Nonlinear Assimilation via Score-based Sequential Langevin Sampling
Pith reviewed 2026-05-23 16:52 UTC · model grok-4.3
The pith
Score-based sequential Langevin sampling establishes asymptotic stability for nonlinear data assimilation by bounding error accumulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SSLS decomposes nonlinear assimilation into alternating prediction and update phases, employs score-based Langevin dynamics with annealing during the update phase, and supplies explicit total-variation error bounds that establish asymptotic stability: local posterior-sampling errors remain controlled and do not accumulate indefinitely over time.
What carries the argument
Score-based sequential Langevin sampling (SSLS) with integrated annealing inside the recursive Bayesian update step.
If this is right
- The derived total-variation bounds give explicit dependence of the error on the number of Langevin steps and the annealing schedule.
- Local sampling errors remain bounded across arbitrary numbers of assimilation cycles.
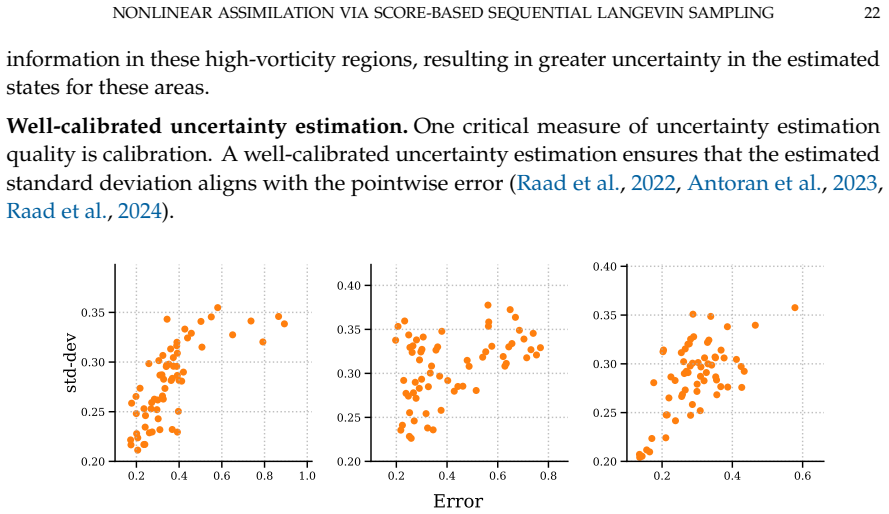
- The method supplies calibrated uncertainty estimates for the state trajectory in high-dimensional nonlinear settings.
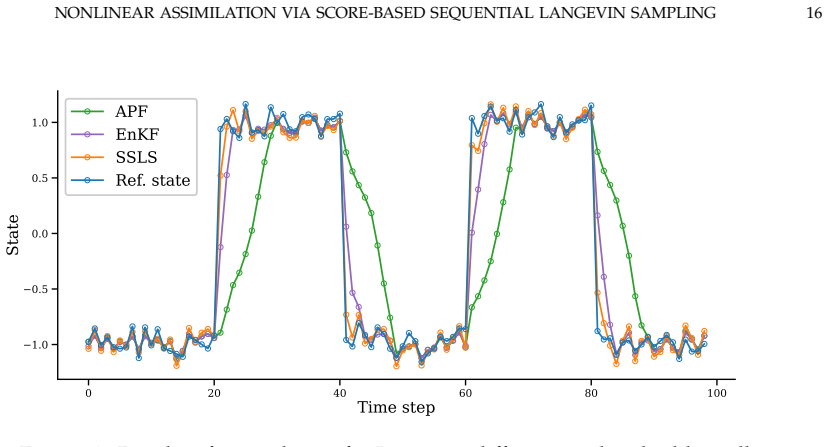
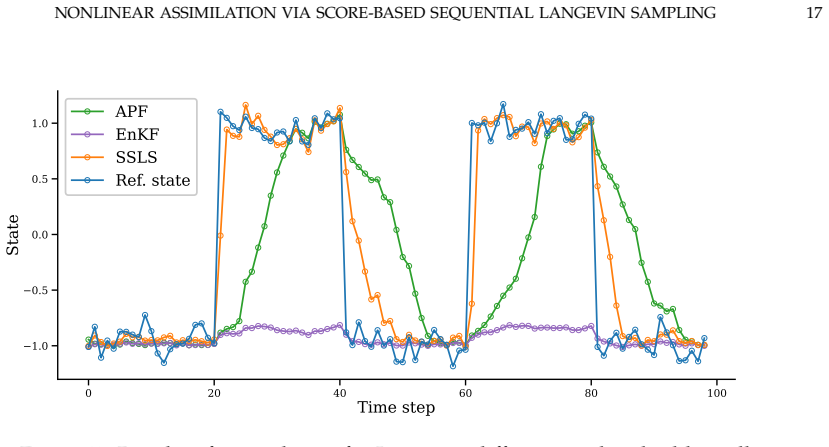
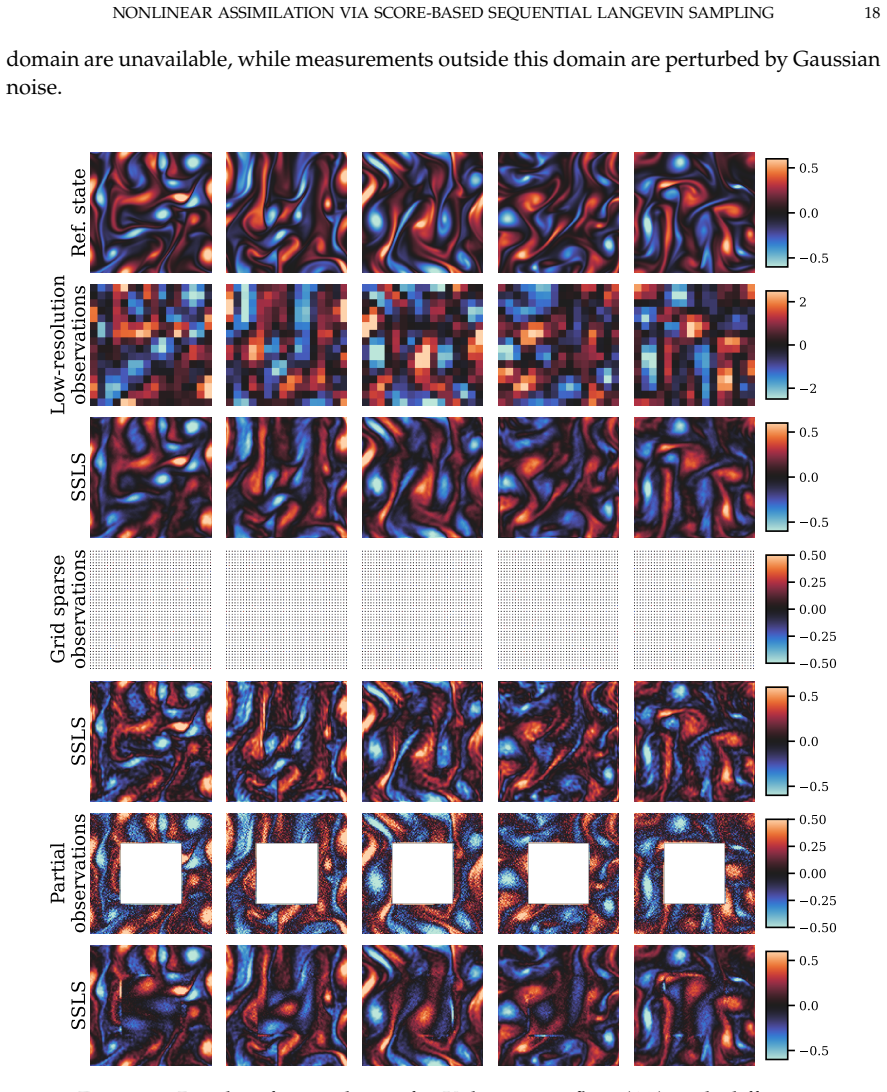
- Performance holds under sparse observations and strong nonlinearity.
Where Pith is reading between the lines
- The stability result could be checked by monitoring total-variation distance on a controlled linear-Gaussian problem where the exact posterior is known.
- If annealing is the key enabler, replacing it with other tempering schemes might preserve the same error bounds.
- The recursive structure suggests direct extension to online filtering where new observations arrive continuously.
Load-bearing premise
The annealing schedule is sufficient to make score-based Langevin sampling reliable even for highly non-log-concave posteriors.
