VoxCPM2 Technical Report
Pith reviewed 2026-06-27 21:16 UTC · model grok-4.3
The pith
VoxCPM2 shows a single 2B-parameter model using hierarchical continuous latents can unify 30-language speech generation, voice design, and cloning without any external discrete tokenizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
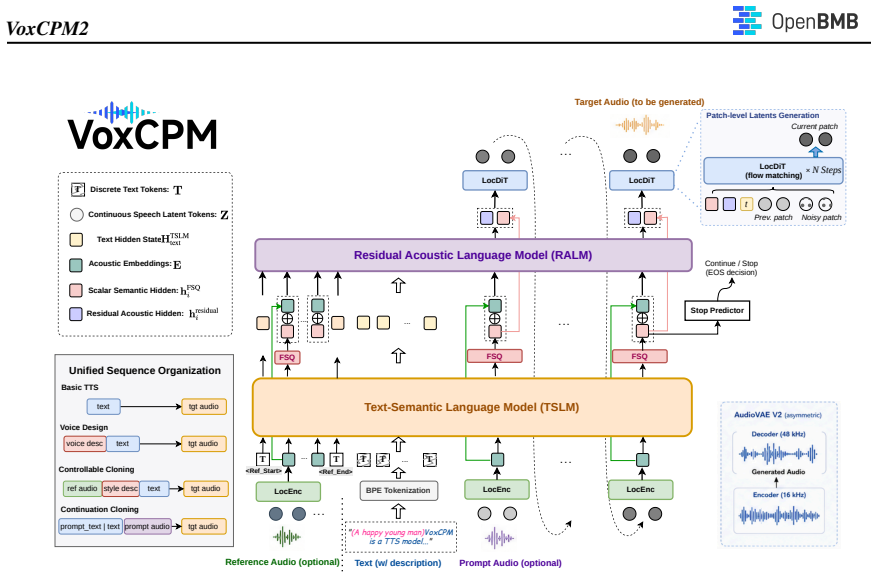
VoxCPM2 advances the hierarchical diffusion-autoregressive modeling paradigm by unifying diverse capabilities in a single backbone through a unified sequence organization and an asymmetric AudioVAE. The model jointly scales to 2B parameters and over 2 million hours of multilingual speech, achieving state-of-the-art or competitive performance on public zero-shot and instruction-following TTS benchmarks. On the internal 30-language evaluation set it attains an average WER of 1.68%. These results demonstrate that hierarchical continuous-latent modeling, without relying on any external discrete speech tokenizer, offers a viable and powerful foundation for large-scale multilingual and controllabl
What carries the argument
The unified sequence organization that expresses all generation modes through different arrangements of the same input building blocks, supported by the asymmetric AudioVAE for efficient encoding and high-quality reconstruction.
If this is right
- All generation modes can be trained jointly under a single set of parameters and objective.
- The model reaches state-of-the-art or competitive results on public zero-shot and instruction-following TTS benchmarks.
- Implicit super-resolution occurs from 16 kHz encoding to 48 kHz reconstruction without additional stages.
- High-fidelity continuation cloning and style-controllable cloning work alongside multilingual generation in one model.
Where Pith is reading between the lines
- The removal of external tokenizers could simplify training pipelines for custom speech models across languages.
- Joint scaling of continuous latents and data may improve cross-lingual transfer compared with separate per-language models.
- The same hierarchical structure might be tested on related audio tasks such as music generation if the sequence organization generalizes.
Load-bearing premise
A single 2B-parameter backbone with one unified sequence organization and asymmetric AudioVAE can jointly support all listed capabilities at claimed quality without hidden trade-offs or mode-specific degradation.
What would settle it
An experiment that measures whether performance on natural-language voice design or continuation cloning drops when the model is trained jointly on all 30 languages and tasks versus a version trained only on that single capability.
