Randomized conjugate gradient least squares
Pith reviewed 2026-06-29 23:47 UTC · model grok-4.3
The pith
RCGLS converges linearly in expectation with a better bound than randomized coordinate descent for least squares
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By viewing the next descent direction in CGLS as the solution of a constraint correction problem associated with the gradient, the full gradient can be replaced by a randomized coordinate gradient that satisfies the variance reduction property. This replacement produces RCGLS, which is shown to converge linearly in expectation with a better convergence bound than the randomized coordinate descent method.
What carries the argument
The constraint correction formulation of the descent direction in CGLS, which allows direct substitution of the gradient by a randomized coordinate gradient while retaining the linear convergence property.
If this is right
- RCGLS admits an implementation that avoids full-dimensional vector operations and is therefore practical for sparse matrices.
- The same construction yields a lightweight parallelizable solver for ridge regression.
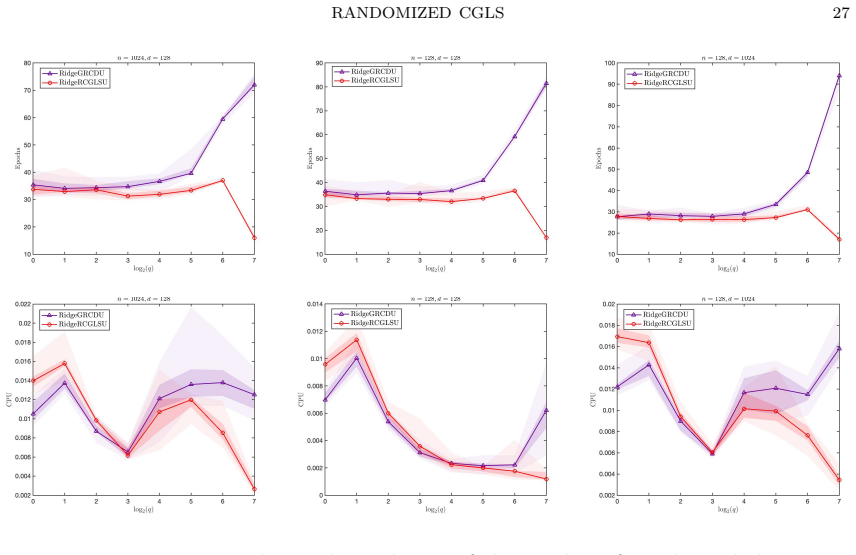
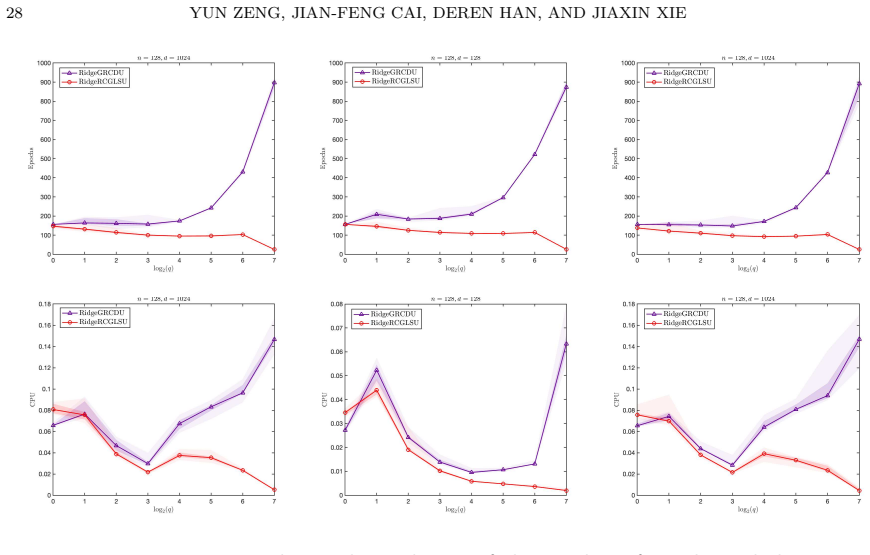
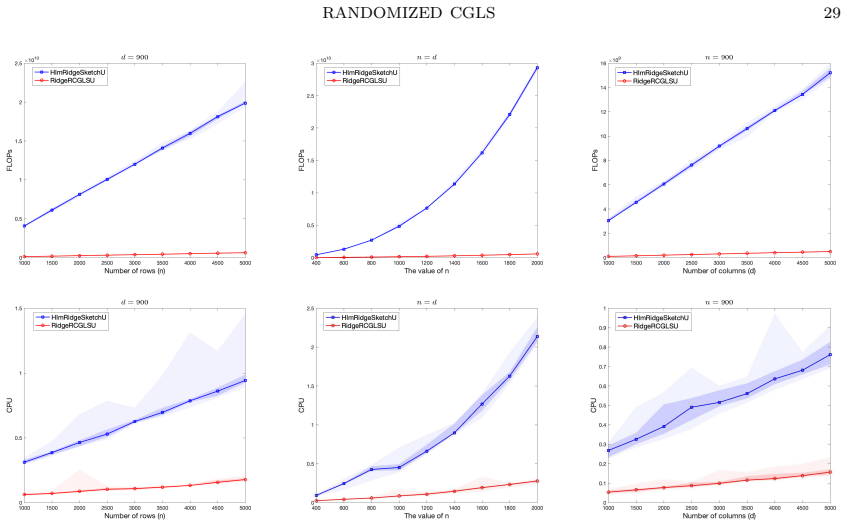
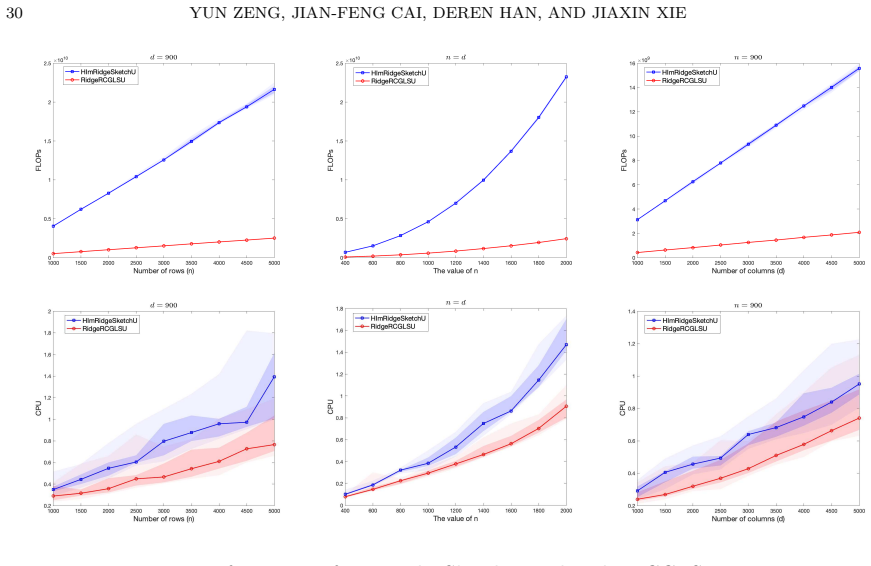
- Numerical experiments confirm the linear expected convergence and the improved bound relative to coordinate descent.
- Iterative sketching at each step reduces the working dimension while preserving the convergence guarantee.
Where Pith is reading between the lines
- The constraint-correction perspective on descent directions may allow similar randomizations inside other Krylov subspace methods.
- Hybrid sampling strategies that mix coordinate gradients with other estimators could be tested for further acceleration on very large systems.
- The variance-reduction property exploited here might extend to randomized estimators in related first-order optimization settings.
Load-bearing premise
The randomized coordinate gradient must satisfy the variance reduction property so it can replace the full gradient inside the constraint correction problem.
