Sundial: A Family of Highly Capable Time Series Foundation Models
Pith reviewed 2026-05-23 04:25 UTC · model grok-4.3
The pith
Sundial uses flow-matching loss to pre-train transformers on continuous time series without tokenization or prior distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using TimeFlow Loss based on flow-matching, Sundial models are pre-trained to predict the next-patch distribution on continuous time series without any discrete tokenization or specified prior, mitigating mode collapse and enabling generation of multiple probable forecasts from arbitrary-length conditioning inputs. Pre-training occurs on the TimeBench collection of one trillion points. The resulting models exhibit strong scalability and achieve state-of-the-art results on point and probabilistic forecasting benchmarks with zero-shot, just-in-time inference.
What carries the argument
TimeFlow Loss, a flow-matching objective that predicts next-patch distributions to enable continuous-valued pre-training of Transformers.
If this is right
- Models generate multiple probable predictions from a single conditioning series without assuming a parametric form.
- Zero-shot performance reaches state-of-the-art levels on both point and probabilistic time series forecasting benchmarks.
- Inference produces predictions in milliseconds, supporting real-time use.
- Model capacity and generalization improve as pre-training scale increases.
Where Pith is reading between the lines
- The same loss could be tested on other sequential data types such as audio or sensor streams to check whether token-free pre-training generalizes beyond time series.
- If the models truly require no domain adaptation, organizations could replace collections of specialized forecasters with one shared Sundial backbone.
- The generative capability may reduce over-reliance on single-point forecasts in applications where uncertainty quantification affects decisions.
Load-bearing premise
A curated collection of one trillion real-world and synthetic time points is enough to train models that generalize to arbitrary new forecasting tasks without adaptation.
What would settle it
On a forecasting benchmark whose data distribution lies outside the TimeBench mix, Sundial models underperform task-specific baselines or require fine-tuning to match them.
Figures













read the original abstract
We introduce Sundial, a family of native, flexible, and scalable time series foundation models. To predict the next-patch's distribution, we propose a TimeFlow Loss based on flow-matching, which facilitates native pre-training of Transformers on continuous-valued time series without discrete tokenization. Conditioned on arbitrary-length time series, our models are pre-trained without specifying any prior distribution and can generate multiple probable predictions, achieving more flexibility in representation learning than using parametric densities. Towards time series foundation models, we leverage minimal but crucial adaptations of Transformers and curate TimeBench with one trillion time points, comprising mostly real-world datasets and synthetic data. By mitigating mode collapse via TimeFlow Loss, we pre-train a family of Sundial models on TimeBench, which achieve unprecedented model capacity and generalization performance. In addition to excellent scalability, Sundial achieves state-of-the-art results on both point and probabilistic forecasting benchmarks with a just-in-time inference speed, i.e., making zero-shot predictions within a few milliseconds. We believe that Sundial's pioneering generative forecasting capability can improve model reliability in real-world decision-making. Code is available at: https://github.com/thuml/Sundial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sundial, a family of Transformer-based time series foundation models pre-trained on the TimeBench corpus (one trillion points, mostly real-world plus synthetic data) using a novel TimeFlow Loss derived from flow-matching. The central claims are that this loss mitigates mode collapse, enables native continuous-valued pre-training without tokenization or parametric density assumptions, and yields zero-shot SOTA performance on both point and probabilistic forecasting benchmarks together with millisecond-scale just-in-time inference.
Significance. If the zero-shot results prove robust, the work would constitute a meaningful step toward scalable generative foundation models for time series. The public release of code is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract and experimental sections: the headline SOTA claims on point and probabilistic forecasting are presented without quantitative details on benchmark definitions, baseline re-implementations, statistical significance testing, or ablation of the TimeFlow Loss, so the central performance assertions rest on unverified experimental execution.
- [TimeBench description] TimeBench curation (presumably §3 or §4): no exclusion protocol, temporal split rules, or overlap statistics are supplied to demonstrate that the one-trillion-point mix is disjoint from standard evaluation test sets; without this, the zero-shot generalization claim cannot be distinguished from memorization or distributional leakage.
minor comments (2)
- Notation for the flow-matching objective is introduced without an explicit equation reference or comparison to standard flow-matching formulations, making it harder to verify the claimed advantages over parametric densities.
