Classification and Clustering of Arguments with Contextualized Word Embeddings
Pith reviewed 2026-05-25 17:41 UTC · model grok-4.3
The pith
Contextualized embeddings from ELMo and BERT advance argument classification and clustering with large gains over prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
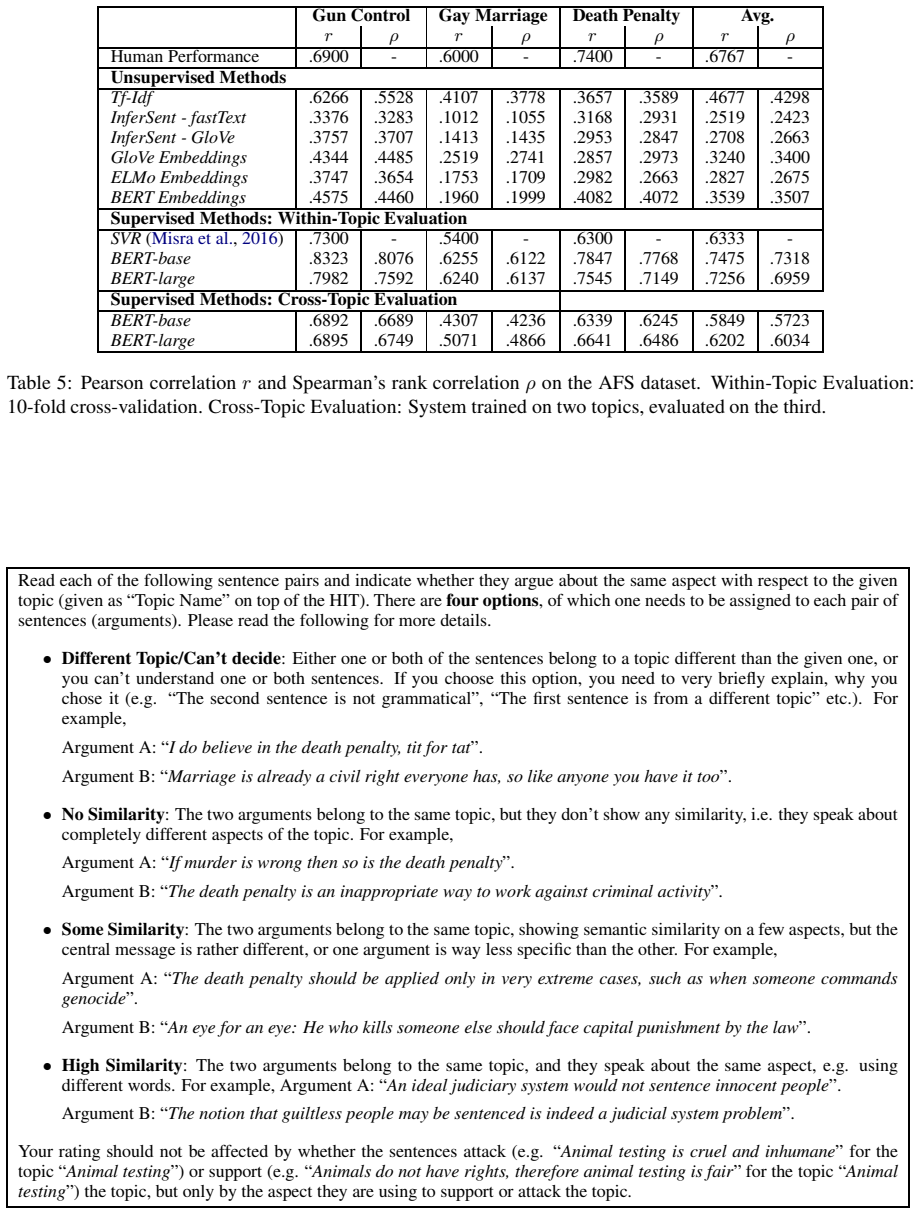
For the first time, contextualized word embeddings are leveraged to classify and cluster topic-dependent arguments in open-domain argument search, resulting in state-of-the-art performance across datasets with gains of 20.8 percentage points on the UKP Sentential Argument Mining Corpus and 7.4 on the IBM Debater dataset for classification, plus improvements of 7.8 and 12.3 points for clustering on a novel dataset and the AFS Corpus.