What would settle it
A counter-example least-squares problem where the expected convergence rate of RCGLS is no better than that of randomized coordinate descent would falsify the main claim.
Figures
read the original abstract
We develop a novel randomized conjugate gradient least squares (RCGLS) method for solving least-squares problems, in which iterative sketching is employed at each step to reduce the dimension and hence the computational cost. In particular, we propose a new perspective on the classical CGLS method, where the next descent direction is determined via a constraint correction problem associated with the gradient. Based on this insight, we replace the gradient with a randomized coordinate gradient that naturally satisfies the variance reduction property, leading directly to the proposed RCGLS method. We prove that RCGLS converges linearly in expectation, with a better convergence bound compared to the randomized coordinate descent method. Furthermore, we investigate an implementation of the method that avoids full-dimensional vector operations, which are the major bottleneck of vanilla RCGLS for sparse matrices and render it impractical. We also show how to apply the RCGLS method to solve the ridge regression problem, yielding a lightweight, parallelizable, and accelerated method for such problems. Numerical experiments are provided to confirm our results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the randomized conjugate gradient least squares (RCGLS) method for least-squares problems. It derives the method from a new constraint-correction perspective on classical CGLS, replaces the full gradient with a randomized coordinate gradient that satisfies a variance-reduction property, proves linear convergence in expectation with a bound superior to that of randomized coordinate descent, develops an implementation avoiding full-dimensional operations for sparse matrices, extends the approach to ridge regression, and validates the results with numerical experiments.