What would settle it
A sequence of assimilation steps long enough that the total-variation distance between the SSLS output and the true filtering distribution grows unbounded.
Figures











read the original abstract
This paper introduces score-based sequential Langevin sampling (SSLS), a novel approach to nonlinear data assimilation within a recursive Bayesian filtering framework. The proposed method decomposes the assimilation process into alternating prediction and update steps, using dynamic models for state prediction and incorporating observational data via score-based Langevin Monte Carlo during the updates. To overcome inherent challenges in highly non-log-concave posterior sampling, we integrate an annealing strategy into the update mechanism. Theoretically, we establish convergence guarantees for SSLS in total variation (TV) distance, yielding concrete insights into the algorithm's error behavior with respect to key hyperparameters. Crucially, our derived error bounds demonstrate the asymptotic stability of SSLS, guaranteeing that local posterior sampling errors do not accumulate indefinitely over time. Extensive numerical experiments across challenging scenarios, including high-dimensional systems, strong nonlinearity, and sparse observations, highlight the robust performance of the proposed method. Furthermore, SSLS effectively quantifies the uncertainty associated with state estimates, rendering it particularly valuable for reliable error calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces score-based sequential Langevin sampling (SSLS) for nonlinear data assimilation in a recursive Bayesian filtering setting. It alternates dynamic-model prediction steps with score-based Langevin Monte Carlo updates that incorporate an annealing schedule to sample from non-log-concave posteriors. The central theoretical contribution is a set of total-variation error bounds that establish asymptotic stability, ensuring local sampling errors do not accumulate over time. Numerical experiments on high-dimensional, strongly nonlinear, and sparsely observed systems are presented to illustrate performance and uncertainty quantification.
Significance. If the TV bounds and their dependence on the annealing schedule are correctly established, the work supplies a theoretically grounded alternative to existing nonlinear assimilation schemes that also quantifies posterior uncertainty. The explicit stability result with respect to hyperparameters is a concrete strength.
minor comments (3)
- The abstract states that the annealing strategy overcomes challenges in non-log-concave sampling, but the precise schedule (temperature sequence, number of steps per temperature) is not summarized in the introduction; a short paragraph or table listing the schedule parameters used in the experiments would improve reproducibility.
- Notation for the score function and the Langevin dynamics is introduced without an explicit reference to the standard definition (e.g., the Ornstein-Uhlenbeck or overdamped Langevin SDE); adding one sentence with the SDE would clarify the update step for readers outside the score-based sampling community.
- Figure captions for the high-dimensional experiments should state the dimension, observation sparsity ratio, and the precise metric (RMSE, coverage, etc.) plotted; several captions currently omit these quantities.
Simulated Author's Rebuttal
We thank the referee for their careful reading and positive assessment of the manuscript. The recommendation for minor revision is appreciated, and we note that no specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper introduces SSLS as a new algorithmic decomposition into prediction and update steps with score-based Langevin Monte Carlo and annealing, then derives independent TV-distance convergence bounds showing asymptotic stability. No quoted equations or self-citations reduce any central claim (error bounds, stability guarantee) to fitted inputs, self-definitions, or prior author results by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Rethinking Forward Processes for Score-Based Nonlinear Data Assimilation in High Dimensions
A measurement-aware forward process for score-based data assimilation yields an exact likelihood score for linear measurements by construction.
-
Rethinking Forward Processes for Score-Based Nonlinear Data Assimilation in High Dimensions
MASF redesigns the forward diffusion process to align with measurements, yielding a theoretically grounded likelihood score and up to 28.2x speedup on O(10^5)-dimensional Kolmogorov flow under sparse and nonlinear obs...
