How Does A Text Preprocessing Pipeline Affect Ontology Matching?
Pith reviewed 2026-05-23 17:12 UTC · model grok-4.3
The pith
Tokenisation and normalisation improve ontology matching results more than stop-word removal and stemming, with two repair methods correcting false mappings from the latter steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
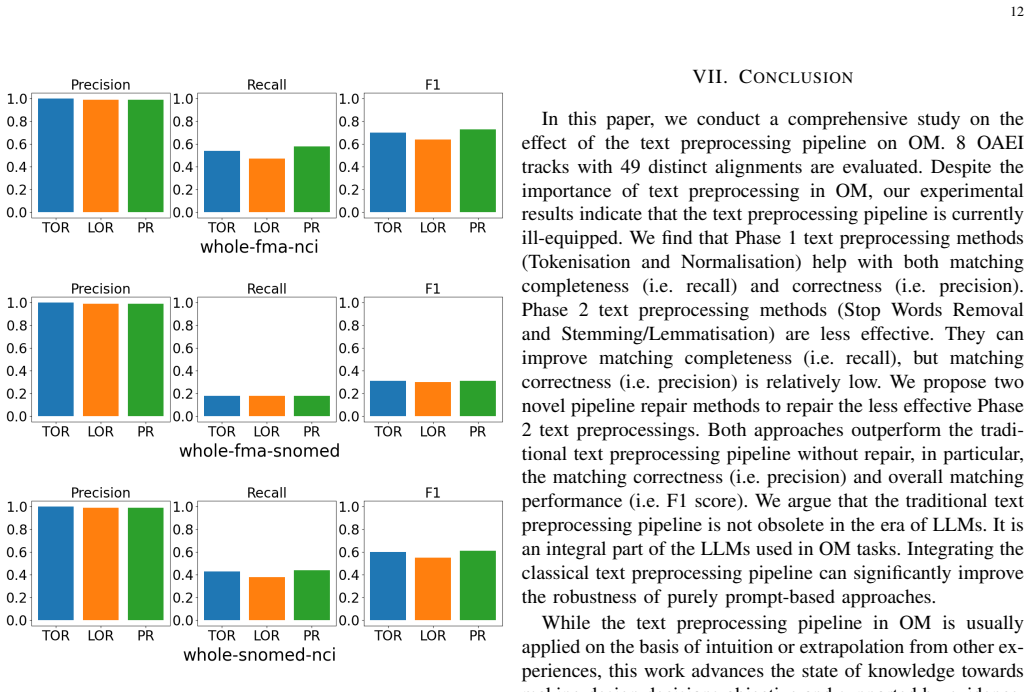
The authors establish that tokenisation and normalisation are more effective than stop-word removal and stemming or lemmatisation for ontology matching. They further establish that a pre hoc logic-based repair, which uses an ontology-specific check for common words that generate false mappings, and a post hoc LLM-based repair, which applies large language model knowledge to correct non-existent and counter-intuitive mappings, each raise matching correctness and overall performance on the tested OAEI tracks.
What carries the argument
The split of text preprocessing into Phase 1 (tokenisation and normalisation) versus Phase 2 (stop-word removal and stemming/lemmatisation), together with the pre hoc logic-based repair and post hoc LLM-based repair for Phase 2 false mappings.
If this is right
- Restricting preprocessing to Phase 1 alone produces higher match quality than running the full pipeline.
- The logic-based repair detects common words that trigger false mappings by performing an ontology-specific check before any preprocessing occurs.
- The LLM-based repair corrects non-existent and counter-intuitive mappings by drawing on external background knowledge after preprocessing finishes.
- Both repairs raise matching correctness and overall performance metrics on the evaluated OAEI alignments.
Where Pith is reading between the lines
- Systems could routinely omit Phase 2 steps unless a repair step is attached, reducing unnecessary mapping errors.
- The LLM repair might transfer to other tasks that combine structured data with unstructured text, such as knowledge graph completion.
- The pre hoc check could be turned into an automated filter that runs on any pair of ontologies before matching begins.
- Results on OAEI tracks may not capture domain-specific ontologies where word overlap patterns differ sharply from the tested cases.
