ConTrack: Constrained Hand Motion Tracking with Adaptive Trade-off Control
Pith reviewed 2026-06-28 10:11 UTC · model grok-4.3
The pith
ConTrack improves hand motion tracking success and accuracy by treating object trajectories as constraints and adapting fidelity trade-offs online via dual-variable updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ConTrack treats object tracking as a constraint in the RL objective and employs dual-variable updates to allocate remaining authority to motion fidelity, enabling online adaptation of task-style trade-offs. Combined with an adaptive mid-trajectory reset library that reuses policy-reachable simulator states, the framework yields higher success rates and improved object pose accuracy compared with prior methods in both simulated tracking and real-robot experiments, while still preserving the joint trajectories and contact timing of the original demonstrations.
What carries the argument
Dual-variable update that dynamically balances the object-tracking constraint against motion-fidelity objectives during policy optimization.
If this is right
- Success rates and object pose accuracy rise over prior tracking methods on long-horizon contact-rich sequences.
- Demonstrated joint motion and contact timing remain faithful without explicit reward shaping.
- Online adaptation of the trade-off functions under limited interaction budgets without per-sequence retuning.
- The adaptive reset library keeps long-horizon policy learning stable by reusing reachable states.
Where Pith is reading between the lines
- The same constraint-plus-dual-update pattern could be tested on other multi-objective robot control problems that currently rely on hand-tuned rewards.
- Removing the reset library entirely would provide a direct test of whether the dual-variable mechanism alone suffices for stability.
- The formulation suggests that hard constraints may substitute for reward engineering in a broader class of demonstration-tracking tasks.
Load-bearing premise
Dual-variable updates produce stable online adaptation of the tracking-versus-fidelity trade-off under limited interaction budgets without any per-sequence manual tuning.
What would settle it
Reproducing the reported simulation and real-robot experiments and finding no statistically significant gains in success rate or object-pose accuracy relative to tuned baselines, or observing that the dual updates require manual intervention to remain stable.
Figures


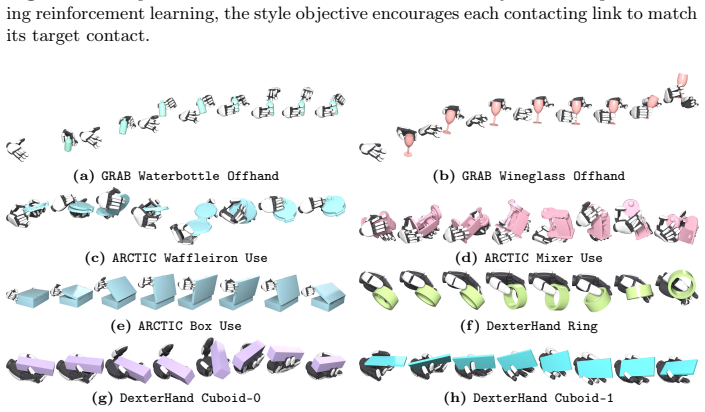
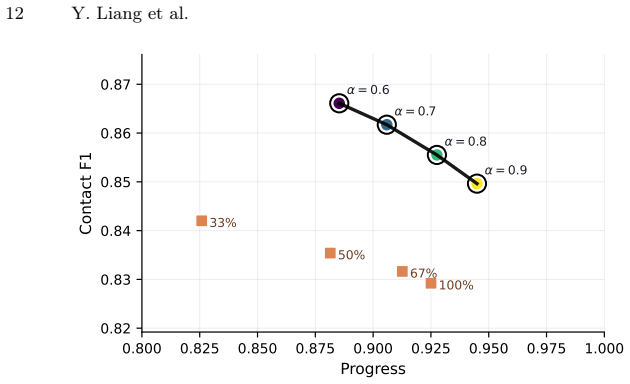
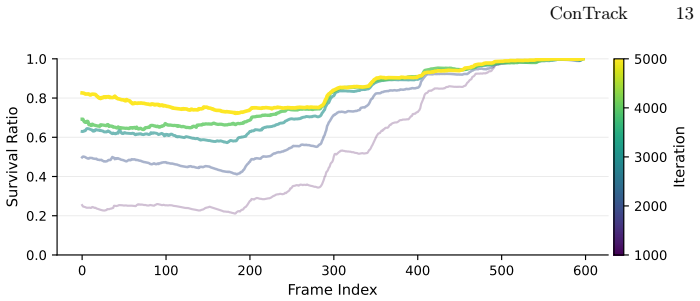


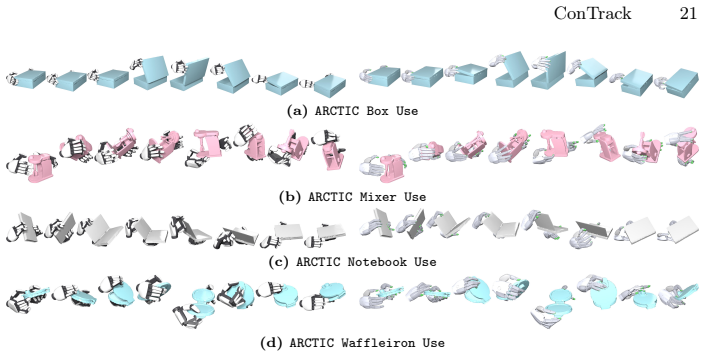
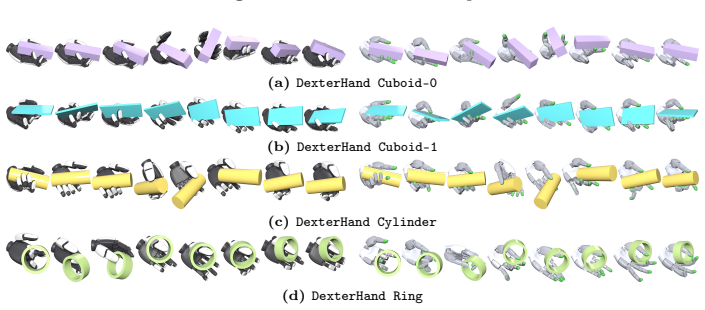
read the original abstract
Human demonstrations provide strong priors for robot manipulation, yet it is non-trivial to transfer them to execute on real robots due to the kinematic gap. In dexterous manipulation, it remains challenging to track long-horizon, contact-rich sequences even in simulators: a reference-tracking policy must keep objects on their target trajectories while preserving demonstrated joint motion and contact timing. Existing approaches often rely on hand-crafted reward tuning that require per-sequence