Scalable and Generalizable Correspondence Pruning via Geometry-Consistent Pre-training
Pith reviewed 2026-05-24 00:15 UTC · model grok-4.3
The pith
Pre-training via masked inlier reconstruction yields correspondence pruning models that stay robust to outliers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Geometry-consistent pre-training that uses masked inlier reconstruction as a pretext task, realized through a dual-branch masked autoencoder and a unified dual-stream encoder with built-in consensus interaction, produces representations for correspondence pruning that remain free from outlier interference and therefore scale and generalize across camera pose estimation, visual localization, and 3D registration.
What carries the argument
Masked inlier reconstruction pretext task inside a dual-branch masked autoencoder that reconstructs keypoints of each image separately to achieve indirect 4D correspondence reconstruction using paired keypoints as positional prompts.
If this is right
- The pre-trained encoder delivers 10.76 percent higher accuracy on camera pose estimation than prior state-of-the-art pruners.
- The same encoder yields 11.84 percent gains on visual localization benchmarks.
- It produces 8.65 percent better results on 3D registration tasks.
- The dual-stream architecture with consensus interaction supplies a single extensible backbone for multiple correspondence-based pipelines.
Where Pith is reading between the lines
- The same pre-training recipe could be applied to other unordered matching problems such as multi-view feature tracking.
- If the representations truly ignore outliers, fine-tuning data requirements for new tasks could drop because the encoder already encodes geometry without false-match noise.
- Systematic variation of the masking ratio during pre-training would reveal how much geometric signal is needed to achieve the reported robustness.
Load-bearing premise
That learning to reconstruct only inliers during pre-training will keep the model from picking up outlier patterns once it sees real data that mixes both.
What would settle it
Measure whether pruning accuracy on a held-out test set degrades as the fraction of outliers is increased from 0 percent to 90 percent; if the pre-trained model shows the same sensitivity curve as a model trained directly on mixed data, the claim does not hold.
Figures
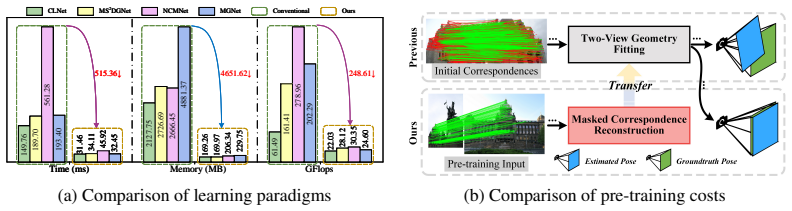

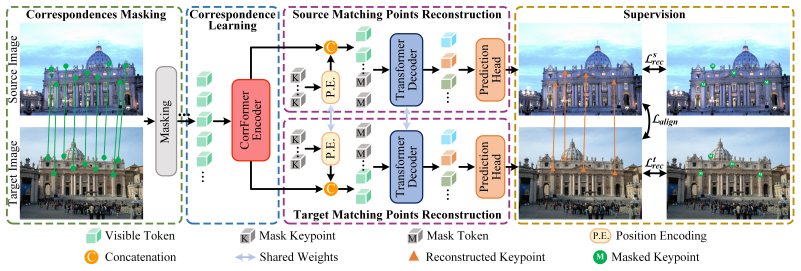
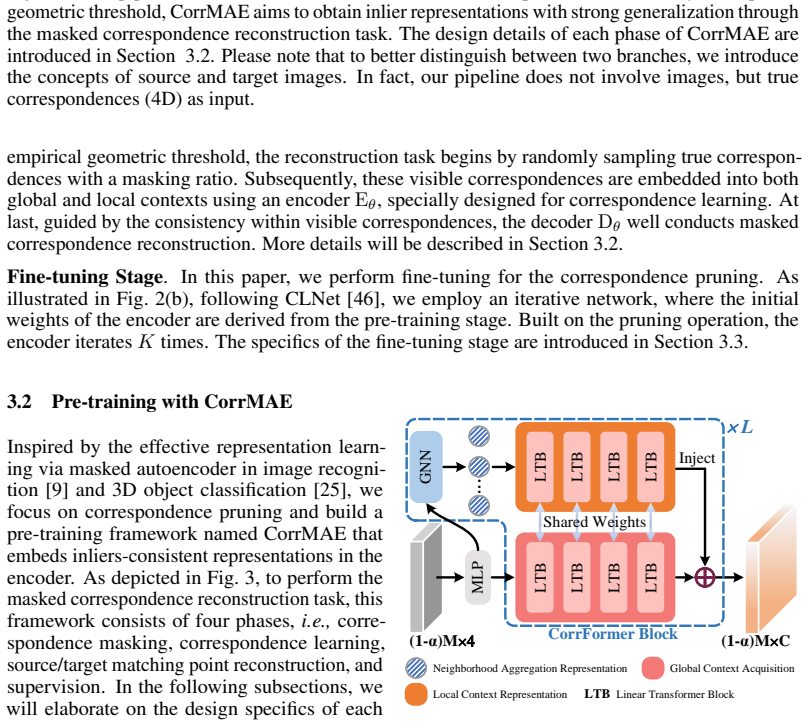


read the original abstract
Two-view correspondence pruning aims to identify reliable correspondences for camera pose estimation, serving as a fundamental step in many 3D vision tasks. Existing methods rely on geometric consistency to seek true correspondences (inliers) from numerous false correspondences (outliers). In this learning paradigm, outliers severely affect the representation learning of inliers, resulting in models that are neither robust nor generalizable. To address this issue, we propose a geometry-consistent pre-training paradigm that sculpts scalable and generalizable representations free from outlier interference. The paradigm features two appealing properties. 