A Review of Causal Decision Making
Pith reviewed 2026-05-23 02:45 UTC · model grok-4.3
The pith
Causal decision making proceeds through structure learning, effect estimation, and policy application.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
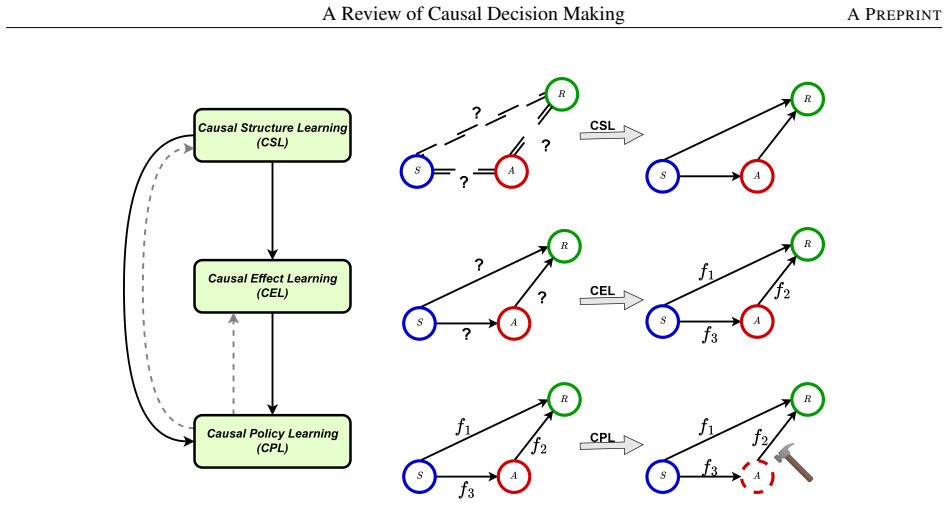
The review establishes that effective causal decision-making requires three sequential components: causal structure learning to discover relationships, causal effect learning to quantify impacts, and causal policy learning to select actions, all supported by a consolidated Python collection of methods along with identified challenges and research directions.
What carries the argument
The three-stage pipeline of causal structure learning, causal effect learning, and causal policy learning.
If this is right
- Practitioners can follow the three stages in order to build decision systems from observational data.
- Advances that solve the listed challenges will directly improve the pipeline's reliability.
- The Python collection serves as a concrete implementation resource for the full framework.
- Real-world applications can be developed by chaining methods across the three stages.
Where Pith is reading between the lines
- The staged structure could guide integration of causal methods with existing reinforcement-learning systems.
- Testing the pipeline on domains with partial observability would reveal where the stages break down.
- Future extensions might add feedback loops that let policy learning refine earlier structure estimates.
Load-bearing premise
The selected methods and challenges in the three stages accurately represent the current state of the field without major omissions or selection bias.
What would settle it
A widely used causal decision-making method or an important practical challenge that is absent from the review and cannot be fit into the three-stage structure.
Figures






read the original abstract
To make effective decisions, it is important to have a thorough understanding of the causal relationships among actions, environments, and outcomes. This review aims to surface three crucial aspects of decision-making through a causal lens: 1) the discovery of causal relationships through causal structure learning, 2) understanding the impacts of these relationships through causal effect learning, and 3) applying the knowledge gained from the first two aspects to support decision making via causal policy learning. Moreover, we identify challenges that hinder the broader utilization of causal decision-making and discuss recent advances in overcoming these challenges. Finally, we provide future research directions to address these challenges and to further enhance the implementation of causal decision-making in practice, with real-world applications illustrated based on the proposed causal decision-making. We aim to offer a comprehensive methodology and practical implementation framework by consolidating various methods in this area into a Python-based collection. URL: https://causaldm.github.io/Causal-Decision-Making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reviews causal decision making by organizing the literature into three stages—causal structure learning, causal effect learning, and causal policy learning—while identifying challenges, discussing advances to overcome them, outlining future directions, and consolidating methods into a Python collection (with real-world application examples) hosted at causaldm.github.io/Causal-Decision-Making.