Reference graph
Works this paper leans on
-
[1]
Jonas Adler and Ozan \"O ktem. Deep B ayesian inversion. In Tatiana A. Bubba, editor, Data-driven Models in Inverse Problems, volume 31 of Radon Series on Computational and Applied Mathematics, pages 359--412. Berlin, Boston: De Gruyter, 2025
work page 2025
- [2]
-
[3]
Jeffrey L. Anderson and Stephen L. Anderson. A M onte C arlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts. Monthly Weather Review, 121: 0 2741--2758, 1999
work page 1999
-
[4]
Uncertainty estimation for computed tomography with a linearised deep image prior
Javier Antoran, Riccardo Barbano, Johannes Leuschner, Jos \'e Miguel Hern \'a ndez-Lobato, and Bangti Jin. Uncertainty estimation for computed tomography with a linearised deep image prior. Transactions on Machine Learning Research, 2023. ISSN 2835--8856
work page 2023
-
[5]
Dominique Bakr, Ivan Gentil, and Michel Ledoux. Analysis and Geometry of Markov Diffusion Operators, volume 348 of Grundlehren der mathematischen Wissenschaften (GL). Springer Cham, first edition, 2014
work page 2014
-
[6]
A score-based filter for nonlinear data assimilation
Feng Bao, Zezhong Zhang, and Guannan Zhang. A score-based filter for nonlinear data assimilation. Journal of Computational Physics, 514: 0 113207, 2024. ISSN 0021-9991
work page 2024
-
[7]
Curse-of-dimensionality revisited: C ollapse of the particle filter in very large scale systems
Thomas Bengtsson, Peter Bickel, and Bo Li. Curse-of-dimensionality revisited: C ollapse of the particle filter in very large scale systems. In Deborah Nolan and Terry Speed, editors, Institute of Mathematical Statistics Collections, Probability and Statistics: Essays in Honor of David A. Freedman, pages 316--334. Institute of Mathematical Statistics, 2008
work page 2008
-
[8]
Alexandros Beskos, Ajay Jasra, Ege A. Muzaffer, and Andrew M. Stuart. Sequential M onte C arlo methods for B ayesian elliptic inverse problems. Statistics and Computing, 25: 0 727--737, 2015
work page 2015
-
[9]
Stochastic Filtering with Applications in Finance
Ramaprasad Bhar. Stochastic Filtering with Applications in Finance. World Scientific, 2010
work page 2010
-
[10]
Sharp failure rates for the bootstrap particle filter in high dimensions
Peter Bickel, Bo Li, and Thomas Bengtsson. Sharp failure rates for the bootstrap particle filter in high dimensions. In Bertrand Clarke and Subhashis Ghosal, editors, Institute of Mathematical Statistics Collections, Pushing the Limits of Contemporary Statistics: Contributions in Honor of Jayanta K. Ghosh, pages 318--329. Institute of Mathematical Statist...
work page 2008
-
[11]
Evaluating raw ensembles with the continuous ranked probability score
Jochen Br \"o cker. Evaluating raw ensembles with the continuous ranked probability score. Quarterly Journal of the Royal Meteorological Society, 138 0 (667): 0 1611--1617, 2012
work page 2012
-
[12]
Normalizing constants of log-concave densities
Nicolas Brosse, Alain Durmus, and \'E ric Moulines. Normalizing constants of log-concave densities. Electronic Journal of Statistics, 12 0 (1): 0 851 -- 889, 2018
work page 2018
-
[13]
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[14]
Sinho Chewi. Log-concave sampling, 2024. URL https://chewisinho.github.io/main.pdf. unfinished draft
work page 2024
-
[15]
Erdogdu, Mufan Li, Ruoqi Shen, and Matthew S
Sinho Chewi, Murat A. Erdogdu, Mufan Li, Ruoqi Shen, and Matthew S. Zhang. Analysis of L angevin M onte C arlo from P oincar \'e to log- S obolev. Foundations of Computational Mathematics, 2024
work page 2024
-
[16]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[17]
Bayesian inverse problems for functions and applications to fluid mechanics
S L Cotter, M Dashti, J C Robinson, and A M Stuart. Bayesian inverse problems for functions and applications to fluid mechanics. Inverse Problems, 25 0 (11): 0 115008, 2009
work page 2009
-
[18]
Sequential M onte C arlo samplers
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential M onte C arlo samplers. Journal of the Royal Statistical Society Series B: Statistical Methodology, 68 0 (3): 0 411--436, 05 2006
work page 2006
-
[19]
Sequential Monte Carlo Methods in Practice
