Evaluating Protein Transfer Learning with TAPE
Pith reviewed 2026-05-25 20:12 UTC · model grok-4.3
The pith
Self-supervised pretraining more than doubles performance on protein tasks but still lags non-neural methods in several cases
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TAPE supplies five biologically relevant semi-supervised tasks with fixed splits; benchmarking across models demonstrates that self-supervised pretraining helps almost all of them on all tasks, more than doubling performance in some cases, yet the resulting features still trail state-of-the-art non-neural techniques on several tasks.
What carries the argument
TAPE benchmark: five semi-supervised protein tasks with curated splits that enforce biologically relevant generalization
If this is right
- Self-supervised pretraining will raise performance on the TAPE protein tasks for nearly all models.
- The persistent gap versus non-neural methods indicates a need for new architectures that better extract signal from biological sequences.
- Standardized TAPE splits will let future work measure whether innovations actually improve real-world protein generalization.
- Releasing all data and code will allow direct replication and extension of the reported comparisons.
Where Pith is reading between the lines
- Combining self-supervised embeddings with non-neural features could close part of the observed gap without new model design.
- The same pretraining-plus-benchmark pattern could be applied to other sequence domains such as RNA or small molecules.
- If the gap persists across future architectures, it may point to fundamental limits in what purely sequence-based models can capture from protein data.
Load-bearing premise
The curated training, validation, and test splits ensure that each task tests biologically relevant generalization that transfers to real-life scenarios.
What would settle it
A self-supervised model that matches or exceeds the best non-neural baseline on every TAPE task, or a controlled experiment showing pretraining yields no improvement on the same splits, would falsify the reported gap and benefit claims.
Figures



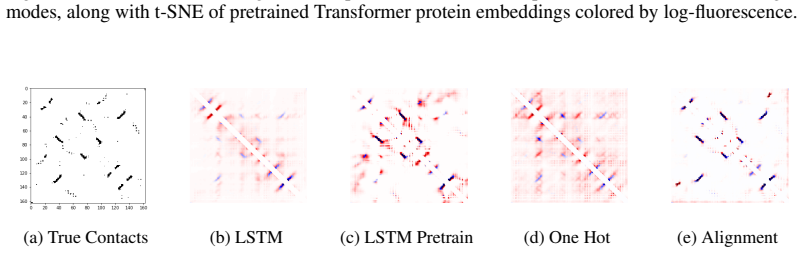
read the original abstract
Protein modeling is an increasingly popular area of machine learning research. Semi-supervised learning has emerged as an important paradigm in protein modeling due to the high cost of acquiring supervised protein labels, but the current literature is fragmented when it comes to datasets and standardized evaluation techniques. To facilitate progress in this field, we introduce the Tasks Assessing Protein Embeddings (TAPE), a set of five biologically relevant semi-supervised learning tasks spread across different domains of protein biology. We curate tasks into specific training, validation, and test splits to ensure that each task tests biologically relevant generalization that transfers to real-life scenarios. We benchmark a range of approaches to semi-supervised protein representation learning, which span recent work as well as canonical sequence learning techniques. We find that self-supervised pretraining is helpful for almost all models on all tasks, more than doubling performance in some cases. Despite this increase, in several cases features learned by self-supervised pretraining still lag behind features extracted by state-of-the-art non-neural techniques. This gap in performance suggests a huge opportunity for innovative architecture design and improved modeling paradigms that better capture the signal in biological sequences. TAPE will help the machine learning community focus effort on scientifically relevant problems. Toward this end, all data and code used to run these experiments are available at https://github.com/songlab-cal/tape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Tasks Assessing Protein Embeddings (TAPE) benchmark consisting of five semi-supervised learning tasks across protein biology domains. It curates task-specific train/validation/test splits to promote biologically relevant generalization, benchmarks a range of self-supervised pretraining approaches and canonical sequence models, and reports that pretraining improves performance on nearly all tasks (more than doubling it in some cases) yet still trails state-of-the-art non-neural feature extraction methods on several tasks.
