VidHal: Benchmarking Temporal Hallucinations in Vision LLMs
Pith reviewed 2026-05-23 16:53 UTC · model grok-4.3
The pith
VidHal benchmark shows vision LLMs struggle to rank video captions by hallucination level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VidHal evaluates video-based hallucinations in VLLMs by supplying videos paired with captions that vary in hallucination severity across temporal aspects, then requiring models to rank the captions by hallucinatory extent. Comprehensive tests across multiple models demonstrate that existing VLLMs exhibit significant limitations in generating responses without such hallucinations.
What carries the argument
The caption ordering task, which requires models to rank captions by their degree of hallucination for each video.
If this is right
- Existing VLLMs produce responses containing significant temporal hallucinations when describing video content.
- Standard evaluation methods miss the nuanced spatiotemporal errors that arise in video responses.
- The benchmark supports targeted development of VLLMs that reduce hallucination in video settings.
- Further work should pursue more complete assessment of VLLM hallucination across dynamic inputs.
Where Pith is reading between the lines
- Widespread use of the ordering task could push training methods to explicitly reduce temporal inconsistencies in generated descriptions.
- The graduated-caption approach may transfer to measuring hallucinations in other time-based modalities such as audio sequences.
- Models succeeding on this task might also show stronger general temporal reasoning when combining vision and language.
Load-bearing premise
The manually created captions accurately reflect distinct and ordered levels of hallucination without bias or inconsistency.
What would settle it
Human raters reordering the captions in a way that frequently disagrees with the benchmark's intended ranking across many videos.
Figures






























read the original abstract
Vision Large Language Models (VLLMs) are widely acknowledged to be prone to hallucinations. Existing research addressing this problem has primarily been confined to image inputs, with limited exploration of video-based hallucinations. Furthermore, current evaluation methods fail to capture nuanced errors in generated responses, which are often exacerbated by the rich spatiotemporal dynamics of videos. To address this, we introduce VidHal, a benchmark specially designed to evaluate video-based hallucinations in VLLMs. VidHal is constructed by bootstrapping video instances across a wide range of common temporal aspects. A defining feature of our benchmark lies in the careful creation of captions which represent varying levels of hallucination associated with each video. To enable fine-grained evaluation, we propose a novel caption ordering task requiring VLLMs to rank captions by hallucinatory extent. We conduct extensive experiments on VidHal and comprehensively evaluate a broad selection of models. Our results uncover significant limitations in existing VLLMs regarding hallucination generation. Through our benchmark, we aim to inspire further research on 1) holistic understanding of VLLM capabilities, particularly regarding hallucination, and 2) extensive development of advanced VLLMs to alleviate this problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VidHal, a benchmark for temporal hallucinations in Vision Large Language Models (VLLMs). It constructs the benchmark by bootstrapping video instances across temporal aspects, creates captions representing varying hallucination levels for each video, and proposes a caption ordering task in which VLLMs rank captions by hallucinatory extent. Experiments on a range of models are reported to uncover significant limitations in existing VLLMs regarding hallucination generation.
Significance. If the benchmark construction is shown to be reliable, VidHal would address a clear gap: most hallucination work targets static images, while video inputs introduce richer spatiotemporal dynamics that current metrics do not capture. The caption-ordering task supplies a fine-grained, ordinal evaluation signal that could support more nuanced model comparisons and motivate targeted mitigation research. The manuscript correctly identifies the need for holistic VLLM evaluation focused on temporal hallucination.
major comments (2)
- [Abstract / benchmark construction] Abstract and benchmark-construction description: the central claim that the caption ordering task enables 'fine-grained evaluation' of hallucinatory extent rests on the assumption that the human-created captions accurately encode ordered hallucination levels. No details are supplied on the assignment procedure (temporal error taxonomy, grounding against video ground truth, or controls for length/style confounds), nor on inter-annotator agreement. This directly affects the validity of all reported model rankings and the conclusion of 'significant limitations.'