Significance. If the coverage is representative and the Python implementations faithful, the review would supply a useful organizing framework and accessible implementation resource for causal ML applied to decisions. The explicit consolidation of methods into a public Python collection is a concrete strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim to offer a 'comprehensive methodology' and to surface the three stages without major omissions is load-bearing for the central contribution, yet no inclusion criteria, search protocol, date range, or explicit rationale for method selection appears in the abstract or introductory sections; this leaves open the possibility that recent advances (e.g., scalable discovery under latent confounding or instrument-based off-policy evaluation) are underrepresented.
- The manuscript's assessment of challenges and future directions rests on the chosen literature; without documented selection criteria it is impossible to evaluate whether the listed challenges are the most pressing or whether the cited advances are the most relevant.
minor comments (1)
- The repository URL is given but no statement confirms that the collection has been tested against the original papers' reported results or includes unit tests for the reviewed algorithms.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in literature selection. We will revise the manuscript to include explicit selection criteria and rationale, which will strengthen the presentation of the three-stage framework, challenges, and future directions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim to offer a 'comprehensive methodology' and to surface the three stages without major omissions is load-bearing for the central contribution, yet no inclusion criteria, search protocol, date range, or explicit rationale for method selection appears in the abstract or introductory sections; this leaves open the possibility that recent advances (e.g., scalable discovery under latent confounding or instrument-based off-policy evaluation) are underrepresented.
Authors: We agree that the abstract and introduction would benefit from an explicit statement of scope. The review organizes the literature around the three-stage conceptual framework (structure learning, effect learning, policy learning) and prioritizes methods with publicly available implementations that support the accompanying Python collection. We will add a dedicated paragraph in the Introduction describing this rationale, the emphasis on decision-oriented applications, and the time frame of literature considered. We will also assess the two example advances cited and incorporate brief discussion where they align with the stages. revision: yes
-
Referee: The manuscript's assessment of challenges and future directions rests on the chosen literature; without documented selection criteria it is impossible to evaluate whether the listed challenges are the most pressing or whether the cited advances are the most relevant.
Authors: We accept that documenting the selection process will allow readers to better judge the completeness of the identified challenges and proposed directions. The challenges are drawn directly from limitations observed across the methods reviewed in each stage, and the future directions target practical deployment gaps. Adding the selection rationale (as noted above) will make this linkage clearer without altering the core organization or the Python resource. revision: yes
Circularity Check
No circularity: review paper with no derivations or predictions
full rationale
This is a survey paper that organizes existing literature into three stages (causal structure learning, causal effect learning, causal policy learning), identifies challenges, and points to a Python collection. No original equations, derivations, fitted parameters, or predictions are presented. The central claims are descriptive syntheses of prior work rather than reductions of new results to inputs defined within the paper. None of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) apply. The absence of explicit inclusion criteria for the review is a potential coverage limitation but does not constitute circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This review aims to surface three crucial aspects... consolidating various methods... into a Python-based collection.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Kernelized Advantage Estimation: From Nonparametric Statistics to LLM Reasoning
Kernel smoothing yields accurate value and gradient estimates for low-variance policy learning in LLM reasoning under tight per-prompt sampling budgets.
-
Kernelized Advantage Estimation: From Nonparametric Statistics to LLM Reasoning
Kernel smoothing enables accurate low-variance value and gradient estimates for policy optimization in LLM reasoning under tight sampling constraints per prompt.
-
Causal Additive Models with Unobserved Causal Paths and Backdoor Paths
Establishes sufficient conditions for causal direction identification in additive models with unobserved paths and introduces a sound, complete search algorithm.
Reference graph
Works this paper leans on
-
[1]
The economic costs of conflict: A case study of the basque country
Abadie A, Gardeazabal J (2003). The economic costs of conflict: A case study of the basque country. American economic review, 93(1): 113–132. Abadie A, Imbens GW (2006). Large sample properties of matching estimators for average treatment effects. econo- metrica, 74(1): 235–267. Abadie A, Imbens GW (2008). On the failure of the bootstrap for matching esti...
-
[2]
In: The economics of artificial intelligence, 507–552
the impact of machine learning on economics. In: The economics of artificial intelligence, 507–552. University of Chicago Press. Athey S, Bayati M, Doudchenko N, Imbens G, Khosravi K (2021). Matrix completion methods for causal panel data models. Journal of the American Statistical Association, 116(536): 1716–1730. Athey S, Chetty R, Imbens G (2020). Comb...