Significance. If the central empirical patterns hold under properly controlled generalization, the work supplies a much-needed standardized benchmark and reproducible codebase (all data and code released at https://github.com/songlab-cal/tape) that can focus community effort on scientifically grounded protein modeling problems and quantify the remaining gap between learned embeddings and established non-neural techniques.
major comments (1)
- [Abstract / task curation] Abstract (task curation paragraph) and the corresponding methods section on split construction: the statement that splits were curated “to ensure that each task tests biologically relevant generalization” is not accompanied by quantitative details on the homology-reduction procedure (sequence-identity threshold, structural clustering method, or evolutionary distance cutoff). Because every reported performance number and the comparison to non-neural baselines rests on the assumption of genuine out-of-distribution generalization, the absence of these metrics leaves open the possibility of residual homology leakage that would invalidate the headline claims.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from an explicit forward reference to the exact section or table that lists the five tasks and their data sources.
- [Figures] Figure captions should state the number of independent runs or seeds used to generate error bars so that readers can assess statistical reliability of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on the TAPE benchmark. We agree that greater transparency on the quantitative aspects of split construction is important for validating the out-of-distribution generalization claims. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract / task curation] Abstract (task curation paragraph) and the corresponding methods section on split construction: the statement that splits were curated “to ensure that each task tests biologically relevant generalization” is not accompanied by quantitative details on the homology-reduction procedure (sequence-identity threshold, structural clustering method, or evolutionary distance cutoff). Because every reported performance number and the comparison to non-neural baselines rests on the assumption of genuine out-of-distribution generalization, the absence of these metrics leaves open the possibility of residual homology leakage that would invalidate the headline claims.
Authors: We appreciate the referee drawing attention to this. The original manuscript describes the split construction for each task in the Methods section (e.g., remote homology uses a 40% sequence-identity threshold with structural clustering via SCOPe; fluorescence and stability use evolutionary distance cutoffs derived from phylogenetic trees; secondary structure and contact prediction use standard train/test splits with additional homology filtering). However, we acknowledge that these details were not presented with sufficient quantitative precision or uniformity. In the revised version we will add a dedicated subsection (or expanded table) that explicitly lists, for every task: (i) the sequence-identity threshold applied, (ii) the clustering algorithm or database used, (iii) any evolutionary-distance or structural criteria, and (iv) the resulting train/validation/test sizes after filtering. This will make the homology-reduction procedure fully reproducible and directly address the concern about possible leakage. revision: yes
Circularity Check
No circularity; results are direct empirical measurements
full rationale
The paper is an empirical benchmark study that reports performance numbers obtained by training and evaluating models on externally defined tasks and splits. No result is obtained by fitting a parameter to a subset of the data and then relabeling that fit as a prediction, nor does any central claim reduce to a self-citation chain or to a quantity defined in terms of itself. The curation of splits is presented as a methodological decision whose validity is left to external scrutiny; it is not derived from any equation or prior result internal to the paper. All comparisons to non-neural baselines are likewise direct measurements against independent reference methods.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The curated training, validation, and test splits test biologically relevant generalization that transfers to real-life scenarios.
Forward citations
Cited by 2 Pith papers
-
Distribution-Aware Reward: Reinforcement Learning over Predictive Distributions for LLM Regression
Distribution-Aware Reward optimizes LLM regression by treating rollouts as empirical predictive distributions and rewarding marginal improvements in CRPS quality rather than point accuracy alone.
-
ProteinJEPA: Latent prediction complements protein language models
Masked-position MLM plus JEPA latent prediction outperforms MLM-only pretraining on 10-11 of 16 downstream tasks for 35M-150M protein models while JEPA alone fails.
Reference graph
Works this paper leans on
-
[1]
UniProt: a worldwide hub of protein knowledge
The UniProt Consortium. UniProt: a worldwide hub of protein knowledge. Nucleic Acids Research, 47(D1):D506–D515, 2018
work page 2018
-
[2]
The kinetics of formation of native ribonuclease during oxidation of the reduced polypeptide chain
C B Anfinsen, E Haber, M Sela, F H White, and Jr. The kinetics of formation of native ribonuclease during oxidation of the reduced polypeptide chain. Proceedings of the National Academy of Sciences of the United States of America, 47(9):1309–14, 1961
work page 1961
-
[3]
Protein Structure Relationships Revealed by Mutational Analysis
C Yanofsky, V Horn, and D Thorpe. Protein Structure Relationships Revealed by Mutational Analysis. Science (New York, N.Y.), 146(3651):1593–4, 1964
work page 1964
-
[4]
Coordinated amino acid changes in homologous protein families
D Altschuh, T Vernet, P Berti, D Moras, and K Nagai. Coordinated amino acid changes in homologous protein families. Protein engineering, 2(3):193–9, 1988
work page 1988
-
[5]
Deep Contextualized Word Representations
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–2237, New Orleans, Lo...