Figures
read the original abstract
We present VoxCPM2, a https://info.arxiv.org/help/prep#abstractsfully open-source multilingual and controllable speech generation foundation model that extends the hierarchical diffusion-autoregressive modeling paradigm of VoxCPM. VoxCPM2 advances the framework in three key dimensions: (i) capability, by unifying 30 languages, 9 Chinese dialects, natural-language voice design, style-controllable voice cloning, and high-fidelity continuation cloning within a single backbone; (ii) quality, through an asymmetric AudioVAE that encodes at 16 kHz and reconstructs at 48 kHz, enabling implicit super-resolution with high encoding efficiency; and (iii) scale, by jointly scaling the model to 2B parameters and the training data to over 2 million hours of multilingual speech. To support these diverse capabilities within one model, we introduce a unified sequence organization that expresses all generation modes through different arrangements of the same input building blocks, allowing joint training under a single set of parameters and objective. VoxCPM2 achieves state-of-the-art or competitive performance on public zero-shot and instruction-following TTS benchmarks. On our internal 30-language evaluation set, it attains an average WER of 1.68%. These results demonstrate that hierarchical continuous-latent modeling, without relying on any external discrete speech tokenizer, offers a viable and powerful foundation for large-scale multilingual and controllable speech generation. The model weights, fine-tuning code, and inference tools are publicly released under the Apache 2.0 license to foster community research and development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VoxCPM2, a 2B-parameter open-source multilingual and controllable speech generation model extending the hierarchical diffusion-autoregressive framework of VoxCPM. It uses an asymmetric AudioVAE (16 kHz encoding, 48 kHz reconstruction) for continuous latents, a unified sequence organization to support 30 languages, 9 Chinese dialects, natural-language voice design, style-controllable cloning, and continuation within a single backbone, trained on over 2 million hours of data. The work claims state-of-the-art or competitive results on public zero-shot and instruction-following TTS benchmarks plus an average WER of 1.68% on an internal 30-language evaluation set, arguing that hierarchical continuous-latent modeling without external discrete tokenizers is viable for large-scale speech generation. Model weights, fine-tuning code, and inference tools are released under Apache 2.0.
Significance. If the performance claims hold under rigorous evaluation, the result would be significant for demonstrating that a single scaled continuous-latent hierarchical model can unify diverse multilingual and controllable speech tasks without discrete tokenizers. The open-source release of a 2B-parameter model and training code is a concrete community contribution that enables further research on continuous-latent speech foundations.
major comments (2)
- [Abstract] Abstract: The claims of SOTA or competitive performance on public benchmarks and the internal WER of 1.68% are presented without any evaluation protocol, baseline comparisons, statistical significance tests, ablation studies, or details on the test sets, making it impossible to assess whether the results support the central claim of viability for the hierarchical continuous-latent approach.
- [Model description] The manuscript provides only a high-level description of the unified sequence organization and asymmetric AudioVAE; without concrete details on input block arrangements for different generation modes or how the single 2B backbone avoids capability trade-offs, the claim that one model jointly supports all listed tasks (30 languages, voice design, cloning, continuation) at claimed quality cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for greater detail in both the evaluation claims and the model architecture description. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of SOTA or competitive performance on public benchmarks and the internal WER of 1.68% are presented without any evaluation protocol, baseline comparisons, statistical significance tests, ablation studies, or details on the test sets, making it impossible to assess whether the results support the central claim of viability for the hierarchical continuous-latent approach.
Authors: We agree that the current manuscript presents performance claims at a high level without accompanying protocol details, baselines, or test-set descriptions. This limits verifiability of the central claim. We will add a new Evaluation section that specifies the public benchmark protocols, baseline systems, internal 30-language test-set composition, and any available statistical or ablation information to support the reported results. revision: yes
-
Referee: [Model description] The manuscript provides only a high-level description of the unified sequence organization and asymmetric AudioVAE; without concrete details on input block arrangements for different generation modes or how the single 2B backbone avoids capability trade-offs, the claim that one model jointly supports all listed tasks (30 languages, voice design, cloning, continuation) at claimed quality cannot be evaluated.
Authors: The referee is correct that the description remains high-level. We will expand the Model section with explicit examples of input-block arrangements for each generation mode and with discussion of how the single 2B-parameter backbone is trained to support the full task set without major capability trade-offs, including any empirical observations from joint training. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, parameter fits, or derivation steps. The central claim is presented as an empirical outcome of scaling a hierarchical continuous-latent model (extending prior VoxCPM work) to 2B parameters and 2M hours of data, with performance metrics (e.g., WER 1.68%) reported as measured results rather than quantities defined by the model's own parameters or self-citations. No load-bearing step reduces to a self-definition, fitted input renamed as prediction, or ansatz smuggled via citation. The unified sequence organization and asymmetric AudioVAE are described as architectural choices supporting joint training, not as quantities derived from the target capabilities themselves. This is the most common honest finding for a technical report focused on empirical scaling.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Closing the Quality Gap in Low-Resource Text-to-Speech: LoRA Fine-Tuning of VoxCPM2 for Khmer and Korean
A shared LoRA adapter on VoxCPM2 trained on 26 hours of Khmer and Korean data improves Khmer MOS from 3.85 to 4.23 using under 3% of parameters, with no gain for Korean.
