SenSE: Semantic-Aware High-Fidelity Universal Speech Enhancement
Pith reviewed 2026-05-18 12:32 UTC · model grok-4.3
The pith
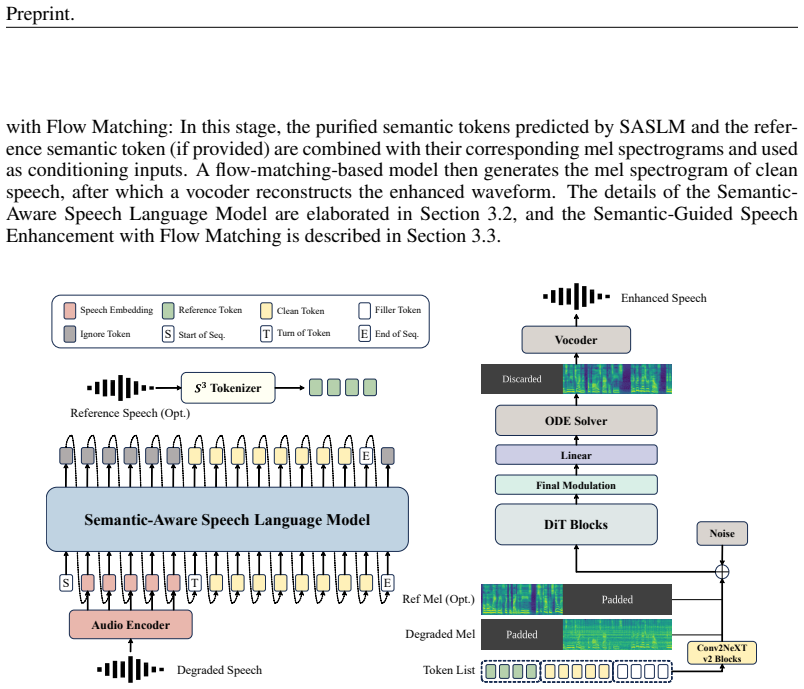
SenSE guides flow matching with semantic tokens from a language model to produce semantically faithful enhanced speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
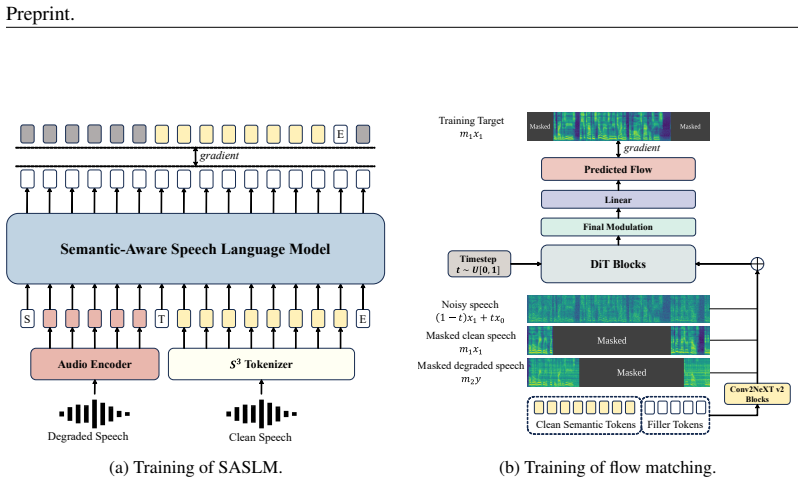
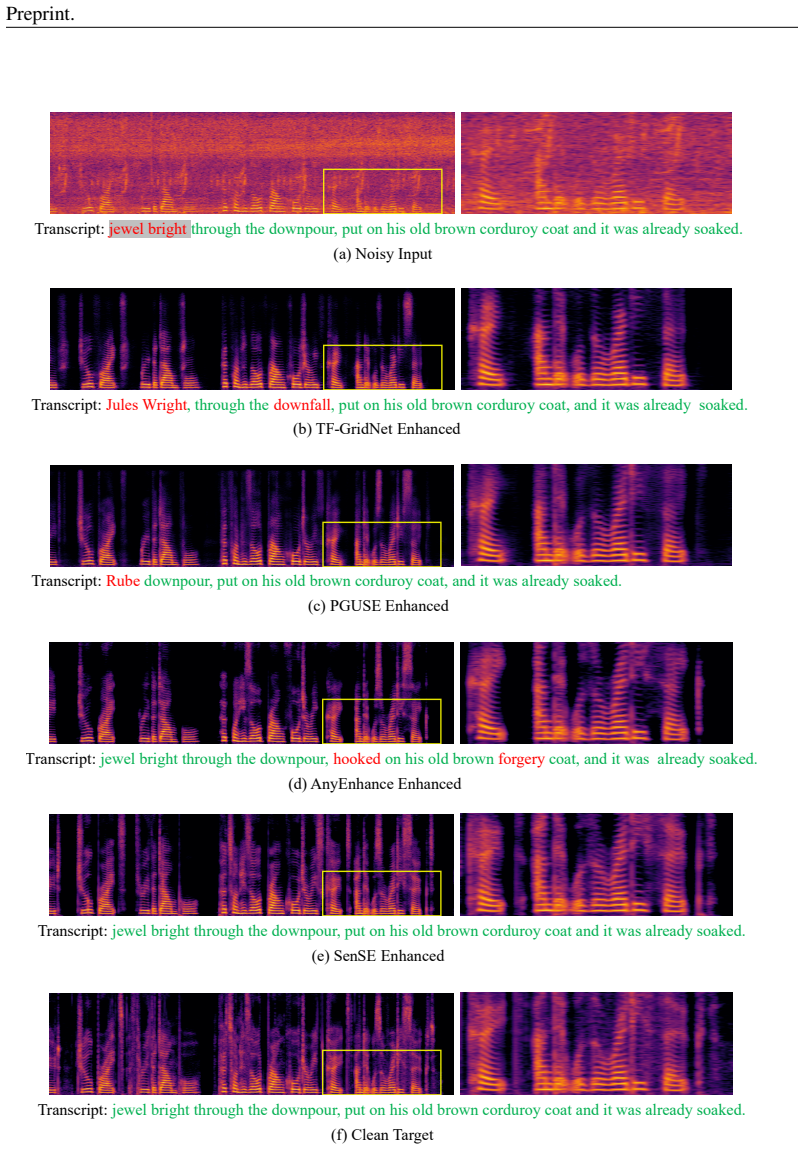
By modeling semantic priors with a language model, the flow matching-based speech enhancement process is guided to generate semantically faithful speech. The dual-path masked conditioning training strategy enables flexible integration of multi-source conditioning signals, improving model flexibility and adaptability.
What carries the argument
Semantic priors modeled by a language model guiding a flow-matching generator, with dual-path masked conditioning for multi-source signals.
If this is right
- Achieves state-of-the-art performance among generative speech enhancement models.
- Exhibits a high performance ceiling particularly under challenging distortion conditions.
- Improves context fidelity in generated speech outputs.
- Enhances adaptability through flexible conditioning integration.
Where Pith is reading between the lines
- This semantic guidance approach might extend to enhancing other audio modalities like music or environmental sounds by preserving semantic or structural consistency.
- If the language model tokens prove robust, future systems could rely less on reference speech and more on semantic understanding for enhancement.
- Combining this with larger context-aware language models could enable enhancement that adapts to conversation topics or speaker intent.
Load-bearing premise
Semantic tokens from an off-the-shelf language model remain reliable guides even when the input speech is heavily distorted.
What would settle it
A test where semantic tokens are extracted from heavily distorted speech and the resulting enhancement is checked for semantic accuracy against the original undistorted meaning.