work page 2018
-
[6]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv, 2018
work page 2018
-
[7]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1:8, 2019
work page 2019
-
[8]
Timothy A Whitehead, Aaron Chevalier, Yifan Song, Cyrille Dreyfus, Sarel J Fleishman, Cecilia De Mattos, Chris A Myers, Hetunandan Kamisetty, Patrick Blair, Ian A Wilson, et al. Optimization of affinity, specificity and function of designed influenza inhibitors using deep sequencing. Nature biotechnology, 30(6):543, 2012
work page 2012
-
[9]
Modular protein engineering in emerging cancer therapies
Esther Vazquez, Neus Ferrer-Miralles, Ramon Mangues, Jose L Corchero, Jr Schwartz, An- tonio Villaverde, et al. Modular protein engineering in emerging cancer therapies. Current pharmaceutical design, 15(8):893–916, 2009
work page 2009
-
[10]
Nelson Perdigão, Julian Heinrich, Christian Stolte, Kenneth S. Sabir, Michael J. Buckley, Bruce Tabor, Beth Signal, Brian S. Gloss, Christopher J. Hammang, Burkhard Rost, Andrea Schafferhans, and Seán I. O’Donoghue. Unexpected features of the dark proteome. Proceedings of the National Academy of Sciences, 112(52):15898–15903, 2015
work page 2015
-
[11]
Learning protein sequence embeddings using information from structure
Tristan Bepler and Bonnie Berger. Learning protein sequence embeddings using information from structure. In International Conference on Learning Representations, 2019
work page 2019
-
[12]
Alley, Grigory Khimulya, Surojit Biswas, Mohammed AlQuraishi, and George M
Ethan C. Alley, Grigory Khimulya, Surojit Biswas, Mohammed AlQuraishi, and George M. Church. Unified rational protein engineering with sequence-only deep representation learning. bioRxiv, page 589333, 2019
work page 2019
-
[13]
Gapped blast and psi-blast: a new generation of protein database search programs
Stephen F Altschul, Thomas L Madden, Alejandro A Schäffer, Jinghui Zhang, Zheng Zhang, Webb Miller, and David J Lipman. Gapped blast and psi-blast: a new generation of protein database search programs. Nucleic acids research, 25(17):3389–3402, 1997
work page 1997
-
[14]
HHblits: lightning- fast iterative protein sequence searching by HMM-HMM alignment
Michael Remmert, Andreas Biegert, Andreas Hauser, and Johannes Söding. HHblits: lightning- fast iterative protein sequence searching by HMM-HMM alignment. Nature Methods, 9(2):173– 175, 2012
work page 2012
- [15]
-
[16]
Sean R. Eddy. Profile hidden markov models.Bioinformatics (Oxford, England), 14(9):755–763, 1998
work page 1998
-
[17]
Recommendations on nomenclature and symbolism for amino acids and peptides
IUPAC-IUB. Recommendations on nomenclature and symbolism for amino acids and peptides. Pure Appl. Chem, 56:595–623, 1984. 10
work page 1984
-
[18]
Proteins: structures and molecular properties
Thomas E Creighton. Proteins: structures and molecular properties. Macmillan, 1993
work page 1993
-
[19]
Twilight zone of protein sequence alignments
Burkhard Rost. Twilight zone of protein sequence alignments. Protein Engineering, Design and Selection, 12(2):85–94, 1999
work page 1999
-
[20]
Steven E Brenner, Cyrus Chothia, and Tim JP Hubbard. Assessing sequence comparison methods with reliable structurally identified distant evolutionary relationships.Proceedings of the National Academy of Sciences, 95(11):6073–6078, 1998
work page 1998
-
[21]
Altschul, Warren Gish, Webb Miller, Eugene W
Stephen F. Altschul, Warren Gish, Webb Miller, Eugene W. Myers, and David J. Lipman. Basic local alignment search tool. Journal of Molecular Biology, 215(3):403–410, 1990
work page 1990
-
[22]
Biological sequence analysis: probabilistic models of proteins and nucleic acids
Richard Durbin, Sean R Eddy, Anders Krogh, and Graeme Mitchison. Biological sequence analysis: probabilistic models of proteins and nucleic acids. Cambridge university press, 1998
