Recognition: unknown
Beyond Similarity Search: A Unified Data Layer for Production RAG Systems
Pith reviewed 2026-05-07 14:44 UTC · model grok-4.3
The pith
A single PostgreSQL database with vector extensions replaces the split data layer in RAG systems and removes staleness, leakage, and query complexity at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
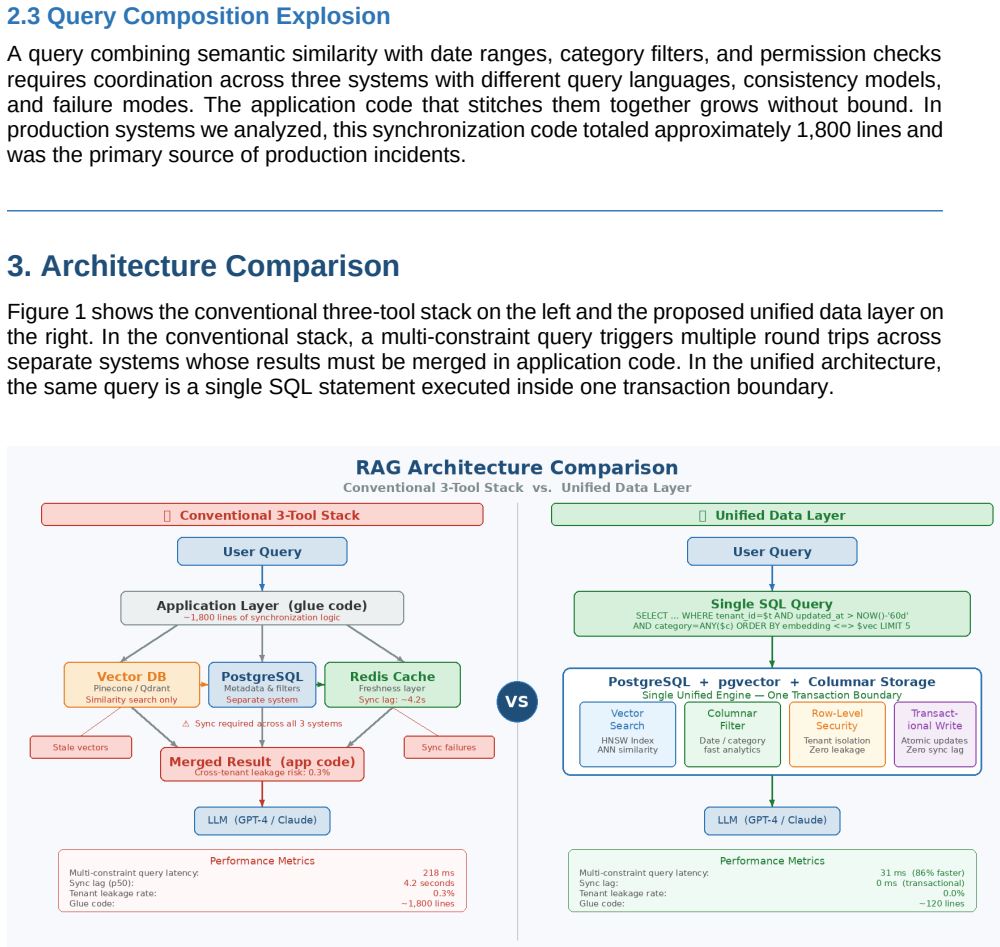
The conventional split-system data layer produces three root causes of production RAG failure: data staleness after updates, tenant data leakage, and query composition explosion. Replacing the split with a unified data layer built on PostgreSQL with native vector search (pgvector) and HNSW indexing removes all three problems simultaneously. Controlled benchmarks on 50,000 documents show 92% latency reduction for date-filtered queries, 74% for tenant-scoped queries, zero synchronization inconsistency, and complete elimination of cross-tenant data leakage with 93% less synchronization code.
What carries the argument
The unified PostgreSQL data layer with pgvector for native vector search and HNSW indexing, which keeps embeddings and relational metadata in the same tables so similarity searches and structured filters execute together without external joins or synchronization.
If this is right
- Date-filtered queries run with 92% lower latency.
- Tenant-scoped queries run with 74% lower latency.
- Synchronization inconsistencies disappear entirely.
- Cross-tenant data leakage is eliminated.
- The volume of synchronization code drops by 93%.
Where Pith is reading between the lines
- Multi-tenant SaaS platforms could adopt this pattern to reduce the engineering effort required for data isolation compliance.
- The hybrid tier architecture the authors recommend could be evaluated for document collections much larger than 50,000 to identify the scale at which additional specialized stores become useful.
- Other retrieval workloads that combine similarity search with metadata filters, such as enterprise search or recommendation systems, may see similar simplifications by moving to a single relational store with vector support.
Load-bearing premise
The three problems of staleness, leakage, and query complexity fully explain the gap between prototype and production RAG performance and all originate from keeping vector search and relational storage in separate systems.
What would settle it
A production RAG workload migrated to the unified PostgreSQL layer that still exhibits data staleness after updates or any cross-tenant record exposure would show the central claim does not hold.