- [Experiments] Experimental section: the claim that results 'uncover significant limitations' requires that the ordering task measures genuine hallucination differences rather than superficial cues. Without reported validation of the caption levels or experimental controls (e.g., caption-length balancing, reference-video verification), the performance differences cannot be confidently attributed to hallucination sensitivity.
minor comments (1)
- The abstract states that VidHal is 'specially designed' and that 'extensive experiments' were conducted, yet the provided text gives no concrete counts of videos, captions per video, or model list; these numbers should appear in the main text or a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of benchmark validity that we will address through revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark-construction description: the central claim that the caption ordering task enables 'fine-grained evaluation' of hallucinatory extent rests on the assumption that the human-created captions accurately encode ordered hallucination levels. No details are supplied on the assignment procedure (temporal error taxonomy, grounding against video ground truth, or controls for length/style confounds), nor on inter-annotator agreement. This directly affects the validity of all reported model rankings and the conclusion of 'significant limitations.'
Authors: We agree that the manuscript would benefit from explicit details on the caption creation process to support the claim of ordered hallucination levels. In the revised manuscript, we will expand the relevant sections to describe the temporal error taxonomy, the grounding procedure against video ground truth, controls for length and style confounds, and inter-annotator agreement statistics from the annotation process. revision: yes
-
Referee: [Experiments] Experimental section: the claim that results 'uncover significant limitations' requires that the ordering task measures genuine hallucination differences rather than superficial cues. Without reported validation of the caption levels or experimental controls (e.g., caption-length balancing, reference-video verification), the performance differences cannot be confidently attributed to hallucination sensitivity.
Authors: We acknowledge that additional validation and controls would strengthen attribution of results to hallucination sensitivity. In revision, we will add explicit discussion of any existing controls (such as caption-length balancing and reference verification) and, where needed, report further analyses or validation steps to confirm that performance differences reflect hallucination rather than superficial cues. revision: partial
Circularity Check
No circularity: benchmark construction paper with no derivations or self-referential steps
full rationale
This is a benchmark introduction paper. The abstract and provided text describe constructing VidHal by bootstrapping videos and creating captions, then proposing a caption ordering task. No equations, fitted parameters, predictions, or derivation chains exist. No self-citations are invoked to justify core claims, and the evaluation approach does not reduce to its inputs by construction. The central claim of uncovering VLLM limitations rests on the benchmark's design rather than any circular reduction. This matches the default expectation of no significant circularity for such papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLLMs are prone to hallucinations, particularly with video inputs due to spatiotemporal dynamics
Forward citations
Cited by 2 Pith papers
-
XModBench: Benchmarking Cross-Modal Capabilities and Consistency in Omni-Language Models
XModBench is a tri-modal benchmark that systematically measures cross-modal consistency, modality disparities, and directional imbalances in omni-language models across five task families and all modality combinations.
-
Relaxing Anchor-Frame Dominance for Mitigating Hallucinations in Video Large Language Models
Decoder-side Temporal Rebalancing (DTR) reduces hallucinations in Video-LLMs by mitigating over-dominance of a single anchor frame during inference without training or auxiliary models.
Reference graph
Works this paper leans on
-
[1]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey. CoRR, abs/2404.18930, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Videocon: Robust video- language alignment via contrast captions
Hritik Bansal, Yonatan Bitton, Idan Szpektor, Kai-Wei Chang, and Aditya Grover. Videocon: Robust video- language alignment via contrast captions. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13927–13937. IEEE, 2024. 2, 3, 4, 5
work page 2024
-
[3]
Revisiting the ”video” in video-language understanding
Shyamal Buch, Crist ´obal Eyzaguirre, Adrien Gaidon, Jia- jun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the ”video” in video-language understanding. In IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 2907–2917. IEEE, 2022. 7
work page 2022
-
[4]
Qingxing Cao, Junhao Cheng, Xiaodan Liang, and Liang Lin. Visdiahalbench: A visual dialogue benchmark for di- agnosing hallucination in large vision-language models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages 12161–12176. Associa- tion for Computational Linguistics, 2024. 2