tuning and break under limited interaction budgets. We introduce ConTrack, a reinforcement learning (RL) framework that scales with tracking data. ConTrack treats object tracking as a constraint and allocates remaining control authority to motion fidelity, which allows it to adapt task--style trade-offs online using a dual-variable update. In addition, ConTrack also stabilizes long-horizon learning with an adaptive mid-trajectory reset library that reuses policy-reachable simulator states. Our qualitative and quantitative results in simulation tracking and real robot demonstrate that ConTrack improves success and object pose accuracy significantly over prior arts while preserving joint and contact fidelity. Website: https://www.lyt0112.com/projects/ConTrack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ConTrack, a constrained RL framework for dexterous hand motion tracking. It formulates object tracking as a hard constraint, uses dual-variable updates to adapt task-style trade-offs online without per-sequence tuning, and adds an adaptive mid-trajectory reset library for long-horizon stability. The central claim is that this yields significantly higher success rates and object pose accuracy than prior methods in both simulation tracking and real-robot experiments, while preserving demonstrated joint motion and contact fidelity.
Significance. If the quantitative claims hold with proper baselines and ablations, the approach would address a practical bottleneck in transferring contact-rich human demonstrations to robots by removing manual reward tuning and enabling stable online adaptation under limited interaction budgets. This could improve scalability for long-horizon manipulation tasks.
major comments (2)
- Abstract: The claim of 'significant' improvements in success and object pose accuracy is stated without any numerical metrics, baselines, ablation results, or error bars. This prevents evaluation of whether the central claim is supported by evidence.
- Abstract and method description: No equations, constraint formulations, or dual-variable update rules are provided, so it is impossible to verify whether the online adaptation mechanism is parameter-free or requires hidden tuning as asserted.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of results and technical details.
read point-by-point responses
-
Referee: Abstract: The claim of 'significant' improvements in success and object pose accuracy is stated without any numerical metrics, baselines, ablation results, or error bars. This prevents evaluation of whether the central claim is supported by evidence.
Authors: We agree that the abstract would be stronger with explicit quantitative support. In the revision we will incorporate key metrics (success rates, object pose errors with standard deviations, and direct baseline comparisons) drawn from the experimental tables in Sections 4 and 5, while remaining within the word limit. revision: yes
-
Referee: Abstract and method description: No equations, constraint formulations, or dual-variable update rules are provided, so it is impossible to verify whether the online adaptation mechanism is parameter-free or requires hidden tuning as asserted.