Arnaud Doucet, Nando Freitas, and Neil Gordon, editors. Sequential Monte Carlo Methods in Practice. Information Science and Statistics (ISS). Springer New York, NY, first edition, 2001
work page 2001
-
[20]
John C. Duchi. Information theory and statistics, 2024. URL http://web.stanford.edu/class/stats311/lecture-notes.pdf. unfinished draft
work page 2024
-
[21]
Robert J. Elliott and Tak Kuen Siu. Option pricing and filtering with hidden M arkov-modulated pure-jump processes. Applied Mathematical Finance, 20 0 (1): 0 1--25, 2013
work page 2013
-
[22]
Vossepoel, and Peter Jan van Leeuwen
Geir Evensen, Femke C. Vossepoel, and Peter Jan van Leeuwen. Data Assimilation Fundamentals: A Unified Formulation of the State and Parameter Estimation Problem. Springer Textbooks in Earth Sciences, Geography and Environment (STEGE). Springer Cham, first edition, 2022
work page 2022
-
[23]
Pricing and hedging of credit derivatives via the innovations approach to nonlinear filtering
R \"u diger Frey and Thorsten Schmidt. Pricing and hedging of credit derivatives via the innovations approach to nonlinear filtering. Finance and Stochastics, 16: 0 105--133, 2012
work page 2012
-
[24]
Estimating normalizing constants for log-concave distributions: algorithms and lower bounds
Rong Ge, Holden Lee, and Jianfeng Lu. Estimating normalizing constants for log-concave distributions: algorithms and lower bounds. In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, STOC 2020, pages 579--586. Association for Computing Machinery, 2020
work page 2020
-
[25]
Tilmann Gneiting, Fadoua Balabdaoui, and Adrian E. Raftery. Probabilistic forecasts, calibration and sharpness. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 69 0 (2): 0 243--268, 2007
work page 2007
-
[26]
N.J. Gordon, D.J. Salmond, and A.F.M. Smith. Novel approach to nonlinear/non- G aussian B ayesian state estimation. IEE Proceedings on Radar and Signal Processing, 140: 0 107--113, 1993
work page 1993
-
[27]
Gradient guidance for diffusion models: A n optimization perspective, 2024
Yingqing Guo, Hui Yuan, Yukang Yang, Minshuo Chen, and Mengdi Wang. Gradient guidance for diffusion models: A n optimization perspective, 2024. arXiv:2404.14743
-
[28]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 6840--6851. Curran Associates, Inc., 2020
work page 2020
-
[29]
Data assimilation using an ensemble kalman filter technique
Peter L Houtekamer and Herschel L Mitchell. Data assimilation using an ensemble kalman filter technique. Monthly weather review, 126 0 (3): 0 796--811, 1998
work page 1998
-
[30]
Estimation of non-normalized statistical models by score matching
Aapo Hyv \"a rinen. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6 0 (24): 0 695--709, 2005
work page 2005
-
[31]
Robust compressed sensing MRI with deep generative priors
Ajil Jalal, Marius Arvinte, Giannis Daras, Eric Price, Alexandros G Dimakis, and Jon Tamir. Robust compressed sensing MRI with deep generative priors. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 14938--14954. Curran Associates, Inc., 2021
work page 2021
-
[32]
Yuling Jiao, Guohao Shen, Yuanyuan Lin, and Jian Huang. Deep nonparametric regression on approximate manifolds: Nonasymptotic error bounds with polynomial prefactors. The Annals of Statistics, 51 0 (2): 0 691 -- 716, 2023
work page 2023
-
[33]
Nikolas Kantas, Alexandros Beskos, and Ajay Jasra. Sequential M onte C arlo methods for high-dimensional inverse problems: A case study for the N avier- S tokes equations. SIAM/ASA Journal on Uncertainty Quantification, 2 0 (1): 0 464--489, 2014
work page 2014
-
[34]
Numerical Weather Prediction and Data Assimilation
Petros Katsafados, Elias Mavromatidis, and Christos Spyrou. Numerical Weather Prediction and Data Assimilation. John Wiley & Sons, Ltd, 2020
work page 2020
-
[35]
Monte C arlo filter and smoother for non- G aussian nonlinear state space models
Genshiro Kitagawa. Monte C arlo filter and smoother for non- G aussian nonlinear state space models. Journal of Computational and Graphical Statistics, 5 0 (1): 0 1--25, 1996
work page 1996
-
[36]
Smith, Ayya Alieva, Qing Wang, Michael P