What carries the argument
Contextualized word embeddings (ELMo and BERT) for encoding arguments, combined with a proposed pre-training step for the clustering task.
If this is right
- Argument search systems can achieve higher accuracy in identifying relevant evidence sentences.
- Clustering arguments by facet similarity becomes more reliable, aiding in organizing debate materials.
- These embedding techniques demonstrate robustness across different argument datasets.
- Open-domain argument mining benefits from capturing the full sentence context rather than static word representations.
Where Pith is reading between the lines
- Similar gains may appear in related tasks like stance detection or evidence retrieval.
- Integrating these methods with graph-based argument structures could yield further advances.
- Developers of argument tools should prioritize contextual embeddings in their pipelines.
Load-bearing premise
The performance improvements are due to the contextual nature of the embeddings rather than to variations in model training or data preprocessing.
What would settle it
Reproducing the experiments with non-contextual embeddings like GloVe under identical training conditions and observing no significant difference in results would falsify the claim that contextualization drives the gains.
Figures

read the original abstract
We experiment with two recent contextualized word embedding methods (ELMo and BERT) in the context of open-domain argument search. For the first time, we show how to leverage the power of contextualized word embeddings to classify and cluster topic-dependent arguments, achieving impressive results on both tasks and across multiple datasets. For argument classification, we improve the state-of-the-art for the UKP Sentential Argument Mining Corpus by 20.8 percentage points and for the IBM Debater - Evidence Sentences dataset by 7.4 percentage points. For the understudied task of argument clustering, we propose a pre-training step which improves by 7.8 percentage points over strong baselines on a novel dataset, and by 12.3 percentage points for the Argument Facet Similarity (AFS) Corpus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to be the first to apply contextualized word embeddings (ELMo and BERT) to classify and cluster topic-dependent arguments for open-domain argument search. It reports concrete gains of 20.8 percentage points on the UKP Sentential Argument Mining Corpus and 7.4 percentage points on the IBM Debater Evidence Sentences dataset for classification, plus 7.8 percentage points on a novel dataset and 12.3 percentage points on the AFS Corpus for clustering via a proposed pre-training step.
Significance. If the reported lifts are shown to arise from the contextualized embeddings under matched conditions, the work would be significant for establishing the practical value of these representations in argument mining, a key component of argument search systems. The pre-training step for clustering constitutes a methodological addition that could be adopted more broadly.
major comments (1)
- [§4 (Experiments)] §4 (Experiments) and associated results tables: the headline attribution of the 20.8 pp, 7.4 pp, 7.8 pp and 12.3 pp gains to ELMo/BERT requires that non-contextual baselines received identical data splits, tokenization, preprocessing pipelines, and hyper-parameter search budgets. The manuscript does not explicitly document these controls; any mismatch would mean the lifts cannot be credited to the embeddings themselves, which is load-bearing for the central claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'strong baselines' is used without naming the exact systems or feature sets; adding one sentence of clarification would aid readers.
- [§3 (Method)] Notation: the description of the pre-training step for clustering could be accompanied by a short pseudocode block or explicit loss formulation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of matched experimental conditions. We address the single major comment below and will revise the manuscript to strengthen the central claim.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated results tables: the headline attribution of the 20.8 pp, 7.4 pp, 7.8 pp and 12.3 pp gains to ELMo/BERT requires that non-contextual baselines received identical data splits, tokenization, preprocessing pipelines, and hyper-parameter search budgets. The manuscript does not explicitly document these controls; any mismatch would mean the lifts cannot be credited to the embeddings themselves, which is load-bearing for the central claim.
