Doing More With Less: Towards More Data-Efficient Syndrome-Based Neural Decoders
Pith reviewed 2026-05-23 03:10 UTC · model grok-4.3
The pith
Carefully chosen samples from fixed datasets let syndrome-based neural decoders reach better performance with fewer training examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose several heuristics for selecting training samples from fixed datasets and provide experimental evidence that syndrome-based neural decoders trained on these curated sets achieve higher performance than decoders trained on larger randomly chosen or dynamically generated sets, all while using fewer examples overall.
What carries the argument
Heuristics for selecting training samples and targets from fixed datasets in syndrome-based neural decoding.
If this is right
- Fixed datasets are preferable to dynamic on-the-fly generation of training data.
- Heuristics for choosing which samples to include improve decoder accuracy over random selection.
- Superior decoding performance is possible while using substantially fewer training examples.
- Existing neural decoder architectures can reach higher potential when paired with better-curated data.
Where Pith is reading between the lines
- The same selection rules might transfer to new code parameters if the underlying statistics remain similar.
- Data curation could become a standard preprocessing step before training any neural decoder.
- The approach highlights that data quality can matter at least as much as network size or loss function choice.
Load-bearing premise
The sample-selection heuristics produce training sets whose statistical properties stay advantageous when the channel or code parameters differ from those used to create the heuristics.
What would settle it
Train decoders with the proposed heuristics on one noise level or code length, then test them on a noticeably different noise level or longer code; if the curated small set no longer beats a larger random set, the efficiency claim does not hold.
Figures
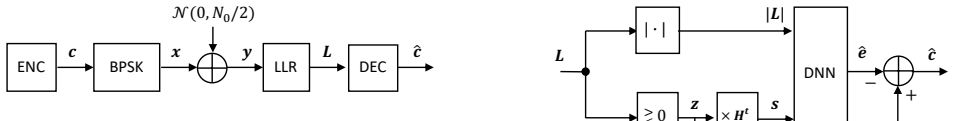




read the original abstract
While significant research efforts have been directed toward developing more capable neural decoding architectures, comparatively little attention has been paid to the quality of training data. In this study, we address the challenge of constructing effective training datasets to maximize the potential of existing syndrome-based neural decoder architectures. We emphasize the advantages of using fixed datasets over generating training data dynamically and explore the problem of selecting appropriate training targets within this framework. Furthermore,we propose several heuristics for selecting training samples and present experimental evidence demonstrating that, with carefully curated datasets, it is possible to train neural decoders to achieve superior performance while requiring fewer training examples. Code to reproduce all results is available at https://github.com/lebidan/sbnd.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that syndrome-based neural decoders can achieve superior performance with fewer training examples by using fixed, carefully curated datasets rather than dynamically generated ones, and proposes several heuristics for selecting appropriate training samples within this fixed-dataset framework. Experimental evidence is presented to support the data-efficiency gains, and reproduction code is made available.
Significance. If the results hold under broader conditions, the work would usefully redirect attention in neural decoding research toward training-data quality and curation rather than solely architecture innovation. The explicit provision of reproduction code is a clear strength that aids verifiability and follow-on work.
major comments (2)
- [Abstract] Abstract and experimental section: the central claim of superior performance with fewer examples is asserted but the provided abstract supplies no quantitative metrics, baselines, error bars, or description of the selection heuristics, preventing direct evaluation of the reported gains.
- [Proposed heuristics and experiments] Heuristics and experimental validation: the sample-selection heuristics are designed using code- and channel-specific features; the manuscript must demonstrate that the performance advantage persists under parameter shifts (different code length/rate or SNR/crossover probability) rather than remaining an in-distribution artifact, as this directly bears on whether the data-efficiency result is general.
minor comments (1)
- [Abstract] Typo in abstract: 'Furthermore,we' should read 'Furthermore, we'.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendation for major revision. We address each major comment below and indicate planned changes to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: the central claim of superior performance with fewer examples is asserted but the provided abstract supplies no quantitative metrics, baselines, error bars, or description of the selection heuristics, preventing direct evaluation of the reported gains.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will expand the abstract to report key quantitative gains (including comparisons against dynamic-generation baselines), reference error bars from repeated trials, and provide a concise description of the sample-selection heuristics. revision: yes
-
Referee: [Proposed heuristics and experiments] Heuristics and experimental validation: the sample-selection heuristics are designed using code- and channel-specific features; the manuscript must demonstrate that the performance advantage persists under parameter shifts (different code length/rate or SNR/crossover probability) rather than remaining an in-distribution artifact, as this directly bears on whether the data-efficiency result is general.
