Toeplitz Inverse Covariance based Robust Speaker Clustering for Naturalistic Audio Streams
Pith reviewed 2026-05-24 22:33 UTC · model grok-4.3
The pith
A Toeplitz inverse covariance matrix inside a Markov random field models speaker i-vector correlations to reduce diarization error rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing each speaker's i-vector correlations as a Toeplitz inverse covariance matrix within a Markov random field, the method enables a closed-form solution for speaker clustering via a DP and ADMM variant of the EM algorithm, achieving relative DER reductions of 43.22% on CRSS-PLTL, 29.37% on AMI IS1000a, and 9.21% on AMI IS1003b.
What carries the argument
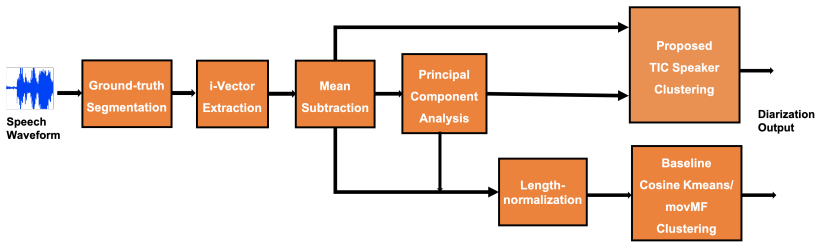
Toeplitz Inverse Covariance (TIC) matrix to represent the MRF correlation network for each speaker
If this is right
- Speaker clustering can exploit the sequential structure of i-vectors belonging to the same speaker.
- The DP+ADMM variant of EM supplies a closed-form update for the clustering parameters.
- The four-step pipeline of ground-truth segmentation, i-vector extraction, post-processing, and TIC-MRF clustering produces measurable DER gains on naturalistic meeting data.
- The model is directly compared against cosine K-means and movMF on the CRSS-PLTL and AMI corpora.
Where Pith is reading between the lines
- The structured covariance assumption may transfer to other sequential clustering tasks that involve ordered feature vectors.
- Gains could change if i-vector extraction or post-processing steps are replaced by different front-ends.
- The method might be tested in fully automatic segmentation settings rather than ground-truth segmentation.
Load-bearing premise
Correlations among i-vectors belonging to the same speaker can be adequately captured by a Toeplitz-structured inverse covariance matrix inside an MRF.
What would settle it
Running the proposed TIC-MRF clustering on the same datasets and observing no relative reduction or an increase in DER compared to the cosine K-means and movMF baselines.
Figures


read the original abstract
Speaker diarization determines who spoke and when? in an audio stream. In this study, we propose a model-based approach for robust speaker clustering using i-vectors. The ivectors extracted from different segments of same speaker are correlated. We model this correlation with a Markov Random Field (MRF) network. Leveraging the advancements in MRF modeling, we used Toeplitz Inverse Covariance (TIC) matrix to represent the MRF correlation network for each speaker. This approaches captures the sequential structure of i-vectors (or equivalent speaker turns) belonging to same speaker in an audio stream. A variant of standard Expectation Maximization (EM) algorithm is adopted for deriving closed-form solution using dynamic programming (DP) and the alternating direction method of multiplier (ADMM). Our diarization system has four steps: (1) ground-truth segmentation; (2) i-vector extraction; (3) post-processing (mean subtraction, principal component analysis, and length-normalization) ; and (4) proposed speaker clustering. We employ cosine K-means and movMF speaker clustering as baseline approaches. Our evaluation data is derived from: (i) CRSS-PLTL corpus, and (ii) two meetings subset of the AMI corpus. Relative reduction in diarization error rate (DER) for CRSS-PLTL corpus is 43.22% using the proposed advancements as compared to baseline. For AMI meetings IS1000a and IS1003b, relative DER reduction is 29.37% and 9.21%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a speaker clustering method for diarization that models correlations among i-vectors of the same speaker via a Markov Random Field whose precision matrix is constrained to be Toeplitz (TIC-MRF). Inference uses a dynamic-programming plus ADMM variant of EM claimed to admit a closed-form solution. The system pipeline consists of ground-truth segmentation, i-vector extraction, post-processing (mean subtraction, PCA, length normalization), and the proposed clustering step. On the CRSS-PLTL corpus the method yields a 43.22 % relative DER reduction versus cosine K-means and movMF baselines; on AMI meeting subsets IS1000a and IS1003b the reductions are 29.37 % and 9.21 %, respectively.