Figures
read the original abstract
Generative Universal Speech Enhancement (USE) methods aim to leverage generative models to improve speech quality under various types of distortions. However, existing generative speech enhancement methods often suffer from semantic inconsistency in the generated outputs. Therefore, we propose SenSE, a novel two-stage generative universal speech enhancement framework, by modeling semantic priors with a language model, the flow matching-based speech enhancement process is guided to generate semantically faithful speech, thereby effectively improving context fidelity. In addition, we introduce a dual-path masked conditioning training strategy that enables flow matching-based enhancement to flexibly integrate multi-source conditioning signals from degraded speech, semantic tokens, and reference speech, thereby improving model flexibility and adaptability. Experimental results demonstrate that SenSE achieves state-of-the-art performance among generative speech enhancement models and exhibits a high performance ceiling, particularly under challenging distortion conditions. Codes and demos are available at https://github.com/ASLP-lab/SenSE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SenSE, a two-stage generative framework for universal speech enhancement. Semantic tokens are first extracted from the input using an off-the-shelf language model; these tokens then condition a flow-matching enhancement model together with the degraded waveform and optional reference speech. A dual-path masked conditioning training strategy is introduced to allow flexible integration of the multi-source signals. The central claim is that this semantic guidance produces outputs with improved context fidelity and yields state-of-the-art results among generative USE models, especially under challenging distortions. Code and demos are released.