Significance. If the claimed linear convergence result and improved bound hold under the stated assumptions, RCGLS would supply a theoretically stronger and practically implementable randomized solver for large-scale least squares and ridge regression, with potential advantages over coordinate-descent baselines in both rate and per-iteration cost for sparse data.
major comments (1)
- [Abstract] Abstract: the central claim of a linear convergence proof in expectation together with a strictly better bound than randomized coordinate descent is asserted without any visible derivation, theorem statement, assumption list, or error analysis; this absence prevents verification of the substitution step that replaces the gradient in the constraint-correction formulation.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting the need for clearer linkage between the abstract claims and the supporting analysis. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a linear convergence proof in expectation together with a strictly better bound than randomized coordinate descent is asserted without any visible derivation, theorem statement, assumption list, or error analysis; this absence prevents verification of the substitution step that replaces the gradient in the constraint-correction formulation.
Authors: The abstract is written as a concise summary of contributions and is not intended to contain full derivations or theorem statements, which is standard practice to respect length constraints. The constraint-correction view of CGLS, the substitution of the full gradient by a randomized coordinate gradient that satisfies the variance-reduction property, the complete theorem statement on linear convergence in expectation, the list of assumptions on the sketching matrices, the error analysis, and the explicit comparison showing a strictly better rate than randomized coordinate descent are all derived and proved in Section 3 (see in particular the statement and proof of Theorem 3.1 together with the surrounding discussion of the substitution step). We are happy to add a brief parenthetical reference in the abstract to the main theorem if the referee believes this would improve readability. revision: partial
Circularity Check
No significant circularity; derivation self-contained via stated substitution insight
full rationale
The paper derives RCGLS by viewing CGLS through a constraint-correction lens on the gradient, then substituting a randomized coordinate gradient (asserted to satisfy variance reduction by construction of the randomization). The linear convergence proof in expectation is claimed to follow directly from this replacement and yields a bound superior to RCD. No equations reduce a prediction to a fitted parameter by definition, no load-bearing self-citation chain is invoked to justify uniqueness or an ansatz, and the central claim does not rename a known result. The provided text and reader's assessment indicate an independent proof step rather than tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The randomized coordinate gradient naturally satisfies the variance reduction property
Forward citations
Cited by 1 Pith paper
-
On subspace-constrained preconditioning for randomized iterative methods
Refines subspace preconditioning for randomized linear solvers via QR-like factorization, enabling implicit use and proving expected linear convergence while reducing to a smaller system with good singular values.