Significance. If the reported gains are shown to be statistically reliable and attributable to the TIC-MRF modeling choice rather than post-processing or baseline implementation details, the work would supply a concrete, structured way to exploit sequential dependence among speaker embeddings in diarization pipelines.
major comments (3)
- [Evaluation / Results] Evaluation (results tables and accompanying text): the abstract and results section report only point estimates of relative DER reduction; no statistical significance tests, bootstrap confidence intervals, or per-meeting variance are supplied, so it is impossible to judge whether the claimed 43.22 %, 29.37 % and 9.21 % improvements exceed sampling variability.
- [Proposed Method] Modeling section (TIC-MRF construction): the paper asserts that a Toeplitz-structured inverse covariance adequately captures same-speaker i-vector correlations, yet provides neither an empirical check (e.g., sample precision-matrix diagonals) nor an ablation that replaces the Toeplitz constraint with an unstructured or banded alternative; without such evidence the central modeling assumption remains unverified and the source of the reported gains cannot be isolated.
- [Algorithm] Algorithm section (DP+ADMM EM): the claim that the variant yields a closed-form optimum is stated without a derivation showing how the ADMM sub-problems preserve the claimed closed-form property or without convergence analysis; this detail is load-bearing for the assertion that the method is both tractable and superior to standard EM or the baselines.
minor comments (2)
- [System Pipeline] The post-processing pipeline (mean subtraction, PCA, length normalization) is applied identically to all methods; the manuscript should clarify whether any of these steps were tuned on the test data or whether they interact with the TIC-MRF objective.
- [Modeling] Notation for the MRF potential functions and the precise definition of the Toeplitz constraint (constant diagonals, bandwidth, etc.) should be stated explicitly with an equation reference.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of statistical rigor, modeling validation, and algorithmic transparency that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation (results tables and accompanying text): the abstract and results section report only point estimates of relative DER reduction; no statistical significance tests, bootstrap confidence intervals, or per-meeting variance are supplied, so it is impossible to judge whether the claimed 43.22 %, 29.37 % and 9.21 % improvements exceed sampling variability.
Authors: We agree that reporting only point estimates limits the ability to assess reliability. In the revised manuscript we will add bootstrap confidence intervals (resampling over segments or meetings) and per-meeting DER breakdowns for both corpora. These additions will allow readers to evaluate whether the observed relative reductions exceed sampling variability. revision: yes
-
Referee: [Proposed Method] Modeling section (TIC-MRF construction): the paper asserts that a Toeplitz-structured inverse covariance adequately captures same-speaker i-vector correlations, yet provides neither an empirical check (e.g., sample precision-matrix diagonals) nor an ablation that replaces the Toeplitz constraint with an unstructured or banded alternative; without such evidence the central modeling assumption remains unverified and the source of the reported gains cannot be isolated.
Authors: The Toeplitz constraint is motivated by the stationary sequential dependence among i-vectors belonging to the same speaker, which is a natural modeling choice given the turn-based nature of the embeddings. While the original submission did not include an explicit empirical verification of the learned precision-matrix structure or an ablation against an unstructured MRF, the consistent gains over non-structured baselines (cosine K-means and movMF) provide indirect support. We will expand the modeling section to articulate this motivation more clearly and, space permitting, include a limited ablation comparing Toeplitz versus banded alternatives. revision: partial
-
Referee: [Algorithm] Algorithm section (DP+ADMM EM): the claim that the variant yields a closed-form optimum is stated without a derivation showing how the ADMM sub-problems preserve the claimed closed-form property or without convergence analysis; this detail is load-bearing for the assertion that the method is both tractable and superior to standard EM or the baselines.
