Mean-field imitation dynamics on fast assortative networks
Pith reviewed 2026-06-27 09:09 UTC · model grok-4.3
The pith
In the mean-field limit of imitation dynamics on fast assortative networks, stochastic updates produce unique linearly stable cooperative stationary distributions under sufficient noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
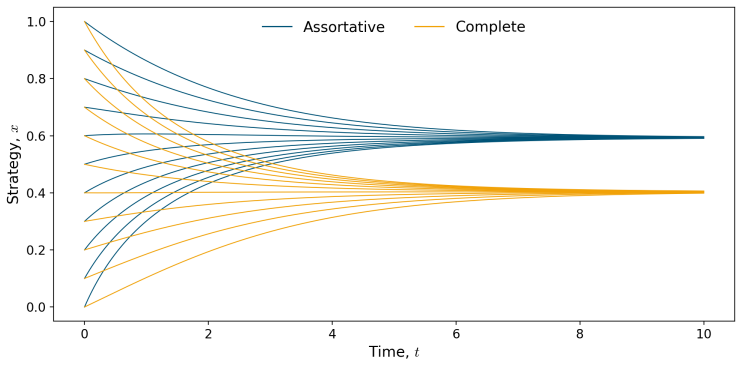
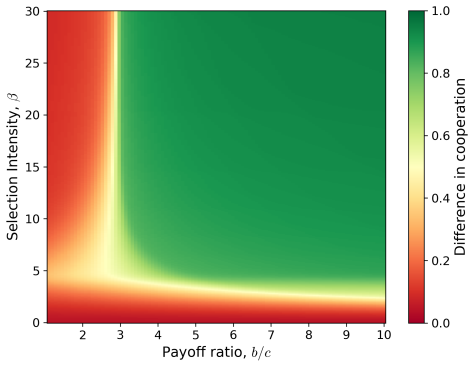
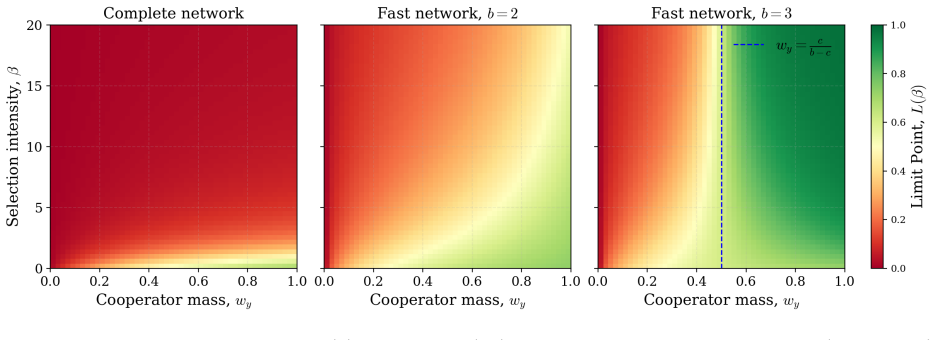
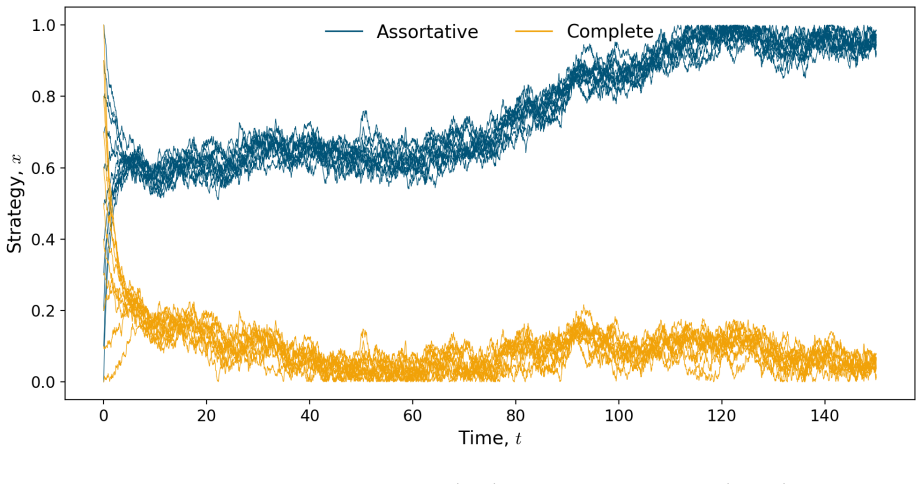
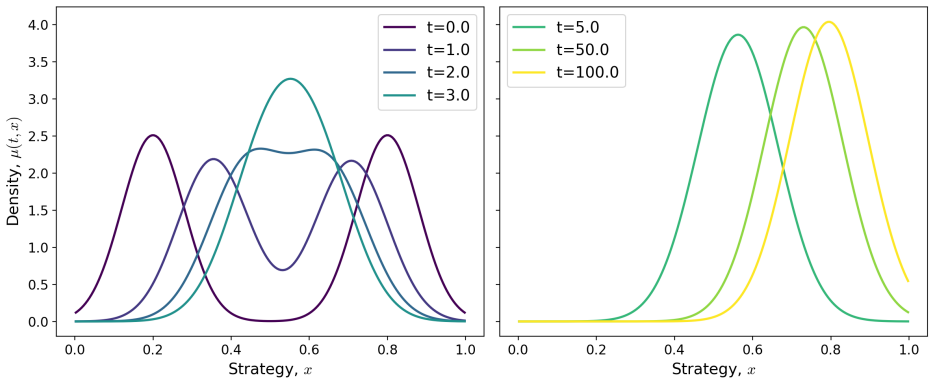
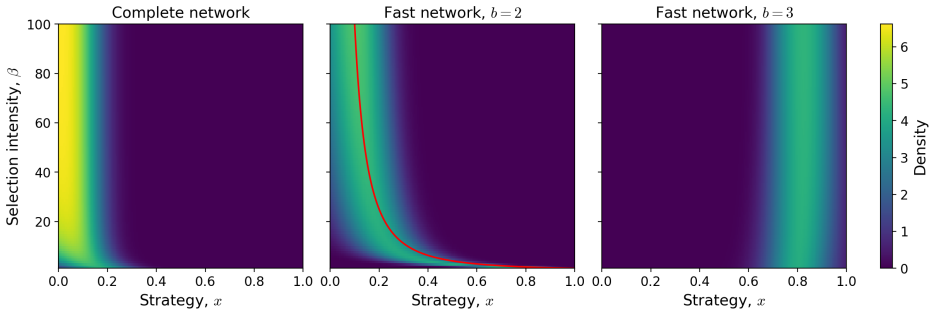
Without noise the mean-field limit is well-posed and collapses to a single Dirac mass. For initially separated clusters a payoff threshold and sufficient conditions are given under which overall cooperation increases. With stochastic updates the limit is a non-local Fokker-Planck equation; existence and uniqueness of stationary distributions are proved, and linear stability holds under sufficient noise. Numerics show that noise converts the deterministic consensus into stable cooperative stationary behaviour.
What carries the argument
The non-local Fokker-Planck equation obtained after incorporating edge weights into the strategy evolution equation and passing to the mean-field limit.
If this is right
- Without noise every solution converges to a single Dirac mass.
- For initially separated clusters a payoff threshold controls whether mean cooperation rises.
- Sufficient noise guarantees existence, uniqueness and linear stability of stationary distributions.
- Numerical trajectories confirm that noise replaces deterministic consensus with stable cooperative states.
Where Pith is reading between the lines
- The payoff threshold identified for separated clusters could be checked by running finite-population agent-based simulations with controlled initial separation.
- The linear-stability result suggests that adding small random perturbations to strategy updates in real social networks might prevent collapse to uniform defection.
- The same fast-network reduction might be applied to other continuous-strategy games to test whether noise-assisted stability is specific to the Prisoner's Dilemma payoff structure.
Load-bearing premise
The network evolves fast enough that its edge weights can be folded into the strategy update rule before the large-population limit is taken.
What would settle it