Load-bearing premise
False mappings created by Phase 2 preprocessing can be identified reliably as unwanted and repaired without introducing new errors, and the OAEI tracks represent the range of real-world ontology matching cases where the repairs will generalise.
What would settle it
Apply the two repair approaches to a fresh collection of ontologies outside the eight OAEI tracks and check whether precision and F-measure rise or whether new false mappings appear.
Figures















read the original abstract
The classical text preprocessing pipeline, comprising Tokenisation, Normalisation, Stop Words Removal, and Stemming/Lemmatisation, has been implemented in many systems for ontology matching (OM). However, the lack of standardisation in text preprocessing creates diversity in the mapping results. In this paper, we investigate the effect of the text preprocessing pipeline on 8 Ontology Alignment Evaluation Initiative (OAEI) tracks with 49 distinct alignments. We find that Tokenisation and Normalisation (categorised as Phase 1 text preprocessing) are more effective than Stop Words Removal and Stemming/Lemmatisation (categorised as Phase 2 text preprocessing). We propose two novel approaches to repair unwanted false mappings that occur in Phase 2 text preprocessing. One is a pre hoc logic-based repair approach used before text preprocessing, employing an ontology-specific check to find common words that cause false mappings. The other repair approach is the post hoc large language model (LLM)-based approach, used after text preprocessing, which utilises the strong background knowledge provided by LLMs to repair non-existent and counter-intuitive false mappings. The experimental results indicate that these two approaches can significantly improve the matching correctness and the overall matching performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates the impact of a classical text preprocessing pipeline (tokenisation, normalisation, stop words removal, stemming/lemmatisation) on ontology matching across 8 OAEI tracks with 49 alignments. It claims that Phase 1 steps (tokenisation and normalisation) are more effective than Phase 2 steps, and proposes two repair methods—a pre-hoc logic-based check for common words causing false mappings and a post-hoc LLM-based repair—to correct unwanted false mappings from Phase 2, reporting significant gains in matching correctness and overall performance.
Significance. If the central claims hold after addressing validation gaps, the work could help standardise preprocessing choices in OM systems and demonstrate practical value of hybrid logic-LLM repairs on public benchmarks. The evaluation on established OAEI tracks provides a reproducible starting point, though the manuscript does not include code or parameter-free derivations.
major comments (3)
- [Experimental Evaluation] Experimental section: the claim that the two repair approaches improve correctness without introducing new errors is not supported by an explicit before/after comparison against gold-standard reference alignments or an ablation measuring introduced false positives on the 49 alignments; without this, reported gains could result from over-filtering rather than genuine improvement.
- [Methods] Methods description: full details on data exclusion rules, how false mappings are identified in Phase 2, and any statistical tests for the reported improvements across the 8 tracks are missing, preventing verification of the central claim that Phase 1 outperforms Phase 2 and that repairs are reliable.
- [Repair Approaches] Repair approaches section: the pre-hoc logic-based method uses an ontology-specific common-word check, but the manuscript provides no explicit criteria, thresholds, or validation that this check avoids post-hoc selection bias when defining unwanted mappings.
minor comments (2)
- [Preprocessing Pipeline] Clarify the exact definition and implementation of 'Phase 1' versus 'Phase 2' preprocessing steps with pseudocode or a table for reproducibility.
- [Results] The abstract and results would benefit from reporting precision, recall, and F-measure values separately for each track rather than aggregated claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and rigor of our work. We address each major comment below and will incorporate revisions to strengthen the experimental validation, methodological details, and description of the repair approaches.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section: the claim that the two repair approaches improve correctness without introducing new errors is not supported by an explicit before/after comparison against gold-standard reference alignments or an ablation measuring introduced false positives on the 49 alignments; without this, reported gains could result from over-filtering rather than genuine improvement.
Authors: We acknowledge that an explicit ablation isolating introduced false positives would provide stronger evidence. The current results report precision, recall, and F-measure improvements on the 49 alignments relative to gold standards before and after repair, but we agree this does not fully rule out over-filtering. We will add a dedicated before/after table and ablation analysis quantifying false positives introduced (or avoided) by each repair method. revision: yes
-
Referee: [Methods] Methods description: full details on data exclusion rules, how false mappings are identified in Phase 2, and any statistical tests for the reported improvements across the 8 tracks are missing, preventing verification of the central claim that Phase 1 outperforms Phase 2 and that repairs are reliable.