work page 1998
-
[23]
Identification of common molecular subsequences
Temple F Smith, Michael S Waterman, et al. Identification of common molecular subsequences. Journal of molecular biology, 147(1):195–197, 1981
work page 1981
-
[24]
The swiss-model workspace: a web-based environment for protein structure homology modelling
Konstantin Arnold, Lorenza Bordoli, Jürgen Kopp, and Torsten Schwede. The swiss-model workspace: a web-based environment for protein structure homology modelling. Bioinformatics, 22(2):195–201, 2006
work page 2006
-
[25]
Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning. IEEE Transactions on Neural Networks, 20(3):542–542, 2009
work page 2009
-
[26]
Critical assessment of methods of protein structure prediction (CASP)-Round XII
John Moult, Krzysztof Fidelis, Andriy Kryshtafovych, Torsten Schwede, and Anna Tramontano. Critical assessment of methods of protein structure prediction (CASP)-Round XII. Proteins: Structure, Function, and Bioinformatics, 86:7–15, 2018
work page 2018
-
[27]
ProteinNet: a standardized data set for machine learning of protein structure
Mohammed AlQuraishi. ProteinNet: a standardized data set for machine learning of protein structure. bioRxiv, 2019
work page 2019
-
[28]
Semi-supervised protein classification using cluster kernels
Jason Weston, Dengyong Zhou, André Elisseeff, William S Noble, and Christina S Leslie. Semi-supervised protein classification using cluster kernels. In Advances in neural information processing systems, pages 595–602, 2004
work page 2004
-
[29]
Prediction of protein function from networks
Hyunjung Shin, Koji Tsuda, B Schölkopf, A Zien, et al. Prediction of protein function from networks. In Semi-supervised learning, pages 361–376. MIT press, 2006
work page 2006
-
[30]
Modeling the Language of Life - Deep Learning Protein Sequences
Michael Heinzinger, Ahmed Elnaggar, Yu Wang, Christian 4 Dallago, Dmitrii Nachaev, Florian Matthes, and & Burkhard Rost. Modeling the Language of Life - Deep Learning Protein Sequences. bioRxiv, 2019
work page 2019
-
[31]
Lawrence Zitnick, Jerry Ma, and Rob Fergus
Alexander Rives, Siddharth Goyal, Joshua Meier, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. bioRxiv, 2019
work page 2019
-
[32]
Adam J. Riesselman, John B. Ingraham, and Debora S. Marks. Deep generative models of genetic variation capture the effects of mutations. Nature Methods, 15(10):816–822, 2018
work page 2018
-
[33]
Learned protein embeddings for machine learning
Kevin K Yang, Zachary Wu, Claire N Bedbrook, and Frances H Arnold. Learned protein embeddings for machine learning. Bioinformatics, 34(15):2642–2648, 2018
work page 2018
-
[34]
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. arXiv preprint arXiv:1905.00537, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[35]
The Pfam protein families database in 2019
Sara El-Gebali, Jaina Mistry, Alex Bateman, Sean R Eddy, Aurélien Luciani, Simon C Potter, Matloob Qureshi, Lorna J Richardson, Gustavo A Salazar, Alfredo Smart, Erik L L Sonnhammer, Layla Hirsh, Lisanna Paladin, Damiano Piovesan, Silvio C E Tosatto, and Robert D Finn. The Pfam protein families database in 2019. Nucleic Acids Research, 47(D1):D427–D432, 2019. 11
work page 2019
-
[36]
Netsurfp-2.0: Improved prediction of protein structural features by integrated deep learning
Michael Schantz Klausen, Martin Closter Jespersen, Henrik Nielsen, Kamilla Kjaergaard Jensen, Vanessa Isabell Jurtz, Casper Kaae Soenderby, Morten Otto Alexander Sommer, Ole Winther, Morten Nielsen, Bent Petersen, et al. Netsurfp-2.0: Improved prediction of protein structural features by integrated deep learning. Proteins: Structure, Function, and Bioinfo...