Dmitrii Kochkov, Jamie A. Smith, Ayya Alieva, Qing Wang, Michael P. Brenner, and Stephan Hoyer. Machine learning-accelerated computational fluid dynamics. Proceedings of the National Academy of Sciences, 118 0 (21): 0 e2101784118, 2021
work page 2021
-
[37]
On the rate of convergence of fully connected deep neural network regression estimates
Michael Kohler and Sophie Langer. On the rate of convergence of fully connected deep neural network regression estimates. The Annals of Statistics, 49 0 (4): 0 2231--2249, 2021
work page 2021
-
[38]
Data Assimilation: A Mathematical Introduction, volume 62 of Texts in Applied Mathematics (TAM)
Kody Law, Andrew Stuart, and Konstantinos Zygalakis. Data Assimilation: A Mathematical Introduction, volume 62 of Texts in Applied Mathematics (TAM). Springer Cham, first edition, 2015
work page 2015
-
[39]
Fran c ois-Xavier Le Dimet and Olivier Talagrand. Variational algorithms for analysis and assimilation of meteorological observations: theoretical aspects. Tellus A, 38A 0 (2): 0 97--110, 1986
work page 1986
-
[40]
Convergence for score-based generative modeling with polynomial complexity
Holden Lee, Jianfeng Lu, and Yixin Tan. Convergence for score-based generative modeling with polynomial complexity. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 22870--22882. Curran Associates, Inc., 2022
work page 2022
-
[41]
State-observation augmented diffusion model for nonlinear assimilation, 2024
Zhuoyuan Li, Bin Dong, and Pingwen Zhang. State-observation augmented diffusion model for nonlinear assimilation, 2024. arXiv:2407.21314
-
[42]
Andrew J. Majda and John Harlim. Filtering Complex Turbulent Systems. Cambridge University Press, 2012
work page 2012
-
[43]
Jan Mandel, Loren Cobb, and Jonathan D. Beezley. On the convergence of the ensemble kalman filter. Applications of Mathematics, 56: 0 533--541, 2012
work page 2012
-
[44]
Dhruv V. Patel and Assad A. Oberai. GAN -based priors for quantifying uncertainty in supervised learning. SIAM/ASA Journal on Uncertainty Quantification, 9 0 (3): 0 1314--1343, 2021
work page 2021
- [45]
-
[46]
Filtering via simulation: Auxiliary particle filters
Michael K Pitt and Neil Shephard. Filtering via simulation: Auxiliary particle filters. Journal of the American statistical association, 94 0 (446): 0 590--599, 1999
work page 1999
-
[47]
Posterior sampling via L angevin dynamics based on generative priors, 2024
Vishal Purohit, Matthew Repasky, Jianfeng Lu, Qiang Qiu, Yao Xie, and Xiuyuan Cheng. Posterior sampling via L angevin dynamics based on generative priors, 2024. arXiv:2410.02078
-
[48]
Ragheb Raad, Dhruv Patel, Chiao-Chih Hsu, Vijay Kothapalli, Deep Ray, Bino Varghese, Darryl Hwang, Inderbir Gill, Vinay Duddalwar, and Assad A. Oberai. Probabilistic medical image imputation via deep adversarial learning. Engineering with Computers, 38: 0 3975--3986, 2022
work page 2022
-
[49]
Ragheb Raad, Deep Ray, Bino Varghese, Darryl Hwang, Inderbir Gill, Vinay Duddalwar, and Assad A. Oberai. Conditional generative learning for medical image imputation. Scientific Reports, 14 0 (171), 2024
work page 2024
-
[50]
Firas Rassoul-Agha and Timo Sepp \"a l \"a inen. A Course on Large Deviations with an Introduction to Gibbs Measures, volume 162 of Graduate Studies in Mathematics. American Mathematical Society (AMS), 2015
work page 2015
-
[51]
Data assimilation: T he S chr \"o dinger perspective
Sebastian Reich. Data assimilation: T he S chr \"o dinger perspective. Acta Numerica, 28: 0 635--711, 2019
work page 2019
-
[52]
Probabilistic Forecasting and Bayesian Data Assimilation
Sebastian Reich and Colin Cotter. Probabilistic Forecasting and Bayesian Data Assimilation. Cambridge University Press, 2015
work page 2015
-
[53]
Fran c ois Rozet and Gilles Louppe. Score-based data assimilation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 40521--40541. Curran Associates, Inc., 2023 a
work page 2023
-
[54]
Score-based data assimilation for a two-layer quasi-geostrophic model, 2023 b
Fran c ois Rozet and Gilles Louppe. Score-based data assimilation for a two-layer quasi-geostrophic model, 2023 b . arXiv:2310.01853
-
[55]
Sampling errors in ensemble K alman filtering