Authors: The closed-form property follows from the combination of dynamic programming for the discrete assignment variables in the E-step and the ADMM solver for the constrained M-step, where the Toeplitz structure permits efficient closed-form updates for each sub-problem. We will add a dedicated appendix containing the full derivation of the ADMM sub-problems and a brief note on convergence (leveraging standard ADMM guarantees under convexity of the sub-problems). This will make the tractability claim fully transparent. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces the TIC-structured MRF for modeling i-vector correlations per speaker and a DP+ADMM variant of EM as modeling and algorithmic choices, then reports empirical relative DER reductions against cosine K-means and movMF baselines on three evaluation sets. No equations, self-citations, or steps are shown that reduce the claimed improvements to a fitted parameter defined by the same data, a self-referential definition, or a load-bearing self-citation chain. The central claim remains an independent modeling proposal whose validity is tested externally via diarization error rates.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption i-vectors extracted from segments of the same speaker are correlated
- domain assumption A Toeplitz structure on the inverse covariance matrix is sufficient to represent the MRF correlation network for each speaker
Reference graph
Works this paper leans on
-
[1]
Introduction Speaker diarization answers "who spoke and when?" in a multi- speaker audio stream [1]. Some of the practical applications of diarization technology include information retrieval [2], broad- cast news, meeting conversations, telephone calls, V oIP, digi- tal audio logging [3] and interaction analysis in Peer-Led Team Learning (PLTL) groups [4...
work page 2019
-
[2]
Toeplitz Inverse Covariance based Robust Speaker Clustering for Naturalistic Audio Streams
i-V ector Speaker Model Diarization involve extracting i-Vectors from short speech- segments (typically 1s) unlike speaker verification where com- plete utterance is used. Numerous techniques exist for cluster- ing i-Vectors using cosine distance [16]. The i-vector frame- work combines the speaker and channel variability sub-spaces of linear distortion mod...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[3]
Proposed Speaker Clustering Toeplitz Inverse Covariance (TIC)-based clustering was found to be suitable for segmenting the real-world time-series data such as fitness-tracker and driving data [22]. Such temporal data has complicated structure where the underlying sequences of few fixed states repeat in definitive patterns. Robust speaker clustering task poss...
-
[4]
Experiments, Results & Discussions In this study, we focus on speaker clustering and hence ground- truth segmentation information is adopted for all experiments to avoid errors from SAD and speaker segmentation steps (see Fig. 1). We conduct evaluations on: (i) CRSS-PLTL, and (ii) two meetings subset of AMI corpus, as detailed below. 4.1. CRSS-PLTL Eval S...
-
[5]
Summary & Conclusions In this paper, we leveraged the Toeplitz Inverse Covariance (TIC) estimation in speaker clustering task for naturalistic au- dio such as CRSS-PLTL corpus. Such audio data are rich in noise, overlapped-speech and reverberation in addition to short conversational turns (1s). The proposed approach accu- rately models the inner structure...
-
[6]
Speaker diarization: A review of recent research,
X. Anguera, S. Bozonnet, N. Evans, C. Fredouille, G. Fried- land, and O. Vinyals, “Speaker diarization: A review of recent research,” IEEE Trans. on Audio, Speech, and Language Process- ing, vol. 20, no. 2, pp. 356–370, 2012
work page 2012
-
[7]
Huijbregts, Segmentation, diarization and speech transcrip- tion: surprise data unraveled
M. Huijbregts, Segmentation, diarization and speech transcrip- tion: surprise data unraveled. Citeseer, 2008
work page 2008
-
[8]
J. H. L. Hansen, A. Sangwan, A. Ziaei, H. Dubey, L. Kaushik, and C. Yu, “Prof-Life-Log: Monitoring and assessment of human speech and acoustics using daily naturalistic audio streams,” The Journal of the Acoustical Society of America, vol. 140, no. 4, pp. 3010–3010, 2016