Authors: The heuristics are intentionally constructed around code- and channel-specific features to enable effective curation. Our current experiments already cover multiple representative codes and channel conditions to illustrate the data-efficiency benefit. In the revision we will add further results under parameter shifts (additional code lengths/rates and SNR values) to substantiate that the observed advantages are not limited to the original parameter settings. revision: yes
Circularity Check
No derivation chain present; empirical heuristics and experiments are self-contained
full rationale
The paper proposes sample-selection heuristics and reports experimental results on data efficiency for neural decoders. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems are invoked. The central claim rests on curated datasets and empirical performance comparisons rather than any reduction to inputs by construction. Any self-citations (if present) are not load-bearing for a mathematical argument, satisfying the criteria for a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On deep learning- based channel decoding,
T. Gruber, S. Cammerer, J. Hoydis and S. t. Brink, “On deep learning- based channel decoding,” in Proc. 2017 51st Annual Conf. on Inform. Sciences and Systems (CISS) , Baltimore, MD, USA, 2017
work page 2017
-
[2]
Recent advances in deep learning for channel coding: A survey,
T. Matsumine and H. Ochiai, “Recent advances in deep learning for channel coding: A survey,” IEEE Open Journal of the Commun. Soc. , early access, Oct. 2024
work page 2024
-
[3]
Deep learning methods for improved decoding of linear codes,
E. Nachmani, E. Marciano, L. Lugosch, W. Gross, D. Burshtein and Y . Be’ery, “Deep learning methods for improved decoding of linear codes,” IEEE J. Sel. Topics Signal Proc , vol. 12, no. 1, pp. 119-131, Feb. 2018
work page 2018
-
[4]
Learned decimation for neural belief propagation decoders,
A. Buchberger, C. H ¨ager, H. D. Pfister, L. Schmalen and A. Graell i Amat, “Learned decimation for neural belief propagation decoders,” in Proc 2021 IEEE Int. Conf. on Acoustics, Speech and Signal Proc. (ICASSP), Toronto, ON, Canada, 2021
work page 2021
-
[5]
Decoding short LDPC Codes via BP-RNN diversity and reliability-based post-processing,
J. Rosseel, V . Mannoni, I. Fijalkow and V . Savin, “Decoding short LDPC Codes via BP-RNN diversity and reliability-based post-processing,” IEEE Trans. Commun. , vol. 70, no. 12, pp. 7830–7842, Dec. 2022
work page 2022
-
[6]
Graph neural net- works for channel decoding,
S. Cammerer, J. Hoydis, F. A. Aoudia and A. Keller, “Graph neural net- works for channel decoding,” in Proc. 2022 IEEE Globecom Workshops (GC Wkshps), Rio de Janeiro, Brazil, 2022, pp. 486-491
work page 2022
-
[7]
A scalable graph neural network decoder for short block codes,
K. Tian, C. Yue, C. She, Y . Li and B. Vucetic, “A scalable graph neural network decoder for short block codes,” in Proc. IEEE Int. Conf. Commun. (ICC), Rome, Italy, 2023, pp. 1268-1273
work page 2023
-
[8]
Deep learning for decoding of linear codes - A syndrome-based approach,
A. Bennatan, Y . Choukroun, and P. Kisilev, “Deep learning for decoding of linear codes - A syndrome-based approach,” in Proc 2018 IEEE Int. Symp. on Inform. Theory (ISIT ), Vail, CO, USA, 2018, pp. 1595-1599
work page 2018
-
[9]
Improved syndrome-based neural decoder for linear block codes,
G. De Boni Rovella and M. Benammar, “Improved syndrome-based neural decoder for linear block codes,” in Proc. 2023 IEEE Global Commun. Conf. (GLOBECOM) , Kuala Lumpur, Malaysia, 2023
