Compositionally-Warped Gaussian Processes
Pith reviewed 2026-05-25 17:24 UTC · model grok-4.3
The pith
Compositions of elementary invertible functions let Gaussian processes model non-Gaussian data with fully analytical inverses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a warping formed by composing elementary invertible functions yields a non-Gaussian generative model over functions whose inverse is known exactly, thereby preserving the computational advantages of the original Gaussian process while expanding the family of marginal distributions that can be represented.
What carries the argument
The compositionally-warped Gaussian process (CWGP), a non-Gaussian model whose warping is a finite composition of elementary functions chosen so that the overall inverse remains explicit and therefore analytical.
If this is right
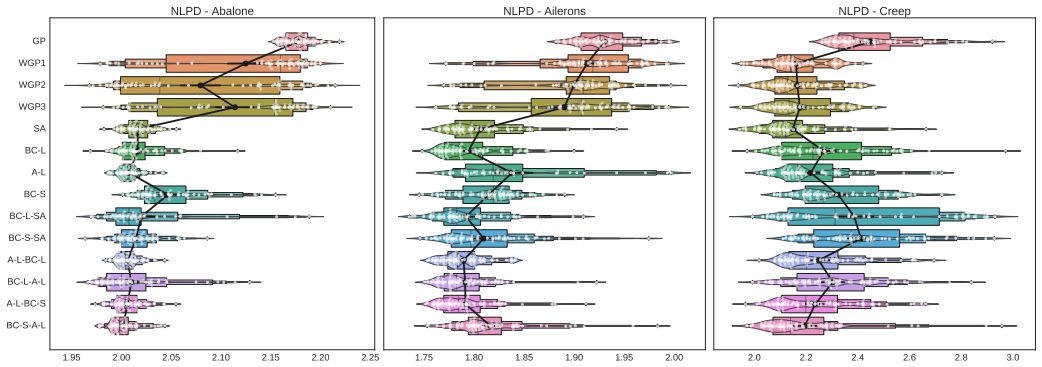
- Point predictions become more accurate than those of a standard warped GP on the tested data.
- Model training requires less computation because no numerical inversion is needed.
- The model remains effective across a range of different elementary warping functions.
- Prediction itself stays fully analytical at every stage.
Where Pith is reading between the lines
- The same compositional pattern could be applied to other latent-variable models that currently rely on numerical inverses.
- One could test whether adding more layers of elementary functions eventually saturates performance gains before reaching the cost of deep GPs.
- The approach implies that many practical non-Gaussian patterns can be captured without arbitrary, non-analytic warpings.
Load-bearing premise
Compositions of a modest number of elementary invertible functions are expressive enough to match the non-Gaussian marginals that appear in the intended applications.
What would settle it
A real-world dataset on which every composition of elementary functions produces visibly worse point predictions or longer training times than a numerically inverted warped GP using the same base kernel.
Figures


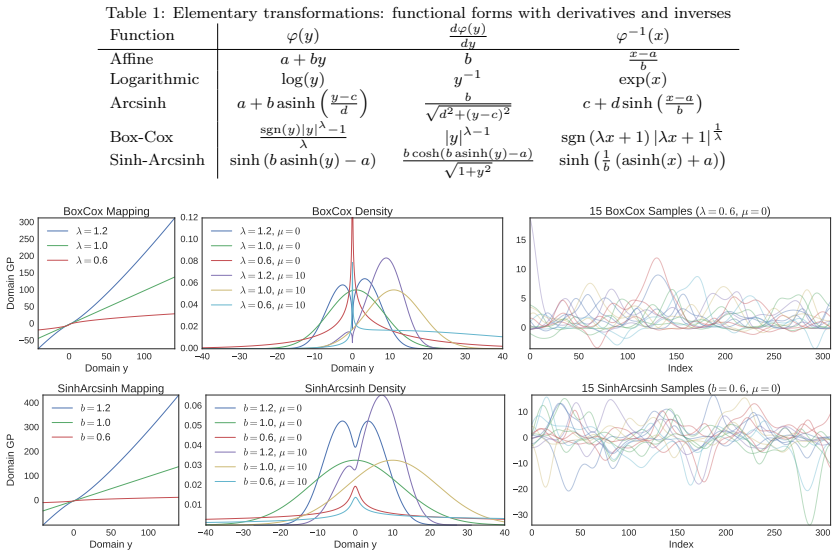
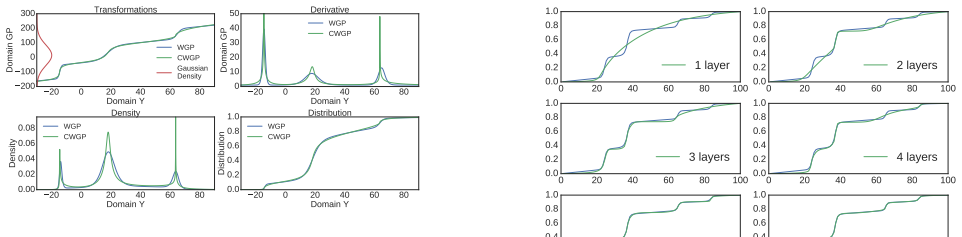
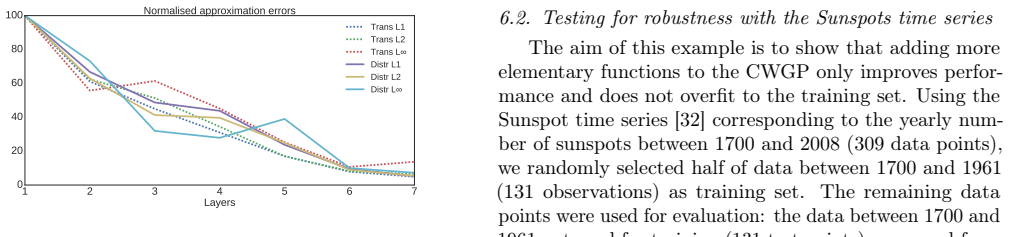

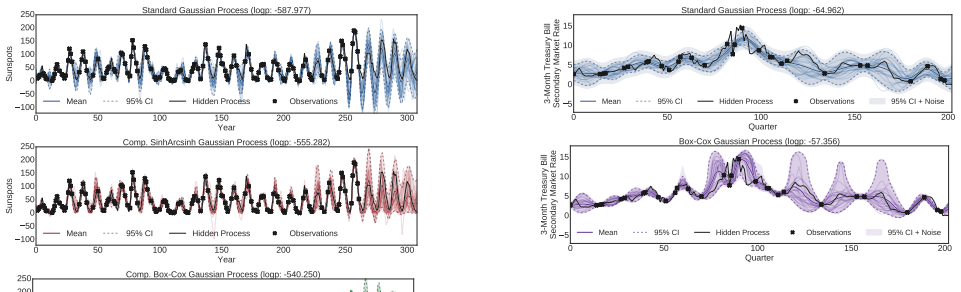
read the original abstract