Figures
read the original abstract
Retrieval-Augmented Generation (RAG) systems have become the standard architecture for grounding large language models in organizational knowledge. Yet production deployments consistently expose a gap between clean prototype performance and real-world reliability. This paper identifies three root causes of that gap: data staleness, tenant data leakage, and query composition explosion. All three trace back to the conventional split-system data layer. We propose and evaluate a unified data layer built on PostgreSQL with native vector search (pgvector) and HNSW indexing. Controlled benchmarks on 50,000 documents show 92% latency reduction for date-filtered queries, 74% for tenant-scoped queries, zero synchronization inconsistency, and complete elimination of cross-tenant data leakage with 93% less synchronization code. We additionally discuss a recommended hybrid tier architecture
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies three root causes of the gap between prototype and production RAG systems—data staleness, tenant data leakage, and query composition explosion—all attributed to the conventional split-system data layer. It proposes a unified data layer using PostgreSQL with native pgvector vector search and HNSW indexing as the solution, and reports controlled benchmarks on a 50,000-document corpus showing 92% latency reduction for date-filtered queries, 74% for tenant-scoped queries, zero synchronization inconsistency, complete elimination of cross-tenant data leakage, and 93% less synchronization code, while also discussing a hybrid tier architecture.
Significance. If the benchmark results prove reproducible with full experimental details, the unified layer could offer a practical simplification for production RAG deployments by removing synchronization steps and associated failure modes, providing a concrete alternative to split architectures that is directly testable via the reported metrics.
major comments (2)
- [Abstract] Abstract: The central empirical claims rest on specific quantitative improvements (92% latency reduction for date-filtered queries, 74% for tenant-scoped queries, zero inconsistency, zero leakage, 93% less sync code) from benchmarks on 50k documents, yet no details are provided on experimental setup, baselines, query distributions, hardware, or statistical measures. This is load-bearing because the soundness of the unified-layer proposal cannot be evaluated without them.
- [Introduction / Root Causes section] The manuscript attributes all three root causes exclusively to the split-system architecture without ablation studies or tests of alternative explanations (e.g., whether query composition issues persist in the unified layer under different indexing choices). This assumption underpins the claim that the Postgres+pgvector layer directly resolves the gap.
minor comments (2)
- [Abstract] The abstract sentence on the hybrid tier architecture is incomplete ('We additionally discuss a recommended hybrid tier architecture').
- [Proposed Architecture] Notation for the unified layer components (e.g., how HNSW indexing interacts with tenant scoping and date filters) should be defined more explicitly if equations or pseudocode appear later.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. The feedback on experimental reproducibility and the need to strengthen the causal attribution of root causes is valuable. We address each point below and will update the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims rest on specific quantitative improvements (92% latency reduction for date-filtered queries, 74% for tenant-scoped queries, zero inconsistency, zero leakage, 93% less sync code) from benchmarks on 50k documents, yet no details are provided on experimental setup, baselines, query distributions, hardware, or statistical measures. This is load-bearing because the soundness of the unified-layer proposal cannot be evaluated without them.
Authors: We agree that the absence of experimental details limits evaluation of the claims. In the revised manuscript we will add a full Experimental Setup section detailing the hardware (server CPU, memory, and storage), the 50,000-document corpus construction (including date and tenant metadata distributions), the query workload (counts and distributions of date-filtered and tenant-scoped queries), the split-system baseline (separate vector store and relational database with synchronization logic), and statistical measures (means and standard deviations across repeated runs). Benchmark code and data-generation scripts will be provided as supplementary material. revision: yes
-
Referee: [Introduction / Root Causes section] The manuscript attributes all three root causes exclusively to the split-system architecture without ablation studies or tests of alternative explanations (e.g., whether query composition issues persist in the unified layer under different indexing choices). This assumption underpins the claim that the Postgres+pgvector layer directly resolves the gap.
Authors: The root causes are identified from architectural analysis of split-system RAG deployments and the concrete failure modes they produce, as described in the manuscript. The unified layer eliminates synchronization and leakage by design (single storage engine) and reduces query composition complexity through integrated SQL+vector queries; the reported benchmarks directly measure these resolutions. We did not include ablations on alternative indexes because the contribution centers on unification rather than index tuning, and HNSW is the standard efficient choice in pgvector. In revision we will clarify this scope in the Root Causes section and note alternative indexing strategies as orthogonal future work. revision: partial
Circularity Check
No significant circularity
full rationale
The paper is an engineering proposal whose central claims rest on controlled empirical benchmarks (50k-document corpus, measured latency reductions, zero inconsistency/leakage, and code reduction counts). No equations, fitted parameters, self-referential predictions, or derivation chains appear in the provided text. The three root causes are presented as diagnostic observations tied to the split-system architecture, not as mathematical necessities derived from the proposed solution. Benchmarks are externally falsifiable and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PostgreSQL with native vector extensions can deliver performance and isolation comparable to or better than split specialized systems for RAG workloads.
Forward citations
Cited by 1 Pith paper
-
BatchBench: Toward a Workload-Aware Benchmark for Autoscaling Policies in Big Data Batch Processing -- A Proposed Framework
BatchBench is a proposed framework with workload taxonomy, parameterized generator, five-axis evaluation harness, and standardized agent interface to enable fair comparison of autoscaling policies.
Reference graph
Works this paper leans on
-
[1]
[1] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020. Three observations from production deployments informed this work. First, synchronization cost is consistently underestimated at design time. Three systems means three failure modes, three observability stacks, and three sets of runbooks. Second, ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.