1) Implementation of geometry-consistent pre-training. We introduce masked inlier reconstruction as a pretext task and develop a simple yet effective pre-training framework based on a masked autoencoder. Specifically, due to the irregular and unordered nature of correspondences, which lack explicit positional information, we adopt a dual-branch structure that separately reconstructs the keypoints of two images. This enables indirect reconstruction of 4D correspondences, where keypoints from the paired image provide positional prompts. 2) Unified correspondence encoder. We propose a simple dual-stream encoder with built-in consensus interaction, providing a unified, extensible architecture that enhances representation learning. Extensive experiments demonstrate that our method, GeneralPruner, consistently outperforms state-of-the-art approaches in terms of robustness and generalization across various downstream tasks. Specifically, our method achieves 10.76%, 11.84%, and 8.65% performance gains in camera pose estimation, visual localization, and 3D registration, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeneralPruner, a correspondence pruning method based on a geometry-consistent pre-training paradigm. It introduces masked inlier reconstruction as a pretext task implemented via a dual-branch masked autoencoder (MAE) that reconstructs keypoints from paired images to handle the unordered nature of correspondences, combined with a unified dual-stream encoder incorporating built-in consensus interaction. The central claim is that this pre-training sculpts scalable, generalizable representations free from outlier interference, yielding consistent outperformance over SOTA methods with reported gains of 10.76% on camera pose estimation, 11.84% on visual localization, and 8.65% on 3D registration.
Significance. If the pre-training successfully produces representations insensitive to outliers despite never seeing mixed inlier/outlier inputs, the approach would offer a practical, extensible pre-training recipe for improving robustness in two-view geometry tasks. The dual-branch MAE design and consensus-interaction encoder are concrete contributions that could be adopted more broadly if the outlier-robustness property is substantiated.
major comments (3)
- [Abstract and §3] Abstract and §3 (pre-training framework): The central claim that the method yields 'representations free from outlier interference' rests on an unverified assumption. Pre-training performs masked reconstruction exclusively on inlier correspondences via the dual-branch MAE; no ablation, attention map analysis, or controlled test (e.g., injecting synthetic outliers at test time while measuring feature drift) is presented to demonstrate that the encoder remains unaffected by outliers when downstream inputs contain both inliers and outliers. This directly bears on the generalization and robustness claims.
- [§4] §4 (experiments): The reported performance gains (10.76%, 11.84%, 8.65%) are stated without error bars, multiple random seeds, or statistical significance tests against the baselines. In addition, the paper does not detail whether baselines were re-implemented with the same training protocols or hyper-parameters, which is required to rule out implementation artifacts when claiming consistent superiority across camera pose estimation, visual localization, and 3D registration.