A numerical simulation of the finite-agent stochastic process on the network whose long-time distribution deviates from the stationary solution of the derived Fokker-Planck equation when noise is large.
Figures
read the original abstract
The emergence of cooperation in structured populations is fundamental to the success of human societies. Physical and online networks can drive behavioural change by altering who people interact with, thereby modifying social pressures. In this paper, we study imitation dynamics in a population of self-interested agents playing a continuous strategy Prisoner's Dilemma on a dynamically evolving weighted network. In the fast-network regime, we incorporate the edge weights into the strategy evolution before deriving and analysing the large population mean-field limit. Without noise, we establish well-posedness and show the solution collapses to a single Dirac mass. For initially separated clusters, we identify a payoff threshold and sufficient conditions for the overall level of cooperation to increase. We then introduce stochastic strategy updates, and obtain a non-local Fokker-Planck equation in the mean-field limit. We rigorously prove existence and uniqueness of stationary distributions, and show linear stability under sufficient noise. Numerics illustrate that noise can transform the deterministic consensus into stable cooperative stationary behaviour. These findings show that the fast adaptive interactions and stochastic exploration can jointly support the emergence of stable cooperation at a population level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies imitation dynamics for a continuous-strategy Prisoner's Dilemma on dynamically evolving weighted networks in the fast-network regime. Edge weights are incorporated into the strategy evolution equation prior to passing to the large-population mean-field limit. Without noise the resulting deterministic equation is shown to be well-posed with solutions collapsing to a single Dirac mass; for initially separated clusters a payoff threshold is identified above which overall cooperation increases. With stochastic strategy updates the mean-field limit yields a non-local Fokker-Planck equation; existence and uniqueness of stationary distributions are proved together with linear stability under sufficient noise. Numerical illustrations indicate that noise can convert deterministic consensus into stable cooperative stationary states.
