Open-MPI over MOSIX: paralleled computing in a clustered world
Pith reviewed 2026-05-25 13:19 UTC · model grok-4.3
The pith
Integrating MOSIX migration into Open-MPI plus a DiCOM module reduces run-time by better resource allocation on clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating the process migration capability of MOSIX into Open-MPI and adding a module for direct communication (DiCOM) between migrated processes overcomes the increased communication latency of TCP/IP, producing reduced run-time through improved resource allocation.
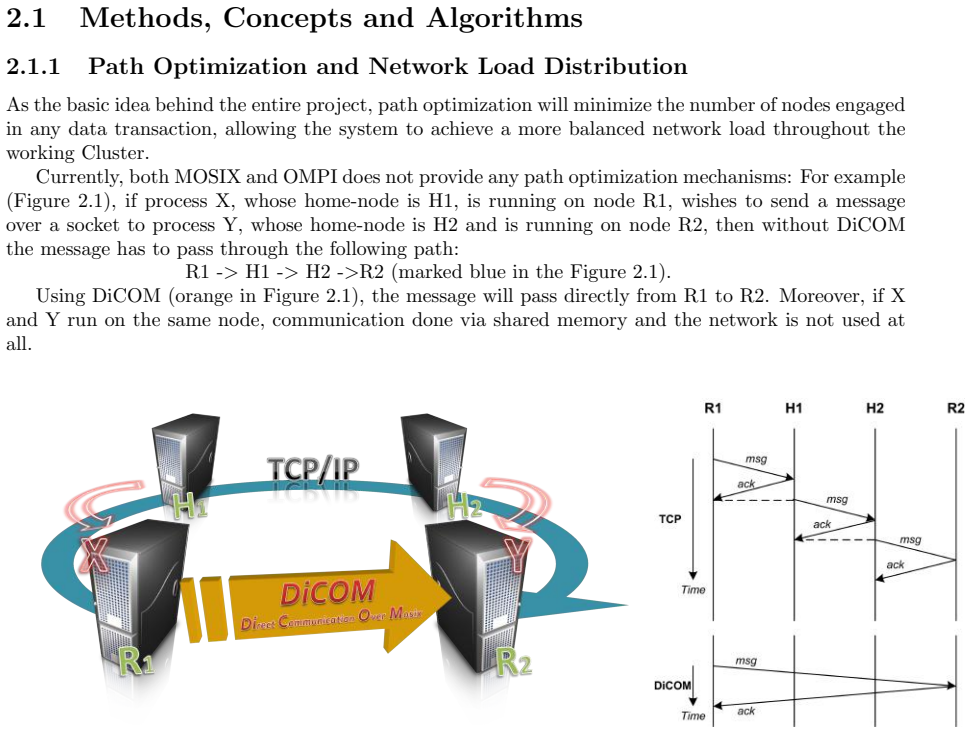
What carries the argument
The DiCOM module, which supplies direct communication between migrated Open-MPI processes to avoid TCP/IP overhead.
If this is right
- Multiple concurrent jobs can share cluster nodes with dynamic reallocation of processes.
- Load balancing improves without the communication penalty that normally follows migration.
- Preemptive migration becomes practical for Open-MPI applications running on shared hardware.
Where Pith is reading between the lines
- The approach may extend to other MPI libraries if similar direct-communication hooks can be added after migration.
- In cloud settings with variable node availability, the same migration-plus-direct-comm pattern could cut idle time across jobs.
- Further work could test whether DiCOM-style shortcuts remain effective when migration frequency rises.
Load-bearing premise
Adding the DiCOM module will produce a net reduction in communication overhead and overall run time rather than introducing new costs that offset the migration benefit.
What would settle it
A side-by-side timing of the same parallel job on a cluster using standard Open-MPI versus the MOSIX-integrated version with DiCOM; if run-time does not decrease, the claim fails.
Figures














read the original abstract
Recent increased interest in Cloud computing emphasizes the need to find an adequate solution to the load-balancing problem in parallel computing -- efficiently running several jobs concurrently on a cluster of shared computers (nodes). One approach to solve this problem is by preemptive process migration -- the transfer of running processes between nodes. A possible drawback of this approach is the increased overhead between heavily communicating processes. This project presents a solution to this last problem by incorporating the process migration capability of MOSIX into Open-MPI and by reducing the resulting communication overhead. Specifically, we developed a module for direct communication (DiCOM) between migrated Open-MPI processes, to overcome the increased communication latency of TCP/IP between such processes. The outcome is reduced run-time by improved resource allocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes integrating MOSIX preemptive process migration into Open-MPI, augmented by a new DiCOM module for direct inter-process communication, to enable dynamic load balancing across cluster nodes while mitigating the TCP/IP latency penalty that would otherwise arise from migration; the central claim is that this yields a net reduction in application run-time.