work page 2023
-
[10]
On a unified deep neural network decoding architecture,
D. Artemasov, K. Andreev and A. Frolov, “On a unified deep neural network decoding architecture,” in Proc/ 2023 IEEE 98th Vehicular Technology Conference (VTC2023-Fall), Hong Kong, Hong Kong, 2023
work page 2023
-
[11]
Error correction code transformer
Y . Choukroun and L. Wolf, “Error correction code transformer.”, in Adv. in Neural Inform. Proc. Sys. (NeurIPS), vol. 35, pp. 38695–38705, 2022
work page 2022
-
[12]
A foundation model for error correction codes
Y . Choukroun and L. Wolf, “A foundation model for error correction codes”, in Proc Forty-first Int. Conf. on Machine Learning (ICML), 2024
work page 2024
-
[13]
CrossMPT: Cross-attention message-passing trans- former for error correcting codes
S.-J. Park, et al. “CrossMPT: Cross-attention message-passing trans- former for error correcting codes”, Preprint. arXiv:2405.01033 (2024)
-
[14]
Foundations of data-efficient learning
B. Mirzasoleiman, and S. Joshi, “Foundations of data-efficient learning”, Proc Forty-first Int. Conf. on Machine Learning (ICML) , 2024
work page 2024
-
[15]
Sketching data sets for large-scale learning: Keeping only what you need,
R. Gribonval, A. Chatalic, N. Keriven, V . Schellekens, L. Jacques and P. Schniter, “Sketching data sets for large-scale learning: Keeping only what you need,” IEEE Signal Proc. Mag. , vol. 8, no. 5, Sept. 2021
work page 2021
-
[16]
Towards a statistical theory of data selection under weak supervision
G. Kolossov, A. Montanari, and P. Tandon, “Towards a statistical theory of data selection under weak supervision”, in Proc. 12th Int. Conf. on Learning Repr. (ICLR), 2024
work page 2024
-
[17]
D. Nguyen et al , “Make the most of your data: Changing the training data distribution to improve in-distribution generalization performance”. Preprint arXiv:2404.17768, 2024
-
[18]
Active deep decoding of linear codes,
I. Be’ery, N. Raviv, T. Raviv, and Y . Be’ery, “Active deep decoding of linear codes,” IEEE Trans. Commun. , vol. 68, no. 2, Feb. 2020
work page 2020
-
[19]
Maximum likelihood soft decoding of binary block codes and decoders for the Golay codes,
J. Snyders and Y . Be’ery, “Maximum likelihood soft decoding of binary block codes and decoders for the Golay codes,” IEEE Trans. Inform. Theory, vol. 35, no. 5, pp. 963-975, Sept. 1989
work page 1989
-
[20]
The construction of fast, high-rate, soft decision block decoders,
E. Berlekamp, “The construction of fast, high-rate, soft decision block decoders,” IEEE Trans. Inform. Theory , vol. 29, no. 3, May 1983
work page 1983
-
[21]
Choukroun, Error Correction Code Transformer (2022) [Source code]
Y . Choukroun, Error Correction Code Transformer (2022) [Source code]. https://github.com/yoniLc/ECCT
work page 2022
-
[22]
Soft-decision decoding of linear block codes based on ordered statistics,
M. P. C. Fossorier and S. Lin, “Soft-decision decoding of linear block codes based on ordered statistics,” IEEE Trans. Inform. Theory, vol. 41, no. 5, pp. 1379-1396, Sept. 1995
work page 1995
-
[23]
Radius domain-based importance sampling estimator for linear block codes over the AWGN channel,
J. Pan and W. H. Mow, “Radius domain-based importance sampling estimator for linear block codes over the AWGN channel,” in Proc. 2022 IEEE Int. Conf. Commun. (ICC) , Seoul, Korea, 2022, pp. 1343-1348
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.