Reference graph
Works this paper leans on
-
[1]
Using ridge regression with genetic algorithm to enhance real estate appraisal forecasting
Jae Joon Ahn, Hyun Woo Byun, Kyong Joo Oh, and Tae Yoon Kim. Using ridge regression with genetic algorithm to enhance real estate appraisal forecasting. Expert Syst. Appl. , 39(9):8369–8379, 2012
2012
-
[2]
On partially randomized e xtended Kaczmarz method for solving large sparse overdetermined inconsistent linear systems
Zhong-Zhi Bai and Wen-Ting Wu. On partially randomized e xtended Kaczmarz method for solving large sparse overdetermined inconsistent linear systems. Linear Algebra Appl. , 578:225–250, 2019
2019
-
[3]
On greedy randomized augm ented Kaczmarz method for solving large sparse inconsistent linear systems
Zhong-Zhi Bai and Wen-Ting Wu. On greedy randomized augm ented Kaczmarz method for solving large sparse inconsistent linear systems. SIAM J. Sci. Comput. , 43(6):A3892–A3911, 2021
2021
-
[4]
SIAM, 2024
˚ Ake Bj¨ orck.Numerical methods for least squares problems . SIAM, 2024
2024
-
[5]
LIBSVM: a library for support vector machines
Chih-Chung Chang and Chih-Jen Lin. LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. , 2(3):1–27, 2011
2011
-
[6]
Tight upper bounds for the convergence of the rand omized extended Kaczmarz and Gauss- Seidel algorithms
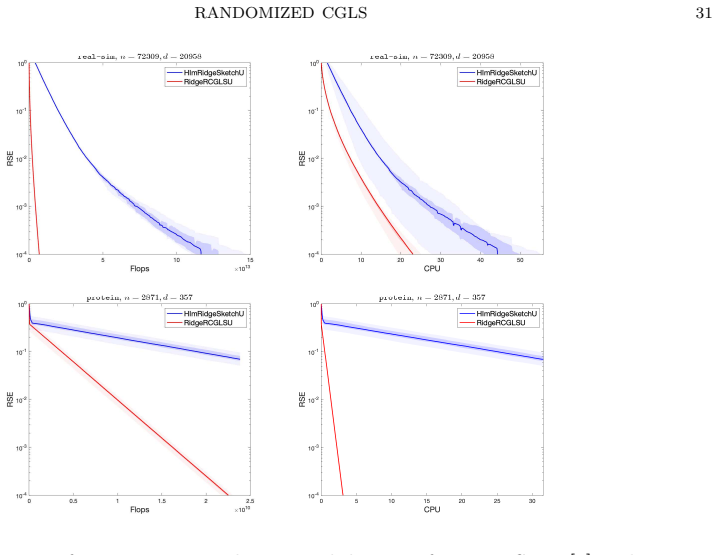
Kui Du. Tight upper bounds for the convergence of the rand omized extended Kaczmarz and Gauss- Seidel algorithms. Numer. Linear Algebra Appl. , 26(3):e2233, 2019. RANDOMIZED CGLS 31 Figure 5. Performance on overdetermined datasets from LIBSVM [ 5] with λ = 0. 05. Figures depict the evolution of RSE with respect to the to tal flops and the CPU time. We set ...
2019
-
[7]
Randomized extended average block Kaczmarz for solving least squares
Kui Du, Wu-Tao Si, and Xiao-Hui Sun. Randomized extended average block Kaczmarz for solving least squares. SIAM J. Sci. Comput. , 42(6):A3541–A3559, 2020
2020
-
[8]
Accelerated, para llel, and proximal coordinate descent
Olivier Fercoq and Peter Richt´ arik. Accelerated, para llel, and proximal coordinate descent. SIAM J. Optim., 25(4):1997–2023, 2015
1997
-
[9]
LSMR: An iter ative algorithm for sparse least-squares problems
David Chin-Lung Fong and Michael Saunders. LSMR: An iter ative algorithm for sparse least-squares problems. SIAM J. Sci. Comput. , 33(5):2950–2971, 2011
2011
-
[10]
Handbook of conv ergence theorems for (stochastic) gradient methods
Guillaume Garrigos and Robert M Gower. Handbook of conv ergence theorems for (stochastic) gradient methods. arXiv preprint arXiv:2301.11235 , 2023
-
[11]
Ri dgeSketch: a fast sketching based solver for large scale ridge regression
Nidham Gazagnadou, Mark Ibrahim, and Robert M Gower. Ri dgeSketch: a fast sketching based solver for large scale ridge regression. SIAM J. Matrix Anal. Appl. , 43(3):1440–1468, 2022
2022
-
[12]
Matrix computations
Gene H Golub and Charles F Van Loan. Matrix computations. JHU press, 2013
2013
-
[13]
Alge braic reconstruction techniques (ART) for three-dimensional electron microscopy and X-ray photogra phy
Richard Gordon, Robert Bender, and Gabor T Herman. Alge braic reconstruction techniques (ART) for three-dimensional electron microscopy and X-ray photogra phy. J. Theor. Biol. , 29(3):471–481, 1970
1970
-
[14]
Gower and Peter Richt´ arik
Robert M. Gower and Peter Richt´ arik. Randomized itera tive methods for linear systems. SIAM J. Matrix Anal. Appl. , 36(4):1660–1690, 2015
2015
-
[15]