Significance. If the central derivations hold, the work supplies a rigorous mean-field treatment of how fast adaptive assortative networks and stochastic exploration jointly support stable cooperation, extending evolutionary game theory on networks with explicit control on the ordering of limits and stability analysis.
major comments (3)
- [§2] §2 (fast-network regime) and the derivation leading to the mean-field equation: the abstract and introduction state that edge weights are incorporated into the strategy evolution before the N→∞ limit is taken, yet no error estimate, commutativity argument, or uniform-in-N control is supplied to justify that this ordering produces the correct non-local Fokker-Planck equation; all subsequent well-posedness, collapse, and stability claims rest on this step.
- [Theorem on well-posedness] Theorem on well-posedness and Dirac-mass collapse (deterministic case): the abstract asserts these properties, but the precise function space, growth conditions on the payoff kernel, and the form of the integro-differential equation (likely Eq. (12) or (15)) are not stated explicitly enough to verify that the proof controls the collapse without additional assumptions that may fail for separated clusters.
- [Stationary distributions section] Existence/uniqueness and linear-stability results for the stationary distributions of the non-local Fokker-Planck equation: these are load-bearing for the claim that sufficient noise yields stable cooperative states, yet the manuscript supplies no explicit spectral-gap estimate or Lyapunov functional whose derivative is controlled uniformly in the non-local interaction term.
minor comments (2)
- Notation for the payoff function and imitation rate should be introduced once and used consistently; several symbols appear to be redefined between the deterministic and stochastic sections.
- The numerical section would benefit from a brief description of the discretization scheme and the number of Monte-Carlo realizations used to generate the reported trajectories.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive criticism. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§2] §2 (fast-network regime) and the derivation leading to the mean-field equation: the abstract and introduction state that edge weights are incorporated into the strategy evolution before the N→∞ limit is taken, yet no error estimate, commutativity argument, or uniform-in-N control is supplied to justify that this ordering produces the correct non-local Fokker-Planck equation; all subsequent well-posedness, collapse, and stability claims rest on this step.
Authors: We agree that an explicit justification for the ordering of limits is desirable. The derivation in §2 first modifies the finite-N imitation dynamics to include the evolving edge weights and only then passes to the mean-field limit; this ordering is built into the model statement. However, the manuscript does not supply quantitative error bounds or a commutativity argument. In the revision we will add a dedicated remark (or short appendix) that (i) recalls the standard propagation-of-chaos framework used for fast adaptive networks, (ii) states the precise assumptions on the weight-update rule under which the limit equation is expected to hold, and (iii) cites comparable results in the literature. We do not claim that a full uniform-in-N control is already present, so this constitutes a partial revision. revision: partial
-
Referee: [Theorem on well-posedness] Theorem on well-posedness and Dirac-mass collapse (deterministic case): the abstract asserts these properties, but the precise function space, growth conditions on the payoff kernel, and the form of the integro-differential equation (likely Eq. (12) or (15)) are not stated explicitly enough to verify that the proof controls the collapse without additional assumptions that may fail for separated clusters.
Authors: The well-posedness result appears in Section 3 and concerns the continuity equation (12) on the space of probability measures with finite first moment; the payoff kernel is assumed continuous and bounded. The collapse statement for initially separated clusters is conditional on the payoff threshold identified in the text. We acknowledge that the theorem statement could be more self-contained. In the revision we will (i) restate the precise function space and kernel assumptions at the beginning of the theorem, (ii) clarify that the velocity field remains Lipschitz under the stated boundedness, and (iii) add a short paragraph explaining why the separated-cluster case does not require extra assumptions beyond those already listed. These changes will be made explicitly. revision: yes
-
Referee: [Stationary distributions section] Existence/uniqueness and linear-stability results for the stationary distributions of the non-local Fokker-Planck equation: these are load-bearing for the claim that sufficient noise yields stable cooperative states, yet the manuscript supplies no explicit spectral-gap estimate or Lyapunov functional whose derivative is controlled uniformly in the non-local interaction term.