The Gaussian process (GP) is a nonparametric prior distribution over functions indexed by time, space, or other high-dimensional index set. The GP is a flexible model yet its limitation is given by its very nature: it can only model Gaussian marginal distributions. To model non-Gaussian data, a GP can be warped by a nonlinear transformation (or warping) as performed by warped GPs (WGPs) and more computationally-demanding alternatives such as Bayesian WGPs and deep GPs. However, the WGP requires a numerical approximation of the inverse warping for prediction, which increases the computational complexity in practice. To sidestep this issue, we construct a novel class of warpings consisting of compositions of multiple elementary functions, for which the inverse is known explicitly. We then propose the compositionally-warped GP (CWGP), a non-Gaussian generative model whose expressiveness follows from its deep compositional architecture, and its computational efficiency is guaranteed by the analytical inverse warping. Experimental validation using synthetic and real-world datasets confirms that the proposed CWGP is robust to the choice of warpings and provides more accurate point predictions, better trained models and shorter computation times than WGP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces compositionally-warped Gaussian processes (CWGP), a non-Gaussian GP model whose warping functions are formed by composing elementary invertible functions. This guarantees an explicit inverse, avoiding the numerical inversion required by standard warped GPs (WGPs). The central empirical claim is that CWGP is robust to the specific choice of elementary warpings and yields more accurate point predictions, better-trained models, and shorter runtimes than WGP on both synthetic and real-world data.
Significance. If the reported gains hold under the full experimental protocol, the work supplies a practical, analytically tractable route to non-Gaussian marginals that sits between the simplicity of a single warping and the cost of deep or Bayesian warped GPs. The compositional construction with closed-form inverses is a concrete engineering advantage that could be adopted in time-series or spatial applications where repeated inversion is the bottleneck.
minor comments (3)
- Abstract: the phrase 'better trained models' is undefined; the experimental section should state the precise metric (e.g., negative log predictive density on held-out data, marginal likelihood value, or convergence speed of the optimizer).
