Coding Beyond Your Training: Claude Code and the Technological Frontier of Software Developers
Pith reviewed 2026-06-29 19:47 UTC · model grok-4.3
The pith
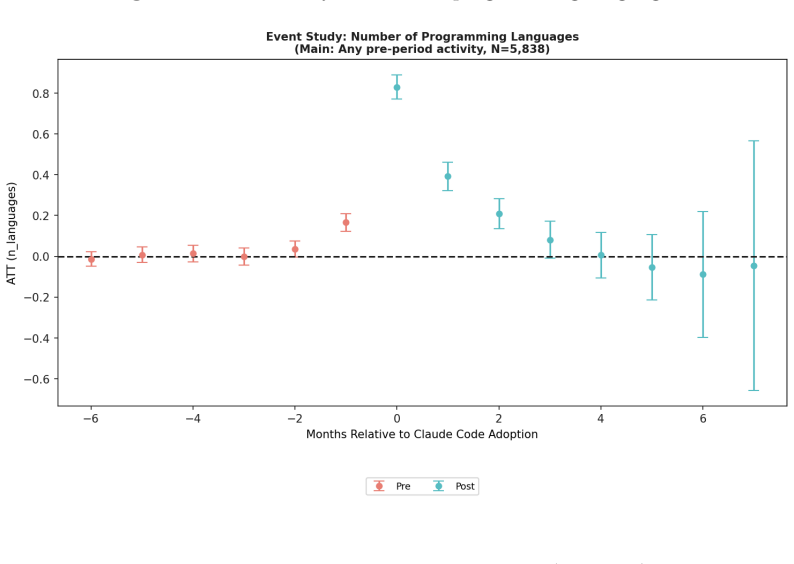
Adoption of Claude Code raises developers' monthly commits by 41, repositories by 1.5, and distinct languages used by 0.83.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using the doubly robust Callaway and Sant'Anna (2021) estimator on staggered adoption defined by first Claude-co-authored commit, the study finds positive and significant effects on monthly commits (+41), repositories contributed to (+1.5), distinct programming languages used (+0.83), Shannon language entropy (+0.14), newly-used languages (+0.31), and cumulative lifetime languages (+0.51). The cumulative-languages effect grows with time since adoption, consistent with a Bayesian-learning model in which the AI supplies free signals about unfamiliar technologies and lowers the switching barrier. Results hold under two stricter activity filters, though identification limits prevent a strict cau
What carries the argument
The Callaway and Sant'Anna (2021) doubly robust estimator applied to staggered rollout of Claude Code, with treatment timed at first co-authored commit and not-yet-treated developers as controls.
If this is right
- The cumulative-languages effect increases with time since adoption.
- The pattern matches a Bayesian-learning model in which AI lowers the barrier to switching technologies.
- Effects remain after applying two stricter filters on developer activity.
- Adoption coincides with a sharp and persistent shift in measured developer behavior.
Where Pith is reading between the lines
- Wider use of such tools could accelerate how quickly developers accumulate experience across languages.
- Organizations might observe more cross-language contributions within teams if adoption spreads.
- Comparable staggered rollouts of other AI assistants could be studied with the same estimator to check consistency.
- Cleaner identification strategies such as randomized access would be needed to move from the current estimates to stronger causal statements.
Load-bearing premise
The staggered rollout of Claude Code from May 2025 to January 2026 permits causal identification via the Callaway and Sant'Anna estimator despite explicit limits on that identification.
What would settle it
A randomized trial that assigns access to Claude Code to a subset of developers while holding other factors fixed and then tracks changes in their monthly commits, repositories, and language counts would test whether the estimated effects appear under tighter identification.
