Risk-averse Decision Making with Contextual Information: Model, Sample Average Approximation, and Kernelization
Pith reviewed 2026-05-23 02:21 UTC · model grok-4.3
The pith
The nested risk minimization over problem data uncertainty given context is equivalent to joint risk minimization over both uncertainties when risk measures are chosen appropriately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Appropriate choices of risk measures make the nested contextual risk process equivalent to joint risk minimization over problem data uncertainty and contextual uncertainty simultaneously; under further conditions the optimal policies are independent of the particular risk measure chosen for the contextual uncertainty.
What carries the argument
The mapping between a nested risk structure (minimize risk of PDU conditional on CU, then assess risk of that policy over CU) and a joint risk measure over both uncertainties, realized by specific pairings of risk measures.
If this is right
- The nested contextual problem reduces to an ordinary one-stage risk minimization problem that admits direct sample average approximation.
- Under the stated conditions the optimal decision does not depend on which risk measure is used to evaluate contextual uncertainty.
- Consistency of optimal values and policies holds for sample average approximations when the problem is posed in a reproducing kernel Hilbert space.
- The same equivalence supplies tractable formulations for standard risk measures in newsvendor and portfolio selection problems.
Where Pith is reading between the lines
- The reduction technique could apply to other multi-layer risk problems in stochastic programming whenever the inner and outer risk measures can be paired appropriately.
- Policy independence from the contextual risk measure would simplify modeling whenever context is observed but its risk cannot be quantified precisely.
- Kernel consistency results may extend to other nonparametric representations of contextual uncertainty beyond the reproducing kernel Hilbert space setting examined here.
Load-bearing premise
The decision process must be structured as first minimizing risk from problem data uncertainty conditional on a contextual observation and only afterward assessing the risk of the resulting policy against contextual uncertainty.
What would settle it
An explicit pair of risk measures together with a joint distribution over PDU and CU such that the policy obtained from the nested process differs from every policy obtained by joint risk minimization, or a concrete instance in which the optimal policy changes when the contextual risk measure is altered while the paper's stated conditions still hold.
Figures
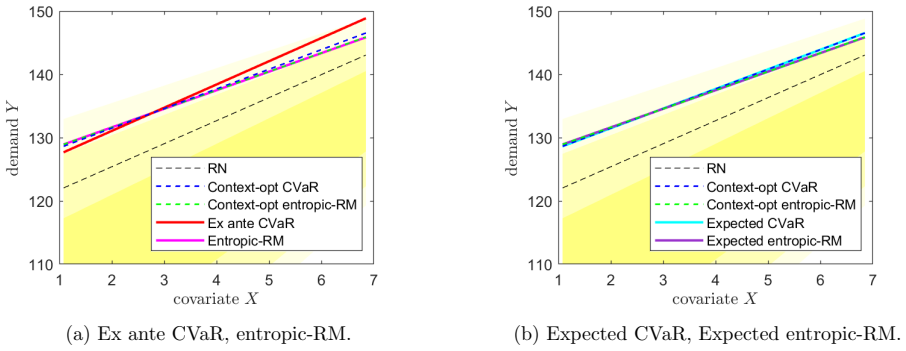