Authors: Existence and uniqueness of stationary measures are obtained via a fixed-point argument on the space of probability measures. Linear stability is shown by linearizing the non-local Fokker-Planck operator and verifying that the principal eigenvalue is negative once the diffusion coefficient exceeds a threshold depending on the interaction strength. The proof controls the nonlocal term by absorbing it into the diffusion; an explicit spectral-gap constant or a global Lyapunov functional is not constructed. We will add a clarifying remark that explains this absorption argument and, if space permits, include a brief numerical check of the decay rate. Should the referee require a quantitative gap estimate, we note that deriving one would necessitate stronger assumptions on the kernel and would constitute additional technical work beyond the present scope. revision: partial
Circularity Check
No significant circularity; derivations are self-contained mathematical limits and analysis
full rationale
The paper derives a mean-field limit from imitation dynamics under a fast-network regime assumption, then proves well-posedness, Dirac collapse without noise, existence/uniqueness of stationary distributions with noise, and linear stability. These are presented as rigorous analysis of the resulting non-local Fokker-Planck equation rather than reductions to fitted parameters, self-definitions, or self-citation chains. No load-bearing steps equate outputs to inputs by construction, and the central claims rest on independent mathematical arguments. The fast-network regime is stated as the modeling choice under study, not smuggled via prior self-work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Convergence of Replicator Dynamics in the Repeated Prisoner's Dilemma with Restarts
In the repeated Prisoner's Dilemma with trigger-restart, longer strategy lengths enable stability of cooperative strategies under replicator dynamics, with stable sequences requiring an initial 'hazing period' of defe...
Reference graph
Works this paper leans on
-
[1]
Five rules for the evolution of cooperation
Martin A. Nowak. “Five rules for the evolution of cooperation”. In:Science (New York, N.y.)314.5805 (Dec. 2006), pp. 1560–1563.issn: 0036-8075.doi:10.1126/science.1133755.url:https://pmc. ncbi.nlm.nih.gov/articles/PMC3279745/
-
[2]
Public Goods, Prisoners’ Dilemmas and the International Political Economy
John A. C. Conybeare. “Public Goods, Prisoners’ Dilemmas and the International Political Economy”. In:International Studies Quarterly28.1 (Mar. 1984), pp. 5–22.issn: 0020-8833.doi:10.2307/2600395. url:https://doi.org/10.2307/2600395
-
[3]
Tax evasion and the prisoner’s dilemma
Daniel Gottlieb. “Tax evasion and the prisoner’s dilemma”. In:Mathematical Social Sciences10.1 (Aug. 1985), pp. 81–89.issn: 0165-4896.doi:10 . 1016 / 0165 - 4896(85 ) 90039 - 3.url:https : //www.sciencedirect.com/science/article/pii/0165489685900393
arXiv 1985
-
[4]
How evolutionary game could solve the human vaccine dilemma
K. M. Ariful Kabir. “How evolutionary game could solve the human vaccine dilemma”. In:Chaos, Solitons & Fractals152 (Nov. 2021), p. 111459.issn: 0960-0779.doi:10.1016/j.chaos.2021.111459. url:https://www.sciencedirect.com/science/article/pii/S0960077921008134
-
[5]
Dynamic social networks promote cooperation in experiments with humans
David G. Rand, Samuel Arbesman, and Nicholas A. Christakis. “Dynamic social networks promote cooperation in experiments with humans”. en. In:Proceedings of the National Academy of Sciences 108.48 (Nov. 2011), pp. 19193–19198.issn: 0027-8424, 1091-6490.doi:10.1073/pnas.1108243108. url:https://pnas.org/doi/full/10.1073/pnas.1108243108
-
[6]
Cooperation Prevails When Individuals Adjust Their Social Ties
Francisco C Santos, Jorge M Pacheco, and Tom Lenaerts. “Cooperation Prevails When Individuals Adjust Their Social Ties”. en. In:PLoS Computational Biology2.10 (Oct. 2006). Ed. by Luis Amaral, e140.issn: 1553-7358.doi:10.1371/journal.pcbi.0020140.url:https://dx.plos.org/10.1371/ journal.pcbi.0020140
