Trade-offs in Large-Scale Distributed Tuplewise Estimation and Learning
Pith reviewed 2026-05-25 18:27 UTC · model grok-4.3
The pith
A repartitioning strategy across workers trades off accuracy against runtime for distributed tuplewise problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We first propose a simple strategy based on occasionally repartitioning data across workers between parallel computation stages, where the number of repartitioning steps rules the trade-off between accuracy and runtime. We then present some theoretical results highlighting the benefits brought by the proposed method in terms of variance reduction, and extend our results to design distributed stochastic gradient descent algorithms for tuplewise empirical risk minimization.
What carries the argument
The repartitioning strategy that occasionally shuffles data across workers between parallel stages, with the number of repartition steps controlling the accuracy-runtime trade-off.
If this is right
- Variance of the estimators is reduced relative to fixed partitioning across stages.
- Distributed SGD algorithms for tuplewise empirical risk minimization can be constructed using the same repartitioning approach.
- The accuracy-runtime trade-off is directly governed by the chosen number of repartitioning steps.
- The method applies to pairwise statistical estimation and learning tasks on both synthetic and real-world data.
Where Pith is reading between the lines
- The same repartitioning idea could be tested on other non-separable objectives that resist straightforward data parallelism.
- If communication cost of shuffles scales favorably, the strategy might shorten wall-clock time to reach a target accuracy in very large clusters.
- Extensions to tuples larger than pairs would follow the same variance-reduction logic if the repartitioning cost remains controlled.
Load-bearing premise
Occasional full data shuffles can be performed at acceptable communication cost while keeping the resulting sample pairs sufficiently representative.
What would settle it
An experiment in which increasing the number of repartitioning steps fails to reduce estimator variance or fails to improve the observed accuracy-runtime curve would falsify the central claim.
Figures



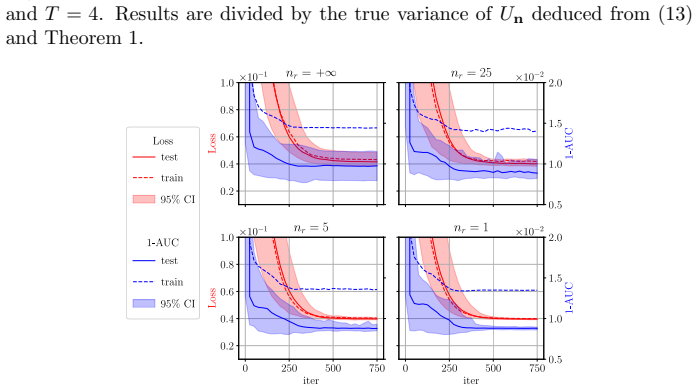


read the original abstract
The development of cluster computing frameworks has allowed practitioners to scale out various statistical estimation and machine learning algorithms with minimal programming effort. This is especially true for machine learning problems whose objective function is nicely separable across individual data points, such as classification and regression. In contrast, statistical learning tasks involving pairs (or more generally tuples) of data points - such as metric learning, clustering or ranking do not lend themselves as easily to data-parallelism and in-memory computing. In this paper, we investigate how to balance between statistical performance and computational efficiency in such distributed tuplewise statistical problems. We first propose a simple strategy based on occasionally repartitioning data across workers between parallel computation stages, where the number of repartitioning steps rules the trade-off between accuracy and runtime. We then present some theoretical results highlighting the benefits brought by the proposed method in terms of variance reduction, and extend our results to design distributed stochastic gradient descent algorithms for tuplewise empirical risk minimization. Our results are supported by numerical experiments in pairwise statistical estimation and learning on synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses challenges in scaling tuplewise statistical estimation and learning (e.g., metric learning, ranking) to distributed settings where standard data-parallelism does not apply directly. It proposes occasional repartitioning of data across workers between computation stages, with the number of repartitioning steps explicitly controlling the accuracy-runtime trade-off. Theoretical results are presented on variance reduction benefits of this strategy, which are then extended to design distributed SGD algorithms for tuplewise empirical risk minimization. The claims are supported by numerical experiments on synthetic and real-world datasets.
Significance. If the variance-reduction analysis holds under the stated conditions, the repartitioning approach provides a simple, tunable mechanism for distributed tuplewise problems that could be practically useful for large-scale metric learning and ranking tasks. The explicit user-chosen control parameter (repartitioning count) and the extension to distributed SGD are positive features; however, the absence of detailed derivations, error bars, and data-handling descriptions in the provided material limits immediate assessment of impact.
major comments (2)
- [theoretical results] Theoretical results section: the variance-reduction claims are asserted without derivation details, explicit assumptions on tuple sampling, or proof sketches; this is load-bearing because the central claim that repartitioning controls the accuracy-runtime trade-off rests on these unshown steps.
- [experiments] Experimental section: no error-bar information, description of data splits, or exclusion criteria are provided; this undermines verification of the reported practical benefits and the claim that the number of repartitioning steps rules the observed trade-off.
minor comments (1)
- [abstract] Abstract and introduction could more clearly distinguish the proposed repartitioning from standard shuffling or mini-batch strategies in distributed SGD literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will incorporate revisions to strengthen the presentation of both the theoretical and experimental results.
read point-by-point responses
-
Referee: Theoretical results section: the variance-reduction claims are asserted without derivation details, explicit assumptions on tuple sampling, or proof sketches; this is load-bearing because the central claim that repartitioning controls the accuracy-runtime trade-off rests on these unshown steps.