Figures

read the original abstract
We study whether adoption of an AI coding assistant causally expands the technological frontier of individual software developers. We exploit the staggered rollout of Claude Code across GitHub between May 2025 and January 2026 in a panel of 5,838 developers observed monthly over 28 months, with treatment defined by the developer's first Claude-co-authored commit and not-yet-treated developers as controls. Using the doubly robust Callaway and Sant'Anna (2021) estimator, we find positive and significant effects on monthly commits (+41), repositories contributed to (+1.5), distinct programming languages used (+0.83), Shannon language entropy (+0.14), newly-used languages (+0.31), and cumulative lifetime languages (+0.51). The cumulative-languages effect grows with time since adoption, matching a Bayesian-learning model in which AI provides free signals about unfamiliar technologies and lowers the switching barrier. Results are robust to two stricter activity filters. The estimates document a sharp, persistent shift in developer behavior coincident with AI adoption; identification limits prevent a strict causal claim and we outline an agenda for cleaner tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies whether adoption of Claude Code causally expands individual software developers' technological frontier. It exploits the staggered rollout of Claude Code on GitHub (May 2025–January 2026) in a monthly panel of 5,838 developers, defining treatment as a developer's first Claude-co-authored commit and using not-yet-treated developers as controls. Applying the doubly robust Callaway and Sant'Anna (2021) estimator, it reports positive significant effects on monthly commits (+41), repositories contributed to (+1.5), distinct languages used (+0.83), Shannon entropy (+0.14), newly-used languages (+0.31), and cumulative lifetime languages (+0.51). The cumulative-languages effect grows with time since adoption, consistent with a Bayesian-learning model in which AI supplies free signals about unfamiliar technologies. The authors explicitly caveat that identification limits preclude a strict causal claim and present the estimates as documenting coincident behavioral shifts, with robustness to two stricter activity filters.
Significance. If the reported associations are robust, the findings would indicate that AI coding assistants can increase developer activity and broaden language use, with the time-growing cumulative-languages effect supporting learning models that emphasize lowered switching costs. The application of a published off-the-shelf estimator to large-scale external GitHub data constitutes a methodological strength and provides falsifiable, quantitative predictions that future work could test.
major comments (2)
- [Abstract] Abstract and treatment definition: defining treatment by the developer's own first Claude-co-authored commit renders timing endogenous and plausibly correlated with unobservables (productivity shocks, project demands). This directly threatens the no-anticipation and conditional parallel-trends assumptions required by the Callaway and Sant'Anna (2021) estimator, making the point estimates load-bearing for any interpretation beyond descriptive association. The paper's caveat is appropriate but does not remove the need to demonstrate that the estimator's identifying assumptions are at least approximately satisfied.
- [Results (presumed §4)] Results and robustness: the claim of robustness to 'two stricter activity filters' is stated without reporting the filters themselves, the resulting sample sizes, or the coefficient changes. Because the main estimates rest on the selected sample of 5,838 developers, this omission prevents assessment of whether the robustness checks address selection on observables or activity levels that could drive the reported effects.
minor comments (2)
- [Abstract] The abstract mentions 'Shannon language entropy' without a brief definition or reference; a one-sentence clarification on first use would improve accessibility.
- [Discussion (presumed §5)] The Bayesian-learning model is invoked to rationalize the growing cumulative-languages effect, but the manuscript provides only a qualitative match; adding a short formal sketch or simulated path from the model would strengthen the link.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the estimates document associations coincident with adoption rather than strict causal effects, consistent with the explicit caveats already in the manuscript. We address each major comment below and will revise the paper to increase transparency on the robustness checks.
read point-by-point responses
-
Referee: [Abstract] Abstract and treatment definition: defining treatment by the developer's own first Claude-co-authored commit renders timing endogenous and plausibly correlated with unobservables (productivity shocks, project demands). This directly threatens the no-anticipation and conditional parallel-trends assumptions required by the Callaway and Sant'Anna (2021) estimator, making the point estimates load-bearing for any interpretation beyond descriptive association. The paper's caveat is appropriate but does not remove the need to demonstrate that the estimator's identifying assumptions are at least approximately satisfied.