work page doi:10.1371/journal.pcbi.0020140.url:https://dx.plos.org/10.1371/ 2006
-
[7]
Enabling imitation-based cooperation in dy- namic social networks
Jacques Bara, Paolo Turrini, and Giulia Andrighetto. “Enabling imitation-based cooperation in dy- namic social networks”. en. In:Autonomous Agents and Multi-Agent Systems36.2 (May 2022), p. 34. issn: 1573-7454.doi:10.1007/s10458- 022- 09562- w.url:https://doi.org/10.1007/s10458- 022-09562-w
-
[8]
Evolution of cooperation on large networks with community structure
Babak Fotouhi et al. “Evolution of cooperation on large networks with community structure”. In: Journal of The Royal Society Interface16.152 (Mar. 2019), p. 20180677.issn: 1742-5689.doi:10. 1098/rsif.2018.0677.url:https://doi.org/10.1098/rsif.2018.0677
-
[9]
A simple rule for the evolution of cooperation on graphs and social networks
Hisashi Ohtsuki et al. “A simple rule for the evolution of cooperation on graphs and social networks”. en. In:Nature441.7092 (May 2006), pp. 502–505.issn: 1476-4687.doi:10.1038/nature04605.url: https://www.nature.com/articles/nature04605
-
[10]
Scale-Free Networks Provide a Unifying Framework for the Emergence of Cooperation
F. C. Santos and J. M. Pacheco. “Scale-Free Networks Provide a Unifying Framework for the Emergence of Cooperation”. en. In:Physical Review Letters95.9 (Aug. 2005), p. 098104.issn: 0031-9007, 1079- 7114.doi:10 . 1103 / PhysRevLett . 95 . 098104.url:https : / / link . aps . org / doi / 10 . 1103 / PhysRevLett.95.098104
2005
-
[11]
Prosocial Orientation Alters Network Dynamics and Fosters Cooperation
David Melamed, Brent Simpson, and Ashley Harrell. “Prosocial Orientation Alters Network Dynamics and Fosters Cooperation”. en. In:Scientific Reports7.1 (Mar. 2017), p. 357.issn: 2045-2322.doi: 10.1038/s41598-017-00265-x.url:https://www.nature.com/articles/s41598-017-00265-x
work page doi:10.1038/s41598-017-00265-x.url:https://www.nature.com/articles/s41598-017-00265-x 2017
-
[12]
Co-evolution of behaviour and social network structure promotes human cooperation
Katrin Fehl, Daniel J. van der Post, and Dirk Semmann. “Co-evolution of behaviour and social network structure promotes human cooperation”. eng. In:Ecology Letters14.6 (June 2011), pp. 546–551.issn: 1461-0248.doi:10.1111/j.1461-0248.2011.01615.x. Page 18
-
[13]
Opting out against defection leads to stable coexistence with cooperation
Bo-Yu Zhang et al. “Opting out against defection leads to stable coexistence with cooperation”. In: Scientific Reports6 (Oct. 2016), p. 35902.issn: 2045-2322.doi:10.1038/srep35902.url:https: //www.ncbi.nlm.nih.gov/pmc/articles/PMC5075917/
-
[14]
Anastassacos, S
N. Anastassacos, S. Hailes, and M. Musolesi.Partner Selection for the Emergence of Cooperation in Multi-Agent Systems Using Reinforcement Learning. eng. Proceedings paper. Conference Name: Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20) Meeting Name: Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20) Place: New York City...
2020
-
[15]
Luis R Izquierdo, Segismundo S Izquierdo, and Robert Boyd.Successful strategies in the voluntarily repeated Prisoner’s Dilemma. en. 2026.doi:10.64898/2026.01.16.699891
-
[16]
Learning Partner Selection Rules that Sustain Cooperation in Social Dilemmas with the Option of Opting Out
Chin-wing Leung. “Learning Partner Selection Rules that Sustain Cooperation in Social Dilemmas with the Option of Opting Out”. en. In:New Zealand(2024)
2024
-
[17]
Xiaoqing Fan, Chin-wing Leung, and Paolo Turrini. “Co-learning of strategy and structure achieves full cooperation in complex networks with dynamical linking”. In:34th International Joint Conference on Artificial Intelligence. In Press. International Joint Conferences on Artificial Intelligence Organization, Aug. 2025, pp. 72–80.doi:10.24963/ijcai.2025/9....