-
[3]
Bai Y , Gao Y , Wan R, Zhang S, Song R (2024)
Statistics in medicine, 27(12): 2037–2049. Bai Y , Gao Y , Wan R, Zhang S, Song R (2024). A review of reinforcement learning in financial applications.Annual Review of Statistics and Its Application,
work page 2037
-
[4]
Baird III LC (1993). Advantage updating. Technical report, WRIGHT LAB WRIGHT-PATTERSON AFB OH. Balakrishnan S, Bi J, Soh H (2022). Scales: From fairness principles to constrained decision-making. In: Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, 46–55. Bannon J, Windsor B, Song W, Li T (2020). Causality and batch reinforcement le...
-
[5]
Heterogeneous treatment and spillover effects under clustered network interference
Bargagli-Stoffi FJ, Tortù C, Forastiere L (2020). Heterogeneous treatment and spillover effects under clustered network interference. arXiv preprint arXiv:2008.00707. Bargiacchi E, Verstraeten T, Roijers D, Nowé A, Hasselt H (2018). Learning to coordinate with coordination graphs in repeated single-stage multi-agent decision problems. In: International co...
-
[6]
No regrets for learning the prior in bandits
Basu S, Kveton B, Zaheer M, Szepesvári C (2021). No regrets for learning the prior in bandits. Advances in neural information processing systems, 34: 28029–28041. Baxter J, Bartlett PL (2001). Infinite-horizon policy-gradient estimation. journal of artificial intelligence research, 15: 319–350. Bellemare M, Srinivasan S, Ostrovski G, Schaul T, Saxton D, M...
work page 2021
-
[7]
Doubly robust nonparametric inference on the average treatment effect
Benkeser D, Carone M, Laan MVD, Gilbert PB (2017). Doubly robust nonparametric inference on the average treatment effect. Biometrika, 104(4): 863–880. Bibaut A, Dimakopoulou M, Kallus N, Chambaz A, van der Laan M (2021). Post-contextual-bandit inference.Advances in Neural Information Processing Systems,
work page 2017
-
[8]
A Survey on Practical Applications of Multi-Armed and Contextual Bandits
Bietti A, Agarwal A, Langford J (2021). A contextual bandit bake-off. Journal of Machine Learning Research, 22(133): 1–49. Blyth CR (1972). On simpson’s paradox and the sure-thing principle. Journal of the American Statistical Association, 67(338): 364–366. Bollen KA (1987). Total, direct, and indirect effects in structural equation models. Sociological m...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Bühlmann P, Peters J, Ernest J, et al. (2014). Cam: Causal additive models, high-dimensional order search and penalized regression. The Annals of Statistics, 42(6): 2526–2556. Cai H, Song R, Lu W (2020). Anoce: Analysis of causal effects with multiple mediators via constrained structural learning. In: International Conference on Learning Representations. ...
work page 2014
-
[10]
Flexible and efficient contextual bandits with heterogeneous treatment effect oracles
42 A Review of Causal Decision Making A PREPRINT Carranza AG, Krishnamurthy SK, Athey S (2023). Flexible and efficient contextual bandits with heterogeneous treatment effect oracles. In: International Conference on Artificial Intelligence and Statistics, 7190–7212. PMLR. Cesa-Bianchi N, Fischer P (1998). Finite-time regret bounds for the multiarmed bandit...
-
[11]
An empirical evaluation of thompson sampling
Chapelle O, Li L (2011). An empirical evaluation of thompson sampling. Advances in neural information processing systems, 24: 2249–2257. Chen F (2009). Bayesian modeling using the mcmc procedure. In: Proceedings of the SAS Global Forum 2008 Conference, Cary NC: SAS Institute Inc. Citeseer. Chen G, Zeng D, Kosorok MR (2016). Personalized dose finding using...