- [Abstract] The phrase 'unprecedented model capacity' is used without a concrete metric or table comparing parameter counts and training tokens to prior time-series foundation models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment below and will update the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental sections: the headline SOTA claims on point and probabilistic forecasting are presented without quantitative details on benchmark definitions, baseline re-implementations, statistical significance testing, or ablation of the TimeFlow Loss, so the central performance assertions rest on unverified experimental execution.
Authors: The full experimental sections define the benchmarks (standard point and probabilistic forecasting tasks drawn from established libraries and datasets), describe baseline re-implementations (using official public code with hyperparameter settings matched to original publications), report statistical significance via multiple random seeds with standard deviations, and present an ablation of TimeFlow Loss. The abstract is intentionally concise, but we agree it would benefit from explicit quantitative highlights. We will revise the abstract to include key performance numbers and add a concise experimental protocol summary subsection. revision: yes
-
Referee: [TimeBench description] TimeBench curation (presumably §3 or §4): no exclusion protocol, temporal split rules, or overlap statistics are supplied to demonstrate that the one-trillion-point mix is disjoint from standard evaluation test sets; without this, the zero-shot generalization claim cannot be distinguished from memorization or distributional leakage.
Authors: This is a substantive point for validating the zero-shot claims. The current TimeBench description focuses on scale and composition but omits explicit leakage-prevention details. In the revision we will add a dedicated subsection specifying the temporal split rules (ensuring pre-training data ends before any evaluation start dates), the protocol for excluding overlapping sources, and quantitative overlap statistics obtained via direct dataset comparison and similarity checks. These additions will directly support the generalization assertions. revision: yes
Circularity Check
No circularity; empirical results rest on external benchmarks with no algebraic reduction to inputs.
full rationale
The paper's derivation consists of proposing TimeFlow Loss (flow-matching based), curating TimeBench, and pre-training Sundial models, with performance claims evaluated on independent point and probabilistic forecasting benchmarks. No equations, parameters, or predictions are shown to reduce by construction to fitted inputs or self-definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes are quoted that collapse the central claims. Results are measured externally rather than being statistically forced, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
invented entities (2)
-
TimeFlow Loss
no independent evidence
-
TimeBench
no independent evidence
Forward citations
Cited by 12 Pith papers
-
Olivia: Harmonizing Time Series Foundation Models with Power Spectral Density
Olivia harmonizes time series datasets via normalized power spectral density using a Harmonizer module and resonator-based HarmonicAttention, achieving state-of-the-art zero-shot, few-shot, and full-shot forecasting o...
-
What if Tomorrow is the World Cup Final? Counterfactual Time Series Forecasting with Textual Conditions
Introduces the task of counterfactual time series forecasting with textual conditions plus a text-attribution mechanism that improves accuracy by distinguishing mutable from immutable factors.
-
TimeClaw: A Time-Series AI Agent with Exploratory Execution Learning
TimeClaw is an exploratory execution learning system that turns multiple valid tool-use paths into hierarchical distilled experience for improved time-series reasoning without test-time adaptation.
-
TempusBench: An Evaluation Framework for Time-Series Forecasting
TempusBench is a new evaluation framework for time-series forecasting models that supplies fresh non-overlapping datasets, tasks beyond horizon and domain, consistent tuning across models, and visualization tools.
-
Is Flow Matching Just Trajectory Replay for Sequential Data?
Flow matching on time series targets a closed-form nonparametric velocity field that is a similarity-weighted mixture of observed transition velocities, making neural models approximations to an ideal memory-augmented...
-
TS-Arena -- A Live Forecast Pre-Registration Platform
TS-Arena is a live pre-registration platform that evaluates time series forecasts on future data streams to eliminate information leakage.
-
Predicting Power-System Dynamic Trajectories with Foundation Models
LASS-ODE-Power is a pretrained model that predicts power-system dynamic trajectories across regimes in a zero-shot manner after large-scale ODE pretraining and targeted fine-tuning.
-
FM-CAC: Carbon-Aware Control for Battery-Buffered Edge AI via Time-Series Foundation Models
FM-CAC uses battery buffering and time-series foundation models for zero-shot carbon forecasting in a dynamic programming optimizer to reduce edge AI carbon emissions by up to 65.6% with near-maximum accuracy.
-
Timer-S1: A Billion-Scale Time Series Foundation Model with Serial Scaling
Timer-S1 is a released 8.3B-parameter MoE time series model that achieves state-of-the-art MASE and CRPS scores on GIFT-Eval using serial scaling and Serial-Token Prediction.