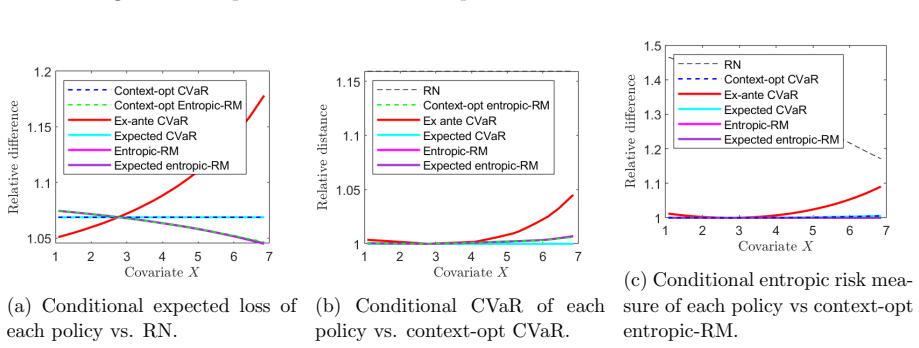


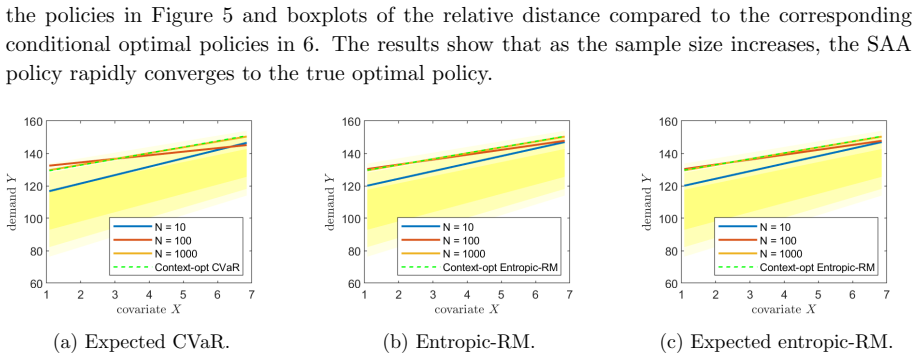

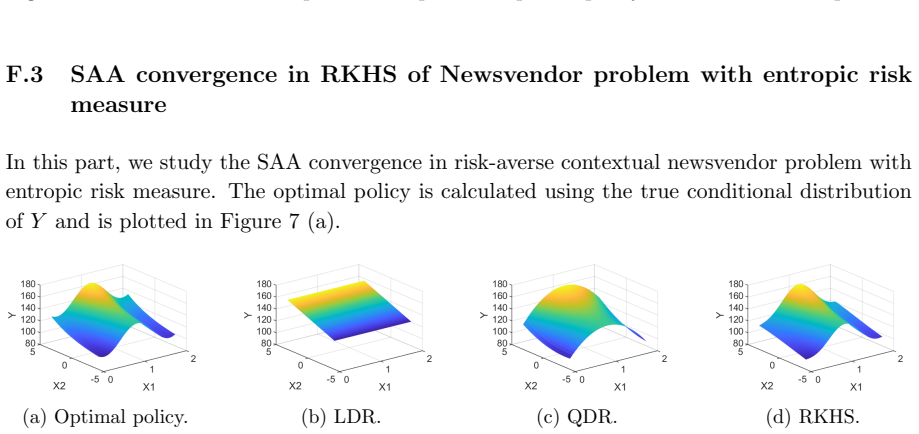

read the original abstract
We consider risk-averse contextual optimization problems where the decision maker (DM) faces two types of uncertainties: problem data uncertainty (PDU) and contextual uncertainty (CU) associated with PDU, the DM makes an optimal decision by minimizing the risk arising from PDU based on the present observation of CU and then assesses the risk of the optimal policy against the CU. A natural question arises as to whether the nested risk minimization/assessment process is equivalent to joint risk minimization/assessment against CU and PDU simultaneously. First, we demonstrate that the equivalence can be established by appropriate choices of the risk measures and give counter examples where such equivalence may fail. One of the interesting findings is that the optimal policies are independent of the choice of the risk measure against the CU under certain conditions. Second, by using the equivalence, we propose computational method for solving the risk-averse contextual optimization problem by solving a one-stage risk minimization problem. The latter is particularly helpful in data-driven environments. We consider a number of risk measures/metrics to characterize the DM's risk preference for PDU and discuss the computational tractability for the resulting risk-averse contextual optimization problem. Third, when the risk-averse contextual optimization problem is defined in the reproducing kernel Hilbert space, we show consistency of the optimal values obtained from solving sample average approximation problems. Some numerical tests, in newsvendor problem and portfolio selection problem, are performed to validate the theoretical results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies risk-averse contextual optimization problems with two uncertainty sources: problem data uncertainty (PDU) and contextual uncertainty (CU). It analyzes when the natural nested procedure (minimize PDU risk conditional on a CU observation, then evaluate the resulting policy under CU risk) is equivalent to joint risk minimization over both uncertainties simultaneously. Equivalence is shown to hold for suitable choices of risk measures, with counterexamples when it fails; under stated conditions the optimal policy is independent of the CU risk measure. The equivalence is used to reduce the problem to a single-stage risk minimization, whose tractability is examined for several risk measures/metrics. Consistency of sample-average approximations is proved when the problem is posed in a reproducing kernel Hilbert space, and the results are illustrated numerically on newsvendor and portfolio instances.