Variance-reduced methods for machine learning
Robert M Gower, Mark Schmidt, Francis Bach, and Peter Ri cht´ arik. Variance-reduced methods for machine learning. Proc. IEEE, 108(11):1968–1983, 2020
1968
-
[16]
Randomized Doug las–Rachford methods for linear systems: Improved accuracy and efficiency
Deren Han, Yansheng Su, and Jiaxin Xie. Randomized Doug las–Rachford methods for linear systems: Improved accuracy and efficiency. SIAM J. Optim. , 34(1):1045–1070, 2024
2024
-
[17]
On pseudoinverse-free random ized methods for linear systems: Unified framework and acceleration
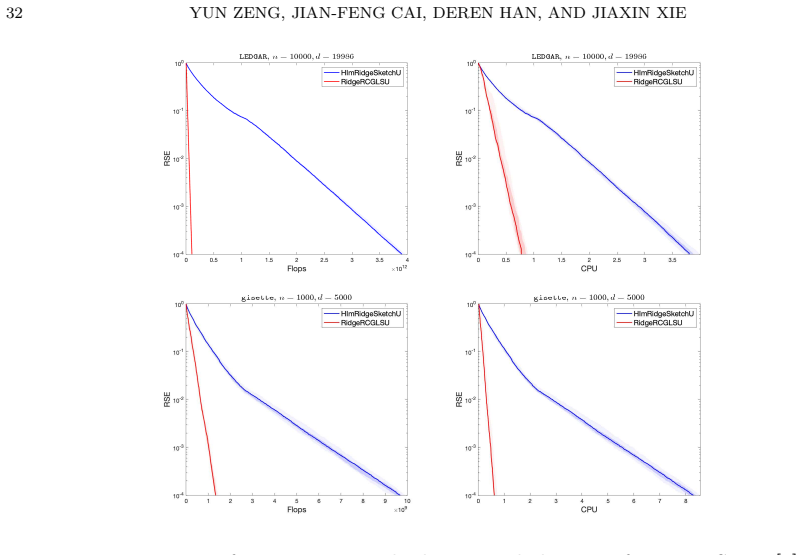
Deren Han and Jiaxin Xie. On pseudoinverse-free random ized methods for linear systems: Unified framework and acceleration. Optim. Methods Softw. , 41(1):82–117, 2026. 32 YUN ZENG, JIAN-FENG CAI, DEREN HAN, AND JIAXIN XIE Figure 6. Performance on underdetermined datasets from LIBSVM [ 5] with λ = 0 . 05. Figures depict the evolution of RSE with respect to ...
2026
-
[18]
Regularization tools: A Matlab p ackage for analysis and solution of discrete ill-posed problems
Per Christian Hansen. Regularization tools: A Matlab p ackage for analysis and solution of discrete ill-posed problems. Numer. Algorithms , 6(1):1–35, 1994
1994
-
[19]
Rows v ersus columns: Randomized Kaczmarz or Gauss-Seidel for ridge regression
Ahmed Hefny, Deanna Needell, and Aaditya Ramdas. Rows v ersus columns: Randomized Kaczmarz or Gauss-Seidel for ridge regression. SIAM J. Sci. Comput. , 39(5):S528–S542, 2017
2017
-
[20]
Algebraic reconstr uction techniques can be made computation- ally efficient (positron emission tomography application)
Gabor T Herman and Lorraine B Meyer. Algebraic reconstr uction techniques can be made computation- ally efficient (positron emission tomography application). IEEE Trans. Med. Imaging , 12(3):600–609, 1993
1993
-
[21]
Methods of con jugate gradients for solving linear systems
Magnus R Hestenes, Eduard Stiefel, et al. Methods of con jugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. , 49(6):409–436, 1952
1952
-
[22]
Kaczmarz algorithm for Tikhonov regularization problem
Andrey Aleksandrovich Ivanov and Aleksandr Ivanovich Zhdanov. Kaczmarz algorithm for Tikhonov regularization problem. Appl. Math. E-Notes , 13:270–276, 2013
2013
-
[23]
Efficient accelerated coor dinate descent methods and faster algorithms for solving linear systems
Yin Tat Lee and Aaron Sidford. Efficient accelerated coor dinate descent methods and faster algorithms for solving linear systems. In Proc. 54th Annu. IEEE Symp. Found. Comput. Sci. (FOCS) , pages 147–
-
[24]
Randomized method s for linear constraints: convergence rates and conditioning
Dennis Leventhal and Adrian S Lewis. Randomized method s for linear constraints: convergence rates and conditioning. Math. Oper. Res. , 35(3):641–654, 2010
2010
-
[25]
An accelerated ra ndomized proximal coordinate gradient method and its application to regularized empirical risk mi nimization
Qihang Lin, Zhaosong Lu, and Lin Xiao. An accelerated ra ndomized proximal coordinate gradient method and its application to regularized empirical risk mi nimization. SIAM J. Optim. , 25(4):2244– 2273, 2015
2015
-
[26]
An accelerated randomized Ka czmarz algorithm
Ji Liu and Stephen Wright. An accelerated randomized Ka czmarz algorithm. Math. Comp., 85(297):153– 178, 2016. RANDOMIZED CGLS 33
2016
-
[27]
Momentum and stoc hastic momentum for stochastic gradient, newton, proximal point and subspace descent methods