- [§3.2] §3.2 (dual-stream encoder): The consensus-interaction module is presented as enhancing representation learning, yet no ablation isolates its contribution to outlier robustness versus the pre-training alone. Without this, it is unclear whether the claimed freedom from outlier interference stems from the masked inlier reconstruction objective or from the architectural choice.
minor comments (2)
- [Abstract] The abstract states quantitative gains but supplies no information on experimental protocols, baseline implementations, or statistical significance; this information should be summarized briefly even in the abstract for a methods paper.
- [Figure 2 and §3.1] Figure captions and the description of the dual-branch structure would benefit from explicit notation for how positional prompts from the paired image are injected into the MAE decoder.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (pre-training framework): The central claim that the method yields 'representations free from outlier interference' rests on an unverified assumption. Pre-training performs masked reconstruction exclusively on inlier correspondences via the dual-branch MAE; no ablation, attention map analysis, or controlled test (e.g., injecting synthetic outliers at test time while measuring feature drift) is presented to demonstrate that the encoder remains unaffected by outliers when downstream inputs contain both inliers and outliers. This directly bears on the generalization and robustness claims.
Authors: We agree that direct empirical verification of outlier insensitivity would strengthen the central claim. The pre-training objective is deliberately restricted to inliers and the dual-branch design avoids explicit outlier exposure during pre-training; however, we will add (i) attention-map visualizations on mixed inlier/outlier inputs and (ii) a controlled test that injects synthetic outliers at inference time and quantifies feature drift, to substantiate that the learned encoder remains robust. revision: yes
-
Referee: [§4] §4 (experiments): The reported performance gains (10.76%, 11.84%, 8.65%) are stated without error bars, multiple random seeds, or statistical significance tests against the baselines. In addition, the paper does not detail whether baselines were re-implemented with the same training protocols or hyper-parameters, which is required to rule out implementation artifacts when claiming consistent superiority across camera pose estimation, visual localization, and 3D registration.
Authors: We acknowledge the importance of statistical rigor and implementation transparency. In the revised manuscript we will report results over multiple random seeds with error bars and paired statistical significance tests. We will also explicitly state that all baselines were re-implemented using the identical training protocols, data splits, and hyper-parameter settings described in their original papers. revision: yes
-
Referee: [§3.2] §3.2 (dual-stream encoder): The consensus-interaction module is presented as enhancing representation learning, yet no ablation isolates its contribution to outlier robustness versus the pre-training alone. Without this, it is unclear whether the claimed freedom from outlier interference stems from the masked inlier reconstruction objective or from the architectural choice.
Authors: We will include an additional ablation that trains the dual-stream encoder both with and without the consensus-interaction module, each under the same pre-training and fine-tuning regimes, thereby isolating the module’s contribution to outlier robustness. revision: yes
Circularity Check
No circularity: empirical pre-training recipe with no self-referential derivations
full rationale
The paper introduces a masked inlier reconstruction pretext task and dual-stream encoder as an empirical pre-training method, then reports performance gains on downstream tasks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that reduce any claim to an input by construction. The central robustness claim is framed as an experimental outcome rather than a definitional or fitted tautology, rendering the work self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked autoencoder reconstruction on dual-branch keypoint streams can learn outlier-robust representations for 4D correspondences.