Authors: The abstract is intentionally equation-free, as is conventional. The method section (Section 3) contains the full constraint formulation (object tracking as a hard constraint) and the dual-variable Lagrangian update rules that enable online adaptation without per-sequence hyper-parameter search. We will add a brief textual pointer to these equations already present in the method and ensure they are clearly numbered and cross-referenced; no new hidden tuning parameters are introduced. revision: partial
Circularity Check
No significant circularity; derivation grounded in standard RL components
full rationale
The provided abstract and description introduce ConTrack as a constrained RL method that treats object tracking as a hard constraint, employs dual-variable updates for adaptive trade-offs, and uses an adaptive reset library for stability. These elements draw from established constrained optimization and RL practices without any quoted equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the central claims to their inputs by construction. The claims of improved success and fidelity remain independent of the method description itself.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Mana: Dexterous Manipulation of Articulated Tools
Mana framework achieves zero-shot sim-to-real transfer for grasping and in-hand manipulation of four articulated tools using a coarse-to-fine animation-inspired pipeline.
Reference graph
Works this paper leans on
-
[1]
In: Precup, D., Teh, Y.W
Achiam, J., Held, D., Tamar, A., Abbeel, P.: Constrained policy optimization. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 70, pp. 22–31. PMLR (06–11 Aug 2017)
2017
-
[2]
arXiv preprint arXiv:2507.05331 (2025)
Barreiros, J., Beaulieu, A., Bhat, A., Cory, R., Cousineau, E., Dai, H., Fang, C.H., Hashimoto, K., Irshad, M.Z., Itkina, M., et al.: A careful examination of large behavior models for multitask dexterous manipulation. arXiv preprint arXiv:2507.05331 (2025)
Pith/arXiv arXiv 2025
-
[3]
In: The European Conference on Computer Vision (ECCV) (August 2020)
Brahmbhatt, S., Tang, C., Twigg, C.D., Kemp, C.C., Hays, J.: ContactPose: A dataset of grasps with object contact and hand pose. In: The European Conference on Computer Vision (ECCV) (August 2020)
2020
-
[4]
arXiv preprint arXiv:2511.15704 (2025)
Cai, X., Qiu, R.Z., Chen, G., Wei, L., Liu, I., Huang, T., Cheng, X., Wang, X.: In-n-on: Scaling egocentric manipulation with in-the-wild and on-task data. arXiv preprint arXiv:2511.15704 (2025)
arXiv 2025
-
[5]
In: IEEE Inter- national Symposium on System Integrations (SII) (2019)
Carpentier, J., Saurel, G., Buondonno, G., Mirabel, J., Lamiraux, F., Stasse, O., Mansard, N.: The pinocchio c++ library – a fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives. In: IEEE Inter- national Symposium on System Integrations (SII) (2019)
2019
-
[6]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) (2021)
Chao,Y.W.,Yang,W.,Xiang, Y.,Molchanov,P.,Handa,A., Tremblay, J.,Narang, Y.S., Van Wyk, K., Iqbal, U., Birchfield, S., Kautz, J., Fox, D.: DexYCB: A bench- mark for capturing hand grasping of objects. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) (2021)
2021
-
[7]
In: CoRL (2024)
Chen, Y., Wang, C., Yang, Y., Liu, C.K.: Object-centric dexterous manipulation from human motion data. In: CoRL (2024)
2024
-
[8]
arXiv preprint arXiv:2407.01512 (2024)
Cheng, X., Li, J., Yang, S., Yang, G., Wang, X.: Open-television: Teleoperation with immersive active visual feedback. arXiv preprint arXiv:2407.01512 (2024)
arXiv 2024
-
[9]
arXiv preprint arXiv:2402.10329 (2024)
Chi, C., Xu, Z., Pan, C., Cousineau, E., Burchfiel, B., Feng, S., Tedrake, R., Song, S.:Universalmanipulationinterface:In-the-wildrobotteachingwithoutin-the-wild robots. arXiv preprint arXiv:2402.10329 (2024)
Pith/arXiv arXiv 2024
-
[10]
arXiv preprint arXiv:1901.10995 (2019)
Ecoffet, A., Huizinga, J., Lehman, J., Stanley, K.O., Clune, J.: Go-explore: a new approach for hard-exploration problems. arXiv preprint arXiv:1901.10995 (2019)
arXiv 1901
-
[11]
In: Pro- ceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: ARCTIC: A dataset for dexterous bimanual hand-object manipulation. In: Pro- ceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fu, R., Zhang, D., Jiang, A., Fu, W., Funk, A., Ritchie, D., Sridhar, S.: Gigahands: A massive annotated dataset of bimanual hand activities. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17461–17474 (2025)
2025
-
[13]
arXiv preprint arXiv:2504.18904 (2025)
Geng, H., Wang, F., Wei, S., Li, Y., Wang, B., An, B., Cheng, C.T., Lou, H., Li, P., Wang, Y.J., Liang, Y., Goetting, D., Xu, C., Chen, H., Qian, Y., Geng, Y., Mao, J., Wan, W., Zhang, M., Lyu, J., Zhao, S., Zhang, J., Zhang, J., Zhao, C., Lu, H., Ding, Y., Gong, R., Wang, Y., Kuang, Y., Wu, R., Jia, B., Sferrazza, C., Dong, H., Huang, S., Wang, Y., Malik...