Authors: We appreciate the referee highlighting this concern. The manuscript already states that 'identification limits prevent a strict causal claim' and presents results as documenting 'a sharp, persistent shift in developer behavior coincident with AI adoption.' Treatment is defined at the individual level as the first Claude-co-authored commit to measure personal adoption within the GitHub staggered rollout, using not-yet-treated developers as controls. While we acknowledge that individual timing could correlate with unobservables and affect the parallel-trends assumption, the doubly robust estimator is applied to the staggered design as described. In revision we will expand the limitations discussion to further address potential violations and note any feasible pre-trend or sensitivity checks. revision: partial
-
Referee: [Results (presumed §4)] Results and robustness: the claim of robustness to 'two stricter activity filters' is stated without reporting the filters themselves, the resulting sample sizes, or the coefficient changes. Because the main estimates rest on the selected sample of 5,838 developers, this omission prevents assessment of whether the robustness checks address selection on observables or activity levels that could drive the reported effects.
Authors: We agree that the robustness section lacks sufficient detail. In the revised manuscript we will add a description of the two stricter activity filters, report the resulting sample sizes, and present the coefficient estimates under each filter so readers can evaluate their impact on the main results. revision: yes
Circularity Check
No circularity: off-the-shelf estimator applied to external data with no self-referential reduction
full rationale
The paper applies the Callaway and Sant'Anna (2021) doubly-robust estimator to GitHub panel data with treatment defined by first observed Claude-co-authored commit. No derivation, prediction, or result is obtained by fitting parameters to a subset and renaming the fit as a prediction; no self-citation chain supplies a uniqueness theorem or ansatz that the current estimates reduce to; the Bayesian-learning model is invoked only as a post-hoc match to the observed time pattern, not as an input that forces the estimates. The manuscript explicitly flags identification limits, confirming the estimates are descriptive of coincident shifts rather than constructed from internal definitions. This is a standard observational study whose central quantities are computed from external data via an independent method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Callaway and Sant'Anna (2021) doubly robust estimator identifies average treatment effects on the treated under staggered adoption when not-yet-treated units serve as valid controls.
Forward citations
Cited by 1 Pith paper
-
Adoption and Impact of Command-Line AI Coding Agents: A Study of Microsoft's Early 2026 Rollout of Claude Code and GitHub Copilot CLI
Observational study of Claude Code and GitHub Copilot CLI at Microsoft finds social-network-driven adoption, activity-linked retention, and a persistent 24% lift in merged pull requests among adopters.
Reference graph
Works this paper leans on
-
[1]
Tasks, automation, and the rise in US wage inequality
Daron Acemoglu and Pascual Restrepo. Tasks, automation, and the rise in US wage inequality. Econometrica, 90(5):1973–2016,
1973
-
[2]
New frontiers: The origins and content of new work, 1940–2018.Quarterly Journal of Economics, 139(3):1399–1465,
David Autor, Caroline Chin, Anna Salomons, and Bryan Seegmiller. New frontiers: The origins and content of new work, 1940–2018.Quarterly Journal of Economics, 139(3):1399–1465,
1940
-
[3]
Erik Brynjolfsson, Danielle Li, and Lindsey R. Raymond. Generative AI at work.Quarterly Journal of Economics, 139(4):1919–1971,
1919
-
[4]
Measuring the impact of early-2025 AI on experienced open-source developer productivity
33 METR. Measuring the impact of early-2025 AI on experienced open-source developer productivity. Technical report, METR,
2025
-
[5]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. The impact of AI on developer productivity: Evidence from GitHub Copilot.arXiv preprint arXiv:2302.06590,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Throughout,τi denotes the date at which developeri adopts AI,πdenotes the initial precision on unfamiliar languages, and δ≡nAT/σ2 A denotes the precision accumulated throughT periods of AI exposure on an unfamiliar language. Proof of Proposition 1 Define the entry condition for languagek′at timet: k′is in the portfolio if and only if µik′,t−ρ/(2πik′,t) > ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.