Significance. A working implementation of this architecture could supply a practical, migration-based alternative to static scheduling or checkpoint-restart techniques for MPI workloads on shared clusters, directly addressing load imbalance without requiring application changes. The design itself is a concrete engineering contribution, but the lack of any performance model, overhead measurements, or comparative experiments prevents assessment of whether the claimed net benefit materializes.
major comments (1)
- [Abstract] Abstract: the assertion that 'the outcome is reduced run-time by improved resource allocation' is presented as an achieved result, yet the manuscript supplies neither runtime measurements, baseline comparisons, error bars, nor any analysis of DiCOM module overhead versus the migration benefit; this leaves the central empirical claim without support.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract overstates the empirical outcome and will revise the manuscript to align claims with the presented content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'the outcome is reduced run-time by improved resource allocation' is presented as an achieved result, yet the manuscript supplies neither runtime measurements, baseline comparisons, error bars, nor any analysis of DiCOM module overhead versus the migration benefit; this leaves the central empirical claim without support.
Authors: We agree with this assessment. The manuscript describes the architecture, the integration of MOSIX preemptive migration into Open-MPI, and the design of the DiCOM module for direct communication after migration, but contains no runtime measurements, baselines, or overhead analysis. The abstract claim will be revised to state that the approach is intended to enable reduced run-time via improved resource allocation, rather than asserting it as a demonstrated result. This change will be made in the next version. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a systems/engineering description of integrating MOSIX preemptive migration into Open-MPI plus a new DiCOM module for direct inter-process communication. No equations, fitted parameters, predictions, uniqueness theorems, or ansatzes appear in the provided abstract or described content. The outcome claim (reduced run-time via better allocation) is presented as the direct result of the architecture rather than any derivation that reduces to its own inputs by construction. No self-citation load-bearing steps exist. This is a standard non-circular implementation paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we developed a module for direct communication (DiCOM) between migrated Open-MPI processes, to overcome the increased communication latency of TCP/IP
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
DiCOM is slightly slower than migrated TCP/IP for small message sizes (below 32k). For larger message sizes, DiCOM is increasingly better than TCP/IP between migrated processes, with an average improvement of 52% for all of the measured message sizes. Figure 1: DiCOM compared to TCP/IP TCP send/recv latency with and without migration (red and orange respe...
-
[3]
Today the DiCOM module is ready to be sub- mitted
Open-MPI source code - Downloaded from openMPI.org, provided with some common usage code examples, no special relation to MOSIX existed. Today the DiCOM module is ready to be sub- mitted
-
[4]
Latest version of MOSIX - Updated several times during the project, including change from 32 bit to 64, some source code was also available. Mosix provides a well build information dissemination daemon (\infod"), and as for today usage of Direct Communication is enabled, but without TCP/IP compatibility (even though it exists and works awlessly, as can be...
-
[5]
CLIP - Cluster management tool
-
[6]
Standard Linux libraries and kernel - Due to the nature of MOSIX, parts of it are compiled in the Linux kernel; therefore, with every change done to the part of DiCOM which is embedded in the kernel, we had to recompile the entire OS
-
[7]
Matlab - Output data analysis and presentation
-
[8]
Virtual Box - virtual machine client. 2.2.2 Development and Test Environment In order to comply with very high compatibility, we developed and tested DiCOM on a verity of envi- ronments including: Clusters of raging sizes (2 to 50 nodes), Heterogeneous and homogeneous Clusters, Busy and free Clusters, 32 bit and 64 bit architectures, Intel, SPARC and virt...
-
[9]
The average slowdown is about 17% for all message sizes
The performance of TCP/IP between non-migrated process is slightly better then DiCOM for all message sizes. The average slowdown is about 17% for all message sizes. This is due to the xed overhead of the DiCOM protocol
-
[10]
DiCOM is slightly slower than migrated TCP/IP for small message sizes (below 10k). For larger message sizes, DiCOM is increasingly better than TCP/IP between migrated processes, with an average improve- ment of 52% for all of the measured message sizes. From Figure 3.4, which present the latencies for di erent message sizes of TCP/IP and DiCOM without pro...
-
[11]
We have solved problems concerning the integration of two vastly used scienti c tools, Open-MPI and MOSIX
-
[12]
We have constructed a tool enabling simple integration of DiCOM into various TCP/IP enabled applica- tions running on MOSIX
-
[13]
Extensive tests and measurements indicate that the developed tool is stable; it indeed reduces the total runtime of parallel OMPI jobs over MOSIX, and is ready for deployment . 4.3 Future Work The most signi cant of possible future developments of this project very well may be the integration of the DiCOM module into the standard MOSIX TCP (see Figure 4.1...