Significance. If the equivalence and independence results hold, the work supplies a principled modeling framework and a practical reduction to one-stage problems that is especially useful in data-driven settings. The RKHS consistency result and the explicit numerical validation on standard test problems add concrete value for stochastic optimization under risk aversion.
minor comments (3)
- [Abstract / §1] The abstract states that equivalence holds 'by appropriate choices of the risk measures' but does not name the classes (e.g., coherent, convex, distortion) for which the result is proved; a brief enumeration in the introduction would help readers locate the precise statements.
- [RKHS consistency section] The consistency theorem for the RKHS formulation should explicitly list the assumptions on the kernel and the risk measure (e.g., continuity, Lipschitz properties) that are used to pass to the limit; these are alluded to but not itemized in the provided description.
- [Numerical experiments] In the numerical section, report the number of SAA samples, the kernel bandwidth selection procedure, and the out-of-sample evaluation protocol so that the observed convergence can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the paper's contributions on equivalence between nested and joint risk measures, policy independence under stated conditions, reduction to one-stage problems, and RKHS consistency. No specific major comments appear in the provided report, so we have no point-by-point responses to address.
Circularity Check
No significant circularity
full rationale
The paper derives equivalence between nested (conditional on CU then risk on PDU) and joint risk minimization for specific choices of risk measures, with explicit counterexamples for failure cases. This is presented as a mathematical result grounded in properties of standard risk measures (e.g., those discussed for PDU). The subsequent reduction to a one-stage problem follows directly from the established equivalence rather than assuming it. Consistency of SAA in RKHS is shown via standard approximation arguments. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain; the independence of optimal policies under conditions is a derived finding, not an input. The structure is self-contained against external benchmarks of risk measure theory.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We demonstrate that the equivalence can be established by appropriate choices of the risk measures... optimal policies are independent of the choice of the risk measure against the CU under certain conditions.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
when the risk-averse contextual optimization problem is defined in the reproducing kernel Hilbert space, we show consistency of the optimal values obtained from solving sample average approximation problems.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Spectral measures of risk: A coherent representation of subjective risk aver- sion
Carlo Acerbi. Spectral measures of risk: A coherent representation of subjective risk aver- sion. Journal of Banking & Finance , 26(7):1505–1518, 2002
work page 2002
-
[2]
Portfolio Optimization with Spectral Measures of Risk
Carlo Acerbi and Prospero Simonetti. Portfolio optimization with spectral measures of risk. arXiv preprint cond-mat/0203607, 2002. 29
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[3]
Spectral risk measures and portfolio selection
Alexandre Adam, Mohamed Houkari, and Jean-Paul Laurent. Spectral risk measures and portfolio selection. Journal of Banking & Finance , 32(9):1870–1882, 2008
work page 2008
-
[4]
The big data newsvendor: Practical insights from machine learning
Gah-Yi Ban and Cynthia Rudin. The big data newsvendor: Practical insights from machine learning. Operations Research, 67(1):90–108, 2019
work page 2019
-
[5]
Generalization bounds for regularized portfolio selection with market side information
Thierry Bazier-Matte and Erick Delage. Generalization bounds for regularized portfolio selection with market side information. INFOR: Information Systems and Operational Research, 58(2):374–401, 2020