arXiv 2025
-
[14]
In: ICRA (2020) 16 Y
Handa, A., Van Wyk, K., Yang, W., Liang, J., Chao, Y.W., Wan, Q., Birchfield, S., Ratliff, N., Fox, D.: Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system. In: ICRA (2020) 16 Y. Liang et al
2020
-
[15]
arXiv preprint arXiv:2510.08475 (2025)
Hsieh, J., Tu, K.H., Hung, K.H., Ke, T.W.: Dexman: Learning bimanual dexterous manipulation from human and generated videos. arXiv preprint arXiv:2510.08475 (2025)
arXiv 2025
-
[16]
arXiv preprint arXiv:2504.16054 (2025)
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.: pi0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
Pith/arXiv arXiv 2025
-
[17]
arXiv preprint arXiv:2501.04228 (2025)
Ishihara, Y., Takasugi, N., Kawakami, K., Kinoshita, M., Aoyama, K.: Constraints as rewards: Reinforcement learning for robots without reward functions. arXiv preprint arXiv:2501.04228 (2025)
arXiv 2025
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Jian, J., Liu, X., Li, M., Hu, R., Liu, J.: Affordpose: A large-scale dataset of hand-object interactions with affordance-driven hand pose. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14713– 14724 (October 2023)
2023
-
[19]
arXiv preprint arXiv:2510.20813 (2025)
Jiang, G., Chang, H., Qiu, R.Z., Liang, Y., Ji, M., Zhu, J., Dong, Z., Zou, X., Wang, X.: Gsworld: Closed-loop photo-realistic simulation suite for robotic manipulation. arXiv preprint arXiv:2510.20813 (2025)
arXiv 2025
-
[20]
arXiv preprint arXiv:2603.10158 (2026)
Jiang, G., Liang, Y., Ye, J., Huang, J.Y., Jing, C., Duan, R., Abbeel, P., Wang, X., Zou, X.: Cross-hand latent representation for vision-language-action models. arXiv preprint arXiv:2603.10158 (2026)
arXiv 2026
-
[21]
In: ICCV (2023)
Jiang, N., Liu, T., Cao, Z., Cui, J., Chen, Y., Wang, H., Zhu, Y., Huang, S.: Full-body articulated human-object interaction. In: ICCV (2023)
2023
-
[22]
In: ICRA
Kareer, S., Patel, D., Punamiya, R., Mathur, P., Cheng, S., Wang, C., Hoffman, J., Xu, D.: Egomimic: Scaling imitation learning via egocentric video. In: ICRA. IEEE (2025)
2025
-
[23]
arXiv preprint arXiv:2512.22414 (2025)
Kareer, S., Pertsch, K., Darpinian, J., Hoffman, J., Xu, D., Levine, S., Finn, C., Nair, S.: Emergence of human to robot transfer in vision-language-action models. arXiv preprint arXiv:2512.22414 (2025)
arXiv 2025
-
[24]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kim, J., Kim, J., Na, J., Joo, H.: ParaHome: Parameterizing Everyday Home Ac- tivities Towards 3D Generative Modeling of Human-Object Interactions . In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1816–1828. IEEE Computer Society (2025)
2025
-
[25]
In: CVPR (2025)
Li, K., Li, P., Liu, T., Li, Y., Huang, S.: Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning. In: CVPR (2025)
2025
-
[26]
arXiv preprint arXiv:2601.05844 (2026)
Liang, Y., Xu, S., Zhang, Y., Zhan, B., Zhang, H., Liu, L.: Dextercap: An affordable and automated system for capturing dexterous hand-object manipulation. arXiv preprint arXiv:2601.05844 (2026)
arXiv 2026
-
[27]
arXiv preprint arXiv:2508.08241 (2025)