work page doi:10.24963/ijcai.2025/9.url:https://doi.org/10.24963/ijcai 2025
-
[18]
Benedict Russell, Chin-wing Leung, and Paolo Turrini. “Defection at first sight : learning partner selection in optional social dilemmas without prior information”. In:25th International Conference on Autonomous Agents and Multiagent Systems. In Press. IFAAMAS; ACM Digital library, May 2026. doi:10.65109/IBSZ1473.url:https://doi.org/10.65109/IBSZ1473
work page doi:10.65109/ibsz1473.url:https://doi.org/10.65109/ibsz1473 2026
-
[19]
Repeated games with partner choice
Christopher Graser et al. “Repeated games with partner choice”. en. In:PLOS Computational Biology 21.2 (Feb. 2025), e1012810.issn: 1553-7358.doi:10 . 1371 / journal . pcbi . 1012810.url:https : //journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1012810
-
[20]
Active linking in evolutionary games
Jorge M. Pacheco, Arne Traulsen, and Martin A. Nowak. “Active linking in evolutionary games”. In: Journal of Theoretical Biology243.3 (Dec. 2006), pp. 437–443.issn: 0022-5193.doi:10.1016/j.jtbi. 2006.06.027.url:https://www.sciencedirect.com/science/article/pii/S0022519306002736
-
[21]
Coevolution of Cooperation, Response to Adverse Social Ties and Network Structure
Sven Van Segbroeck et al. “Coevolution of Cooperation, Response to Adverse Social Ties and Network Structure”. en. In:Games1.3 (Sept. 2010), pp. 317–337.issn: 2073-4336.doi:10.3390/g1030317. url:https://www.mdpi.com/2073-4336/1/3/317
-
[22]
Xiu-Deng Zheng et al. “A simple rule of direct reciprocity leads to the stable coexistence of cooperation and defection in the Prisoner’s Dilemma game”. en. In:Journal of Theoretical Biology420 (May 2017), pp. 12–17.issn: 00225193.doi:10.1016/j.jtbi.2017.02.036.url:https://linkinghub. elsevier.com/retrieve/pii/S0022519317300991
work page doi:10.1016/j.jtbi.2017.02.036.url:https://linkinghub 2017
-
[23]
Benedict Russell, Chin-wing Leung, and Paolo Turrini.The Dynamics of Policy Gradient in Social Dilemmas with Partner Selection. 2026. arXiv:2605.18185.url:https://arxiv.org/abs/2605. 18185
Pith/arXiv arXiv 2026
-
[24]
Leave and let leave: A sufficient condition to explain the evolutionary emergence of cooperation
Luis R. Izquierdo, Segismundo S. Izquierdo, and Fernando Vega-Redondo. “Leave and let leave: A sufficient condition to explain the evolutionary emergence of cooperation”. In:Journal of Economic Dynamics and Control46 (Sept. 2014), pp. 91–113.issn: 0165-1889.doi:10.1016/j.jedc.2014.06. 007.url:https://www.sciencedirect.com/science/article/pii/S0165188914001456
-
[25]
On evolving network models and their influence on opinion formation
Andrew Nugent, Susana N. Gomes, and Marie-Therese Wolfram. “On evolving network models and their influence on opinion formation”. In:Physica D: Nonlinear Phenomena456 (Dec. 2023), p. 133914. issn: 0167-2789.doi:10.1016/j.physd.2023.133914.url:https://www.sciencedirect.com/ science/article/pii/S0167278923002683
work page doi:10.1016/j.physd.2023.133914.url:https://www.sciencedirect.com/ 2023
-
[26]
Gomes.Emergent structures in coupled opinion and network dynamics
Andrew Nugent, Carmen Calatayud Fernandez, and Susana N. Gomes.Emergent structures in coupled opinion and network dynamics. 2026. arXiv:2602.03738.url:https://arxiv.org/abs/2602.03738
arXiv 2026
-
[27]
Continuum limits for adaptive network dynamics
Marios Antonios Gkogkas, Christian Kuehn, and Chuang Xu. “Continuum limits for adaptive network dynamics”. In:arXiv preprint arXiv:2109.05898(2021)
arXiv 2021
-
[28]
Mean-field and graph limits for collective dynamics models with time-varying weights
Nathalie Ayi and Nastassia Pouradier Duteil. “Mean-field and graph limits for collective dynamics models with time-varying weights”. In:Journal of Differential Equations299 (2021), pp. 65–110
2021
-
[29]
Bridging the gap between agent based models and continuous opinion dynamics
Andrew Nugent, Susana N Gomes, and Marie-Therese Wolfram. “Bridging the gap between agent based models and continuous opinion dynamics”. In:Physica A: Statistical Mechanics and its Applications 651 (2024), p. 129886
2024
-
[30]
Network adaption based on environment feedback promotes cooperation in co- evolutionary games
Yujie Guo et al. “Network adaption based on environment feedback promotes cooperation in co- evolutionary games”. In:Physica A: Statistical Mechanics and its Applications617 (May 2023), p. 128689. issn: 0378-4371.doi:10.1016/j.physa.2023.128689.url:https://www.sciencedirect.com/ science/article/pii/S0378437123002443