Significance. If the reported gains hold under rigorous verification, the work would usefully demonstrate how external language-model semantics can be injected into flow-matching pipelines to reduce semantic inconsistency, a known limitation of purely acoustic generative enhancers. The dual-path conditioning mechanism adds practical flexibility. Explicit credit is due for the public release of code and listening examples, which supports reproducibility.
major comments (2)
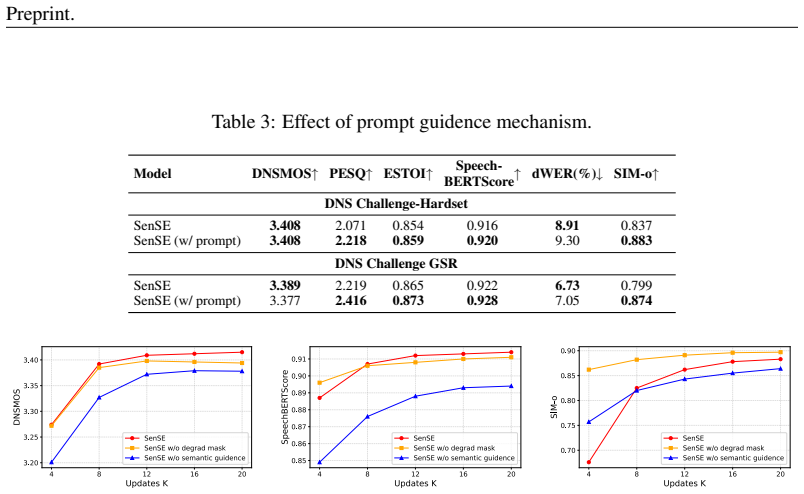
- [§3.2] §3.2 (Semantic Token Extraction and Conditioning): The central claim that semantic tokens provide reliable guidance for the flow-matching stage under heavy distortion rests on an untested precondition. No quantitative measurement (token edit distance, semantic similarity, or alignment rate between tokens extracted from clean versus distorted versions of the same utterance) is reported. Without this, it remains possible that conflicting priors are injected, undermining the asserted semantic-faithfulness advantage.
- [§4] §4 (Experimental Results): The abstract and results section assert SOTA performance among generative USE models and a high performance ceiling, yet the manuscript supplies no tabulated objective metrics (e.g., PESQ, STOI, or perceptual scores), no baseline comparisons with recent flow-matching or diffusion enhancers, and no ablation isolating the contribution of the semantic path. These omissions make the load-bearing performance claim unverifiable from the provided evidence.
minor comments (2)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the key quantitative gains (e.g., average improvement over the strongest baseline) rather than a purely qualitative claim.
- [§3.3] Notation for the dual-path conditioning (e.g., the masking schedule and how semantic tokens are embedded) could be made more explicit in the equations of §3.3 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript to improve clarity and verifiability of our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Semantic Token Extraction and Conditioning): The central claim that semantic tokens provide reliable guidance for the flow-matching stage under heavy distortion rests on an untested precondition. No quantitative measurement (token edit distance, semantic similarity, or alignment rate between tokens extracted from clean versus distorted versions of the same utterance) is reported. Without this, it remains possible that conflicting priors are injected, undermining the asserted semantic-faithfulness advantage.
Authors: We agree that a direct quantitative assessment of semantic token stability under distortion would strengthen the justification for the semantic guidance mechanism. In the revised manuscript we have added this analysis to §3.2, reporting token edit distance, semantic similarity, and alignment rates between tokens extracted from clean and distorted versions of the same utterances. The results indicate that the off-the-shelf language model preserves sufficient semantic fidelity even under heavy distortion, supporting the reliability of the conditioning strategy. revision: yes
-
Referee: [§4] §4 (Experimental Results): The abstract and results section assert SOTA performance among generative USE models and a high performance ceiling, yet the manuscript supplies no tabulated objective metrics (e.g., PESQ, STOI, or perceptual scores), no baseline comparisons with recent flow-matching or diffusion enhancers, and no ablation isolating the contribution of the semantic path. These omissions make the load-bearing performance claim unverifiable from the provided evidence.