Reference graph
Works this paper leans on
-
[1]
Mela-tts: Joint transformer-diffusion model with representation alignment for speech synthesis
Keyu An, Zhiyu Zhang, Changfeng Gao, Yabin Li, Zhendong Peng, Haoxu Wang, Zhihao Du, Han Zhao, Zhifu Gao, and Xiangang Li. Mela-tts: Joint transformer-diffusion model with representation alignment for speech synthesis. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 18337–18341. IEEE,
2026
-
[2]
Seed-tts: A family of high-quality versatile speech generation models
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality versatile speech generation models. arXiv preprint arXiv:2406.02430,
-
[3]
Mars6: A small and robust hierarchical-codec text-to-speech model
Matthew Baas, Pieter Scholtz, Arnav Mehta, Elliott Dyson, Akshat Prakash, and Herman Kamper. Mars6: A small and robust hierarchical-codec text-to-speech model. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[4]
Audiolm: a language modeling approach to audio generation
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio generation. IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023a. Zalán Borsos, Matt Sharifi, Damien Vin...
-
[5]
Emotion controllable speech synthesis using emotion-unlabeled dataset with the assistance of cross-domain speech emotion recognition
Xiong Cai, Dongyang Dai, Zhiyong Wu, Xiang Li, Jingbei Li, and Helen Meng. Emotion controllable speech synthesis using emotion-unlabeled dataset with the assistance of cross-domain speech emotion recognition. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5734–5738. IEEE,
2021
-
[6]
Xtts: a massively multilingual zero-shot text-to-speech model
Edresson Casanova, Kelly Davis, Eren Gölge, Görkem Göknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, et al. Xtts: a massively multilingual zero-shot text-to-speech model. arXiv preprint arXiv:2406.04904,
-
[7]
Flexivoice: Enabling flexible style control in zero-shot tts with natural language instructions
Dekun Chen, Xueyao Zhang, Yuancheng Wang, Kenan Dai, Li Ma, and Zhizheng Wu. Flexivoice: Enabling flexible style control in zero-shot tts with natural language instructions. arXiv preprint arXiv:2601.04656, 2026a. Huakang Chen, Jingbin Hu, Liumeng Xue, Qirui Zhan, Wenhao Li, Guobin Ma, Hanke Xie, Dake Guo, Linhan Ma, Yuepeng Jiang, et al. Mint-bench: A co...
-
[8]
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi
arXiv:2306.05284. Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438,
-
[9]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407, 2024a. – 21 – V oxCPM2 Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu G...
-
[10]
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, et al. E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In 2024 IEEE spoken language technology workshop (SLT), pp. 682–689. IEEE,
2024
-
[11]
Cfg-zero*: Improved classifier-free guidance for flow matching models
Weichen Fan, Amber Yijia Zheng, Dejia Zhu, Yao Ma, Nikola Liu, Zhangyang Wang, and Dilin Liu. Cfg-zero*: Improved classifier-free guidance for flow matching models. arXiv preprint arXiv:2503.18886,
-
[12]
Yitian Gong, Botian Jiang, Yiwei Zhao, Yucheng Yuan, Kuangwei Chen, Yaozhou Jiang, Cheng Chang, Dong Hong, Mingshu Chen, Ruixiao Li, et al. Moss-tts technical report. arXiv preprint arXiv:2603.18090,
-
[13]
Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications
Hao-Han Guo, Yao Hu, Kun Liu, Fei-Yu Shen, Xu Tang, Yi-Chen Wu, Feng-Long Xie, Kun Xie, and Kai-Tuo Xu. Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications. arXiv preprint arXiv:2409.03283,
-
[14]
Prompttts: Controllable text-to-speech with text descriptions
Zhifang Guo, Yichong Leng, Yihan Wu, Sheng Zhao, and Xu Tan. Prompttts: Controllable text-to-speech with text descriptions. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[15]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, et al. Qwen3-tts technical report. arXiv preprint arXiv:2601.15621, 2026a. Jingbin Hu, Huakang Chen, Linhan Ma, Dake Guo, Qirui Zhan, Wenhao Li, Haoyu Zhang, Kangxiang Xia, Ziyu Zhang, Wenjie Tian, et al. V oicesculptor: Your voice, designed...