-
[12]
Optimal structure identification with greedy search
Chickering DM (2002). Optimal structure identification with greedy search. Journal of machine learning research, 3(Nov): 507–554. Chu W, Li L, Reyzin L, Schapire R (2011). Contextual bandits with linear payoff functions. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 208–214. JMLR Workshop and Confere...
work page 2002
-
[13]
Pessimistic off-policy optimization for learning to rank
Cief M, Kveton B, Kompan M (2022). Pessimistic off-policy optimization for learning to rank. arXiv preprint arXiv:2206.02593. Crump RK, Hotz VJ, Imbens GW, Mitnik OA (2009). Dealing with limited overlap in estimation of average treatment effects. Biometrika, 96(1): 187–199. Cui Y , Tchetgen Tchetgen E (2021). A semiparametric instrumental variable approac...
-
[14]
Dubey A, et al. (2020). Kernel methods for cooperative multi-agent contextual bandits. In: International Conference on Machine Learning, 2740–2750. PMLR. Dudik M, Hsu D, Kale S, Karampatziakis N, Langford J, Reyzin L, et al. (2011). Efficient optimal learning for contextual bandits. arXiv preprint arXiv:1106.2369. Dudík M, Langford J, Li L (2011). Doubly ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Farahat A, Bailey MC (2012). How effective is targeted advertising? In: Proceedings of the 21st international conference on World Wide Web, 111–120. Feder A, Keith KA, Manzoor E, Pryzant R, Sridhar D, Wood-Doughty Z, et al. (2021). Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. arXiv preprint arXiv:2109...
-
[16]
Hu X, Zhang R, Tang K, Guo J, Yi Q, Chen R, et al
Cambridge university press. Hu X, Zhang R, Tang K, Guo J, Yi Q, Chen R, et al. (2022). Causality-driven hierarchical structure discovery for reinforcement learning. Advances in Neural Information Processing Systems, 35: 20064–20076. Hu Y , Kallus N (2020). Dtr bandit: Learning to make response-adaptive decisions with low regret. arXiv preprint arXiv:2005....
-
[17]
Imai K, Keele L, Yamamoto T (2010b). Identification, inference and sensitivity analysis for causal mediation effects. Imbens G, Kallus N, Mao X, Wang Y (2022). Long-term causal inference under persistent confounding via data combination. arXiv preprint arXiv:2202.07234. Imbens GW (2004). Nonparametric estimation of average treatment effects under exogenei...
-
[18]
Doubly robust thompson sampling with linear payoffs
46 A Review of Causal Decision Making A PREPRINT Kim W, Kim GS, Paik MC (2021). Doubly robust thompson sampling with linear payoffs. Advances in Neural Information Processing Systems, 34: 15830–15840. Kim W, Lee K, Paik MC (2023). Double doubly robust thompson sampling for generalized linear contextual bandits. In: Proceedings of the AAAI Conference on Ar...
work page 2021
-
[19]
Stabilizing off-policy q-learning via bootstrapping error reduction
Kumar A, Fu J, Soh M, Tucker G, Levine S (2019). Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in Neural Information Processing Systems,
work page 2019
-
[20]
Gradient-based neural dag learning
Künzel SR, Sekhon JS, Bickel PJ, Yu B (2019). Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the national academy of sciences, 116(10): 4156–4165. Kveton B, Konobeev M, Zaheer M, Hsu Cw, Mladenov M, Boutilier C, et al. (2021). Meta-thompson sampling. In: International Conference on Machine Learning, 5884...
-
[21]
Lattimore T, Szepesvári C (2020). Bandit algorithms. Cambridge University Press. Le H, V oloshin C, Yue Y (2019). Batch policy learning under constraints. In:International Conference on Machine Learning, 3703–3712. PMLR. Leacy FP, Stuart EA (2014). On the joint use of propensity and prognostic scores in estimation of the average treatment effect on the tr...
work page 2020
-
[22]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Lee S, Bareinboim E (2019). Structural causal bandits with non-manipulable variables. In: Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 4164–4172. Lee S, Honavar V (2020). Towards robust relational causal discovery. In:Uncertainty in Artificial Intelligence, 345–355. PMLR. Leung MP (2022a). Causal inference under approximate ne...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Unifying offline causal inference and online bandit learning for data driven decision
Li Y , Xie H, Lin Y , Lui JC (2021b). Unifying offline causal inference and online bandit learning for data driven decision. In: Proceedings of the Web Conference 2021, 2291–2303. Liang S, Lu W, Song R (2018). Deep advantage learning for optimal dynamic treatment regime. Statistical theory and related fields, 2(1): 80–88. Liao P, Qi Z, Wan R, Klasnja P, M...