work page doi:10.1016/j.physa.2023.128689.url:https://www.sciencedirect.com/ 2023
-
[31]
Propagation of chaos: A review of models, methods and applications. I. Models and methods
Louis-Pierre Chaintron and Antoine Diez. “Propagation of chaos: A review of models, methods and applications. I. Models and methods”. In:Kinetic and Related Models15.6 (2022), pp. 895–1015. Page 19 issn: 1937-5093.doi:10.3934/krm.2022017.url:https://www.aimsciences.org/article/id/ 631fd3b64cedfd0007ce7600
work page doi:10.3934/krm.2022017.url:https://www.aimsciences.org/article/id/ 2022
-
[32]
Jan Haskovec. “Flocking dynamics and mean-field limit in the Cucker–Smale-type model with topo- logical interactions”. In:Physica D: Nonlinear Phenomena261 (2013), pp. 42–51.issn: 0167-2789. doi:https://doi.org/10.1016/j.physd.2013.06.006.url:https://www.sciencedirect.com/ science/article/pii/S0167278913001796
work page doi:10.1016/j.physd.2013.06.006.url:https://www.sciencedirect.com/ 2013
-
[33]
Modelling the Dynamics of Multiagent Q-Learning in Repeated Symmetric Games: a Mean Field Theoretic Approach
Shuyue Hu, Chin-wing Leung, and Ho-fung Leung. “Modelling the Dynamics of Multiagent Q-Learning in Repeated Symmetric Games: a Mean Field Theoretic Approach”. In:Advances in Neural Information Processing Systems. Ed. by H. Wallach et al. Vol. 32. Curran Associates, Inc., 2019.url:https:// proceedings.neurips.cc/paper_files/paper/2019/file/40afd3a37cca05ef...
2019
-
[34]
Chin-wing Leung, Shuyue Hu, and Ho-fung Leung. “Modelling the Dynamics of Multi-Agent Q- learning: The Stochastic Effects of Local Interaction and Incomplete Information”. en. In:Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence. Vienna, Austria: Interna- tional Joint Conferences on Artificial Intelligence Organizat...
work page doi:10.24963/ijcai.2022/55.url:https://www.ijcai.org/proceedings/2022/55 2022
-
[35]
Opinion dynamics with continuous age structure
Andrew Nugent, Susana N Gomes, and Marie-Therese Wolfram. “Opinion dynamics with continuous age structure”. In:European Journal of Applied Mathematics(2025), pp. 1–36
2025
-
[36]
InProceedings of the 15th ACM SIGPLAN-SIGACT symposium on Principles of programming languages
Rene Carmona and Fran¸ cois Delarue.Probabilistic Theory of Mean Field Games with Applications I : Mean Field FBSDEs, Control, and Games. Springer, Jan. 2018.doi:doi.org/10.1007/978-3-319- 58920-6
-
[37]
Linking Individual and Collective Behavior in Adaptive Social Networks
Fl´ avio L. Pinheiro, Francisco C. Santos, and Jorge M. Pacheco. “Linking Individual and Collective Behavior in Adaptive Social Networks”. en. In:Physical Review Letters116.12 (Mar. 2016), p. 128702. issn: 0031-9007, 1079-7114.doi:10.1103/PhysRevLett.116.128702.url:https://link.aps.org/ doi/10.1103/PhysRevLett.116.128702
work page doi:10.1103/physrevlett.116.128702.url:https://link.aps.org/ 2016
-
[38]
Heterophilious dynamics enhances consensus
Sebastien Motsch and Eitan Tadmor. “Heterophilious dynamics enhances consensus”. In:SIAM review 56.4 (2014), pp. 577–621
2014
-
[39]
Emergence of polarization in a sigmoidal bounded-confidence model of opinion dynamics
Heather Z Brooks, Philip S Chodrow, and Mason A Porter. “Emergence of polarization in a sigmoidal bounded-confidence model of opinion dynamics”. In:SIAM Journal on Applied Dynamical Systems 23.2 (2024), pp. 1442–1470
2024
-
[40]
Collective memory and spatial sorting in animal groups
Iain D Couzin et al. “Collective memory and spatial sorting in animal groups”. In:Journal of theoretical biology218.1 (2002), pp. 1–11
2002
-
[41]
Evolution of cooperation on temporal networks
Aming Li et al. “Evolution of cooperation on temporal networks”. en. In:Nature Communications 11.1 (May 2020), p. 2259.issn: 2041-1723.doi:10 . 1038 / s41467 - 020 - 16088 - w.url:https : //www.nature.com/articles/s41467-020-16088-w
2020
-
[42]
Grigorios A. Pavliotis and Andrew M. Stuart.Multiscale Methods: Averaging and Homogenization. Springer, 2008.isbn: 978-0-387-73829-1.doi:10.1007/978-0-387-73829-1
-
[43]
Mean Field Limit for Stochastic Particle Systems
Pierre-Emmanuel Jabin and Zhenfu Wang. “Mean Field Limit for Stochastic Particle Systems”. en. In:Active Particles, Volume 1. Series Title: Modeling and Simulation in Science, Engineering and Technology. Cham: Springer International Publishing, 2017, pp. 379–402.isbn: 978-3-319-49994-9 978- 3-319-49996-3.doi:10.1007/978-3-319-49996-3_10.url:http://link.sp...