Authors: We agree these details are essential for reproducibility. The revised manuscript will explicitly document: (i) all data exclusion rules applied to the OAEI tracks, (ii) the precise procedure used to identify false mappings arising from Phase 2 preprocessing, and (iii) the statistical tests (including p-values) used to assess improvements across the eight tracks. revision: yes
-
Referee: [Repair Approaches] Repair approaches section: the pre-hoc logic-based method uses an ontology-specific common-word check, but the manuscript provides no explicit criteria, thresholds, or validation that this check avoids post-hoc selection bias when defining unwanted mappings.
Authors: The pre-hoc method identifies common words via an ontology-specific logical check performed prior to any preprocessing or result inspection. To address potential bias concerns, the revision will supply the exact criteria, thresholds, and decision rules employed, together with a validation step showing that word selection is driven solely by structural inconsistencies observable before mapping generation. revision: yes
Circularity Check
No circularity: empirical evaluation on external OAEI benchmarks
full rationale
The paper reports experimental results from applying text preprocessing phases and two repair methods to 49 alignments across 8 public OAEI tracks. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. All performance claims (Phase 1 vs Phase 2 effectiveness; repair improvements) rest on direct comparison against the fixed OAEI gold standards rather than reducing to the paper's own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
G. Stephan, H. Pascal, and A. Andreas,Knowledge Representation and Ontologies. Berlin, Heidelberg, Germany: Springer, 2007, pp. 51–105
work page 2007
-
[2]
J. Euzenat and P. Shvaiko,Ontology Matching (2nd ed.). Berlin, Heidelberg, Germany: Springer, 2013
work page 2013
-
[3]
C. D. Manning, P. Raghavan, and H. Sch ¨utze,Introduction to Informa- tion Retrieval. Cambridge, UK: Cambridge University Press, 2008
work page 2008
-
[4]
Ontology alignment evaluation initiative (oaei)
OAEI Community, “Ontology alignment evaluation initiative (oaei).” [Online]. Available: https://oaei.ontologymatching.org
-
[5]
A translation approach to portable ontology specifica- tions,
T. R. Gruber, “A translation approach to portable ontology specifica- tions,”Knowledge Acquisition, vol. 5, no. 2, pp. 199–220, 1993
work page 1993
-
[6]
Ontology development 101: A guide to creating your first ontology,
N. F. Noy, D. L. McGuinnesset al., “Ontology development 101: A guide to creating your first ontology,” 2001
work page 2001
-
[7]
OBO Foundry, “Principles: Overview.” [Online]. Available: https: //obofoundry.org/principles/fp-000-summary.html
-
[8]
LogMap: Logic-based and scalable ontology matching,
E. Jim ´enez-Ruiz and B. Cuenca Grau, “LogMap: Logic-based and scalable ontology matching,” inThe Semantic Web – ISWC 2011. Bonn, Germany: Springer, 2011, pp. 273–288
work page 2011
-
[9]
LogMap 2.0: towards logic- based, scalable and interactive ontology matching,
E. Jim ´enez-Ruiz, B. C. Grau, and Y . Zhou, “LogMap 2.0: towards logic- based, scalable and interactive ontology matching,” inProceedings of the 4th International Workshop on Semantic Web Applications and Tools for the Life Sciences. London, UK: ACM, 2011, pp. 45–46
work page 2011
-
[10]
The AgreementMakerLight ontology matching system,
D. Faria, C. Pesquita, E. Santos, M. Palmonari, I. F. Cruz, and F. M. Couto, “The AgreementMakerLight ontology matching system,” inOn the Move to Meaningful Internet Systems: OTM 2013 Conferences. Graz, Austria: Springer, 2013, pp. 527–541
work page 2013
-
[11]
Agree- mentMakerLight 2.0: towards efficient large-scale ontology matching,
D. Faria, C. Pesquita, E. Santos, I. F. Cruz, and F. M. Couto, “Agree- mentMakerLight 2.0: towards efficient large-scale ontology matching,” inProceedings of the ISWC 2014 Posters and Demonstrations Track, vol. 1272. Riva del Garda, Italy: CEUR-WS.org, 2014, pp. 457–460
work page 2014
-
[12]
Matching biomedical ontologies based on formal concept analysis,