-
AlphaCast: A Human Wisdom-LLM Intelligence Co-Reasoning Framework for Interactive Time Series Forecasting
AlphaCast is a training-free LLM framework that performs interactive multi-stage reasoning for time series forecasting by integrating feature extraction, knowledge bases, case libraries, and contextual pools.
-
An AI system to help scientists write expert-level empirical software
ERA is an AI system using LLMs and tree search to produce expert-level empirical software, generating methods that outperformed top human approaches in single-cell data analysis and COVID-19 forecasting tasks.
-
An AI system to help scientists write expert-level empirical software
ERA combines LLMs and tree search to produce expert-level empirical software that outperforms top human methods on single-cell analysis leaderboards and CDC COVID-19 forecasts.
Reference graph
Works this paper leans on
-
[1]
Chronos: Learning the Language of Time Series
Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Adaptive Input Representations for Neural Language Modeling
Baevski, A. and Auli, M. Adaptive input representa- tions for neural language modeling.arXiv preprint arXiv:1809.10853,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Bai, S., Kolter, J. Z., and Koltun, V . An empirical evalua- tion of generic convolutional and recurrent networks for sequence modeling.arXiv preprint arXiv:1803.01271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosse- lut, A., Brunskill, E., et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Long- term forecasting with tide: Time-series dense encoder
Das, A., Kong, W., Leach, A., Sen, R., and Yu, R. Long- term forecasting with tide: Time-series dense encoder. arXiv preprint arXiv:2304.08424, 2023a. Das, A., Kong, W., Sen, R., and Zhou, Y . A decoder- only foundation model for time-series forecasting.arXiv preprint arXiv:2310.10688, 2023b. Esser, P., Kulal, S., Blattmann, A., Entezari, R., M¨uller, J.,...
-
[6]
Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885,
Goswami, M., Szafer, K., Choudhry, A., Cai, Y ., Li, S., and Dubrawski, A. Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885,
- [7]
-
[8]
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Hor´anyi, A., Mu˜noz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., et al. The era5 global reanalysis.Quarterly Journal of the Royal Meteorological Society, 146(730): 1999–2049,
work page 1999
-
[9]
B., M¨uller, S., Salinas, D., and Hutter, F
Hoo, S. B., M¨uller, S., Salinas, D., and Hutter, F. The tabular foundation model tabpfn outperforms specialized time series forecasting models based on simple features.arXiv preprint arXiv:2501.02945,
-
[10]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Kollovieh, M., Lienen, M., L ¨udke, D., Schwinn, L., and G¨unnemann, S. Flow matching with gaussian process priors for probabilistic time series forecasting.arXiv preprint arXiv:2410.03024,
-
[12]
Autoregres- sive image generation without vector quantization.arXiv preprint arXiv:2406.11838,
Li, T., Tian, Y ., Li, H., Deng, M., and He, K. Autoregres- sive image generation without vector quantization.arXiv preprint arXiv:2406.11838,
-
[13]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lipman, Y ., Havasi, M., Holderrieth, P., Shaul, N., Le, M., Karrer, B., Chen, R. T., Lopez-Paz, D., Ben-Hamu, H., and Gat, I. Flow matching guide and code.arXiv preprint arXiv:2412.06264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Liu, Y ., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., and Long, M. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625, 2023a. Liu, Y ., Li, C., Wang, J., and Long, M. Koopa: Learning non- stationary time series dynamics with koopman predictors. arXiv preprint arXiv:2305.18803, 2023b. Liu, Y ., Qi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y ., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
OpenAI, R. Gpt-4 technical report. arxiv 2303.08774.View in Article, 2:13,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
N., Carpov, D., Chapados, N., and Bengio, Y
Oreshkin, B. N., Carpov, D., Chapados, N., and Bengio, Y . N-beats: Neural basis expansion analysis for interpretable time series forecasting.arXiv preprint arXiv:1905.10437,
-
[19]
R., Khorasani, A., Adamopoulos, G., Bhagwatkar, R., Biloˇs, M., Ghonia, H., Hassen, N
Rasul, K., Ashok, A., Williams, A. R., Khorasani, A., Adamopoulos, G., Bhagwatkar, R., Biloˇs, M., Ghonia, H., Hassen, N. V ., Schneider, A., et al. Lag-llama: Towards foundation models for time series forecasting.arXiv preprint arXiv:2310.08278,
-
[20]
Scaling law for time series forecasting.arXiv preprint arXiv:2405.15124, 2024a
Shi, J., Ma, Q., Ma, H., and Li, L. Scaling law for time series forecasting.arXiv preprint arXiv:2405.15124, 2024a. Shi, X., Wang, S., Nie, Y ., Li, D., Ye, Z., Wen, Q., and Jin, M. Time-moe: Billion-scale time series founda- tion models with mixture of experts.arXiv preprint arXiv:2409.16040, 2024b. Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casp...