Reference graph
Works this paper leans on
-
[1]
Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors
Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krystian Mikolajczyk. Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 5173–5182, 2017
work page 2017
-
[2]
Magsac++, a fast, reliable and accurate robust estimator
Daniel Barath, Jana Noskova, Maksym Ivashechkin, and Jiri Matas. Magsac++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 1304–1312, 2020
work page 2020
-
[3]
Geometry-aware learning of maps for camera localization
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz. Geometry-aware learning of maps for camera localization. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 2616–2625, 2018
work page 2018
-
[4]
Traj-mae: Masked autoencoders for trajectory prediction
Hao Chen, Jiaze Wang, Kun Shao, Furui Liu, Jianye Hao, Chenyong Guan, Guangyong Chen, and Pheng-Ann Heng. Traj-mae: Masked autoencoders for trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[5]
Mgnet: Learning correspondences via multiple graphs
Luanyuan Dai, Xiaoyu Du, Hanwang Zhang, and Jinhui Tang. Mgnet: Learning correspondences via multiple graphs. In Proceedings of the AAAI conference on Artificial Intelligence, pages 3945–3953, 2024
work page 2024
-
[6]
Ms2dg-net: Progressive correspondence learning via multiple sparse semantics dynamic graph
Luanyuan Dai, Yizhang Liu, Jiayi Ma, Lifang Wei, Taotao Lai, Changcai Yang, and Riqing Chen. Ms2dg-net: Progressive correspondence learning via multiple sparse semantics dynamic graph. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pages 8973–8982, 2022
work page 2022
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, 2021
work page 2021
-
[8]
In defense of the eight-point algorithm
Richard I Hartley. In defense of the eight-point algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(6):580–593, 1997
work page 1997
-
[9]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 15979–15988, 2022
work page 2022
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[11]
Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset)
Jared Heinly, Johannes L Schonberger, Enrique Dunn, and Jan-Michael Frahm. Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset). In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 3287–3295, 2015
work page 2015
-
[12]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Lei Ba. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, pages 1–15, 2014
work page 2014
-
[13]
Aligndet: Aligning pre-training and fine-tuning in object detection
Ming Li, Jie Wu, Xionghui Wang, Chen Chen, Jie Qin, Xuefeng Xiao, Rui Wang, Min Zheng, and Xin Pan. Aligndet: Aligning pre-training and fine-tuning in object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6866–6876, 2023
work page 2023
-
[14]
Megadepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 2041–2050, 2018
work page 2041
-
[15]
U-match: two-view correspondence learning with hierarchy-aware local context aggregation
Zizhuo Li, Shihua Zhang, and Jiayi Ma. U-match: two-view correspondence learning with hierarchy-aware local context aggregation. In Proceedings of the International Joint Conference on Artificial Intelligence, pages 1169–1176, 2023
work page 2023
-
[16]
Vsformer: Visual-spatial fusion transformer for correspondence pruning
Tangfei Liao, Xiaoqin Zhang, Li Zhao, Tao Wang, and Guobao Xiao. Vsformer: Visual-spatial fusion transformer for correspondence pruning. In Proceedings of the AAAI conference on Artificial Intelligence, 2024
work page 2024
-
[17]
Pgfnet: Preference-guided filtering network for two-view correspondence learning
Xin Liu, Guobao Xiao, Riqing Chen, and Jiayi Ma. Pgfnet: Preference-guided filtering network for two-view correspondence learning. IEEE Transactions on Image Processing, 32:1367–1378, 2023. 10
work page 2023
-
[18]
Progressive neighbor consistency mining for correspondence pruning
Xin Liu and Jufeng Yang. Progressive neighbor consistency mining for correspondence pruning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pages 9527–9537, 2023
work page 2023
-
[19]
Learnable motion coherence for correspondence pruning
Yuan Liu, Lingjie Liu, Cheng Lin, Zhen Dong, and Wenping Wang. Learnable motion coherence for correspondence pruning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 3237–3246, 2021
work page 2021
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Sgdr: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. In Proceedings of the International Conference on Learning Representations, 2017
work page 2017
-
[22]
David G Lowe. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vision, 60(2):91–110, 2004
work page 2004
-
[23]
Haoming Lu, Hazarapet Tunanyan, Kai Wang, Shant Navasardyan, Zhangyang Wang, and Humphrey Shi. Specialist diffusion: Plug-and-play sample-efficient fine-tuning of text-to-image diffusion models to learn any unseen style. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 14267–14276, 2023
work page 2023
-
[24]
Orb-slam: a versatile and accurate monocular slam system
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: a versatile and accurate monocular slam system. IEEE Transactions on Robotics, 31(5):1147–1163, 2015
work page 2015
-
[25]
Masked au- toencoders for point cloud self-supervised learning