Nicolas Loizou and Peter Richt´ arik. Momentum and stoc hastic momentum for stochastic gradient, newton, proximal point and subspace descent methods. Comput. Optim. Appl. , 77(3):653–710, 2020
2020
-
[28]
Minimal error mom entum Bregman-Kaczmarz
Dirk A Lorenz and Maximilian Winkler. Minimal error mom entum Bregman-Kaczmarz. Linear Algebra Appl., 2025
2025
-
[29]
Convergen ce properties of the randomized extended Gauss–Seidel and Kaczmarz methods
Anna Ma, Deanna Needell, and Aaditya Ramdas. Convergen ce properties of the randomized extended Gauss–Seidel and Kaczmarz methods. SIAM J. Matrix Anal. Appl. , 36(4):1590–1604, 2015
2015
-
[30]
Faster randomized block Kaczmarz algorit hms
Ion Necoara. Faster randomized block Kaczmarz algorit hms. SIAM J. Matrix Anal. Appl. , 40(4):1425– 1452, 2019
2019
-
[31]
Randomized sketch desc ent methods for non-separable linearly con- strained optimization
Ion Necoara and Martin Tak´ aˇ c. Randomized sketch desc ent methods for non-separable linearly con- strained optimization. IMA J. Numer. Anal. , 41(2):1056–1092, 2021
2021
-
[32]
Randomized Kaczmarz solver for noisy l inear systems
Deanna Needell. Randomized Kaczmarz solver for noisy l inear systems. BIT, 50(2):395–403, 2010
2010
-
[33]
Paved with good intenti ons: analysis of a randomized block Kaczmarz method
Deanna Needell and Joel A Tropp. Paved with good intenti ons: analysis of a randomized block Kaczmarz method. Linear Algebra Appl. , 441:199–221, 2014
2014
-
[34]
Efficiency of coordinate descent methods on huge-scale optimization problems
Yu Nesterov. Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM J. Optim., 22(2):341–362, 2012
2012
-
[35]
Introductory lectures on convex optimization: A basic cour se, volume 87
Yurii Nesterov. Introductory lectures on convex optimization: A basic cour se, volume 87. Springer Sci- ence & Business Media, 2003
2003
-
[36]
A method for solving the convex progra mming problem with convergence rate O(1 /k2)
Yurii E Nesterov. A method for solving the convex progra mming problem with convergence rate O(1 /k2). In Dokl. akad. nauk Sssr , volume 269, pages 543–547, 1983
1983
-
[37]
M-IH S: An accelerated randomized precondition- ing method avoiding costly matrix decompositions
Ibrahim K Ozaslan, Mert Pilanci, and Orhan Arikan. M-IH S: An accelerated randomized precondition- ing method avoiding costly matrix decompositions. Linear Algebra Appl. , 678:57–91, 2023
2023
-
[38]
LSQR: An alg orithm for sparse linear equations and sparse least squares
Christopher C Paige and Michael A Saunders. LSQR: An alg orithm for sparse linear equations and sparse least squares. ACM Trans. Math. Softw. , 8(1):43–71, 1982
1982
-
[39]
Some methods of speeding up the converge nce of iteration methods
Boris T Polyak. Some methods of speeding up the converge nce of iteration methods. Comput. Math. Math. Phys. , 4(5):1–17, 1964
1964
-
[40]
Extensions of block-projections met hods with relaxation parameters to inconsistent and rank-deficient least-squares problems
Constantin Popa. Extensions of block-projections met hods with relaxation parameters to inconsistent and rank-deficient least-squares problems. BIT, 38(1):151–176, 1998
1998
-
[41]
Characterization of the solutions se t of inconsistent least-squares problems by an extended Kaczmarz algorithm
Constantin Popa. Characterization of the solutions se t of inconsistent least-squares problems by an extended Kaczmarz algorithm. Korean J. Comput. Appl. Math. , 6(1):51–64, 1999
1999
-
[42]
An efficient ridge regression algorithm with pa rameter estimation for data analysis in ma- chine learning