work page 2021
-
[24]
Interventional approach for path-specific effects
Lin SH, VanderWeele T (2017). Interventional approach for path-specific effects. Journal of Causal Inference, 5(1). Littman ML (2009). A tutorial on partially observable markov decision processes. Journal of Mathematical Psychology, 53(3): 119–125. Liu Q, Li L, Tang Z, Zhou D (2018a). Breaking the curse of horizon: Infinite-horizon off-policy estimation. ...
work page 2017
-
[25]
A map of bandits for e-commerce.arXiv preprint arXiv:2107.00680
Liu Y , Li L (2021). A map of bandits for e-commerce.arXiv preprint arXiv:2107.00680. Liu Y , Wang Y , Kosorok MR, Zhao Y , Zeng D (2018b). Augmented outcome-weighted learning for estimating optimal dynamic treatment regimens. Statistics in medicine, 37(26): 3776–3788. Lopez-Paz D, Schölkopf B (2017). Discovering causal signals in images. In: Proceedings ...
-
[26]
Explainable reinforcement learning through a causal lens
Madumal P, Miller T, Sonenberg L, Vetere F (2020). Explainable reinforcement learning through a causal lens. In: Proceedings of the AAAI conference on artificial intelligence, volume 34, 2493–2500. 48 A Review of Causal Decision Making A PREPRINT Manski CF (2013). Identification of treatment response with social interactions. The Econometrics Journal, 16(...
-
[27]
Off-policy evaluation in markov decision processes
Paduraru C (2013). Off-policy evaluation in markov decision processes. Pan L, Huang L, Ma T, Xu H (2022). Plan better amid conservatism: Offline multi-agent reinforcement learning with actor rectification. In: International conference on machine learning, 17221–17237. PMLR. Panizza U, Presbitero AF (2014). Public debt and economic growth: is there a causa...
work page 2013
-
[28]
Springer. Pearl J (2003). Statistics and causal inference: A review. Test, 12: 281–345. Pearl J (2010a). Causal inference. Causality: objectives and assessment, 39–58. Pearl J (2010b). The foundations of causal inference. Sociological Methodology, 40(1): 75–149. Pearl J (2022). Direct and indirect effects. In: Probabilistic and causal inference: the works...
-
[29]
Bayesian inference for causal effects: The role of randomization
Rubin DB (1978). Bayesian inference for causal effects: The role of randomization. The Annals of statistics, 6: 34–58. Rubin DB (2004). Direct and indirect causal effects via potential outcomes. Scandinavian Journal of Statistics, 31(2): 161–170. Rummery GA, Niranjan M (1994). On-line Q-learning using connectionist systems , volume
work page 1978
-
[30]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
University of Cambridge, Department of Engineering Cambridge, UK. Runge J, Bathiany S, Bollt E, Camps-Valls G, Coumou D, Deyle E, et al. (2019). Detecting and quantifying causal associations in large nonlinear time series datasets. Science Advances, 5(11): eaau4996. Russo DJ, Van Roy B, Kazerouni A, Osband I, Wen Z, et al. (2018). A tutorial on thompson s...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Contextual Multi-Armed Bandits for Causal Marketing
Sawant N, Namballa CB, Sadagopan N, Nassif H (2018). Contextual multi-armed bandits for causal marketing. arXiv preprint arXiv:1810.01859. Schölkopf B, Locatello F, Bauer S, Ke NR, Kalchbrenner N, Goyal A, et al. (2021). Toward causal representation learning. Proceedings of the IEEE, 109(5): 612–634. Schulman J, Levine S, Abbeel P, Jordan M, Moritz P (201...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Causal influence detection for improving efficiency in reinforcement learning
Seitzer M, Schölkopf B, Martius G (2021). Causal influence detection for improving efficiency in reinforcement learning. Advances in Neural Information Processing Systems, 34: 22905–22918. Selig JP, Preacher KJ (2009). Mediation models for longitudinal data in developmental research. Research in human development, 6(2-3): 144–164. Sen R, Shanmugam K, Dima...