-
[21]
Improving and generalizing flow-based generative models with minibatch optimal transport
Tong, A., Fatras, K., Malkin, N., Huguet, G., Zhang, Y ., Rector-Brooks, J., Wolf, G., and Bengio, Y . Improving and generalizing flow-based generative models with mini- batch optimal transport.arXiv preprint arXiv:2302.00482,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Finetuned Language Models Are Zero-Shot Learners
Wei, J., Bosma, M., Zhao, V . Y ., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V . Finetuned lan- guage models are zero-shot learners.arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
A Multi-Horizon Quantile Recurrent Forecaster
Wen, R., Torkkola, K., Narayanaswamy, B., and Madeka, D. A multi-horizon quantile recurrent forecaster.arXiv preprint arXiv:1711.11053,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Woo, G., Liu, C., Kumar, A., Xiong, C., Savarese, S., and Sahoo, D. Unified training of universal time series fore- casting transformers.arXiv preprint arXiv:2402.02592,
-
[26]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
Wu, H., Hu, T., Liu, Y ., Zhou, H., Wang, J., and Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
A Survey of Large Language Models
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., et al. A survey of large language models.arXiv preprint arXiv:2303.18223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
12 Sundial: A Family of Highly Capable Time Series Foundation Models A. Dataset Statistics Large-scale datasets are of paramount importance for pre-training foundation models. Recent research has contributed significant time series datasets (Das et al., 2023b; Liu et al., 2024b; Shi et al., 2024b). While the scaling law of time series foundation models ha...
work page 2021
-
[29]
In addition to open-source datasets from research teams on time series foundation models (Woo et al., 2024; Ansari et al., 2024; Liu et al., 2024b;a), we collected substantial real-world time series from various domains such as finance, IoT, meteorology, and healthcare (Goldberger et al., 2000). These resources enable us to construct large-scale time-seri...
work page 2024
-
[30]
We adopt S3 format (Liu et al., 2024b) for univariate pre-training
for model optimization. We adopt S3 format (Liu et al., 2024b) for univariate pre-training. During training, data from different domains is sampled according to a predefined ratio to balance the domain weightings and ensure diversity in the training data. We implement a global shuffle strategy by loading time series into a standard parquet format. We use ...
work page 2024
-
[31]
and GIFT-Eval (Aksu et al., 2024), which consist of forecasting datasets with a prediction length ranging from 6 to 900, we train Sundial models by TimeFlow Loss with the prediction length of F= 720 . For the required prediction length less than the model prediction length, we truncate the output generated by Sundial. For the required length more than the...
work page 2024
-
[32]
We provide a model summary in Table 6, which summarizes several aspects of current time series foundation models. C. Supplementary Results C.1. Discussion of Mode Collapse Mode collapse is a failure of representation learning, where a model generates a limited variety of outputs, ignoring the diversity in the training data. For time series foundation mode...
work page 2048
-
[33]
Comparison of time series foundation models.Architecturedenotes the Transformer category.Model Sizepresents parameter counts of different model sizes.Pre-training Scalemeasures pre-training datasets in time points.Token Levelpresents the graininess of time series tokens.Tokenizationdenotes what kind of values are embedded from time series.Context Lengthme...
-
[34]
Zero-shot forecasting performance of models trained on different scales of datasets (measured in time points, pts, and 1B means a billion). We report the averaged results from four prediction lengths{96,192,336,720}on Time-Series-Library (Wu et al., 2022). Model (pts.) Chronos (94B) Moirai (230B) Sundial (94B) Sundial (230B) Sundial (1032B) Dataset MSE MA...
work page 2022
-
[35]
Zero-shot forecasting performance using different lookback lengths in {480,960,1440,1920,2400,2880} . We report the averaged results from four prediction lengths{96,192,336,720}on Time-Series-Library (Wu et al., 2022). 15 Sundial: A Family of Highly Capable Time Series Foundation Models C.4. Zero-Shot Results of Point Forecasting Table 9 provides full zer...