work page doi:10.1007/978-3-319-49996-3_10.url:http://link.springer.com/10.1007/ 2017
-
[44]
The Pontryagin Maximum Principle in the Wasserstein Space
Benoˆ ıt Bonnet and Francesco Rossi. “The Pontryagin Maximum Principle in the Wasserstein Space”. In:Calculus of Variations and Partial Differential Equations58 (2017), pp. 1–36.url:https://api. semanticscholar.org/CorpusID:23997334
2017
-
[45]
Asymptotic behaviour of some interacting particle systems; McKean-Vlasov and Boltzmann models
Sylvie M´ el´ eard. “Asymptotic behaviour of some interacting particle systems; McKean-Vlasov and Boltzmann models”. en. In:Probabilistic Models for Nonlinear Partial Differential Equations: Lectures given at the 1st Session of the Centro Internazionale Matematico Estivo (C.I.M.E.) held in Montecatini Terme, Italy, May 22–30, 1995. Ed. by Carl Graham et a...
work page doi:10.1007/bfb0093177.url:https://doi.org/10.1007/bfb0093177 1995
-
[47]
J. L. Lions and E. Magenes.Non-Homogeneous Boundary Value Problems and Applications. Vol. 1. Springer, 1972
1972
-
[48]
Static network structure can stabilize human cooperation
David G. Rand et al. “Static network structure can stabilize human cooperation”. In:Proceedings of the National Academy of Sciences111.48 (Dec. 2014), pp. 17093–17098.doi:10.1073/pnas.1400406111. url:https://www.pnas.org/doi/10.1073/pnas.1400406111. Page 20
-
[49]
DOI: 10.1007/978- 3-031-99155-4
C´ edric Villani. “The Wasserstein distances”. In:Optimal Transport: Old and New. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 93–111.isbn: 978-3-540-71050-9.doi:10.1007/978- 3- 540- 71050-9_6.url:https://doi.org/10.1007/978-3-540-71050-9_6
-
[50]
Walter Rudin.Principles of Mathematical Analysis. 3rd ed. McGraw-Hill, 1976.isbn: 978-0070856134
1976
-
[51]
1 ki NX j=1 aijpx(xi, xj)(xj −x i) # = 1 N NX i=1 φ′(xi)
Lawrence C Evans.Partial differential equations. Vol. 19. American Mathematical Society, 2022. Page 21 A Additional derivations The full mean-field derivation reads Z Ω ∂tµ(t, x)φ(x)dx = d dt Z Ω 1 N NX i=1 δxi(x)φ(x)dx = d dt 1 N NX i=1 φ(xi) = 1 N NX i=1 φ′(xi) dxi dt = 1 N NX i=1 φ′(xi) " 1 ki NX j=1 aijpx(xi, xj)(xj −x i) # = 1 N NX i=1 φ′(xi) " 1P k=...
2022
-
[52]
This condition is (b−c)m µ(t)−c(y+z)≥0 (b−c)w z −c z+ (b−c)w y −c y≥0 α1z+α 2y≥0 whereα 1 := (b−c)w z −candα 2 := (b−c)w y −c. The define the region X={(z, y) : 0≤z≤y≤1, α 1z+α 2y≥0} Then the time derivative of the boundary line is dS dt =α 1 dz dt +α 2 dy dt = (y2 −z 2) α1wypµ(z, y) z+m µ − α2wz(1−p µ(z, y)) y+m µ Now substitutep µ(z, y) = 1 2 andα 2 =−α...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.