Authors: The referee correctly observes that the submitted version lacked explicit tabulated objective metrics and detailed comparisons in the main text. We have revised §4 to include comprehensive tables with PESQ, STOI, and perceptual scores, added direct comparisons against recent flow-matching and diffusion-based universal speech enhancement models, and incorporated an ablation study that isolates the contribution of the semantic conditioning path. These additions render the performance claims verifiable. revision: yes
Circularity Check
No significant circularity; derivation relies on independent external components
full rationale
The SenSE paper describes a two-stage framework that extracts semantic tokens from an off-the-shelf pre-trained language model and uses them to condition a flow-matching enhancement process, together with a dual-path masked conditioning strategy. These elements draw on externally trained models whose parameters and training data are independent of the present work. No equations or methodological steps reduce a claimed prediction or result to a quantity fitted or defined by the authors themselves within this paper. The SOTA performance claims are supported by experimental comparisons rather than by any self-referential derivation or self-citation chain that would force the outcome by construction. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantic tokens extracted by an external language model remain faithful guides even under heavy acoustic distortion.
- domain assumption Flow-matching generative models can be conditioned on mixed signals from degraded speech, semantic tokens, and reference speech without loss of stability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage generative universal speech enhancement framework... semantic-aware speech language model... flow-matching-based speech enhancement... dual-path masked conditioning
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
semantic tokens... purified semantic tokens... semantic guidance mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Reducing Linguistic Hallucination in LM-Based Speech Enhancement via Noise-Invariant Acoustic-Semantic Distillation
L3-SE reduces linguistic hallucination in LM-based speech enhancement by distilling noise-invariant acoustic-semantic representations from noisy inputs to condition an autoregressive decoder-only language model.
-
UniPASE: A Generative Model for Universal Speech Enhancement with High Fidelity and Low Hallucinations
UniPASE extends the PASE framework with DeWavLM-Omni to convert degraded speech into high-fidelity, low-hallucination audio across sampling rates via phonetic enhancement, acoustic adaptation, and multi-rate vocoding.
Reference graph
Works this paper leans on
-
[1]
Keyu An, Qian Chen, Chong Deng, Zhihao Du, Changfeng Gao, Zhifu Gao, Yue Gu, Ting He, Hangrui Hu, Kai Hu, et al. Funaudiollm: V oice understanding and generation foundation models for natural interaction between humans and llms.arXiv preprint arXiv:2407.04051,
-
[2]
Towards efficient models for real-time deep noise suppression
Sebastian Braun, Hannes Gamper, Chandan KA Reddy, and Ivan Tashev. Towards efficient models for real-time deep noise suppression. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 656–660. IEEE,
work page 2021
-
[3]
Towards robust speech representa- tion learning for thousands of languages,
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505– 1518, 2022a. William Chen, Wangyou Zhang, Yifan Peng, Xinjian Li, Jinchuan ...
-
[4]
Large-scale self-supervised speech representation learning for automatic speaker verification
Zhengyang Chen, Sanyuan Chen, Yu Wu, Yao Qian, Chengyi Wang, Shujie Liu, Yanmin Qian, and Michael Zeng. Large-scale self-supervised speech representation learning for automatic speaker verification. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6147–6151. IEEE, 2022b. Ross Cutler, Ando Saabas, Ta...