work page 2024
-
[5]
Xiuyuan Chen, Yuan Lin, Yuchen Zhang, and Weiran Huang. Autoeval-video: An automatic benchmark for assessing large vision language models in open-ended video question answering. CoRR, abs/2311.14906, 2023. 1, 2, 4, 13
-
[6]
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David F. Fouhey, and Joyce Chai. Multi-object hallucination in vision-language models. CoRR, abs/2407.06192, 2024. 2
-
[7]
Unified hallucination detection for multi- modal large language models
Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xi- aoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, and Huajun Chen. Unified hallucination detection for multi- modal large language models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages 3235–3252. Association for Computational Linguis- tics, 2024. 2
work page 2024
-
[8]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video- llms. CoRR, abs/2406.07476, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning. In Advances in Neural Information Processing Systems , 2023. 2
work page 2023
-
[10]
Hallu-pi: Evaluating hallucination in multi-modal large language models within perturbed inputs
Peng Ding, Jingyu Wu, Jun Kuang, Dan Ma, Xuezhi Cao, Xunliang Cai, Shi Chen, Jiajun Chen, and Shujian Huang. Hallu-pi: Evaluating hallucination in multi-modal large language models within perturbed inputs. CoRR, abs/2408.01355, 2024. 1
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aur ´elien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozi `ere, B...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Multi-modal hallucination control by visual information grounding
Alessandro Favero, Luca Zancato, Matthew Trager, Sid- dharth Choudhary, Pramuditha Perera, Alessandro Achille, Ashwin Swaminathan, and Stefano Soatto. Multi-modal hallucination control by visual information grounding. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14303–14312. IEEE, 2024. 1, 2
work page 2024
-
[13]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Rongrong Ji, and Xing Sun. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. CoRR, abs/240...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Chat- rec: Towards interactive and explainable llms-augmented recommender system,
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. Chat-rec: Towards interactive and explainable llms-augmented recommender system. CoRR, abs/2303.14524, 2023. 5
-
[15]
DAMRO: dive into the attention mechanism of LVLM to reduce object hallucination
Xuan Gong, Tianshi Ming, Xinpeng Wang, and Zhihua Wei. DAMRO: dive into the attention mechanism of LVLM to reduce object hallucination. In Proceedings of the Confer- ence on Empirical Methods in Natural Language Process- ing, pages 7696–7712. Association for Computational Lin- guistics, 2024. 1
work page 2024
-
[16]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hal- lusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision- language models. In IEEE/CVF Conference on Computer Vision and Pattern Recog...
-
[17]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Con- ghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. OPERA: alleviating hallucination in multi- 9 modal large language models via over-trust penalty and retrospection-allocation. In IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pages 13418–13427. IEEE, 2024. 1, 2
work page 2024
-
[18]
Cumulated gain- based evaluation of IR techniques
Kalervo J ¨arvelin and Jaana Kek ¨al¨ainen. Cumulated gain- based evaluation of IR techniques. ACM Trans. Inf. Syst. , 20(4):422–446, 2002. 5
work page 2002
-
[19]
Hallucination augmented contrastive learning for multimodal large language model
Chaoya Jiang, Haiyang Xu, Mengfan Dong, Jiaxing Chen, Wei Ye, Ming Yan, Qinghao Ye, Ji Zhang, Fei Huang, and Shikun Zhang. Hallucination augmented contrastive learning for multimodal large language model. In IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 27026–27036. IEEE, 2024. 2
work page 2024
-
[20]
Chaoya Jiang, Wei Ye, Mengfan Dong, Hongrui Jia, Haiyang Xu, Ming Yan, Ji Zhang, and Shikun Zhang. Hal-eval: A uni- versal and fine-grained hallucination evaluation framework for large vision language models. CoRR, abs/2402.15721,
-
[21]
Prannay Kaul, Zhizhong Li, Hao Yang, Yonatan Dukler, Ashwin Swaminathan, C. J. Taylor, and Stefano Soatto. THRONE: an object-based hallucination benchmark for the free-form generations of large vision-language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27218–27228. IEEE, 2024. 1, 2
work page 2024
-
[22]
Jie Lei, Tamara L. Berg, and Mohit Bansal. Revealing single frame bias for video-and-language learning. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, pages 487–507. Association for Computational Linguistics, 2023. 7
work page 2023
-
[23]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. In IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pages 13872–13882. IEEE, 2024. 1, 2
work page 2024
-
[24]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yix- iao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension. CoRR, abs/2307.16125, 2023. 2, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. InIn- ternational Conference on Machine Learning, pages 12888– 12900. PMLR, 2022. 2
