Learning Multi-Party Turn-Taking Models from Dialogue Logs
Pith reviewed 2026-05-25 09:53 UTC · model grok-4.3
The pith
Machine learning can learn who speaks next in multi-party dialogues from prior speaker sequences and utterance content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that the size of the corpus has a very positive impact on the accuracy for the content-based deep learning approaches and those models perform best in the larger datasets; and if the dialogue dataset is small and topic-oriented (but with few topics), it is sufficient to use an agent-only MLE or SVM models, although slightly higher accuracies can be achieved with the use of the content of the utterances with a CNN model.
What carries the argument
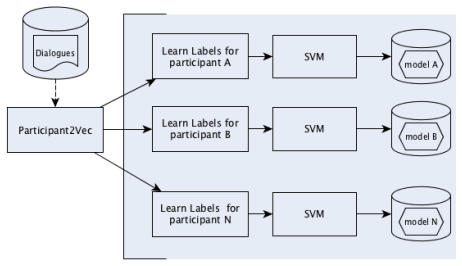
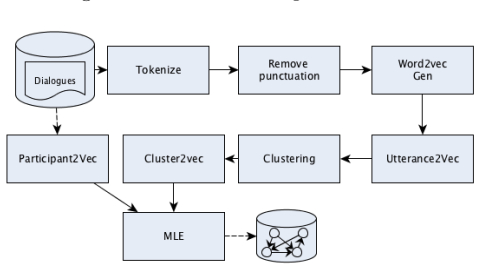
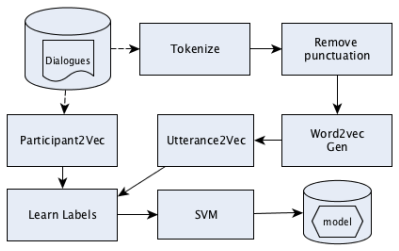
The next-speaker prediction task that maps sequences of prior speakers (and optionally the text of their utterances) to the identity of the following speaker.
If this is right
- Content-based convolutional networks become the strongest option once training corpora exceed the size of the smaller collections examined.
- Agent-only maximum likelihood or support vector machine predictors remain practical choices for limited, topic-constrained dialogue logs.
- Slight accuracy gains are still available by adding utterance content even when data volume is modest.
- Turn-taking behavior learned from television dialogue or wizard-of-oz logs transfers to deployed multi-bot systems within similar domains.
Where Pith is reading between the lines
- The same training approach could be applied to live interaction logs to adapt turn-taking rules over time without retraining from scratch.
- Models might improve further if participant identities or roles were added as explicit input features beyond the current speaker-sequence encoding.
- Cross-domain testing on entirely new conversation settings would reveal whether dataset size alone compensates for differences in topic variety.
Load-bearing premise
The three corpora accurately represent real multi-party turn-taking dynamics and the supervised prediction task based solely on prior speaker sequence and utterance content is sufficient to capture the underlying behavior without additional context or external factors.
What would settle it
Train the same models on one of the reported corpora and evaluate them on a new multi-party dialogue collection that includes participant role information or external interruptions; if accuracy falls below the levels reported for the original small datasets, the claim that speaker history plus content is adequate would be undermined.
Figures



read the original abstract
This paper investigates the application of machine learning (ML) techniques to enable intelligent systems to learn multi-party turn-taking models from dialogue logs. The specific ML task consists of determining who speaks next, after each utterance of a dialogue, given who has spoken and what was said in the previous utterances. With this goal, this paper presents comparisons of the accuracy of different ML techniques such as Maximum Likelihood Estimation (MLE), Support Vector Machines (SVM), and Convolutional Neural Networks (CNN) architectures, with and without utterance data. We present three corpora: the first with dialogues from an American TV situated comedy (chit-chat), the second with logs from a financial advice multi-bot system and the third with a corpus created from the Multi-Domain Wizard-of-Oz dataset (both are topic-oriented). The results show: (i) the size of the corpus has a very positive impact on the accuracy for the content-based deep learning approaches and those models perform best in the larger datasets; and (ii) if the dialogue dataset is small and topic-oriented (but with few topics), it is sufficient to use an agent-only MLE or SVM models, although slightly higher accuracies can be achieved with the use of the content of the utterances with a CNN model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper compares MLE, SVM, and CNN models (with and without utterance content) for predicting the next speaker in multi-party dialogues on three corpora: a large chit-chat TV comedy corpus and two smaller topic-oriented corpora (financial advice logs and Multi-Domain WoZ). The central claims are that corpus size has a strongly positive effect on accuracy for content-based deep learning approaches (which perform best on larger datasets) and that agent-only MLE or SVM models suffice for small topic-oriented datasets, though CNN with content can yield slight gains.