Authors: We agree that additional detail is needed to make the variance-reduction analysis fully self-contained. In the revision we will add explicit assumptions on tuple sampling (including independence and bounded moments), a proof sketch for the variance reduction bound, and the key derivation steps showing how the number of repartitioning steps enters the variance term. These will be placed in the main text or a dedicated appendix subsection. revision: yes
-
Referee: Experimental section: no error-bar information, description of data splits, or exclusion criteria are provided; this undermines verification of the reported practical benefits and the claim that the number of repartitioning steps rules the observed trade-off.
Authors: We acknowledge that the current experimental section lacks these details. In the revised version we will report error bars computed over multiple independent runs, provide a clear description of train/validation/test splits for both synthetic and real-world datasets, and state any exclusion criteria applied to the data. We will also add a short paragraph confirming that the observed trade-off is consistent across these runs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central proposal is a repartitioning strategy in which the number of repartitioning steps is presented as an explicit, user-chosen control variable that trades off accuracy against runtime. Theoretical claims concern variance reduction benefits of this strategy and its extension to distributed SGD for tuplewise ERM; these are framed as consequences of the repartitioning mechanism rather than quantities fitted from the same data or defined in terms of the target performance metrics. No equations or derivations in the provided material reduce a prediction to an input by construction, import uniqueness via self-citation chains, or smuggle ansatzes through prior work. The argument structure remains self-contained against external benchmarks, with the repartitioning premise stated at a high level but not internally forced by the derivation itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of repartitioning steps
Reference graph
Works this paper leans on
-
[1]
Y. Arjevani and O. Shamir. Communication complexity of distributed convex learning and optimization. In NIPS, 2015
work page 2015
- [2]
-
[3]
R. Bekkerman, M. Bilenko, and J. Langford. Scaling Up Machine Learning: Parallel and Distributed Approaches . Cambridge University Press, 2011
work page 2011
- [4]
-
[5]
P. Bertail and J. Tressou. Incomplete generalized U -statistics for food risk assessment. Biometrics, 62(1):66–74, 2006
work page 2006
-
[6]
G. Blom. Some properties of incomplete U-statistics. Biometrika, 63(3):573–580, 1976
work page 1976
-
[7]
L. Bottou and O. Bousquet. The Tradeoffs of Large Scale Learning. In NIPS, 2007
work page 2007
-
[8]
S. P. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed Op- timization and Statistical Learning via the Alternating Direction Method of Multipliers. Foundations and Trends in Machine Learning , 3(1):1–122, 2011
work page 2011
-
[9]
S. Bubeck. Convex Optimization: Algorithms and Complexity. Founda- tions and Trends in Machine Learning , 8(3–4):231–357, 2015
work page 2015
-
[10]
P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi, and K. Tzoumas. Apache Flink TM: Stream and Batch Processing in a Sin- gle Engine. IEEE Data Engineering Bulletin , 38(4):28–38, 2015. 15
work page 2015
-
[11]
S. Cl´ emen¸ con. A statistical view of clustering performance through the theory of U-processes. Journal of Multivariate Analysis , 124:42–56, 2014
work page 2014
-
[12]
S. Cl´ emen¸ con, A. Bellet, and I. Colin. Scaling-up Empirical Risk Min- imization: Optimization of Incomplete U-statistics. Journal of Machine Learning Research, 13:165–202, 2016
work page 2016
-
[13]
S. Cl´ emen¸ con, G. Lugosi, and N. Vayatis. Ranking and empirical risk minimization ofU-statistics. The Annals of Statistics, 36(2):844–874, 2008
work page 2008
-
[14]
S. Cl´ emen¸ con and S. Robbiano. Building confidence regions for the ROC surface. Pattern Recognition Letters, 46:67–74, 2014
work page 2014
-
[15]
H. Daum´ e III, J. M. Phillips, A. Saha, and S. Venkatasubramanian. Pro- tocols for Learning Classifiers on Distributed Data. In AISTATS, 2012
work page 2012
-
[16]
V. de la Pena and E. Gin´ e.Decoupling: from Dependence to Independence. Springer, 1999
work page 1999
-
[17]
J. Dean and S. Ghemawat. Mapreduce: simplified data processing on large clusters. Communications of the ACM , 51(1):107–113, 2008
work page 2008
- [18]
-
[19]
M. Jordan. On statistics, computation and scalability. Bernoulli, 19(4):1378–1390, 2013
work page 2013
-
[20]
A. Lee. U-statistics: Theory and practice . Marcel Dekker, Inc., New York, 1990
work page 1990
-
[21]
G. Papa, A. Bellet, and S. Cl´ emen¸ con. SGD Algorithms based on Incom- plete U-statistics: Large-Scale Minimization of Empirical Risk. In NIPS, 2015
work page 2015
- [22]
-
[23]
A. Van Der Vaart. Asymptotic Statistics . Cambridge University Press, 2000
work page 2000
- [24]
-
[25]
E. P. Xing, Q. Ho, W. Dai, J. K. Kim, J. Wei, S. Lee, X. Zheng, P. Xie, A. Kumar, and Y. Yu. Petuum: A New Platform for Distributed Machine Learning on Big Data. IEEE Transactions on Big Data , 1(2):49–67, 2015
work page 2015
-
[26]
M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica. Spark : Cluster Computing with Working Sets. In HotCloud, 2012. 16 SUPPLEMENTARY MATERIAL The code of the experiments can be found on the authors’ repository. 4 A Acknowledgments This work was supported by IDEMIA. We would like to thank Anne Sabourin for her feedback that helped improve ...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.