M. Zhao, S. Zhang, W. Li, and G. Chen, “Matching biomedical ontologies based on formal concept analysis,”Journal of Biomedical Semantics, vol. 9, 2018
work page 2018
-
[13]
Combining FCA-Map with representation learning for aligning large biomedical ontologies,
G. Li, S. Zhang, J. Wei, and W. Ye, “Combining FCA-Map with representation learning for aligning large biomedical ontologies,” in Proceedings of the 16th International Workshop on Ontology Matching – ISWC 2021, vol. 3063. Virtual Conference: CEUR-WS.org, 2021, pp. 207–208
work page 2021
-
[14]
Agent-OM: Leveraging LLM Agents for Ontology Matching , 2024
Z. Qiang, W. Wang, and K. Taylor, “Agent-OM: Leveraging LLM agents for ontology matching,” 2023. [Online]. Available: https://arxiv.org/abs/2312.00326
-
[15]
AgreementMaker: Efficient matching for large real-world schemas and ontologies,
I. F. Cruz, F. P. Antonelli, and C. Stroe, “AgreementMaker: Efficient matching for large real-world schemas and ontologies,”Proceedings of the VLDB Endowment, vol. 2, no. 2, pp. 1586–1589, 2009
work page 2009
-
[16]
SAMBO—a system for aligning and merging biomedical ontologies,
P. Lambrix and H. Tan, “SAMBO—a system for aligning and merging biomedical ontologies,”Journal of Web Semantics, vol. 4, no. 3, pp. 196–206, 2006
work page 2006
-
[17]
RiMOM: A dynamic multistrategy ontology alignment framework,
J. Li, J. Tang, Y . Li, and Q. Luo, “RiMOM: A dynamic multistrategy ontology alignment framework,”IEEE Transactions on Knowledge and Data Engineering, vol. 21, no. 8, pp. 1218–1232, 2009
work page 2009
-
[18]
BERTMap: A BERT- based ontology alignment system,
Y . He, J. Chen, D. Antonyrajah, and I. Horrocks, “BERTMap: A BERT- based ontology alignment system,” inProceedings of the 36th AAAI Conference on Artificial Intelligence, vol. 36. Virtual Conference: AAAI Press, 2022, pp. 5684–5691
work page 2022
-
[19]
DeepOnto: A python package for ontology engineering with deep learning,
Y . He, J. Chen, H. Dong, I. Horrocks, C. Allocca, T. Kim, and B. Sapkota, “DeepOnto: A python package for ontology engineering with deep learning,”Semantic Web, vol. 15, no. 5, pp. 1991–2004, 2024
work page 1991
-
[20]
EL embeddings: Geometric construction of models for the description logic EL++,
M. Kulmanov, W. Liu-Wei, Y . Yan, and R. Hoehndorf, “EL embeddings: Geometric construction of models for the description logic EL++,” in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macao, China: IJCAI, 2019, pp. 6103–6109
work page 2019
-
[21]
Augmenting ontology alignment by semantic embedding and distant supervision,
J. Chen, E. Jim ´enez-Ruiz, I. Horrocks, D. Antonyrajah, A. Hadian, and J. Lee, “Augmenting ontology alignment by semantic embedding and distant supervision,” inThe Semantic Web – ESWC 2021. Virtual Conference: Springer, 2021, pp. 392–408
work page 2021
-
[22]
Exploring large language models for ontology alignment,
Y . He, J. Chen, H. Dong, and I. Horrocks, “Exploring large language models for ontology alignment,” inProceedings of the ISWC 2023 Posters, Demos and Industry Tracks, vol. 3632. Athens, Greece: CEUR- WS.org, 2023
work page 2023
-
[23]
Conversational on- tology alignment with chatgpt,
S. S. Norouzi, M. S. Mahdavinejad, and P. Hitzler, “Conversational on- tology alignment with chatgpt,” inProceedings of the 18th International Workshop on Ontology Matching – ISWC 2023, vol. 3591. Athens, Greece: CEUR-WS.org, 2023, pp. 61–66
work page 2023
-
[24]
OLaLa: Ontology matching with large language models,
S. Hertling and H. Paulheim, “OLaLa: Ontology matching with large language models,” inProceedings of the 12th Knowledge Capture Conference 2023. Pensacola, Florida, USA: ACM, 2023, pp. 131–139
work page 2023
-
[25]
LLMs4OM: Matching ontologies with large language models,
H. B. Giglou, J. D’Souza, F. Engel, and S. Auer, “LLMs4OM: Matching ontologies with large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2404.10317
-
[26]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” inProceedings of the 34th Annual Conference on Neural Information Processing Systems, vol. 33. Vancouver, BC, Canada: Curran Associates Inc., 202...