- The manuscript should include an explicit table or appendix listing every elementary function employed, its closed-form inverse, and the range of composition depths tested, so that the robustness claim can be reproduced.
- Figure captions and axis labels in the experimental results should report the exact number of Monte-Carlo samples or quadrature points used when any numerical integration remains, even if the inverse itself is analytic.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript and recommendation for minor revision. We are encouraged by the recognition of the analytical and computational advantages of the compositional warping construction. No specific major comments were provided in the report, so we have no point-by-point rebuttals to offer at this stage.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces CWGP by directly defining a novel warping class as compositions of elementary functions with explicit inverses; this is a modeling construction, not a derivation that reduces to fitted parameters or prior results by construction. No self-citation load-bearing steps, uniqueness theorems imported from authors, or ansatzes smuggled via citation appear in the abstract or summary. The performance claims rest on experimental validation rather than internal redefinition, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian process defines a prior over functions with Gaussian marginals
- domain assumption Warping function must be invertible to recover data-space predictions
invented entities (1)
-
Compositionally-warped GP
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a novel class of warpings consisting of compositions of multiple elementary functions, for which the inverse is known explicitly... ϕ(y)=ϕd(ϕd−1(⋯(ϕ2(ϕ1(·)))⋯)).
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The NLL... warping-complexity term −∑log(dϕ(yi)/dy)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
C. E. Rasmussen, C. K. I. Williams, Gaussian Processes for Machine Learning, MIT, 2006
work page 2006
-
[3]
A. Bain, D. Crisan, Fundamentals of Stochastic Filtering, Springer, 2009
work page 2009
-
[4]
C. K. I. Williams, Computing with infinite networks, in: Ad- vances in Neural Information Processing Systems 9, MIT Press, 1997, pp. 295–301
work page 1997
-
[5]
R. M. Neal, Bayesian Learning for Neural Networks, Springer- Verlag New York, Inc., Secaucus, NJ, USA, 1996
work page 1996
-
[6]
Hornik, Some new results on neural network approximation, Neural Networks 6 (8) (1993) 1069–1072
K. Hornik, Some new results on neural network approximation, Neural Networks 6 (8) (1993) 1069–1072
work page 1993
-
[7]
Tao, An Introduction to Measure Theory, Vol
T. Tao, An Introduction to Measure Theory, Vol. 126, American Mathematical Society, 2011
work page 2011
-
[8]
R. M. Sakia, The Box-Cox transformation technique: A review, The Statistician (1992) 169–178
work page 1992
-
[9]
E. Snelson, Z. Ghahramani, C. E. Rasmussen, Warped Gaus- sian processes, in: Advances in Neural Information Processing Systems 16, MIT Press, 2004, pp. 337–344
work page 2004
-
[10]
M. Lázaro-Gredilla, Bayesian warped Gaussian processes, in: Advances in Neural Information Processing Systems 25, Curran Associates, Inc., 2012, pp. 1619–1627
work page 2012
-
[11]
A. C. Damianou, N. D. Lawrence, Deep Gaussian processes, in: Proc. of the International Conference on Artificial Intelligence and Statistics, 2013, pp. 207–215
work page 2013
-
[12]
P. J. Bickel, K. A. Doksum, An analysis of transformations revisited, Journal of the American Statistical Association 76 (1981) 296–311
work page 1981
-
[13]
N. L. Johnson, Systems of frequency curves generated by meth- ods of translation, Biometrika 36 (1/2) (1949) 149–176. 13
work page 1949
-
[14]
R. V. Hogg, A. T. Craig, Introduction to Mathematical Statistics, 5th Edition, Upper Saddle River, New Jersey: Prentice Hall, 1995
work page 1995
-
[15]
K. E. Atkinson, An Introduction to Numerical Analysis, John Wiley & Sons, 2008
work page 2008
-
[16]
Titsias, Variational learning of inducing variables in sparse Gaussian processes, in: Proc
M. Titsias, Variational learning of inducing variables in sparse Gaussian processes, in: Proc. of the International Conference on Artificial Intelligence and Statistics, Vol. 5, 2009, pp. 567–574