work page 2020
-
[6]
Expected utility, penalty functions, and duality in stochastic nonlinear programming
Aharon Ben-Tal and Marc Teboulle. Expected utility, penalty functions, and duality in stochastic nonlinear programming. Management Science, 32(11):1445–1466, 1986
work page 1986
-
[7]
An old-new concept of convex risk measures: The optimized certainty equivalent
Aharon Ben-Tal and Marc Teboulle. An old-new concept of convex risk measures: The optimized certainty equivalent. Mathematical Finance, 17(3):449–476, 2007
work page 2007
-
[8]
Topological Spaces: Including a Treatment of Multi-valued Functions, Vector Spaces and Convexity
Claude Berge. Topological Spaces: Including a Treatment of Multi-valued Functions, Vector Spaces and Convexity. Macmillan, 1963
work page 1963
-
[9]
From predictive to prescriptive analytics
Dimitris Bertsimas and Nathan Kallus. From predictive to prescriptive analytics. Manage- ment Science, 66(3):1025–1044, 2020
work page 2020
-
[10]
Data-driven optimization: A reproducing kernel hilbert space approach
Dimitris Bertsimas and Nihal Koduri. Data-driven optimization: A reproducing kernel hilbert space approach. Operations Research, 70(1):454–471, 2022
work page 2022
-
[11]
Convergence of probability measures
Patrick Billingsley. Convergence of probability measures. John Wiley & Sons, 2013
work page 2013
-
[12]
Theory of classification: A survey of some recent advances
St´ ephane Boucheron, Olivier Bousquet, and G´ abor Lugosi. Theory of classification: A survey of some recent advances. ESAIM: probability and statistics , 9:323–375, 2005
work page 2005
-
[13]
Elements of Mathematics: General Topology
Nicolas Bourbaki. Elements of Mathematics: General Topology. Part 2 . Hermann, 1966
work page 1966
-
[14]
End-to-end conditional robust optimization
Abhilash Chenreddy and Erick Delage. End-to-end conditional robust optimization. arXiv preprint arXiv:2403.04670, 2024
-
[15]
Data-driven conditional robust optimization
Abhilash Reddy Chenreddy, Nymisha Bandi, and Erick Delage. Data-driven conditional robust optimization. Advances in Neural Information Processing Systems , 35:9525–9537, 2022
work page 2022
-
[16]
Alexander S Cherny and Michael Kupper. Divergence utilities. Available at SSRN 1023525, 2007
work page 2007
-
[17]
Advancing stability analysis of mean-risk stochastic programs: Bilevel and two-stage models
Matthias Claus. Advancing stability analysis of mean-risk stochastic programs: Bilevel and two-stage models. PhD thesis, Dissertation, Duisburg, Essen, Universit¨ at Duisburg-Essen, 2016, 2016
work page 2016
-
[18]
Shortfall risk models when information on loss function is incomplete
Erick Delage, Shaoyan Guo, and Huifu Xu. Shortfall risk models when information on loss function is incomplete. Operations Research, 70(6):3511–3518, 2022
work page 2022
-
[19]
Victor DeMiguel, Lorenzo Garlappi, and Raman Uppal. Optimal versus naive diversifi- cation: How inefficient is the 1/n portfolio strategy? The review of Financial studies , 22(5):1915–1953, 2009. 30
work page 1915
-
[20]
Task-based end-to-end model learning in stochastic optimization
Priya Donti, Brandon Amos, and J Zico Kolter. Task-based end-to-end model learning in stochastic optimization. Advances in neural information processing systems , 30, 2017
work page 2017
-
[21]
Generaliza- tion bounds in the predict-then-optimize framework
Othman El Balghiti, Adam N Elmachtoub, Paul Grigas, and Ambuj Tewari. Generaliza- tion bounds in the predict-then-optimize framework. Mathematics of Operations Research, 48(4):2043–2065, 2023
work page 2043
-
[22]
Adam N Elmachtoub and Paul Grigas. Smart “predict, then optimize”. Management Science, 68(1):9–26, 2022
work page 2022
-
[23]
Adam N Elmachtoub, Henry Lam, Haofeng Zhang, and Yunfan Zhao. Estimate-then- optimize versus integrated-estimation-optimization versus sample average approximation: A stochastic dominance perspective. arXiv preprint arXiv:2304.06833 , 2023
-
[24]
Stochastic finance: an introduction in discrete time