work page 2020
-
[27]
OpenAI, “Function calling.” [Online]. Available: https://platform.openai. com/docs/guides/function-calling/function-calling
-
[28]
Ontology matching with large language models and prioritized depth-first search,
M. Taboada, D. Martinez, M. Arideh, and R. Mosquera, “Ontology matching with large language models and prioritized depth-first search,” Information Fusion, vol. 123, p. 103254, 2025
work page 2025
-
[29]
Towards complex ontology alignment using large language models,
R. Amini, S. S. Norouzi, P. Hitzler, and R. Amini, “Towards complex ontology alignment using large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2404.10329
-
[30]
Towards pattern-based complex ontology matching using sparql and llm,
O. Zamazal, “Towards pattern-based complex ontology matching using sparql and llm,” inPosters, Demos, Workshops, and Tutorials of the 20th International Conference on Semantic Systems (SEMANTiCS 2024), vol
work page 2024
-
[31]
Amsterdam, Netherlands: CEUR-WS.org, 2024
work page 2024
-
[32]
Complex ontology matching with large language model embeddings,
G. Sousa, R. Lima, and C. Trojahn, “Complex ontology matching with large language model embeddings,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13619
-
[33]
MELT - matching evaluation toolkit,
S. Hertling, J. Portisch, and H. Paulheim, “MELT - matching evaluation toolkit,” inSemantic Systems. The Power of AI and Knowledge Graphs - 15th International Conference, vol. 11702. Karlsruhe, Germany: Springer, 2019, pp. 231–245
work page 2019
-
[34]
A reference ontology for biomedical informatics: the foundational model of anatomy,
C. Rosse and J. L. Mejino, “A reference ontology for biomedical informatics: the foundational model of anatomy,”Journal of Biomedical Informatics, vol. 36, no. 6, pp. 478–500, 2003
work page 2003
-
[35]
The national cancer institute’s thesaurus and ontology,
J. Golbeck, G. Fragoso, F. Hartel, J. Hendler, J. Oberthaler, and B. Parsia, “The national cancer institute’s thesaurus and ontology,”Journal of Web Semantics, vol. 1, no. 1, pp. 75–80, 2003
work page 2003
-
[36]
SNOMED-CT: The advanced terminology and coding system for ehealth,
K. Donnelly, “SNOMED-CT: The advanced terminology and coding system for ehealth,”Studies in health technology and informatics, vol. 121, p. 279, 2006
work page 2006
-
[37]
Yago: A core of semantic knowledge unifying wordnet and wikipedia,
F. M. Suchanek, G. Kasneci, and G. Weikum, “Yago: A core of semantic knowledge unifying wordnet and wikipedia,” inProceedings of the 16th International Conference on World Wide Web. Banff, Alberta, Canada: ACM, 2007, pp. 697—-706
work page 2007
-
[38]
Wikidata: A free collaborative knowl- edgebase,
D. Vrande ˇci´c and M. Kr ¨otzsch, “Wikidata: A free collaborative knowl- edgebase,”Communications of the ACM, vol. 57, no. 10, pp. 78—-85, 2014
work page 2014
-
[39]
A new algorithm for data compression,
P. Gage, “A new algorithm for data compression,”The C Users Journal, vol. 12, no. 2, pp. 23–38, 1994
work page 1994
-
[40]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: ACL, 2016, pp. 1715–1725. 14
work page 2016
-
[41]
Japanese and korean voice search,
M. Schuster and K. Nakajima, “Japanese and korean voice search,” in International Conference on Acoustics, Speech and Signal Processing. Kyoto, Japan: IEEE, 2012, pp. 5149–5152
work page 2012
-
[42]