work page 2022
-
[26]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning , pages 19730–19742. PMLR, 2023. 2, 14
work page 2023
-
[27]
VideoChat: Chat-Centric Video Understanding
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. CoRR, abs/2305.06355,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Mvbench: A comprehensive multi- modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Lou, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi- modal video understanding benchmark. In IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22195–22206. IEEE, 2024. 1, 2, 4, 5, 6, 13
work page 2024
-
[29]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Proceedings of the Confer- ence on Empirical Methods in Natural Language Processing, pages 292–305. Association for Computational Linguistics,
-
[30]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. In European Conference on Computer Vision, pages 323–340. Springer, 2024. 6
work page 2024
-
[31]
Mitigating hallucination in large multi-modal models via robust instruction tuning
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Ya- coob, and Lijuan Wang. Mitigating hallucination in large multi-modal models via robust instruction tuning. In The Twelfth International Conference on Learning Representa- tions. OpenReview.net, 2024. 2
work page 2024
-
[32]
Models see hallucinations: Eval- uating the factuality in video captioning
Hui Liu and Xiaojun Wan. Models see hallucinations: Eval- uating the factuality in video captioning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 11807–11823. Association for Computa- tional Linguistics, 2023. 4
work page 2023
-
[33]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, 2023. 1, 2
work page 2023
-
[34]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2024. 1, 2
work page 2024
-
[35]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 2
work page 2024
-
[36]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiu- tian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models. CoRR, abs/2402.00253, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Phd: A prompted visual hallucination evaluation dataset
Jiazhen Liu, Yuhan Fu, Ruobing Xie, Runquan Xie, Xingwu Sun, Fengzong Lian, Zhanhui Kang, and Xirong Li. Phd: A prompted visual hallucination evaluation dataset. CoRR, abs/2403.11116, 2024. 1
-
[38]
Paying more atten- tion to image: A training-free method for alleviating halluci- nation in lvlms
Shi Liu, Kecheng Zheng, and Wei Chen. Paying more atten- tion to image: A training-free method for alleviating halluci- nation in lvlms. arXiv preprint arXiv:2407.21771, 2024. 1, 2
-
[39]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcom- pass: Do video llms really understand videos? In Findings of the Association for Computational Linguistics, pages 8731–
- [40]
-
[41]
Vista-llama: Reducing hallucination in video language models via equal distance to visual tokens
Fan Ma, Xiaojie Jin, Heng Wang, Yuchen Xian, Jiashi Feng, and Yi Yang. Vista-llama: Reducing hallucination in video language models via equal distance to visual tokens. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13151–13160. IEEE, 2024. 1
work page 2024
-
[42]
Munan Ning, Bin Zhu, Yujia Xie, Bin Lin, Jiaxi Cui, Lu Yuan, Dongdong Chen, and Li Yuan. Video-bench: A com- prehensive benchmark and toolkit for evaluating video-based 10 large language models. CoRR, abs/2311.16103, 2023. 1, 2, 4, 5
-
[43]
OpenAI. GPT-4 technical report. CoRR, abs/2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human f...
work page 2022
-
[45]
Per- ception test: A diagnostic benchmark for multimodal video models
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adri `a Re- casens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Do- ersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alexandre Fr´echette, Hanna Klimczak, Raphael Koster, Jun- lin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Dima Damen, ...
work page 2023
-
[46]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy P. Lillicrap, Jean-Baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, Ioannis Antonoglou, Rohan Anil, Sebastian Borgeaud, Andrew M. Dai, Katie Millican, Ethan Dyer, Mia Glaese, Thibault Sottiaux, Benjamin Lee, Fabio Vi- ola, Malcolm Reynolds, Yuanz...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 4035–4045. Association for Computational Linguistics, 2018. 1, 3
work page 2018
-
[48]
CSTA: cnn-based spatiotemporal attention for video summarization
Jaewon Son, Jaehun Park, and Kwangsu Kim. CSTA: cnn-based spatiotemporal attention for video summarization. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18847–18856. IEEE, 2024. 7
work page 2024
-
[49]
PandaGPT: One Model To Instruction-Follow Them All
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all. CoRR, abs/2305.16355, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Aligning large multimodal models with factually augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. Aligning large multimodal models with factually augmented RLHF. In Findings of the Association for Com- putational Linguistics, pages 13088–13110. Association for Computational Linguistics, 2...