work page 2016
-
[9]
Incremental on-line clus- tering of speakers’ short segments,
R. Aloni-Lavi, I. Opher, and I. Lapidot, “Incremental on-line clus- tering of speakers’ short segments,” in Proc. Odyssey 2018 The Speaker and Language Recognition Workshop , 2018, pp. 120– 127
work page 2018
-
[10]
Large-scale speaker di- arization for long recordings and small collections,
M. Huijbregts and D. A. van Leeuwen, “Large-scale speaker di- arization for long recordings and small collections,” IEEE Trans. on Audio, Speech, and Language Processing , vol. 20, no. 2, pp. 404–413, 2012
work page 2012
-
[11]
H. Dubey, A. Sangwan, and J. H. L. Hansen, “Using speech tech- nology for quantifying behavioral characteristics in peer-led team learning sessions,” Computer Speech & Language , vol. 46, pp. 343–366, 2017
work page 2017
-
[12]
A robust diarization system for measuring dominance in peer-led team learning groups,
——, “A robust diarization system for measuring dominance in peer-led team learning groups,” in IEEE Spoken Language Tech- nology Workshop (SLT), 2016, pp. 319–323
work page 2016
-
[13]
J. H. L. Hansen, J. Alberte, N. Jones, H. Dubey, and A. Sang- wan, “Multi-stream audio analysis for knowledge extraction and understanding of small-group interactions in peer-led team learn- ing,” Seventh Annual Conference Peer-Led Team Learning Inter- national Society, the University of Texas at Dallas, Richardson, TX, USA, pp. 1–1, 2018
work page 2018
-
[14]
J. H. L. Hansen, H. Dubey, and A. Sangwan, “CRSS-LDNN Long-duration naturalistic noise corpus containing multi-layer noise recordings for robust speech processing,” The Journal of the Acoustical Society of America, vol. 144, no. 3, pp. 1797–1797, 2018
work page 2018
-
[15]
H. Dubey, A. Sangwan, and J. H. L. Hansen, “Leveraging Frequency-Dependent Kernel and DIP-based Clustering for Ro- bust Speech Activity Detection in Naturalistic Audio Streams,” IEEE/ACM Trans. on Audio, Speech and Language Processing , vol. 26, no. 11, pp. 2056–2071, 2018
work page 2056
-
[16]
Robust feature clustering for unsupervised speech activity detection,
——, “Robust feature clustering for unsupervised speech activity detection,” in IEEE ICASSP, 2018, pp. 2726–2730
work page 2018
-
[17]
Transfer learning using raw waveform sincnet for robust speaker diarization,
——, “Transfer learning using raw waveform sincnet for robust speaker diarization,” in IEEE ICASSP , Brighton, UK., 2019
work page 2019
-
[18]
Front-end factor analysis for speaker verification,
N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-end factor analysis for speaker verification,” IEEE Trans. on Audio, Speech, and Language Processing , vol. 19, no. 4, pp. 788–798, 2011
work page 2011
-
[19]
Speaker diariza- tion system for RT07 and RT09 meeting room audio,
H. Sun, B. Ma, S. Z. K. Khine, and H. Li, “Speaker diariza- tion system for RT07 and RT09 meeting room audio,” in IEEE ICASSP, 2010, pp. 4982–4985
work page 2010
-
[20]
Stream-based speaker segmentation using speaker factors and eigenvoices,
F. Castaldo, D. Colibro, E. Dalmasso, P. Laface, and C. Vair, “Stream-based speaker segmentation using speaker factors and eigenvoices,” in IEEE ICASSP, 2008, pp. 4133–4136
work page 2008
-
[21]
A study of the cosine distance-based mean shift for telephone speech diarization,
M. Senoussaoui, P. Kenny, T. Stafylakis, and P. Dumouchel, “A study of the cosine distance-based mean shift for telephone speech diarization,” IEEE Trans. on Audio, Speech and Language Pro- cessing, vol. 22, no. 1, pp. 217–227, 2014
work page 2014
-
[22]
Step-by-step and integrated approaches in broadcast news speaker diarization,
S. Meignier, D. Moraru, C. Fredouille, J.-F. Bonastre, and L. Be- sacier, “Step-by-step and integrated approaches in broadcast news speaker diarization,” Computer Speech & Language, vol. 20, no. 2-3, pp. 303–330, 2006
work page 2006
-
[23]
Recent Im- provements on ILP-based Clustering for Broadcast News Speaker Diarization,