Liao, Q., Truong, T.E., Huang, X., Gao, Y., Tevet, G., Sreenath, K., Liu, C.K.: Beyondmimic: From motion tracking to versatile humanoid control via guided dif- fusion. arXiv preprint arXiv:2508.08241 (2025)
Pith/arXiv arXiv 2025
-
[28]
arXiv preprint arXiv:2410.07864 (2024)
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024)
Pith/arXiv arXiv 2024
-
[29]
In: ICLR (2025)
Liu, X., Adalibieke, J., Han, Q., Qin, Y., Yi, L.: Dextrack: Towards generalizable neural tracking control for dexterous manipulation from human references. In: ICLR (2025)
2025
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Lu, J., Huang, C.H.P., Bhattacharya, U., Huang, Q., Zhou, Y.: Humoto: A 4d dataset of mocap human object interactions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10886–10897 (October 2025) ConTrack 17
2025
-
[31]
5: Scaling human-centric robot learning for cross- embodiment generalization
Luo, H., Wang, Y., Zhang, W., Zheng, S., Xi, Z., Xu, C., Xu, H., Yuan, H., Zhang, C., Wang, Y., et al.: Being-h0. 5: Scaling human-centric robot learning for cross- embodiment generalization. arXiv preprint arXiv:2601.12993 (2026)
arXiv 2026
-
[32]
arXiv preprint arXiv:2511.07820 (2025)
Luo, Z., Yuan, Y., Wang, T., Li, C., Chen, S., Castaneda, F., Cao, Z.A., Li, J., Minor, D., Ben, Q., et al.: Sonic: Supersizing motion tracking for natural humanoid whole-body control. arXiv preprint arXiv:2511.07820 (2025)
Pith/arXiv arXiv 2025
-
[33]
arXiv preprint arXiv:2505.24853 (2025)
Mandi, Z., Hou, Y., Fox, D., Narang, Y., Mandlekar, A., Song, S.: Dexmachina: Functional retargeting for bimanual dexterous manipulation. arXiv preprint arXiv:2505.24853 (2025)
arXiv 2025
-
[34]
arXiv preprint arXiv:2511.09484 (2025)
Pan, C., Wang, C., Qi, H., Liu, Z., Bharadhwaj, H., Sharma, A., Wu, T., Shi, G., Malik, J., Hogan, F.: Spider: Scalable physics-informed dexterous retargeting. arXiv preprint arXiv:2511.09484 (2025)
arXiv 2025
-
[35]
ACM Trans
Peng, X.B., Abbeel, P., Levine, S., van de Panne, M.: Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Trans. Graph. 37(4), 143:1–143:14 (Jul 2018)
2018
-
[36]
ACM Trans
Peng, X.B., Guo, Y., Halper, L., Levine, S., Fidler, S.: Ase: Large-scale reusable ad- versarial skill embeddings for physically simulated characters. ACM Trans. Graph. 41(4) (Jul 2022)
2022
-
[37]
arXiv preprint arXiv:2307.04577 (2023)
Qin,Y.,Yang,W.,Huang,B.,VanWyk,K.,Su,H.,Wang,X.,Chao,Y.W.,Fox,D.: Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. arXiv preprint arXiv:2307.04577 (2023)
arXiv 2023
-
[38]
In: CoRL (2025)
Qiu, R.Z., Yang, S., Cheng, X., Chawla, C., Li, J., He, T., Yan, G., Yoon, D.J., Hoque, R., Paulsen, L., et al.: Humanoid policy˜ human policy. In: CoRL (2025)
2025
-
[39]
Resnick, C., Raileanu, R., Kapoor, S., Peysakhovich, A., Cho, K., Bruna, J.: Back- play:" man muss immer umkehren". arXiv preprint arXiv:1807.06919 (2018)
arXiv 2018
-
[40]
arXiv preprint arXiv:1707.06347 (2017)
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
Pith/arXiv arXiv 2017
-
[41]
arXiv preprint arXiv:2512.16842 (2025)