work page 1920
-
[36]
We compare the most advanced time series foundation models based on their official checkpoints, including Time-MoE (Shi et al., 2024b), Timer (Liu et al., 2024a;b), Moirai (Woo et al., 2024), TimesFM (Das et al., 2023b), and Chronos (Ansari et al., 2024). We conduct zero-shot evaluations on datasets that are not included during the pre-training of the cor...
work page 2024
-
[37]
(2024) and established by AutoGluon, which comprises 27 datasets for zero-shot evaluation
We evaluate the performance and inference time on the FEV leaderboard, which was originally proposed by Ansari et al. (2024) and established by AutoGluon, which comprises 27 datasets for zero-shot evaluation. We report aggregated metrics in Figure 4 and assess the inference time in Figure
work page 2024
-
[38]
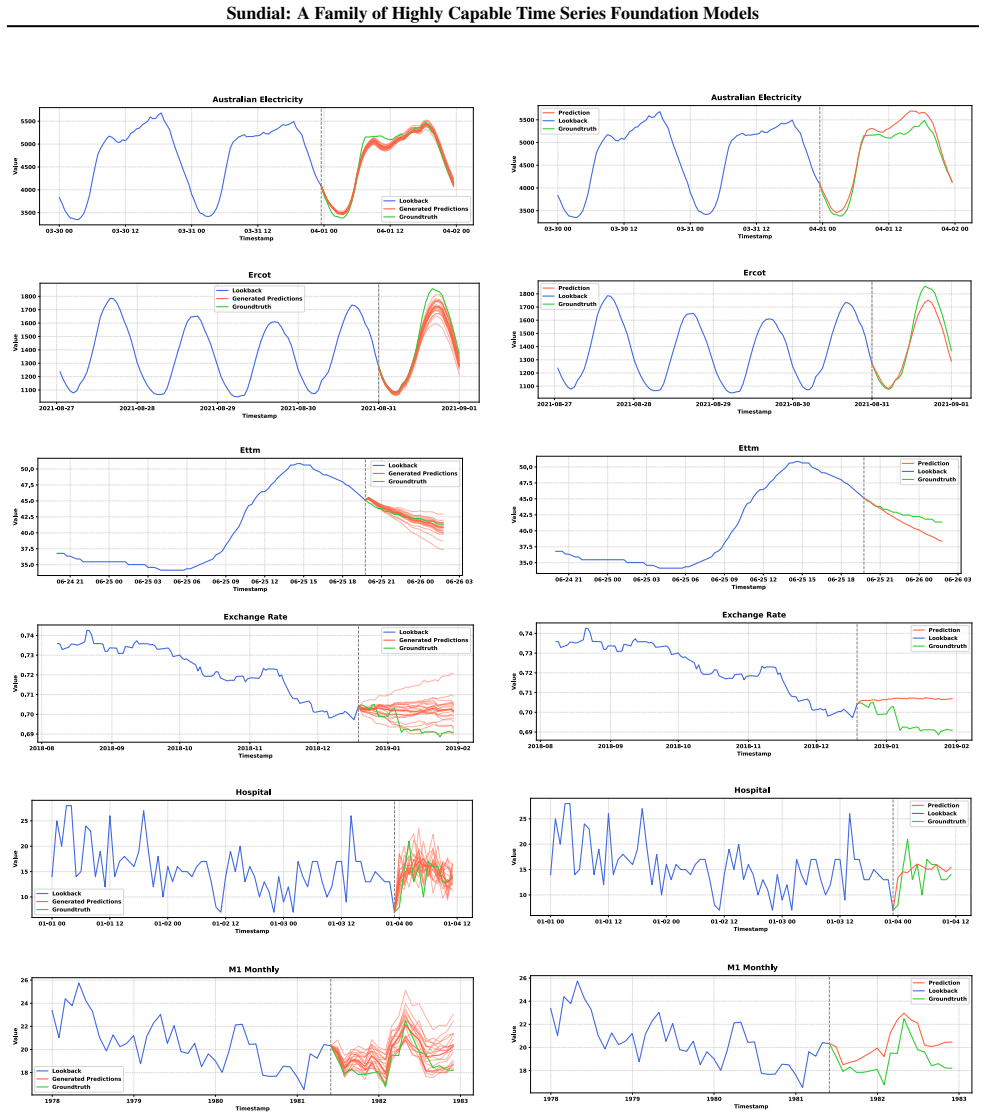