Hans F¨ ollmer and Alexander Schied. Stochastic finance: an introduction in discrete time . Walter de Gruyter, 2011
work page 2011
-
[25]
Newsvendor solutions via conditional value-at-risk min- imization
Jun-ya Gotoh and Yuichi Takano. Newsvendor solutions via conditional value-at-risk min- imization. European Journal of Operational Research, 179(1):80–96, 2007
work page 2007
-
[26]
Distributionally robust shortfall risk optimization model and its approximation
Shaoyan Guo and Huifu Xu. Distributionally robust shortfall risk optimization model and its approximation. Mathematical Programming, 174(1):473–498, 2019
work page 2019
-
[27]
Statistical robustness of empirical risks in machine learning
Shaoyan Guo, Huifu Xu, and Liwei Zhang. Statistical robustness of empirical risks in machine learning. Journal of Machine Learning Research , 24(125):1–38, 2023
work page 2023
-
[28]
Integrals, conditional expectations, and martingales of multivalued functions
Fumio Hiai and Hisaharu Umegaki. Integrals, conditional expectations, and martingales of multivalued functions. Journal of Multivariate Analysis , 7(1):149–182, 1977
work page 1977
-
[29]
Risk guarantees for end-to-end prediction and optimization processes
Nam Ho-Nguyen and Fatma Kılın¸ c-Karzan. Risk guarantees for end-to-end prediction and optimization processes. Management Science, 68(12):8680–8698, 2022
work page 2022
-
[30]
Peter J Huber and Elvezio M Ronchetti. Robust statistics. Wiley Series in Probability and Statistics, 2009
work page 2009
-
[31]
Tight approximations of dynamic risk measures
Dan A Iancu, Marek Petrik, and Dharmashankar Subramanian. Tight approximations of dynamic risk measures. Mathematics of Operations Research, 40(3):655–682, 2015
work page 2015
-
[32]
Optimizer’s information criterion: Dis- secting and correcting bias in data-driven optimization
Garud Iyengar, Henry Lam, and Tianyu Wang. Optimizer’s information criterion: Dis- secting and correcting bias in data-driven optimization. arXiv preprint arXiv:2306.10081 , 2023
-
[33]
Stochastic optimization forests
Nathan Kallus and Xiaojie Mao. Stochastic optimization forests. Management Science , 69(4):1975–1994, 2023
work page 1975
-
[34]
Heteroscedasticity-aware residuals- based contextual stochastic optimization
Rohit Kannan, G¨ uzin Bayraksan, and James Luedtke. Heteroscedasticity-aware residuals- based contextual stochastic optimization. arXiv preprint arXiv:2101.03139 , 2021
-
[35]
Residuals-based distributionally robust optimization with covariate information
Rohit Kannan, G¨ uzin Bayraksan, and James R Luedtke. Residuals-based distributionally robust optimization with covariate information. Mathematical Programming, 207(1):369– 425, 2024. 31
work page 2024
-
[36]
Data-driven sample average ap- proximation with covariate information
Rohit Kannan, G¨ uzin Bayraksan, and James R Luedtke. Data-driven sample average ap- proximation with covariate information. Operations Research, 2025
work page 2025
-
[37]
Representation results for law invariant time consistent functions
Michael Kupper and Walter Schachermayer. Representation results for law invariant time consistent functions. Mathematics and Financial Economics , 2(3):189–210, 2009
work page 2009
-
[38]
On law invariant coherent risk measures
Shigeo Kusuoka. On law invariant coherent risk measures. Advances in mathematical economics, pages 83–95, 2001
work page 2001
-
[39]
Data-driven newsvendor problems regularized by a profit risk constraint
Shaochong Lin, Youhua Chen, Yanzhi Li, and Zuo-Jun Max Shen. Data-driven newsvendor problems regularized by a profit risk constraint. Production and Operations Management , 31(4):1630–1644, 2022
work page 2022
-
[40]
Congzheng Liu and Wenqi Zhu. Newsvendor conditional value-at-risk minimisation: A feature-based approach under adaptive data selection. European Journal of Operational Research, 313(2):548–564, 2024
work page 2024
-
[41]
Risk bounds and calibration for a smart predict-then-optimize method
Heyuan Liu and Paul Grigas. Risk bounds and calibration for a smart predict-then-optimize method. Advances in Neural Information Processing Systems , 34:22083–22094, 2021