work page 2022
-
[5]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Yihui Fu, Yun Liu, Jingdong Li, Dawei Luo, Shubo Lv, Yukai Jv, and Lei Xie. Uformer: A unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7417–7421. IEEE,
work page 2022
-
[7]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement
Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li. Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6633–6637. IEEE,
work page 2021
-
[9]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement
Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie. DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement. InInterspeech 2020, pp. 2472–2476,
work page 2020
-
[12]
Jesper Jensen and Cees H Taal. An algorithm for predicting the intelligibility of speech masked by modulated noise maskers.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(11):2009–2022,
work page 2009
-
[13]
Language models as semantic indexers,
Bowen Jin, Hansi Zeng, Guoyin Wang, Xiusi Chen, Tianxin Wei, Ruirui Li, Zhengyang Wang, Zheng Li, Yang Li, Hanqing Lu, et al. Language models as semantic indexers.arXiv preprint arXiv:2310.07815,
-
[14]
doi: 10.18653/v1/2025.acl-long
-
[15]
Flowse: Flow matching-based speech enhancement
Seonggyu Lee, Sein Cheong, Sangwook Han, and Jong Won Shin. Flowse: Flow matching-based speech enhancement. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
work page 2025
-
[16]
Jens Lehmann, Preetam Gattogi, Dhananjay Bhandiwad, S ´ebastien Ferr´e, and Sahar Vahdati. Lan- guage models as controlled natural language semantic parsers for knowledge graph question an- swering. InECAI 2023-26th European Conference on Artificial Intelligence, volume 372, pp. 1348–1356. IOS Press,
work page 2023
-
[17]
Flow Matching for Generative Modeling
Chenda Li, Samuele Cornell, Shinji Watanabe, and Yanmin Qian. Diffusion-based generative mod- eling with discriminative guidance for streamable speech enhancement. In2024 IEEE Spoken Language Technology Workshop (SLT), pp. 333–340. IEEE, 2024a. Hanzhao Li, Liumeng Xue, Haohan Guo, Xinfa Zhu, Yuanjun Lv, Lei Xie, Yunlin Chen, Hao Yin, and Zhifei Li. Single...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21437/interspeech.2024-1559 2024
-
[18]
V oiceFixer: A Unified Framework for High-Fidelity Speech Restoration
Haohe Liu, Xubo Liu, Qiuqiang Kong, Qiao Tian, Yan Zhao, DeLiang Wang, Chuanzeng Huang, and Yuxuan Wang. V oiceFixer: A Unified Framework for High-Fidelity Speech Restoration. In Interspeech 2022, pp. 4232–4236,
work page 2022
-
[19]
Ye-Xin Lu, Yang Ai, and Zhen-Hua Ling
doi:{10.21437/Interspeech.2022-11026}. Ye-Xin Lu, Yang Ai, and Zhen-Hua Ling. Explicit estimation of magnitude and phase spectra in parallel for high-quality speech enhancement.Neural Networks, pp. 107562,
-
[20]
Con- ditional diffusion probabilistic model for speech enhancement
Yen-Ju Lu, Zhong-Qiu Wang, Shinji Watanabe, Alexander Richard, Cheng Yu, and Yu Tsao. Con- ditional diffusion probabilistic model for speech enhancement. InICASSP 2022-2022 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7402–7406. Ieee,
work page 2022
-
[21]
Gabriel Mittag, Babak Naderi, Assmaa Chehadi, and Sebastian M ¨oller. Nisqa: A deep cnn-self- attention model for multidimensional speech quality prediction with crowdsourced datasets. In Interspeech 2021, pp. 2127–2131,
work page 2021
-
[22]
doi: 10.21437/Interspeech.2021-299. Pooneh Mousavi, Gallil Maimon, Adel Moumen, Darius Petermann, Jiatong Shi, Haibin Wu, Haici Yang, Anastasia Kuznetsova, Artem Ploujnikov, Ricard Marxer, et al. Discrete audio tokens: More than a survey!arXiv preprint arXiv:2506.10274,
-
[23]
Chandan KA Reddy, Vishak Gopal, Ross Cutler, Ebrahim Beyrami, Roger Cheng, Harishchandra Dubey, Sergiy Matusevych, Robert Aichner, Ashkan Aazami, Sebastian Braun, et al. The in- terspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results.arXiv preprint arXiv:2005.13981,
-
[24]
Chandan KA Reddy, Vishak Gopal, and Ross Cutler
12 Preprint. Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6493–6497. IEEE,
work page 2021
-
[25]
Gtcrn: A speech enhancement model requiring ultralow computational resources
Xiaobin Rong, Tianchi Sun, Xu Zhang, Yuxiang Hu, Changbao Zhu, and Jing Lu. Gtcrn: A speech enhancement model requiring ultralow computational resources. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 971–975. IEEE,