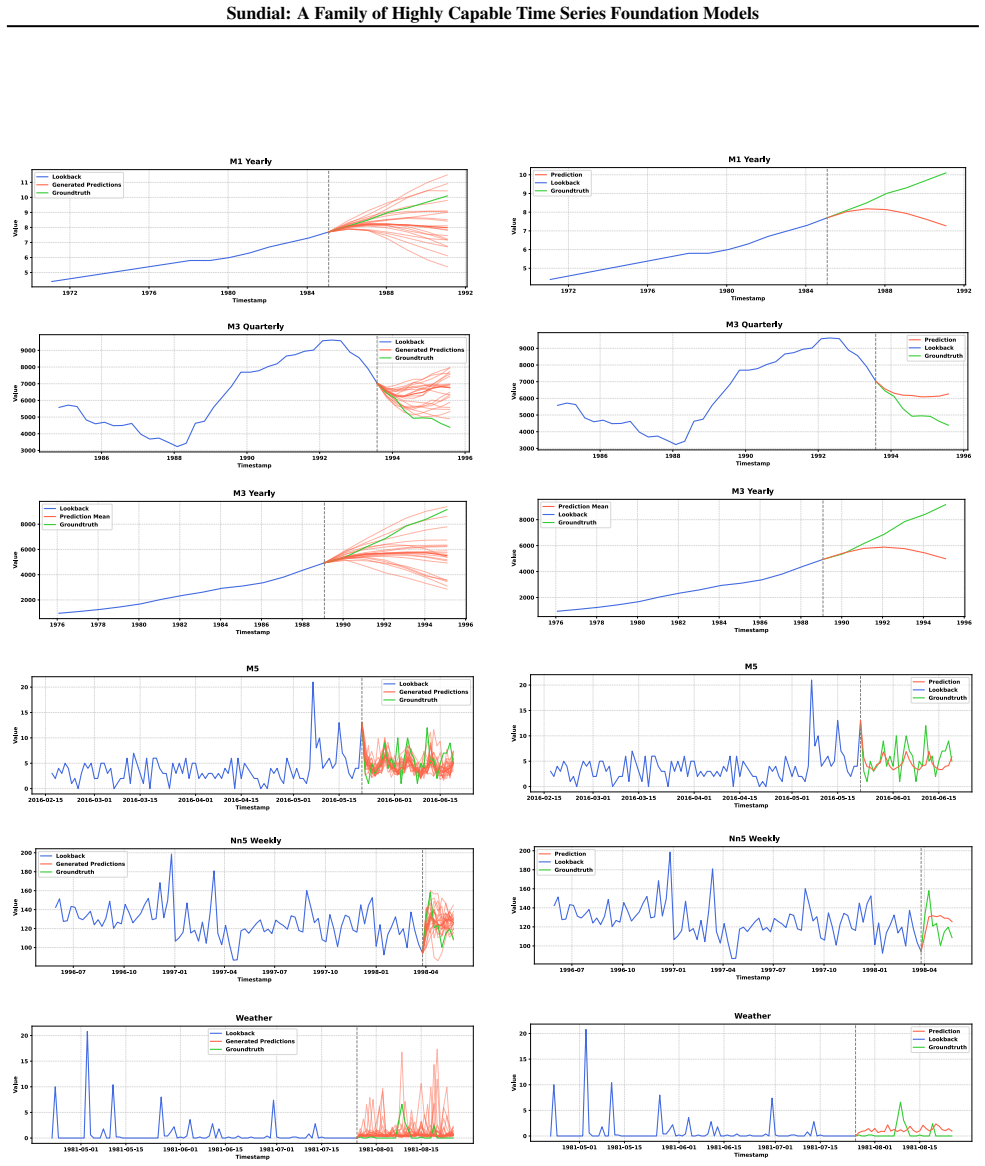
and TSLib (Wu et al., 2022). By generating 20 predictions with different initial noise, we estimate the median and 80% prediction interval. D.2. Showcases of Generative Forecasters and Deterministic Forecasters As we introduce generative modeling in time series foundation models, we compare zero-shot forecasting showcases from two types of models, includi...
work page 2022
-
[39]
A lower MSE or MAE indicates a better prediction
Zero-shot forecasting results of time series foundation models on long-term forecasting datasets (Wu et al., 2022). A lower MSE or MAE indicates a better prediction. Averaged results of four prediction lengths are reported here. 1st Count represents the number of wins achieved by a model under all prediction lengths and datasets. Results of baseline model...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.