work page 2024
-
[51]
Avhbench: A cross- modal hallucination benchmark for audio-visual large lan- guage models
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. Avhbench: A cross- modal hallucination benchmark for audio-visual large lan- guage models. arXiv preprint arXiv:2410.18325, 2024
-
[52]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Ming Yan, Ji Zhang, and Jitao Sang. Amber: An llm-free multi-dimensional bench- mark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397, 2023. 1, 2, 3, 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models
Yuxuan Wang, Yueqian Wang, Dongyan Zhao, Cihang Xie, and Zilong Zheng. Videohallucer: Evaluating intrinsic and extrinsic hallucinations in large video-language models. CoRR, abs/2406.16338, 2024. 2, 3, 8
-
[54]
Le, Thang Luong, and Golnaz Ghiasi
Zhecan Wang, Garrett Bingham, Adams Yu, Quoc V . Le, Thang Luong, and Golnaz Ghiasi. Haloquest: A visual hallu- cination dataset for advancing multimodal reasoning. CoRR, abs/2407.15680, 2024. 2
-
[55]
Hongliang Wei, Xingtao Wang, Xianqi Zhang, Xiaopeng Fan, and Debin Zhao. Toward a stable, fair, and compre- hensive evaluation of object hallucination in large vision- language models. In The Annual Conference on Neural In- formation Processing Systems, 2024. 2
work page 2024
-
[56]
Shangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, Chunhui Li, Jianbing Zhang, and Xinyu Dai. EFUF: effi- cient fine-grained unlearning framework for mitigating hal- lucinations in multimodal large language models. In Pro- ceedings of the Conference on Empirical Methods in Natu- ral Language Processing, pages 1167–1181. Association for Computational Li...
work page 2024
-
[57]
Mitigat- ing object hallucination via concentric causal attention
Yun Xing, Yiheng Li, Ivan Laptev, and Shijian Lu. Mitigat- ing object hallucination via concentric causal attention. In The Annual Conference on Neural Information Processing Systems, 2024. 1
work page 2024
-
[58]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Ziwei Xu, Sanjay Jain, and Mohan S. Kankanhalli. Hallu- cination is inevitable: An innate limitation of large language models. CoRR, abs/2401.11817, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Vript: A video is worth thousands of words
Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, and Hai Zhao. Vript: A video is worth thousands of words. In Advances in Neural Information Processing Systems, 2024. 2, 3, 5
work page 2024
-
[60]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug- owl3: Towards long image-sequence understanding in multi- modal large language models. CoRR, abs/2408.04840, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Jun- feng Tian, Qian Qi, Ji Zhang, and Fei Huang. mplug-owl: Modularization empowers large language models with mul- timodality. CoRR, abs/2304.14178, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jin- gren Zhou. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. CoRR, abs/2311.04257, 2023. 2 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Woodpecker: Hallucination correction for multimodal large language models,
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. Woodpecker: Hallucination correction for multimodal large language models. CoRR, abs/2310.16045, 2023. 2
-
[64]
Fan Yuan, Chi Qin, Xiaogang Xu, and Piji Li. HELPD: miti- gating hallucination of lvlms by hierarchical feedback learn- ing with vision-enhanced penalty decoding. In Proceedings of the Conference on Empirical Methods in Natural Lan- guage Processing, pages 1768–1785. Association for Com- putational Linguistics, 2024. 2
work page 2024
-
[65]
Less is more: Miti- gating multimodal hallucination from an EOS decision per- spective
Zihao Yue, Liang Zhang, and Qin Jin. Less is more: Miti- gating multimodal hallucination from an EOS decision per- spective. In Proceedings of the Annual Meeting of the Asso- ciation for Computational Linguistics , pages 11766–11781. Association for Computational Linguistics, 2024. 1
work page 2024
-
[66]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages 543–553. Association for Computational Linguistics, 2023. 2
work page 2023
-
[67]
Llava- next: A strong zero-shot video understanding model, 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava- next: A strong zero-shot video understanding model, 2024. 2, 6
work page 2024
-
[68]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Ji- aqi Wang, and Conghui He. Beyond hallucinations: Enhanc- ing lvlms through hallucination-aware direct preference op- timization. CoRR, abs/2311.16839, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Weihong Zhong, Xiaocheng Feng, Liang Zhao, Qiming Li, Lei Huang, Yuxuan Gu, Weitao Ma, Yuan Xu, and Bing Qin. Investigating and mitigating the multimodal halluci- nation snowballing in large vision-language models. In Pro- ceedings of the Annual Meeting of the Association for Com- putational Linguistics, pages 11991–12011. Association for Computational Li...