Authors: We agree that the manuscript should explicitly document these controls to support attribution of the reported gains. In the revised version we will add a new subsection (e.g., §4.1) that states: (i) all methods, including non-contextual baselines, were evaluated on the exact same train/dev/test splits; (ii) identical tokenization and preprocessing pipelines were applied; and (iii) hyper-parameter search budgets were matched across conditions (with the same search ranges and number of trials). This documentation will make the experimental comparison fully transparent and allow the lifts to be credited to the contextualized embeddings. revision: yes
Circularity Check
No circularity; purely empirical evaluation against external baselines
full rationale
The paper reports measured F1 improvements from applying ELMo/BERT embeddings to argument classification and clustering tasks on UKP, IBM Debater, AFS, and a novel dataset. No derivation, equation, or first-principles claim is present; results are obtained by standard fine-tuning and clustering pipelines evaluated on held-out test splits. No self-citation is used to justify uniqueness or to close a loop, and no fitted parameter is relabeled as a prediction. The central claim (contextualized embeddings yield gains) is tested by direct comparison to non-contextual baselines on the same data, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
A Community-Based Approach for Stance Distribution and Argument Organization
Unsupervised graph community detection organizes arguments to reveal stance distributions in debates.
Reference graph
Works this paper leans on
-
[1]
Supervised learning of universal sentence representations from natural language inference data . In Proceedings of the 2017 Conference on Empirical Methods in Nat- ural Language Processing, pages 670–680. William H. E. Day and Herbert Edelsbrunner
work page 2017
-
[2]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of deep bidirectional transformers for language under- standing . arXiv preprint arXiv:1810.04805 . Steffen Eger, Johannes Daxenberger, and Iryna Gurevych
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Learning whom to trust with MACE . In Proceedings of the 2013 Confer- ence of the North American Chapter of the Associ- ation for Computational Linguistics: Human Lan- guage T echnologies, pages 1120–1130. Ran Levy, Y onatan Bilu, Daniel Hershcovich, Ehud Aharoni, and Noam Slonim
work page 2013
-
[4]
Context depen- dent claim detection . In Proceedings of COLING 2014, the 25th International Conference on Compu- tational Linguistics: T echnical Papers, pages 1489–
work page 2014
-
[5]
Efficient Estimation of Word Representations in Vector Space
Efficient Estimation of Word Representations in V ector Space . arXiv preprint arXiv:1301.3781. Amita Misra, Brian Ecker, and Marilyn A. Walker
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Measuring the similarity of sentential ar- guments in dialogue . In Proceedings of the SIG- DIAL 2016 Conference, The 17th Annual Meeting of the Special Interest Group on Discourse and Di- alogue, 13-15 September 2016, Los Angeles, CA, USA, pages 276–287. Jeffrey Pennington, Richard Socher, and Christo- pher D. Manning
work page 2016
-
[7]
Deep contextualized word rep- resentations. In Proceedings of the 2018 Confer- ence of the North American Chapter of the Associ- ation for Computational Linguistics: Human Lan- guage T echnologies, V olume 1 (Long Papers), pages 2227–2237. Nils Reimers and Iryna Gurevych
work page 2018
-
[8]
Why com- paring single performance scores does not allow to draw conclusions about machine learning ap- proaches . arXiv preprint arXiv:1803.09578 . Ruty Rinott, Lena Dankin, Carlos Alzate Perez, Mitesh M. Khapra, Ehud Aharoni, and Noam Slonim
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Show me your evidence - an auto- matic method for context dependent evidence detec- tion . In Proceedings of the 2015 Conference on Em- pirical Methods in Natural Language Processing , pages 440–450. Eyal Shnarch, Carlos Alzate, Lena Dankin, Mar- tin Gleize, Y ufang Hou, Leshem Choshen, Ranit Aharonov, and Noam Slonim
work page 2015
-
[10]
Will it Blend? Blending Weak and Strong Labeled Data in a Neu- ral Network for Argumentation Mining . In Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Pa- pers), volume 2, pages 599–605. Christian Stab, Johannes Daxenberger, Chris Stahlhut, Tristan Miller, Benjamin Schiller, Christopher Tauchma...
work page 2018
-
[11]
Identify- ing Argumentative Discourse Structures in Persua- sive Essays . Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 46–56. Christian Stab, Tristan Miller, Benjamin Schiller, Pranav Rai, and Iryna Gurevych. 2018b. Cross-topic argument mining from heterogeneous sources . In Proceedings of the 2018 ...
work page 2014
-
[12]
Retrieval of the best counterargument with- out prior topic knowledge . In Proceedings of the 56th Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 241–251. A Appendices A.1 UKP ASPECT Corpus: Amazon Mechanical Turk Guidelines and Inter-annotator Agreement The annotations required for the UKP ASPECT Corpus ...
work page 1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.