
-
[46]
A mathematical guide to operator learning
Nicolas Boullé and Alex Townsend. A mathematical guide to operator learning. In Handbook of Numerical Analysis, volume 25, pages 83–125. Elsevier, 2024
work page 2024
-
[47]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikesh Kovachki, Kamiar Azizzadenesheli, Bo Liu, Karthik Bhattacharya, Andrew Stuart, and Animashree Anandkumar. Fourier neural operator for parametric partial differential equations. In Proceedings of the 38th International Conference on Machine Learning (ICML) , volume 139, pages 6755–6764, 2021. https://proceedings.mlr.press/v139/li21h.html
work page 2021
-
[48]
Lu Lu, Pengzhan Jin, and George E. Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3:218–229, 2021
work page 2021
-
[49]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015
work page 2015
-
[50]
Mitigating spectral bias for the multiscale operator learning
Xinliang Liu, Bo Xu, Shuhao Cao, and Lei Zhang. Mitigating spectral bias for the multiscale operator learning. Journal of Computational Physics, 506:112944, 2024
work page 2024
-
[51]
Mgnet: A unified framework of multigrid and convolutional neural network
Juncai He and Jinchao Xu. Mgnet: A unified framework of multigrid and convolutional neural network. Science china mathematics, 62:1331–1354, 2019
work page 2019
-
[52]
Mgno: Efficient parameterization of linear operators via multigrid
Juncai He, Xinliang Liu, and Jinchao Xu. Mgno: Efficient parameterization of linear operators via multigrid. arXiv preprint arXiv:2310.19809, 2023
-
[53]
Meta-mgnet: Meta multigrid networks for solving parameterized partial differential equations
Yuyan Chen, Bin Dong, and Jinchao Xu. Meta-mgnet: Meta multigrid networks for solving parameterized partial differential equations. Journal of computational physics, 455:110996, 2022
work page 2022
-
[54]
Neural inverse operators for solving pde inverse problems
Roberto Molinaro, Yunan Yang, Björn Engquist, and Siddhartha Mishra. Neural inverse operators for solving pde inverse problems. arXiv preprint arXiv:2301.11167, 2023
-
[55]
Transformer meets boundary value inverse problems
Ruchi Guo, Shuhao Cao, and Long Chen. Transformer meets boundary value inverse problems. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[56]
Rapid seismic waveform modeling and inversion with neural operators
Yan Yang, Angela F Gao, Kamyar Azizzadenesheli, Robert W Clayton, and Zachary E Ross. Rapid seismic waveform modeling and inversion with neural operators. IEEE Transactions on Geoscience and Remote Sensing, 61:1–12, 2023
work page 2023
-
[57]
Neural born series operator for biomedical ultrasound computed tomography
Zhijun Zeng, Yihang Zheng, Youjia Zheng, Yubing Li, Zuoqiang Shi, and He Sun. Neural born series operator for biomedical ultrasound computed tomography. arXiv preprint arXiv:2312.15575, 2023
-
[58]
Zhijun Zeng, Youjia Zheng, Hao Hu, Zeyuan Dong, Yihang Zheng, Xinliang Liu, Jinzhuo Wang, Zuoqiang Shi, Linfeng Zhang, Yubing Li, et al. Openwaves: A large-scale anatomically realistic ultrasound-ct dataset for benchmarking neural wave equation solvers. 2025
work page 2025
-
[59]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations. In 9th International Conference on Learning Representations, ICLR, 2021
work page 2021
-
[60]
A connection between score matching and denoising autoencoders
Pascal Vincent. A connection between score matching and denoising autoencoders. Neural computation, 23(7):1661–1674, 2011
work page 2011
-
[61]
Improved denoising diffusion probabilistic models
Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. International Conference on Machine Learning, 2021
work page 2021
-
[62]
Herbert E. Robbins. An empirical bayes approach to statistics. In John E. Freund and William C. Stuart, editors, Breakthroughs in Statistics: Foundations and Basic Theory, pages 103–122. Springer, 1992. Originally presented 1956
work page 1992
-
[63]
Elucidating the Design Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Samuli Laine, Joonas Hellsten, Jaakko Lehtinen, and Timo Aila. Elucidating the design space of diffusion-based generative models. arXiv preprint arXiv:2206.00364, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[65]
Juncai He, Xinliang Liu, and Jinchao Xu. Self-composing neural operators with depth and accuracy scaling via adaptive train-and-unroll approach. preprint, 2025
work page 2025
-
[66]
Multi-grid methods and applications, volume 4
Wolfgang Hackbusch. Multi-grid methods and applications, volume 4. Springer Science & Business Media, 2013
work page 2013
-
[67]
Theory of multilevel methods, volume 8924558
Jinchao Xu. Theory of multilevel methods, volume 8924558. Cornell University, 1989. 25 Diff-ANO: Conditional CM with Adjoint NO for USCT
work page 1989
-
[68]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. In The Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[69]
Openpros: A large-scale dataset for limited view prostate ultrasound computed tomography
Hanchen Wang, Yixuan Wu, Yinan Feng, Peng Jin, Shihang Feng, Yiming Mao, James Wiskin, Baris Turkbey, Peter A Pinto, Bradford J Wood, et al. Openpros: A large-scale dataset for limited view prostate ultrasound computed tomography. arXiv preprint arXiv:2505.12261, 2025
-
[70]
Inverse Acoustic and Electromagnetic Scattering Theory, volume 93 of Applied Mathematical Sciences
David Colton and Rainer Kress. Inverse Acoustic and Electromagnetic Scattering Theory, volume 93 of Applied Mathematical Sciences. Springer, 3rd edition, 2013
work page 2013
-
[71]
A convergent born series for solving the inhomogeneous helmholtz equation in arbitrarily large media
Gerwin Osnabrugge, Saroch Leedumrongwatthanakun, and Ivo M Vellekoop. A convergent born series for solving the inhomogeneous helmholtz equation in arbitrarily large media. Journal of computational physics, 322:113–124, 2016
work page 2016
-
[72]
Algorithm 778: L-bfgs-b: Fortran subroutines for large-scale bound-constrained optimization
Ciyou Zhu, Richard H Byrd, Peihuang Lu, and Jorge Nocedal. Algorithm 778: L-bfgs-b: Fortran subroutines for large-scale bound-constrained optimization. ACM Transactions on mathematical software (TOMS), 23(4):550–560, 1997
work page 1997
-
[73]
An introduction to the conjugate gradient method without the agonizing pain
Jonathan Richard Shewchuk et al. An introduction to the conjugate gradient method without the agonizing pain. 1994
work page 1994
-
[74]
Inversionnet3d: Efficient and scalable learning for 3-d full-waveform inversion
Qili Zeng, Shihang Feng, Brendt Wohlberg, and Youzuo Lin. Inversionnet3d: Efficient and scalable learning for 3-d full-waveform inversion. IEEE Transactions on Geoscience and Remote Sensing, 60:1–16, 2021
work page 2021
-
[75]
Plug-and-play priors for model based reconstruction
Singanallur V Venkatakrishnan, Charles A Bouman, and Brendt Wohlberg. Plug-and-play priors for model based reconstruction. In 2013 IEEE global conference on signal and information processing, pages 945–948. IEEE, 2013
work page 2013
-
[76]
Applications of seismic travel-time tomography
R Phillip Bording, Adam Gersztenkorn, Larry R Lines, John A Scales, and Sven Treitel. Applications of seismic travel-time tomography. Geophysical Journal International, 90(2):285–303, 1987. 26
work page 1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.