work page 2021
-
[42]
Multistage utility preference robust optimization
Jia Liu, Zhiping Chen, and Huifu Xu. Multistage utility preference robust optimization. arXiv preprint arXiv:2109.04789 , 2021
-
[43]
Deep reinforcement learning for option pricing and hedging under dynamic expectile risk measures
Saeed Marzban, Erick Delage, and Jonathan Yu-Meng Li. Deep reinforcement learning for option pricing and hedging under dynamic expectile risk measures. Quantitative Finance, 23(10):1411–1430, 2023
work page 2023
-
[44]
Charles A Micchelli, Yuesheng Xu, and Haizhang Zhang. Universal kernels. Journal of Machine Learning Research, 7(12), 2006
work page 2006
-
[45]
Robustifying conditional portfolio decisions via optimal transport
Viet Anh Nguyen, Fan Zhang, Shanshan Wang, Jos´ e Blanchet, Erick Delage, and Yinyu Ye. Robustifying conditional portfolio decisions via optimal transport. Operations Research, 2024
work page 2024
-
[46]
On convergence of kernel learning estimators
Vladimir I Norkin and Michiel A Keyzer. On convergence of kernel learning estimators. SIAM Journal on Optimization , 20(3):1205–1223, 2010
work page 2010
-
[47]
Dual stochastic dominance and related mean-risk models
WLodzimierz Ogryczak and Andrzej Ruszczynski. Dual stochastic dominance and related mean-risk models. SIAM Journal on Optimization , 13(1):60–78, 2002
work page 2002
-
[48]
Risk aversion in the small and in the large
John W Pratt. Risk aversion in the small and in the large. In Uncertainty in economics, pages 59–79. Elsevier, 1978
work page 1978
-
[49]
Integrated condi tional estimation-optimization
Meng Qi, Paul Grigas, and Zuo-Jun Max Shen. Integrated conditional estimation- optimization. arXiv preprint arXiv:2110.12351 , 2021
-
[50]
Data-driven approximation of contextual chance-constrained stochastic programs
Hamed Rahimian and Bernardo Pagnoncelli. Data-driven approximation of contextual chance-constrained stochastic programs. SIAM Journal on Optimization , 33(3):2248–2274, 2023. 32
work page 2023
-
[51]
Contextual stochastic programs with expected-value constraints
Hamed Rahimian and Bernardo Pagnoncelli. Contextual stochastic programs with expected-value constraints. Optimization Online, 2024
work page 2024
-
[52]
Generalized deviations in risk analysis
R Tyrrell Rockafellar, Stan Uryasev, and Michael Zabarankin. Generalized deviations in risk analysis. Finance and Stochastics, 10:51–74, 2006
work page 2006
-
[53]
Optimization of conditional value-at-risk
R Tyrrell Rockafellar, Stanislav Uryasev, et al. Optimization of conditional value-at-risk. Journal of risk , 2:21–42, 2000
work page 2000
-
[54]
Functional Analysis: Second Edition
Walter Rudin. Functional Analysis: Second Edition . McGraw-Hill, 1991
work page 1991
-
[55]
Optimization of convex risk functions.Math- ematics of operations research, 31(3):433–452, 2006
Andrzej Ruszczy´ nski and Alexander Shapiro. Optimization of convex risk functions.Math- ematics of operations research, 31(3):433–452, 2006
work page 2006
-
[56]
A survey of contextual optimization methods for decision-making under uncertainty
Utsav Sadana, Abhilash Chenreddy, Erick Delage, Alexandre Forel, Emma Frejinger, and Thibaut Vidal. A survey of contextual optimization methods for decision-making under uncertainty. European Journal of Operational Research, 2024
work page 2024
-
[57]
A generalized representer theorem
Bernhard Sch¨ olkopf, Ralf Herbrich, and Alex J Smola. A generalized representer theorem. In International conference on computational learning theory , pages 416–426. Springer, 2001
work page 2001
-
[58]
Regulariza- tion via mass transportation
Soroosh Shafieezadeh-Abadeh, Daniel Kuhn, and Peyman Mohajerin Esfahani. Regulariza- tion via mass transportation. Journal of Machine Learning Research , 20(103):1–68, 2019
work page 2019
-
[59]
Interchangeability principle and dynamic equations in risk averse stochastic programming
Alexander Shapiro. Interchangeability principle and dynamic equations in risk averse stochastic programming. Operations Research Letters, 45(4):377–381, 2017