-
[16]
Textrolspeech: A text style control speech corpus with codec language text-to-speech models
Shengpeng Ji, Jialong Zuo, Minghui Fang, Ziyue Jiang, Feiyang Chen, Xinyu Duan, Baoxing Huai, and Zhou Zhao. Textrolspeech: A text style control speech corpus with codec language text-to-speech models. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 10301–10305. IEEE,
2024
-
[17]
MegaTTS 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis
Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Jionghao Bai, Xiaoda Yang, Jialong Zuo, Yu Zhang, Rui Liu, Xiang Yin, and Zhou Zhao. MegaTTS 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis. arXiv preprint arXiv:2502.18924,
-
[18]
Kimi Team. Kimi-Audio technical report. arXiv preprint arXiv:2504.18425,
-
[19]
Prompttts 2: Describing and generating voices with text prompt
Yichong Leng, Zhifang Guo, Kai Shen, Zeqian Ju, Xu Tan, Eric Liu, Yufei Liu, Dongchao Yang, Kaitao Song, Lei He, et al. Prompttts 2: Describing and generating voices with text prompt. In International Conference on Learning Representations, volume 2024, pp. 57672–57688,
2024
-
[20]
Fish audio s2 technical report
Shijia Liao, Yuxuan Wang, Songting Liu, Yifan Cheng, Ruoyi Zhang, Tianyu Li, Shidong Li, Yisheng Zheng, Xingwei Liu, Qingzheng Wang, et al. Fish audio s2 technical report. arXiv preprint arXiv:2603.08823,
-
[21]
V oxtral tts.arXiv preprint arXiv:2603.25551,
Alexander H Liu, Alexis Tacnet, Andy Ehrenberg, Andy Lo, Chen-Yo Sun, Guillaume Lample, Henry Lagarde, Jean-Malo Delignon, Jaeyoung Kim, John Harvill, et al. V oxtral tts.arXiv preprint arXiv:2603.25551,
-
[22]
Promptstyle: Controllable style transfer for text-to-speech with natural language descriptions
Guanghou Liu, Yongmao Zhang, Yi Lei, Yunlin Chen, Rui Wang, Lei Xie, and Zhifei Li. Promptstyle: Controllable style transfer for text-to-speech with natural language descriptions. In Proc. Interspeech 2023, pp. 4888–4892,
2023
-
[23]
Natural language guidance of high-fidelity text-to-speech with synthetic annotations
Dan Lyth and Simon King. Natural language guidance of high-fidelity text-to-speech with synthetic annotations. arXiv preprint arXiv:2402.01912,
-
[24]
Magic-tts: Fine-grained controllable speech synthesis with explicit local duration and pause control
Jialong Mai, Xiaofen Xing, and Xiangmin Xu. Magic-tts: Fine-grained controllable speech synthesis with explicit local duration and pause control. arXiv preprint arXiv:2604.21164,
-
[26]
Zhiliang Peng, Jianwei Yu, Wenhui Wang, Yaoyao Chang, Yutao Sun, Li Dong, Yi Zhu, Weijiang Xu, Hangbo Bao, Zehua Wang, et al. Vibevoice technical report. arXiv preprint arXiv:2508.19205,
-
[27]
Ov-instructtts: Towards open-vocabulary instruct text-to-speech
Yong Ren, Jiangyan Yi, Jianhua Tao, Haiyang Sun, Zhengqi Wen, Hao Gu, Le Xu, and Ye Bai. Ov-instructtts: Towards open-vocabulary instruct text-to-speech. arXiv preprint arXiv:2601.01459,
-
[28]
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions
Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 4779–4783. IEEE,
2018
-
[29]
Minicpm4: Ultra-efficient llms on end devices
MiniCPM Team, Chaojun Xiao, Yuxuan Li, Xu Han, Yuzhuo Bai, Jie Cai, Haotian Chen, Wentong Chen, Xin Cong, Ganqu Cui, et al. Minicpm4: Ultra-efficient llms on end devices. arXiv preprint arXiv:2506.07900,
-
[30]
Step-audio-r1 technical report
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, et al. Step-audio-r1 technical report. arXiv preprint arXiv:2511.15848,
-
[31]
Speech synthesis from continuous features using per-token latent diffusion
Arnon Turetzky, Avihu Dekel, Nimrod Shabtay, Slava Shechtman, David Haws, Hagai Aronowitz, Ron Hoory, and Yossi Adi. Speech synthesis from continuous features using per-token latent diffusion. In 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 1–8. IEEE,
2025
-
[32]
Audiobox: Unified audio generation with natural language prompts
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. Audiobox: Unified audio generation with natural language prompts. arXiv preprint arXiv:2312.15821,
-
[33]
Capspeech: Enabling downstream applications in style-captioned text-to-speech
Helin Wang, Jiarui Hai, Dading Chong, Karan Thakkar, Tiantian Feng, Dongchao Yang, Junhyeok Lee, Thomas Thebaud, Laureano Moro Velazquez, Jesus Villalba, et al. Capspeech: Enabling downstream applications in style-captioned text-to-speech. arXiv preprint arXiv:2506.02863, 2025a. Hui Wang, Shujie Liu, Lingwei Meng, Jinyu Li, Yifan Yang, Shiwan Zhao, Haiyan...