Yatian Pang, Wenxiao Wang, Francis EH Tay, Wei Liu, Yonghong Tian, and Li Yuan. Masked au- toencoders for point cloud self-supervised learning. In Proceedings of the European Conference on Computer Vision, pages 604–621. Springer, 2022
work page 2022
-
[26]
Automatic differentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017
work page 2017
-
[27]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 22500–22510, 2023
work page 2023
-
[28]
From coarse to fine: Robust hierarchical localization at large scale
Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From coarse to fine: Robust hierarchical localization at large scale. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 12716–12725, 2019
work page 2019
-
[29]
Benchmarking 6dof outdoor visual localization in changing conditions
Torsten Sattler, Will Maddern, Carl Toft, Akihiko Torii, Lars Hammarstrand, Erik Stenborg, Daniel Safari, Masatoshi Okutomi, Marc Pollefeys, Josef Sivic, et al. Benchmarking 6dof outdoor visual localization in changing conditions. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 8601–8610, 2018
work page 2018
-
[30]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Pro- ceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pages 4104–4113, 2016
work page 2016
-
[31]
Acne: Attentive context normalization for robust permutation-equivariant learning
Weiwei Sun, Wei Jiang, Eduard Trulls, Andrea Tagliasacchi, and Kwang Moo Yi. Acne: Attentive context normalization for robust permutation-equivariant learning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 11286–11295, 2020
work page 2020
-
[32]
Yfcc100m: The new data in multimedia research.Communications of the ACM, 59(2):64–73, 2016
Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: The new data in multimedia research.Communications of the ACM, 59(2):64–73, 2016
work page 2016
-
[33]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Advances in neural information processing systems, 35:10078–10093, 2022
work page 2022
-
[34]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[35]
A survey of deep face restoration: Denoise, super-resolution, deblur, artifact removal
Tao Wang, Kaihao Zhang, Xuanxi Chen, Wenhan Luo, Jiankang Deng, Tong Lu, Xiaochun Cao, Wei Liu, Hongdong Li, and Stefanos Zafeiriou. A survey of deep face restoration: Denoise, super-resolution, deblur, artifact removal. arXiv preprint arXiv:2211.02831, 2022. 11
-
[36]
Tao Wang, Kaihao Zhang, Ziqian Shao, Wenhan Luo, Bjorn Stenger, Tong Lu, Tae-Kyun Kim, Wei Liu, and Hongdong Li. Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions. International Journal of Computer Vision, pages 1–23, 2024
work page 2024
-
[37]
Dynamic graph cnn for learning on point clouds
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics, 38(5):1–12, 2019
work page 2019
-
[38]
Flowformer: Lineariz- ing transformers with conservation flows
Haixu Wu, Jialong Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Flowformer: Lineariz- ing transformers with conservation flows. In Proceedings of the International Conference on Machine Learning, 2022
work page 2022
-
[39]
Imp: Iterative matching and pose estimation with adaptive pooling
Fei Xue, Ignas Budvytis, and Roberto Cipolla. Imp: Iterative matching and pose estimation with adaptive pooling. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 21317–21326, 2023
work page 2023
-
[40]
Skeletonmae: graph- based masked autoencoder for skeleton sequence pre-training
Hong Yan, Yang Liu, Yushen Wei, Zhen Li, Guanbin Li, and Liang Lin. Skeletonmae: graph- based masked autoencoder for skeleton sequence pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5606–5618, 2023
work page 2023
-
[41]
Learning to find good correspondences
Kwang Moo Yi, Eduard Trulls, Yuki Ono, Vincent Lepetit, Mathieu Salzmann, and Pascal Fua. Learning to find good correspondences. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 2666–2674, 2018
work page 2018
-
[42]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 19313–19322, 2022
work page 2022
-
[43]
Learning two-view correspondences and geometry using order- aware network
Jiahui Zhang, Dawei Sun, Zixin Luo, Anbang Yao, Lei Zhou, Tianwei Shen, Yurong Chen, Long Quan, and Hongen Liao. Learning two-view correspondences and geometry using order- aware network. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 5845–5854, 2019
work page 2019
-
[44]
Convmatch: Rethinking network design for two-view correspon- dence learning
Shihua Zhang and Jiayi Ma. Convmatch: Rethinking network design for two-view correspon- dence learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[45]
Reference pose generation for long-term visual localization via learned features and view synthesis
Zichao Zhang, Torsten Sattler, and Davide Scaramuzza. Reference pose generation for long-term visual localization via learned features and view synthesis. International Journal of Computer Vision, 129:821–844, 2021
work page 2021
-
[46]
Progressive correspondence pruning by consensus learning
Chen Zhao, Yixiao Ge, Feng Zhu, Rui Zhao, Hongsheng Li, and Mathieu Salzmann. Progressive correspondence pruning by consensus learning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 6464–6473, 2021. 12 A Datasets YFCC100M [ 32] is collected by Yahoo and made up of 100 million photos from the Internet. The auth...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.