BERT: Pre- training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota, USA: ACL, 2019, pp. 4171– 4186
work page 2019
-
[43]
T. Kudo, “Subword regularization: Improving neural network transla- tion models with multiple subword candidates,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: ACL, 2018, pp. 66–75
work page 2018
-
[44]
T. Kudo and J. Richardson, “Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text process- ing,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Brussels, Belgium: ACL, 2018, pp. 66–71
work page 2018
-
[45]
Multidisciplinary instruction with the natural language toolkit,
S. Bird, E. Klein, E. Loper, and J. Baldridge, “Multidisciplinary instruction with the natural language toolkit,” inProceedings of the Third Workshop on Issues in Teaching Computational Linguistics. Columbus, Ohio, USA: ACL, 2008, pp. 62–70. [Online]. Available: https://aclanthology.org/W08-0208
work page 2008
-
[46]
WordNet: A lexical database for english,
G. A. Miller, “WordNet: A lexical database for english,”Communica- tions of the ACM, vol. 38, no. 11, pp. 39–41, 1995
work page 1995
-
[47]
Semantic precision and recall for ontology alignment evaluation,
J. Euzenat, “Semantic precision and recall for ontology alignment evaluation,” inProceedings of the 20th International Joint Conference on Artificial Intelligence. Hyderabad, India: AAAI Press, 2007, pp. 348–353
work page 2007
-
[48]
seaborn: statistical data visualization,
M. L. Waskom, “seaborn: statistical data visualization,”Journal of Open Source Software, vol. 6, no. 60, p. 3021, 2021
work page 2021
-
[49]
Towards naming con- ventions for use in controlled vocabulary and ontology engineering,
D. Schober, W. Kusnierczyk, S. E. Lewis, J. Lomax, C. J. Mungall, P. Rocca-Serra, B. Smith, and S.-A. Sansone, “Towards naming con- ventions for use in controlled vocabulary and ontology engineering,” inThe 10th Annual Bio-Ontologies Meeting. Vienna, Austria: Oxford University Press, 2007
work page 2007
-
[50]
Spatial data on the web working group: Ontology design principles,
K. Taylor, S. Cox, and L. van den Brink, “Spatial data on the web working group: Ontology design principles,” 2015. [Online]. Available: https://www.w3.org/2015/spatial/wiki/Ontology Design Principles
work page 2015
-
[51]
OpenAI, “OpenAI models.” [Online]. Available: https://platform.openai. com/docs/models
-
[52]
Anthropic, “Claude models.” [Online]. Available: https://docs.anthropic. com/en/docs/about-claude/models
- [53]
-
[54]
Alibaba Qwen Team, “Qwen models.” [Online]. Available: https: //qwenlm.github.io
-
[55]
Google Gemma Team and Google DeepMind, “Google gemma models.” [Online]. Available: https://ai.google.dev/gemma
-
[56]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhao, H. Lai, H. Yu, H. Wang, J. Sun, J. Zhang, J. Cheng, J. Gui, J. Tang, J. Zhang, J. Sun, J. Li, L. Zhao, L. Wu, L. Zhong, M. Liu, M. Huang, P. Zhang, Q. Zheng, R. Lu, S. Duan, S. Zhang, S. Cao, S. Yang, W. L. Tam, W. Zhao, X. Liu, X. Xia, X. Zhang, X. Gu, X. Lv, X. Liu, X. Liu,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [57]
- [58]
-
[59]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
X. Chen, J. Xu, T. Liang, Z. He, J. Pang, D. Yu, L. Song, Q. Liu, M. Zhou, Z. Zhang, R. Wang, Z. Tu, H. Mi, and D. Yu, “Do not think that much for 2+3=? on the overthinking of o1-like LLMs,” 2025. [Online]. Available: https://arxiv.org/abs/2412.21187
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.