Song, Y.R., Li, J., Fu, R., Murphy, D., Zhou, K., Shiv, R., Li, Y., Xiong, H., Owens, C.E., Du, Y., et al.: Opentouch: Bringing full-hand touch to real-world interaction. arXiv preprint arXiv:2512.16842 (2025)
arXiv 2025
-
[42]
In: European Conference on Computer Vision (ECCV) (2020)
Taheri, O., Ghorbani, N., Black, M.J., Tzionas, D.: GRAB: A dataset of whole- body human grasping of objects. In: European Conference on Computer Vision (ECCV) (2020)
2020
-
[43]
Spirit AI Blog (2026)
Team, S.A.: Spirit-v1.5: Clean data is the enemy of great robot foundation models. Spirit AI Blog (2026)
2026
-
[44]
ACM Trans- actions on Graphics (TOG) (2024)
Tessler, C., Guo, Y., Nabati, O., Chechik, G., Peng, X.B.: Maskedmimic: Unified physics-based character control through masked motion inpainting. ACM Trans- actions on Graphics (TOG) (2024)
2024
-
[45]
arXiv preprint arXiv:1805.11074 (2018)
Tessler, C., Mankowitz, D.J., Mannor, S.: Reward constrained policy optimization. arXiv preprint arXiv:1805.11074 (2018)
Pith/arXiv arXiv 2018
-
[46]
arXiv preprint arXiv:2507.09371 (2025)
Wen, K., Li, C., He, J., Hutter, M.: Constrained style learning from imperfect demonstrations under task optimality. arXiv preprint arXiv:2507.09371 (2025)
arXiv 2025
-
[47]
arXiv preprint arXiv:2512.24210 (2025)
Wen, R., Chen, G., Cui, Z., Du, M., Gou, Y., Han, Z., Huang, L., Lei, M., Li, Y., Li, Z., et al.: Gr-dexter technical report. arXiv preprint arXiv:2512.24210 (2025)
arXiv 2025
-
[48]
arXiv preprint arXiv:2505.21864 (2025)
Xu, M., Zhang, H., Hou, Y., Xu, Z., Fan, L., Veloso, M., Song, S.: Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation. arXiv preprint arXiv:2505.21864 (2025)
arXiv 2025
-
[49]
arXiv preprint arXiv:2509.09671 (2025) 18 Y
Xu, S., Chao, Y.W., Bian, L., Mousavian, A., Wang, Y.X., Gui, L.Y., Yang, W.: Dexplore:Scalableneuralcontrolfordexterousmanipulationfromreference-scoped exploration. arXiv preprint arXiv:2509.09671 (2025) 18 Y. Liang et al
arXiv 2025
-
[50]
In: IROS (2025)
Yin, Z.H., Wang, C., Pineda, L., Bodduluri, K., Wu, T., Abbeel, P., Mukadam, M.: Geometric retargeting: A principled, ultrafast neural hand retargeting algorithm. In: IROS (2025)
2025
-
[51]
In: Lim, J., Song, S., Park, H.W
Ze, Y., Chen, Z., Araujo, J.P., Cao, Z.a., Peng, X.B., Wu, J., Liu, K.: Twist: Teleoperated whole-body imitation system. In: Lim, J., Song, S., Park, H.W. (eds.) Proceedings of The 9th Conference on Robot Learning. Proceedings of Machine Learning Research, vol. 305, pp. 2143–2154. PMLR (27–30 Sep 2025)
2025
-
[52]
arXiv preprint arXiv:2411.04428 (2026)
Zhao, S., Zhu, X., Chen, Y., Li, C., Xie, L., Zhang, X., Ding, M., Tomizuka, M.: Dexh2r: Task-oriented dexterous manipulation from human to robots. arXiv preprint arXiv:2411.04428 (2026)
arXiv 2026
-
[53]
Zheng, R., Niu, D., Xie, Y., Wang, J., Xu, M., Jiang, Y., Castañeda, F., Hu, F., Tan, Y.L., Fu, L., et al.: Egoscale: Scaling dexterous manipulation with diverse egocentric human data. arXiv preprint arXiv:2602.16710 (2026) ConTrack 19 T able 7:Sharpa Wave: tracking metrics on the benchmark set. Dataset Progress↑Obj pos (m)↓Obj rot (rad)↓Finger err (rad)↓...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.