work page 2019
-
[37]
Alexey Drozdetskiy, Christian Cole, James Procter, and Geoffrey J. Barton. JPred4: a protein secondary structure prediction server. Nucleic Acids Research, 43(W1):W389–W394, 2015
work page 2015
-
[38]
Evaluation and improvement of multiple sequence methods for protein secondary structure prediction
James A Cuff and Geoffrey J Barton. Evaluation and improvement of multiple sequence methods for protein secondary structure prediction. Proteins: Structure, Function, and Bioinformatics, 34(4):508–519, 1999
work page 1999
-
[39]
Kim, Frank DiMaio, Ray Yu-Ruei Wang, Yifan Song, and David Baker
David E. Kim, Frank DiMaio, Ray Yu-Ruei Wang, Yifan Song, and David Baker. One contact for every twelve residues allows robust and accurate topology-level protein structure modeling. Proteins: Structure, Function, and Bioinformatics, 82:208–218, 2014
work page 2014
-
[40]
Deepsf: deep convolutional neural network for mapping protein sequences to folds
Jie Hou, Badri Adhikari, and Jianlin Cheng. Deepsf: deep convolutional neural network for mapping protein sequences to folds. Bioinformatics, 34(8):1295–1303, 2017
work page 2017
-
[41]
Leticia Stephan Tavares, Carolina dos Santos Fernandes da Silva, Vinicius Carius Souza, Vânia Lúcia da Silva, Cláudio Galuppo Diniz, and Marcelo De Oliveira Santos. Strategies and molecular tools to fight antimicrobial resistance: resistome, transcriptome, and antimicrobial peptides. Frontiers in microbiology, 4:412, 2013
work page 2013
-
[42]
Casx enzymes comprise a distinct family of rna-guided genome editors
Jun-Jie Liu, Natalia Orlova, Benjamin L Oakes, Enbo Ma, Hannah B Spinner, Katherine LM Baney, Jonathan Chuck, Dan Tan, Gavin J Knott, Lucas B Harrington, et al. Casx enzymes comprise a distinct family of rna-guided genome editors. Nature, 566(7743):218, 2019
work page 2019
-
[43]
Local fitness landscape of the green fluorescent protein
Karen S Sarkisyan, Dmitry A Bolotin, Margarita V Meer, Dinara R Usmanova, Alexander S Mishin, George V Sharonov, Dmitry N Ivankov, Nina G Bozhanova, Mikhail S Baranov, Onuralp Soylemez, et al. Local fitness landscape of the green fluorescent protein. Nature, 533(7603):397, 2016
work page 2016
-
[44]
Machine learning-guided directed evolution for protein engineering
Kevin K Yang, Zachary Wu, and Frances H Arnold. Machine learning in protein engineering. arXiv preprint arXiv:1811.10775, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Global analysis of protein folding using massively parallel design, synthesis, and testing
Gabriel J Rocklin, Tamuka M Chidyausiku, Inna Goreshnik, Alex Ford, Scott Houliston, Alexander Lemak, Lauren Carter, Rashmi Ravichandran, Vikram K Mulligan, Aaron Chevalier, et al. Global analysis of protein folding using massively parallel design, synthesis, and testing. Science, 357(6347):168–175, 2017
work page 2017
-
[46]
Recur- rent neural network based language model
Tomáš Mikolov, Martin Karafiát, Lukáš Burget, JanˇCernock`y, and Sanjeev Khudanpur. Recur- rent neural network based language model. In Eleventh annual conference of the international speech communication association, 2010
work page 2010
-
[47]
DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. Journal of Machine Learning Research, 2013
work page 2013
-
[48]
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[49]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In I Guyon, U V Luxburg, S Bengio, H Wallach, R Fergus, S Vishwanathan, and R Garnett, editors,Advances in Neural Information Processing Systems 30, pages 5998–6008. Curran Associates, Inc., 2017
work page 2017
-
[50]
Fisher Yu, Vladlen Koltun, and Thomas Funkhouser. Dilated residual networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[51]
Multiplicative LSTM for sequence modelling
Ben Krause, Liang Lu, Iain Murray, and Steve Renals. Multiplicative lstm for sequence modelling. arXiv preprint arXiv:1609.07959, 2016. 12
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[52]