William Sacher and Peter Bartello. Sampling errors in ensemble K alman filtering. P art I : T heory. Monthly Weather Review, 136: 0 3035--3049, 2008
work page 2008
-
[56]
Bayesian filtering and smoothing
Simo S \"a rkk \"a and Lennart Svensson. Bayesian filtering and smoothing. Institute of Mathematical Statistics Textbooks. Cambridge University Press, second edition, 2023
work page 2023
-
[57]
Nonparametric regression using deep neural networks with relu activation function
Johannes Schmidt-Hieber. Nonparametric regression using deep neural networks with relu activation function. The Annals of Statistics, 48 0 (4): 0 1875--1897, 2020
work page 2020
-
[58]
Phillip Si and Peng Chen. Latent-EnSF : A latent ensemble score filter for high-dimensional data assimilation with sparse observation data, 2024. arXiv:2409.00127
-
[59]
Obstacles to high-dimensional particle filtering
Chris Snyder, Thomas Bengtsson, Peter Bickel, and Jeff Anderson. Obstacles to high-dimensional particle filtering. Monthly weather review, 136: 0 4629--4640, 2008
work page 2008
-
[60]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. In International Conference on Learning Representations, 2023 a
work page 2023
-
[61]
Loss-guided diffusion models for plug-and-play controllable generation
Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, and Arash Vahdat. Loss-guided diffusion models for plug-and-play controllable generation. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Ma...
work page 2023
-
[62]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alch\' e -Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[63]
Sliced score matching: A scalable approach to density and score estimation
Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced score matching: A scalable approach to density and score estimation. In Ryan P. Adams and Vibhav Gogate, editors, Proceedings of The 35th Uncertainty in Artificial Intelligence Conference, volume 115 of Proceedings of Machine Learning Research, pages 574--584. PMLR, 22--25 Jul 2020
work page 2020
-
[64]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
work page 2021
-
[65]
Coupling techniques for nonlinear ensemble filtering
Alessio Spantini, Ricardo Baptista, and Youssef Marzouk. Coupling techniques for nonlinear ensemble filtering. SIAM Review, 64 0 (4): 0 921--953, 2022
work page 2022
- [66]
-
[67]
Adaptivity of diffusion models to manifold structures
Rong Tang and Yun Yang. Adaptivity of diffusion models to manifold structures. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors, Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 of Proceedings of Machine Learning Research, pages 1648--1656. PMLR, 02--04 May 2024
work page 2024
-
[68]
Adam Thelen, Xiaoge Zhang, Olga Fink, Yan Lu, Sayan Ghosh, D. Byeng Youn, Michael D. Todd, Sankaran Mahadevan, Chao Hu, and Zhen Hu. A comprehensive review of digital twin -- part 1: modeling and twinning enabling technologies. Structural and Multidisciplinary Optimization, 65 0 (354), 2022
work page 2022
-
[69]
Adam Thelen, Xiaoge Zhang, Olga Fink, Yan Lu, Sayan Ghosh, D. Byeng Youn, Michael D. Todd, Sankaran Mahadevan, Chao Hu, and Zhen Hu. A comprehensive review of digital twin -- part 2: roles of uncertainty quantification and optimization, a battery digital twin, and perspectives. Structural and Multidisciplinary Optimization, 66 0 (1), 2023
work page 2023
- [70]
-
[71]
Rapid convergence of the unadjusted L angevin algorithm: Isoperimetry suffices
Santosh Vempala and Andre Wibisono. Rapid convergence of the unadjusted L angevin algorithm: Isoperimetry suffices. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alch\' e -Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[72]
A connection between score matching and denoising autoencoders
Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23 0 (7): 0 1661--1674, 2011
work page 2011
-
[73]
Martin J. Wainwright. High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2019
work page 2019
-
[74]
Dongze Wu and Yao Xie. Annealing flow generative model towards sampling high-dimensional and multi-modal distributions, 2024. arXiv:2409.20547
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.