Significance. If the size effect on CNN performance can be isolated from dialogue-type differences, the work would offer practical guidance for choosing between simple sequence models and content-based neural models in multi-party turn-taking systems, particularly distinguishing open-domain chit-chat from task-oriented settings.
major comments (2)
- [Corpora and results sections] Corpora and results sections: the three corpora differ simultaneously in size and dialogue type (large chit-chat TV vs. small topic-oriented financial and WoZ), with no within-type size variation described. This confounds attribution of CNN accuracy gains specifically to corpus size rather than differences in vocabulary, turn-taking regularity, or content predictability, directly undermining the size-impact claim (i) and the conditional recommendation in the abstract.
- [Abstract and experimental results] Abstract and experimental results: comparative accuracies are reported without details on data splits, statistical significance testing, error bars, hyperparameter selection for CNN/SVM, or controls for confounds, limiting evaluation of whether the data support the stated performance differences and model recommendations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, acknowledging limitations where appropriate.
read point-by-point responses
-
Referee: Corpora and results sections: the three corpora differ simultaneously in size and dialogue type (large chit-chat TV vs. small topic-oriented financial and WoZ), with no within-type size variation described. This confounds attribution of CNN accuracy gains specifically to corpus size rather than differences in vocabulary, turn-taking regularity, or content predictability, directly undermining the size-impact claim (i) and the conditional recommendation in the abstract.
Authors: We agree this is a valid concern: the corpora vary in both size and dialogue type with no controlled within-type size variation, so performance differences cannot be attributed solely to size. The two smaller corpora share a topic-oriented nature, supporting a practical comparison between large chit-chat and small topic-focused settings. We will revise the abstract, claims (i), and discussion to frame results as observational across these dimensions and note the confound as a limitation, rather than claiming isolated size effects. revision: partial
-
Referee: Abstract and experimental results: comparative accuracies are reported without details on data splits, statistical significance testing, error bars, hyperparameter selection for CNN/SVM, or controls for confounds, limiting evaluation of whether the data support the stated performance differences and model recommendations.
Authors: We will incorporate the missing details in the revised experimental results section, including data split descriptions, any statistical significance tests, error bars, and hyperparameter selection methods. Controls for confounds will be addressed via the revised discussion of limitations noted above. revision: yes
Circularity Check
Empirical comparison study with no derivations or equations
full rationale
The paper reports accuracies from training and evaluating MLE, SVM, and CNN models on three fixed dialogue corpora for next-speaker prediction. No equations, derivations, or self-citations are presented that reduce any reported accuracy to a quantity defined by the model's own fitted parameters or by a prior result from the same authors. The central claims are direct empirical observations on held-out data and are externally falsifiable by re-running the models on the same corpora. No load-bearing uniqueness theorems or ansatzes appear.