work page 2024
-
[26]
Takaaki Saeki, Soumi Maiti, Shinnosuke Takamichi, Shinji Watanabe, and Hiroshi Saruwatari. SpeechBERTScore: Reference-Aware Automatic Evaluation of Speech Generation Leveraging NLP Evaluation Metrics. InInterspeech 2024, pp. 4943–4947,
work page 2024
-
[27]
Singing voice graph modeling for singfake detection
doi: 10.21437/Interspeech. 2024-1508. Robin Scheibler, Yusuke Fujita, Yuma Shirahata, and Tatsuya Komatsu. Universal Score-based Speech Enhancement with High Content Preservation. InInterspeech 2024, pp. 1165–1169,
-
[28]
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli
doi: 10.21437/Interspeech.2024-138. Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre-training for speech recognition.arXiv preprint arXiv:1904.05862,
-
[29]
Hendrik Schroter, Alberto N Escalante-B, Tobias Rosenkranz, and Andreas Maier. Deepfilternet: A low complexity speech enhancement framework for full-band audio based on deep filtering. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7407–7411. IEEE,
work page 2022
-
[30]
Hubert Siuzdak. V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis.arXiv preprint arXiv:2306.00814,
-
[31]
Lauratse: Target speaker extraction using auto-regressive decoder-only language models,
Beilong Tang, Bang Zeng, and Ming Li. Lauratse: Target speaker extraction using auto-regressive decoder-only language models.arXiv preprint arXiv:2504.07402,
-
[32]
Heming Wang and DeLiang Wang. Towards robust speech super-resolution.IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, 29:2058–2066,
work page 2058
-
[33]
Tf-gridnet: Making time-frequency domain models great again for monaural speaker separation
Zhong-Qiu Wang, Samuele Cornell, Shukjae Choi, Younglo Lee, Byeong-Yeol Kim, and Shinji Watanabe. Tf-gridnet: Making time-frequency domain models great again for monaural speaker separation. InICASSP 2023-2023 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 1–5. IEEE,
work page 2023
-
[34]
Ziqian Wang, Xinfa Zhu, Zihan Zhang, YuanJun Lv, Ning Jiang, Guoqing Zhao, and Lei Xie
13 Preprint. Ziqian Wang, Xinfa Zhu, Zihan Zhang, YuanJun Lv, Ning Jiang, Guoqing Zhao, and Lei Xie. Selm: Speech enhancement using discrete tokens and language models. InICASSP 2024-2024 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 11561–11565. IEEE,
work page 2024
-
[35]
FlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching
Ziqian Wang, Zikai Liu, Xinfa Zhu, Yike Zhu, Mingshuai Liu, Jun Chen, Longshuai Xiao, Chao Weng, and Lei Xie. FlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching. InInterspeech 2025, pp. 4858–4862, 2025a. doi: 10.21437/Interspeech.2025-1745. Ziqian Wang, Zikai Liu, Yike Zhu, Xingchen Li, Boyi Kang, Jixun Yao, Xianjun Xia, Chuanzeng Hua...
-
[36]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, et al. Codec does matter: Exploring the semantic shortcoming of codec for audio language model. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 25697–25705, 2025a. Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng W...
-
[37]
It is especially effective for assessing speech in conditions with temporally modulated noise or time-frequency processing, and is intended for normal-hearing listeners. B.4 COMPARISON OFSPEECHTOKENIZERS In our experiments, we adoptS 3 Tokenizer v1 50hz as the speech tokenizer. CosyV oice provides three different versions of the tokenizer, namelyS 3 Token...
-
[38]
and V ocos (Siuzdak, 2023), both of which are tested using their publicly available 24 kHz pretrained weights. As shown in Tab. 7, the experimental results demonstrate that using BigVGAN as the vocoder yields overall better performance compared with V ocos, with the only exception being a slightly lower score on the dWER metric. B.7 ANALYSIS OFINFERENCE-T...
work page 2023
-
[39]
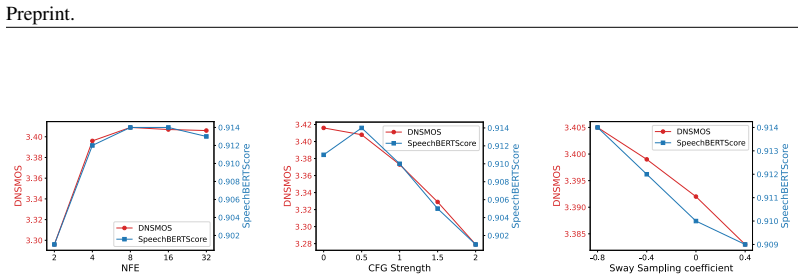
Sway Sampling: This strategy substantially im- proves enhancement outcomes, indicating that allocating more inference steps to the early phase of the process benefits the model and leads to better results. 18 Preprint. Figure 4: Analysis of the three inference-time parameters: NFE, CFG strength, and the sway sam- pling coefficient. Table 8: PESQ/ESTOI on ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.