work page 2009
-
[17]
E. G. Tabak, E. Vanden-Eijnden, Density estimation by dual ascent of the log-likelihood, Communications in Mathematical Sciences 8 (1) (2010) 217–233
work page 2010
-
[18]
E. G. Tabak, C. V. Turner, A family of nonparametric density estimation algorithms, Communications on Pure and Applied Mathematics 66 (2) (2013) 145–164
work page 2013
-
[19]
D. J. Rezende, S. Mohamed, Variational inference with normal- izing flows, in: Proc. of the International Conference on Machine Learning, 2015, pp. 207–215
work page 2015
- [20]
-
[21]
G. Rios, F. Tobar, Learning non-Gaussian time series using the Box-Cox Gaussian process, in: Proc. of the IEEE International Joint Conference on Neural Networks, 2018, pp. 1–8
work page 2018
-
[22]
M. Abramowitz, I. A. Stegun, Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables, Courier Corporation, 1964
work page 1964
-
[23]
J. Aitchison, J. A. C. Brown, The Lognormal Distribution, Vol. 5, CUP Archive, 1976
work page 1976
-
[24]
B. Poblete, J. Guzman, J. Maldonado, F. Tobar, Robust detec- tion of extreme events using Twitter: Worldwide earthquake monitoring, IEEE Transactions on Multimedia 20 (10) (2018) 2551–2561
work page 2018
-
[25]
J. Freeman, R. Modarres, Inverse Box–Cox: The power-normal distribution, Statistics & Probability Letters 76 (8) (2006) 764– 772
work page 2006
-
[26]
M. C. Jones, A. Pewsey, Sinh-Arcsinh distributions, Biometrika 96 (4) (2009) 761
work page 2009
-
[27]
C. Watanabe, K. Hiramatsu, K. Kashino, Modular representa- tion of layered neural networks, Neural Networks 97 (2018) 62 – 73
work page 2018
-
[28]
D. Duvenaud, J. Lloyd, R. Grosse, J. Tenenbaum, G. Zoubin, Structure discovery in nonparametric regression through compo- sitional kernel search, in: Proc. of the International Conference on Machine Learning, 2013, pp. 1166–1174
work page 2013
-
[29]
Y. Bengio, et al., Learning deep architectures for AI, Foundations and trendsR⃝ in Machine Learning 2 (1) (2009) 1–127
work page 2009
- [30]
-
[31]
Schmidhuber, Deep learning in neural networks: An overview, Neural Networks 61 (2015) 85 – 117
J. Schmidhuber, Deep learning in neural networks: An overview, Neural Networks 61 (2015) 85 – 117
work page 2015
-
[32]
SILSO World Data Center, The International Sunspot Number, International Sunspot Number Monthly Bulletin and online catalogue
- [33]
- [34]
-
[35]
J. Nocedal, S. J. Wright, Numerical Optimization, 2nd Edition, Springer, New York, NY, USA, 2006
work page 2006
-
[36]
M. J. D. Powell, An efficient method for finding the minimum of a function of several variables without calculating derivatives, The computer journal 7 (2) (1964) 155–162
work page 1964
-
[37]
F. Tobar, Bayesian nonparametric spectral estimation, in: Ad- vances in Neural Information Processing Systems 31, Curran Associates, Inc., 2018, pp. 10148–10158
work page 2018
- [38]
- [39]
-
[40]
Louis, Federal reserve economic data (2009)
Federal Reserve Bank of St. Louis, Federal reserve economic data (2009). URL http://research.stlouisfed.org/fred2/
work page 2009
-
[41]
D. Duvenaud, J. R. Lloyd, R. Grosse, J. B. Tenenbaum, Z. Ghahramani, Structure discovery in nonparametric regression through compositional kernel search, in: Proc. of the Interna- tional Conference on Machine Learning, 2013
work page 2013
-
[42]
G. Rios, F. Tobar, G3py: Generalized graphical Gaussian pro- cesses, github.com/griosd/g3py (2017)
work page 2017
- [43]
-
[44]
M. A. Álvarez, N. D. Lawrence, Computationally efficient con- volved multiple output Gsaussian processes, Journal of Machine Learning Research 12 (May) (2011) 1459–s1500
work page 2011
-
[45]
Villani, Optimal Transport: Old and New, Springer Berlin Heidelberg, 2008
C. Villani, Optimal Transport: Old and New, Springer Berlin Heidelberg, 2008
work page 2008
-
[46]
J. Backhoff-Veraguas, J. Fontbona, G. Rios, F. Tobar, Bayesian learning with Wasserstein barycenters (2018). arXiv:1805. 10833
work page 2018
-
[47]
Y. Marzouk, T. Moselhy, M. Parno, A. Spantini, Sampling via Measure Transport: An Introduction, Springer International Publishing, 2016, pp. 1–41. 14
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.