work page 2024
-
[70]
Guanyu Zhou, Yibo Yan, Xin Zou, Kun Wang, Aiwei Liu, and Xuming Hu. Mitigating modality prior-induced halluci- nations in multimodal large language models via deciphering attention causality. CoRR, abs/2410.04780, 2024. 1
-
[71]
Aligning Modalities in Vision Large Language Models via Preference Fine-tuning
Yiyang Zhou, Chenhang Cui, Rafael Rafailov, Chelsea Finn, and Huaxiu Yao. Aligning modalities in vision large language models via preference fine-tuning. CoRR, abs/2402.11411, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Analyzing and mitigating object hallucination in large vision-language models
Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. Analyzing and mitigating object hallucination in large vision-language models. In The International Conference on Learning Representations. OpenReview.net, 2024. 2
work page 2024
-
[73]
Calibrated self-rewarding vi- sion language models
Yiyang Zhou, Zhiyuan Fan, Dongjie Cheng, Sihan Yang, Zhaorun Chen, Chenhang Cui, Xiyao Wang, Yun Li, Lin- jun Zhang, and Huaxiu Yao. Calibrated self-rewarding vi- sion language models. In Advances in Neural Information Processing Systems, 2024. 2
work page 2024
-
[74]
Minigpt-4: Enhancing vision-language understanding with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. In The International Conference on Learning Representations . OpenReview.net, 2024. 2
work page 2024
-
[75]
Combating visual question answering hallucinations via robust multi-space co- debias learning
Jiawei Zhu, Yishu Liu, Huanjia Zhu, Hui Lin, Yuncheng Jiang, Zheng Zhang, and Bingzhi Chen. Combating visual question answering hallucinations via robust multi-space co- debias learning. In ACM Multimedia 2024, 2024. 2
work page 2024
-
[76]
IBD: alleviating hallucinations in large vision-language models via image-biased decoding
Lanyun Zhu, Deyi Ji, Tianrun Chen, Peng Xu, Jieping Ye, and Jun Liu. IBD: alleviating hallucinations in large vision-language models via image-biased decoding. CoRR, abs/2402.18476, 2024. 1
-
[77]
Game on tree: Visual hal- lucination mitigation via coarse-to-fine view tree and game theory
Xianwei Zhuang, Zhihong Zhu, Zhanpeng Chen, Yuxin Xie, Liming Liang, and Yuexian Zou. Game on tree: Visual hal- lucination mitigation via coarse-to-fine view tree and game theory. In Proceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing, pages 17984– 18003. Association for Computational Linguistics, 2024. 1 12
work page 2024
-
[78]
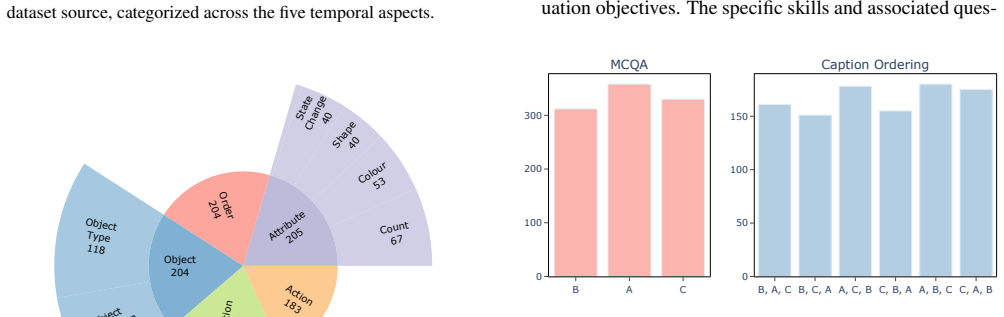
Benchmark Construction Details 7.1. Dataset Statistics Figure 10 illustrates the distribution of public dataset sources contributing to the visual instances in V IDHAL. Additionally, Figures 11 and 12 depict the distribution of temporal aspects across V IDHAL and the ground truth an- swers for the MCQA and caption ordering tasks, respec- tively. One can o...
-
[79]
Separate in-context examples are provided for each At- tribute subaspect of Shape, Size, Color, Count, and State Change to account for their distinct natures. 14 You are given one or more questions targeted at content of a video and their corresponding answers. You are tasked with generating an appropriate and informative single line caption for the video...
-
[80]
Human Validation Details 8.1. Human Validation Process As varying hallucination levels are a distinctive feature of our benchmark, we prioritize validating the robustness of caption ordering produced by our annotation pipeline. Each anchor caption is derived from the original video metadata, making it the most accurate reflection of the video content. Our...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.