Axiom & Free-Parameter Ledger
free parameters (1)
- CNN and SVM hyperparameters
axioms (1)
- domain assumption Prior speaker sequence and utterance content determine next speaker
Reference graph
Works this paper leans on
-
[1]
I. V. Serban, A. Sordoni, R. Lowe, L. Charlin, A. Courville J. Pineau, and Y. Bengio. A hierarchical latent variable encoder-decoder model for generating dialogues. In AAAI Conference, 2017
work page 2017
-
[2]
Multiwoz - a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling
Pawe l Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Inigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gaˇ si´ c. Multiwoz - a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 5016–5026, Brussels, Belgium, 2018. ACL
work page 2018
-
[3]
C. S. Pinhanez, H. Candello, M. C. Pichiliani, M. Vasconcelos, M. Guerra, M. Gatti de Bayser, and Paulo Cavalin. Different but equal: Comparing user collaboration with digital personal assistants vs. teams of expert agents. 2018. arXiv:1808.08157
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Harvey Sacks, Emanuel A. Schegloff, and Gail Jefferson. A simplest systematics for the organization of turn-taking for conversation. Language, 50(4):696–735, 1974
work page 1974
-
[5]
J. W. Harris and H Stocker. Maximum likelihood method. page 824, 1998
work page 1998
-
[6]
A unified view on multi-class support vector classification
¨Ur¨ un Doˇ gan, Tobias Glasmachers, and Christian Igel. A unified view on multi-class support vector classification. J. Mach. Learn. Res. , 17(1):1550–1831, January 2016
work page 2016
-
[7]
A generic model of multi-class support vector machine
Yann Guermeur. A generic model of multi-class support vector machine. Int. J. Intell. Inf. Database Syst. , 6(6):555–577, October 2012
work page 2012
-
[8]
Ronan Collobert, Jason Weston, L´ eon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel P. Kuksa. Natural language processing (almost) from scratch. CoRR, abs/1103.0398, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[9]
Pengfei Liu, Shafiq R. Joty, and Helen M. Meng. Fine-grained opinion mining with recurrent neural networks and word embeddings. In Lluis Marquez, Chris Callison- Burch, Jian Su, Daniele Pighin, and Yuval Marton, editors, EMNLP, pages 1433–1443. The ACL, 2015. 13
work page 2015
-
[10]
M. Gatti de Bayser, C. Pinhanez, H. Candello, M. A. Vasconcelos, M. Pichiliani, M. Al- berio Guerra, P. Cavalin, , and R. Souza. Ravel: a mas orchestration platform for human-chatbots conversations. In The 6th International Workshop on Engineering Multi-Agent Systems (EMAS @ AAMAS 2018) , Stockholm, Sweden, 2018
work page 2018
-
[11]
M. Gatti de Bayser, M. Alberio Guerra, P. Cavalin, and C. Pinhanez. Specifying and implementing multi-party conversation rules with finite-state-automata. In Proc. of the AAAI Workshop On Reasoning and Learning for Human-Machine Dialogues 2018 , New Orleans, USA, 2018
work page 2018
-
[12]
A survey of available corpora for building data-driven dialogue systems: The journal version
Iulian Vlad Serban, Ryan Lowe, Peter Henderson, Laurent Charlin, and Joelle Pineau. A survey of available corpora for building data-driven dialogue systems: The journal version. Dialogue & Discourse, 9(1), 2018
work page 2018
-
[13]
You talking to me? a corpus and algorithm for conversation disentanglement
Micha Elsner and Eugene Charniak. You talking to me? a corpus and algorithm for conversation disentanglement. In Proceedings of Association for Computational Linguistics (ACL), 2008
work page 2008
-
[14]
Samira Shaikh, Tomek Strzalkowski, George Aaron Broadwell, Jennifer Stromer-Galley, Sarah M. Taylor, and Nick Webb. Mpc: A multi-party chat corpus for modeling social phenomena in discourse. In The LREC, 2010
work page 2010
-
[15]
Gunrock: Building a human- like social bot byleveraging large scale real user data
Chun-Yen Chen, Dian Yu, Weiming Wen, Yi Mang Yang, Jiaping Zhang, Mingyang Zhou, Kevin Jesse, Austin Chau, Antara Bhowmick, Shreenath Iyer, Giritheja Sreeniva- sulu, Runxiang Cheng, Ashwin Bhandare, and Zhou Yu. Gunrock: Building a human- like social bot byleveraging large scale real user data. In 2nd Proceedings of Alexa Prize (Alexa Prize 2018) , 2018
work page 2018
-
[16]
Addressee and response selection for multi-party con- versation
Hiroki Ouchi and Yuta Tsuboi. Addressee and response selection for multi-party con- versation. In Kevin Duh Jian Su, Xavier Carreras, editor, EMNLP, pages 2133–2143. The ACL, 2016
work page 2016
-
[17]
D.C. Uthus and D.W Aha. The ubuntu chat corpus for multiparticipant chat analysis analyzing microtext. In AAAI Spring Symposium on Analyzing Mi- crotext , pages 99–102, 2013
work page 2013
-
[18]
Ryan Lowe, Nissan Pow, Iulian V. Serban, and Joelle Pineau. The ubuntu dialogue corpus: A large dataset for research in unstructure multi-turn dialogue systems. pages 285–294, 2015
work page 2015
- [19]
-
[20]
Svante Wold, Kim Esbensen, and Paul Geladi. Principal component analysis. Chemo- metrics and Intelligent Laboratory Systems , 2(1):37 – 52, 1987. Proceedings of the Multivariate Statistical Workshop for Geologists and Geochemists. 14
work page 1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.