-
[33]
High-dimensional a-learning for optimal dynamic treatment regimes
Shi C, Fan A, Song R, Lu W (2018). High-dimensional a-learning for optimal dynamic treatment regimes. Annals of statistics, 46(3):
work page 2018
-
[34]
Testing mediation effects using logic of boolean matrices
Shi C, Li L (2021). Testing mediation effects using logic of boolean matrices. Journal of the American Statistical Association, 1–14. 51 A Review of Causal Decision Making A PREPRINT Shi C, Luo S, Le Y , Zhu H, Song R (2024). Statistically efficient advantage learning for offline reinforcement learning in infinite horizons. Journal of the American Statist...
-
[35]
Partially observable markov decision processes
Spaan MT (2012). Partially observable markov decision processes. Reinforcement learning: State-of-the-art, 387–414. Spirtes P, Glymour C, Scheines R, Kauffman S, Aimale V , Wimberly F (2000a). Constructing bayesian network models of gene expression networks from microarray data. Spirtes P, Glymour CN, Scheines R, Heckerman D (2000b). Causation, prediction...
work page 2012
-
[36]
Modelling and estimation for optimal treatment decision with interference
52 A Review of Causal Decision Making A PREPRINT Su L, Lu W, Song R (2019a). Modelling and estimation for optimal treatment decision with interference. Stat, 8(1): e219. Su Y , Dimakopoulou M, Krishnamurthy A, Dudík M (2019b). Doubly robust off-policy evaluation with shrinkage. arXiv preprint arXiv:1907.09623. Subramanian C, Ravindran B (2021). Causal con...
-
[37]
Swaminathan A, Krishnamurthy A, Agarwal A, Dudik M, Langford J, Jose D, et al. (2017). Off-policy evaluation for slate recommendation. In: Advances in Neural Information Processing Systems, 3632–3642. Tang K, Huang J, Zhang H (2020). Long-tailed classification by keeping the good and removing the bad momentum causal effect. arXiv preprint arXiv:2009.12991...
-
[38]
A review of causal estimation of effects in mediation analyses
Ten Have TR, Joffe MM (2012). A review of causal estimation of effects in mediation analyses. Statistical Methods in Medical Research, 21(1): 77–107. Triantafyllou S, Singla A, Radanovic G (2022). Actual causality and responsibility attribution in decentralized partially observable markov decision processes. In: Proceedings of the 2022 AAAI/ACM Conference...
-
[39]
Conceptual issues concerning mediation, interventions and composition
53 A Review of Causal Decision Making A PREPRINT VanderWeele TJ, Vansteelandt S (2009). Conceptual issues concerning mediation, interventions and composition. Statistics and its Interface, 2(4): 457–468. Vermeulen K, Vansteelandt S (2016). Data-adaptive bias-reduced doubly robust estimation. The international journal of biostatistics, 12(1): 253–282. Vers...
work page 2009
-
[40]
Handling limited overlap in observational studies with cardinality matching
Visconti G, Zubizarreta JR (2018). Handling limited overlap in observational studies with cardinality matching. Observational Studies, 4(1): 217–249. Viviano D (2020). Experimental design under network interference. arXiv preprint arXiv:2003.08421. Viviano D (2024). Policy targeting under network interference. Review of Economic Studies, rdae041. Viviano ...
-
[41]
Behavior Regularized Offline Reinforcement Learning
Macmillan. Wu L, Yang S (2022). Integrativer-learner of heterogeneous treatment effects combining experimental and observational studies. In: Conference on Causal Learning and Reasoning, 904–926. PMLR. Wu Y , Tucker G, Nachum O (2019). Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361. Xiang X, Foo S (2021). Recent advan...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Non-parametric path analysis in structural causal models
Zhang J, Bareinboim E (2018b). Non-parametric path analysis in structural causal models. In: Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence. Zhang K, Janson L, Murphy S (2021). Statistical inference with m-estimators on adaptively collected data. Advances in Neural Information Processing Systems, 34: 7460–7471. Zhang KW, Jans...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.