MP Rajan. An efficient ridge regression algorithm with pa rameter estimation for data analysis in ma- chine learning. SN Comput. Sci. , 3(2):171, 2022
2022
-
[43]
Generalized Gearhart-Koshy accelera tion for the Kaczmarz method
Janosch Rieger. Generalized Gearhart-Koshy accelera tion for the Kaczmarz method. Math. Comp. , 92(341):1251–1272, 2023
2023
-
[44]
Sparse linear least -squares problems
Jennifer Scott and Miroslav T ˚ uma. Sparse linear least -squares problems. Acta Numer. , 34:891–1010, 2025
2025
-
[45]
A randomized Kacz marz algorithm with exponential conver- gence
Thomas Strohmer and Roman Vershynin. A randomized Kacz marz algorithm with exponential conver- gence. J. Fourier Anal. Appl. , 15(2):262–278, 2009
2009
-
[46]
On gree dy multi-step inertial randomized Kaczmarz method for solving linear systems
Yansheng Su, Deren Han, Yun Zeng, and Jiaxin Xie. On gree dy multi-step inertial randomized Kaczmarz method for solving linear systems. Calcolo, 61(4):68, 2024
2024
-
[47]
Connecting rand omized iterative methods with Krylov sub- spaces
Yonghan Sun, Deren Han, and Jiaxin Xie. Connecting rand omized iterative methods with Krylov sub- spaces. arXiv preprint arXiv:2505.20602 , 2025
-
[48]
Linear convergence of Gearhart-Koshy accelerated Kaczmarz methods for tensor linear systems
Yijie Wang, Yonghan Sun, Deren Han, and Jiaxin Xie. Line ar convergence of Gearhart-Koshy acceler- ated Kaczmarz methods for tensor linear systems. arXiv preprint arXiv:2604.05816 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Coordinate descent algorithms
Stephen J Wright. Coordinate descent algorithms. Math. Program., 151(1):3–34, 2015
2015
-
[50]
Randomized itera tive methods for generalized absolute value equations: Solvability and error bounds
Jiaxin Xie, Hou-Duo Qi, and Deren Han. Randomized itera tive methods for generalized absolute value equations: Solvability and error bounds. SIAM J. Optim. , 35(3):1731–1760, 2025
2025
-
[51]
Local ridge regre ssion for face recognition
Hui Xue, Yulian Zhu, and Songcan Chen. Local ridge regre ssion for face recognition. Neurocomputing, 72(4-6):1342–1346, 2009
2009
-
[52]
On adap tive stochastic heavy ball momentum for solving linear systems
Yun Zeng, Deren Han, Yansheng Su, and Jiaxin Xie. On adap tive stochastic heavy ball momentum for solving linear systems. SIAM J. Matrix Anal. Appl. , 45(3):1259–1286, 2024
2024
-
[53]
On adap tive stochastic extended iterative methods for solving least squares
Yun Zeng, Deren Han, Yansheng Su, and Jiaxin Xie. On adap tive stochastic extended iterative methods for solving least squares. Math. Comp. , DOI: https://doi.org/10.1090/mcom/4168, 2025. 34 YUN ZENG, JIAN-FENG CAI, DEREN HAN, AND JIAXIN XIE
-
[54]
Stocha stic dual coordinate descent with adaptive heavy ball momentum for linearly constrained convex optimi zation
Yun Zeng, Deren Han, Yansheng Su, and Jiaxin Xie. Stocha stic dual coordinate descent with adaptive heavy ball momentum for linearly constrained convex optimi zation. Numer. Math. , 158(2):749–794, 2026
2026
-
[55]
Anastasios Zouzias and Nikolaos M. Freris. Randomized extended Kaczmarz for solving least squares. SIAM J. Matrix Anal. Appl. , 34(2):773–793, 2013. School of Mathematical Sciences, Beihang University, Beij ing, 100191, China. Email address : zengyun@buaa.edu.cn Department of Mathematics, Hong Kong University of Science and Technology, Clear W ater Bay, K...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.