G. Dupuy, S. Meignier, P. Deléglise, and Y . Estéve, “Recent Im- provements on ILP-based Clustering for Broadcast News Speaker Diarization,” in ISCA Odyssey, 2014, pp. 187–193
work page 2014
-
[24]
I. Lapidot, A. Shoa, T. Furmanov, L. Aminov, A. Moyal, and J.-F. Bonastre, “Generalized viterbi-based models for time-series segmentation and clustering applied to speaker diarization,”Com- puter Speech & Language, vol. 45, pp. 1–20, 2017
work page 2017
-
[25]
On the use of PLDA i-vector scoring for clustering short segments,
I. Salmun, I. Opher, and I. Lapidot, “On the use of PLDA i-vector scoring for clustering short segments,” in Proc. Odyssey, 2016
work page 2016
-
[26]
H. Dubey, A. Sangwan, and J. H. L. Hansen, “Robust speaker clustering using mixtures of von mises-fisher distributions for naturalistic audio streams,” in ISCA INTERSPEECH, 2018, pp. 3603–3607
work page 2018
-
[27]
Toeplitz inverse covariance-based clustering of multivariate time series data,
D. Hallac, S. Vare, S. Boyd, and J. Leskovec, “Toeplitz inverse covariance-based clustering of multivariate time series data,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . ACM, 2017, pp. 215–223
work page 2017
-
[28]
A speaker diarization system for studying peer-led team learning groups,
H. Dubey, L. Kaushik, A. Sangwan, and J. H. L. Hansen, “A speaker diarization system for studying peer-led team learning groups,” in ISCA INTERSPEECH, 2016, pp. 2180–2184
work page 2016
-
[29]
J. H. L. Hansen, H. Dubey, A. Sangwan, L. Kaushik, and V . Kothapally, “UTDallas-PLTL: Advancing multi-stream speech processing for interaction assessment in peer-led team learning,” The Journal of the Acoustical Society of America, vol. 143, no. 3, pp. 1869–1869, 2018
work page 2018
-
[30]
I. McCowan, J. Carletta, W. Kraaij, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V . Karaiskos et al., “The AMI meeting corpus,” in Proceedings of the 5th Interna- tional Conference on Methods and Techniques in Behavioral Re- search, vol. 88, 2005, p. 100
work page 2005
-
[31]
Speaker recognition by machines and humans: A tutorial review,
J. H. L. Hansen and T. Hasan, “Speaker recognition by machines and humans: A tutorial review,” IEEE Signal Processing Maga- zine, vol. 32, no. 6, pp. 74–99, 2015
work page 2015
-
[32]
Eigenvoice model- ing with sparse training data,
P. Kenny, G. Boulianne, and P. Dumouchel, “Eigenvoice model- ing with sparse training data,” IEEE Trans. on speech and audio processing, vol. 13, no. 3, pp. 345–354, 2005
work page 2005
-
[33]
S. L. Lauritzen, Graphical models . Clarendon Press, 1996, vol. 17
work page 1996
-
[34]
K. Carlson, D. Turvold Celotta, E. Curran, M. Marcus, and M. Loe, “Assessing the Impact of a Multi-Disciplinary Peer-Led- Team Learning Program on Undergraduate STEM Education,” Journal of University Teaching & Learning Practice , vol. 13, no. 1, p. 5, 2016
work page 2016
-
[35]
A. Sangwan, J. H. L. Hansen, D. W. Irvin, S. Crutchfield, and C. R. Greenwood, “Studying the relationship between physical and language environments of children: Who’s speaking to whom and where?” in IEEE Signal Proc.Education Workshop, Salt Lake City, Utah, 2015, pp. 49–54
work page 2015
-
[36]
Fast speaker diarization using a high-level scripting language,
E. Gonina, G. Friedland, H. Cook, and K. Keutzer, “Fast speaker diarization using a high-level scripting language,” inIEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2011, pp. 553–558
work page 2011
-
[37]
Efficient online spherical k-means clustering,
S. Zhong, “Efficient online spherical k-means clustering,” in IEEE International Joint Conference on Neural Networks, vol. 5, 2005, pp. 3180–3185
work page 2005
-
[38]
Analysis of i-vector length normalization in speaker recognition systems,
D. Garcia-Romero and C. Y . Espy-Wilson, “Analysis of i-vector length normalization in speaker recognition systems,” inISCA IN- TERSPEECH, 2011, pp. 249–252
work page 2011
-
[39]
NIST DER script for RT evaluations,
“NIST DER script for RT evaluations,” (Date last accessed 9- Jan-2018). [Online]. Available: as part of the Speech Recognition Scoring Toolkit (SCTK): ftp://jaguar.ncsl.nist.gov/pub/sctk-2.4. 10-20151007-1312Z.tar.bz2
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.