-
[34]
Clear: Continuous latent autoregressive modeling for high-quality and low-latency speech synthesis
Chun Yat Wu, Jiajun Deng, Guinan Li, Qiuqiang Kong, and Simon Lui. Clear: Continuous latent autoregressive modeling for high-quality and low-latency speech synthesis. arXiv preprint arXiv:2508.19098,
-
[35]
Fireredtts-2: Towards long conversational speech generation for podcast and chatbot
Kun Xie, Feiyu Shen, Junjie Li, Fenglong Xie, Xu Tang, and Yao Hu. Fireredtts-2: Towards long conversational speech generation for podcast and chatbot. arXiv preprint arXiv:2509.02020, 2025a. Tianxin Xie, Yan Rong, Pengfei Zhang, Wenwu Wang, and Li Liu. Towards controllable speech synthesis in the era of large language models: A systematic survey. In Proc...
arXiv 2025
-
[36]
Longcat-audiodit: High-fidelity diffusion text-to-speech in the waveform latent space
Detai Xin, Shujie Hu, Chengzuo Yang, Chen Huang, Guoqiao Yu, Guanglu Wan, and Xunliang Cai. Longcat-audiodit: High-fidelity diffusion text-to-speech in the waveform latent space. arXiv preprint arXiv:2603.29339,
-
[37]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2. 5-omni technical report. arXiv preprint arXiv:2503.20215, 2025a. Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report. arXiv preprint arX...
-
[38]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, et al. Codec does matter: Exploring the semantic shortcoming of codec for audio language model. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 25697–25705, 2025a. Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng ...
-
[39]
Minimax-speech: Intrinsic zero-shot text-to-speech with a learnable speaker encoder
Bowen Zhang, Congchao Guo, Geng Yang, Hang Yu, Haozhe Zhang, Heidi Lei, Jialong Mai, Junjie Yan, Kaiyue Yang, Mingqi Yang, et al. Minimax-speech: Intrinsic zero-shot text-to-speech with a learnable speaker encoder. arXiv preprint arXiv:2505.07916, 2025a. – 25 – V oxCPM2 Dong Zhang, Gang Wang, Jinlong Xue, Kai Fang, Liang Zhao, Rui Ma, Shuhuai Ren, Shuo Li...
arXiv 2024
-
[40]
V oxcpm: Tokenizer-free tts for context-aware speech generation and true-to-life voice cloning
Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, et al. V oxcpm: Tokenizer-free tts for context-aware speech generation and true-to-life voice cloning. arXiv preprint arXiv:2509.24650,
-
[41]
Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, et al. Hierarchical semantic-acoustic modeling via semi-discrete residual representations for expressive end-to-end speech synthesis. In The Fourteenth International Conference on Learning Representations, 2026b. Han Zhu, Wei Kang, Zengw...
-
[42]
Omnivoice: Towards omnilingual zero-shot text-to-speech with diffusion language models
Han Zhu, Lingxuan Ye, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhifeng Han, Weiji Zhuang, Long Lin, and Daniel Povey. Omnivoice: Towards omnilingual zero-shot text-to-speech with diffusion language models. arXiv preprint arXiv:2604.00688,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.