-
[14]
Parallel computing oriented scheduler built into the MOSIX system
-
[15]
Introduction of the DiCOM module to other parallel computing environments, such as OpenMP and MPICH
-
[16]
Creation socket oriented mailbox, this will enable MOSIX programmers to create a lter free, faster DiCOM module. Figure 4.1: Future work - Suggested structure Suggested structure of mosix embedded DiCOM module with communication manner optimization mechanism. 14 Appendix A MPI & Open-MPI (OMPI) MPI (Message Passing Interface) is a language-independent com...
-
[17]
The core of the protocol involves periodic, paired, inter-process interactions
-
[18]
The information exchanged during these interactions is of bounded size
-
[19]
When agents interact, the state of at least one agent changes to re ect the state of the other. A gossip interaction does not occur when A pings B just to measure the response time, as this does not involve the transmittal of state between agents
-
[20]
Reliable communication is not assumed
-
[21]
The frequency of the interactions is low compared to typical message latencies so that the protocol costs are negligible
-
[22]
There is some form of randomness in the peer selection. Peers might be selected from the full set of nodes or from a smaller set of "neighbors". As mention before, MOSIX is using a speci c gossip protocol: Dissemination protocols (or rumor- mongering protocols) - These use gossip to spread information; they basically work by ooding agents in the network, ...
-
[23]
R. H. Castain, T. S. Woodall, D. J. Daniel, J. M. Squyres, B. Barrett, and G. E. Fagg. The open run- time environment (OpenRTE): A transparent multi-cluster environment for high-performance com- puting. In Proceedings, 12th European PVM/MPI Users' Group Meeting, Sorrento, Italy, September 2005
work page 2005
-
[24]
K. M. Chandy and J. Misra. Parallel program design: a foundation . Addison-Wesley, 1988
work page 1988
-
[25]
R. K. Chellappa. Cloud computing - emerging paradigm for computing. in INFORMS, Dallas, TX, 1997
work page 1997
-
[26]
R. L. Graham, G. M. Shipman, B. W. Barrett, R. H. Castain, G. Bosilca, and A. Lumsdaine. Open MPI: A high-performance, heterogeneous MPI. In Proceedings, Fifth International Workshop on Algorithms, Models and Tools for Parallel Computing on Heterogeneous Networks , Barcelona, Spain, September 2006
work page 2006
-
[27]
F. Halsall. Data communications, computer networks and open systems (4th ed.) . Addison Wesley Longman Publishing Co., Inc., Redwood City, CA, USA, 1995
work page 1995
-
[28]
R. H. Katz. Tech titans building boom - the race to build the mega data centers that will power cloud computing. IEEE Spectrum, 46(2):36 { 39, 46 { 49, February 2009
work page 2009
-
[29]
C. Kauhaus, A. Knoth, T. Peiselt, and D. Fey. E cient message passing on multi-clusters: An ipv6 extension to Open MPI. In Proceedings of KiCC'07, Chemnitzer Informatik Berichte , February 2007
work page 2007
-
[30]
A. Keren and A. Barak. Opportunity cost algorithms for reduction of I/O and interprocess com- munication overhead in a computing cluster. IEEE Trans. Parallel Distrib. Syst. , 14(1):39{50, 2003
work page 2003
-
[31]
A. L., B. A., D. Z., and O. M. Randomized gossip algorithms for maintaining a distributed bulletin board with guaranteed age properties. Concurrency and Computation: Practice and Experience , 21(15):1907 { 1927, March 2009
work page 1907
-
[32]
MOSIX.org. MOSIX man Pages , 2009. Retrieved from mosix.org: http://www.mosix.org/wiki/index.php/MOSIX-wiki
work page 2009
-
[33]
W. R. Stevens and G. R. Wright. TCP/IP Illustrated: The implementation . Addison-Wesley, 1995
work page 1995
-
[34]
C. H. Still. Scienti c Programming: Portable parallel computing via the MPI message-passing standard. COMPUTERS IN PHYSICS , 8(5):533{538, sep/oct 1994
work page 1994
-
[35]
L. M. Vaquero, L. Rodero-Merino, J. Caceres, and M. Lindner. A break in the clouds: towards a cloud de nition. SIGCOMM Comput. Commun. Rev. , 39(1):50{55, 2009
work page 2009
-
[36]
L. Wall, T. Christiansen, and J. Orwant. Programming Perl. O'Reilly Media, Inc., 3 edition, 2000
work page 2000
-
[37]
D. Z. and B. A. E cient algorithms for routing information in a multicomputer system. In Dis- tributed Algorithms on Graphs: Proceedings of the 1st International Workshop on Distributed Algo- rithms, pages 41{48, Ottawa, Canada, August 1985. Carleton Univ. Press. 19 Index algorithm, gossip, 3, 4, 7, 17 ANSI C, 6, 9 balancing, load, iv, 2, 3, 6 BTL, 16, 18...
work page 1985
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.