Assessment of contact predictions in casp12: Co-evolution and deep learning coming of age
Joerg Schaarschmidt, Bohdan Monastyrskyy, Andriy Kryshtafovych, and Alexandre MJJ Bonvin. Assessment of contact predictions in casp12: Co-evolution and deep learning coming of age. Proteins: Structure, Function, and Bioinformatics, 86:51–66, 2018
work page 2018
-
[53]
Jianzhu Ma, Sheng Wang, Zhiyong Wang, and Jinbo Xu. Protein contact prediction by integrat- ing joint evolutionary coupling analysis and supervised learning. Bioinformatics, 31(21):3506– 3513, 2015
work page 2015
-
[54]
Critical assessment of methods of protein structure prediction (casp)—round xii
John Moult, Krzysztof Fidelis, Andriy Kryshtafovych, Torsten Schwede, and Anna Tramontano. Critical assessment of methods of protein structure prediction (casp)—round xii. Proteins: Structure, Function, and Bioinformatics, 86:7–15, 2018
work page 2018
-
[55]
Yuedong Yang, Jianzhao Gao, Jihua Wang, Rhys Heffernan, Jack Hanson, Kuldip Paliwal, and Yaoqi Zhou. Sixty-five years of the long march in protein secondary structure prediction: the final stretch? Briefings in bioinformatics, 19(3):482–494, 2016
work page 2016
-
[56]
The cost and value of three-dimensional protein structure
Raymond C Stevens. The cost and value of three-dimensional protein structure. Drug Discovery World, 4(3):35–48, 2003
work page 2003
-
[57]
Naomi K Fox, Steven E Brenner, and John-Marc Chandonia. Scope: Structural classification of proteins—extended, integrating scop and astral data and classification of new structures. Nucleic acids research, 42(D1):D304–D309, 2013
work page 2013
-
[58]
The protein data bank.Nucleic acids research, 28(1):235–242, 2000
Helen M Berman, John Westbrook, Zukang Feng, Gary Gilliland, Talapady N Bhat, Helge Weissig, Ilya N Shindyalov, and Philip E Bourne. The protein data bank.Nucleic acids research, 28(1):235–242, 2000
work page 2000
-
[59]
Major new microbial groups expand diversity and alter our understanding of the tree of life
Cindy J Castelle and Jillian F Banfield. Major new microbial groups expand diversity and alter our understanding of the tree of life. Cell, 172(6):1181–1197, 2018
work page 2018
-
[60]
CCMpred—fast and precise prediction of protein residue–residue contacts from correlated mutations
Stefan Seemayer, Markus Gruber, and Johannes Söding. CCMpred—fast and precise prediction of protein residue–residue contacts from correlated mutations. Bioinformatics, 30(21):3128– 3130, 2014
work page 2014
-
[61]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training Deep Nets with Sublinear Memory Cost. arXiv, 2016
work page 2016
-
[62]
A series of pdb related databases for everyday needs
Robbie P Joosten, Tim AH Te Beek, Elmar Krieger, Maarten L Hekkelman, Rob WW Hooft, Reinhard Schneider, Chris Sander, and Gert Vriend. A series of pdb related databases for everyday needs. Nucleic acids research, 39(suppl_1):D411–D419, 2010. 13 Table S1: Dataset sizes Task Train Valid Test Language Modeling 32,207,059 N/A 2,147,130 (Random-split) / 44,314...
work page 2010
-
[63]
All proteins of a given fold are further categorized into related superfamilies
of hierarchically classified protein domains. All proteins of a given fold are further categorized into related superfamilies. Entire superfamilies are held out from the training set, allowing us to evaluate how the model generalizes across evolutionary distance when structure is preserved. (Labeling) Each fold is annotated from the structure of the sequen...
-
[64]
for details). We chose holdout clans and families in pairs, where a clan of novel function is held out together with a family that is similar in sequence but different evolutionarily or functionally. This 16 Table S2: Detailed secondary structure results Three-Way Accuracy (Q3) Eight-Way Accuracy (Q8) CB513 CASP12 TS115 CB513 CASP12 TS115 No Pretrain Tran...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.