work page 2017
-
[60]
Lectures on stochastic programming: Modeling and theory, 2014
Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczy´ nski. Lectures on stochastic programming: Modeling and theory, 2014
work page 2014
-
[61]
Alexander Shapiro and Huifu Xu. Stochastic mathematical programs with equilibrium constraints, modelling and sample average approximation. Optimization, 57(3):395–418, 2008
work page 2008
-
[62]
Universality, charac- teristic kernels and rkhs embedding of measures
Bharath K Sriperumbudur, Kenji Fukumizu, and Gert RG Lanckriet. Universality, charac- teristic kernels and rkhs embedding of measures. Journal of Machine Learning Research , 12(7), 2011
work page 2011
-
[63]
Prateek R Srivastava, Yijie Wang, Grani A Hanasusanto, and Chin Pang Ho. On data- driven prescriptive analytics with side information: A regularized nadaraya-watson ap- proach. arXiv preprint arXiv:2110.04855 , 2021
-
[64]
Ingo Steinwart and Christmann Andreas. Support Vector Machine . Springer, New York, 2008
work page 2008
-
[65]
Distortion riskmetrics on general spaces
Qiuqi Wang, Ruodu Wang, and Yunran Wei. Distortion riskmetrics on general spaces. ASTIN Bulletin: The Journal of the IAA , 50(3):827–851, 2020
work page 2020
-
[66]
Robust contextual portfolio opti- mization with gaussian mixture models
Yijie Wang, Grani A Hanasusanto, and Chin Pang Ho. Robust contextual portfolio opti- mization with gaussian mixture models. Optimization Online, 2022. 33
work page 2022
-
[67]
Generalization bounds for contextual stochastic optimization using kernel regression
Yijie Wang, Grani A Hanasusanto, and Chin Pang Ho. Generalization bounds for contextual stochastic optimization using kernel regression. arXiv preprint arXiv:2407.10764 , 2024
-
[68]
Optimal robust policy for feature-based newsvendor
Luhao Zhang, Jincheng Yang, and Rui Gao. Optimal robust policy for feature-based newsvendor. Management Science, 70(4):2315–2329, 2024
work page 2024
-
[69]
Statistical robustness of kernel learning estimator with respect to data perturbation
Sainan Zhang, Huifu Xu, and Hailin Sun. Statistical robustness of kernel learning estimator with respect to data perturbation. arXiv preprint arXiv:2406.10555 , 2024
-
[70]
Data-driven piecewise affine decision rules for stochastic programming with covariate information
Yiyang Zhang, Junyi Liu, and Xiaobo Zhao. Data-driven piecewise affine decision rules for stochastic programming with covariate information. arXiv preprint arXiv:2304.13646 , 2023
-
[71]
Joint estimation and robustness optimization
Taozeng Zhu, Jingui Xie, and Melvyn Sim. Joint estimation and robustness optimization. Management Science, 68(3):1659–1677, 2022. 34 A Interchangeability Principle We first restate an interchangeability principle in [28, Theorem 2.2]. Lemma A.1 Consider a real separable Banach space Z with Borel field B(Z) and a complete sample space Ω associated with sig...
work page 2022
-
[72]
extends the interchangeability principle to a Polish space. Lemma A.2 (Lemma 1 in [42]) Consider a Polish space Z with Borel field B(Z) and a prob- ability space (Ω, F , P). Let Z : Ω ⇒ Z be a F-measurable set-valued mapping with closed values. Let L be a linear space of measurable functions g : Ω → Z and LZ := {g ∈ L : g(ω) ∈ Z (ω) ⊆ Z, for a.e. ω ∈ Ω}. ...
-
[73]
+ a + b 1 − α(1 + 2β2 1 + 2|y|2) + ∥x∥2 ≥ h(z(x), s(x), y), and R X ×Y ϕ(x, y)P (dxdy) < ∞ holds for P ∈ M2 1. Consider, for another example, a newsvendor problem with entropic risk measure and h(z, s, y) = eγ(a(z−y)++b(y−z)+), (D.55) where z, y ∈ R and a, b, γ are positive constants. Then |h(z(x), s(x), y)| = eγ(a(z(x)−y)++b(y−z(x))+) ≤ eγ(a+b)|z(x)−y|. ...
-
[74]
for N ≥ N0 and R(z, s) =Pdz t=1 ∥z(t)∥2 H+ ∥s∥2 H ≤ β2 1 + β2 2, and the second inequality comes from (E.61). On the other hand, by setting 47 ϵ < δ 6, we have Prob sup k∈{1,...,K} R1(zk, sk, ϵ, P N) ≥ δ − 6ϵ ! ≤ KX k=1 Prob R1(zk, sk, ϵ, P N) ≥ δ − 6ϵ ≤ KX k=1 Prob R1(zk, sk, ϵ, P N) ≥ δ − 6ϵ + Prob R1(zk, sk, ϵ, P N) ≤ −(δ − 6ϵ) ≤ 2 KX k=1 e−N[I(δ−6ϵ,zk...
work page 2035
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.