i-WiViG: Interpretable Window Vision GNN
Pith reviewed 2026-05-23 00:31 UTC · model grok-4.3
The pith
Constraining vision GNN nodes to disjoint local windows plus a learnable sparse attention bottleneck produces semantic subgraph explanations while matching black-box accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
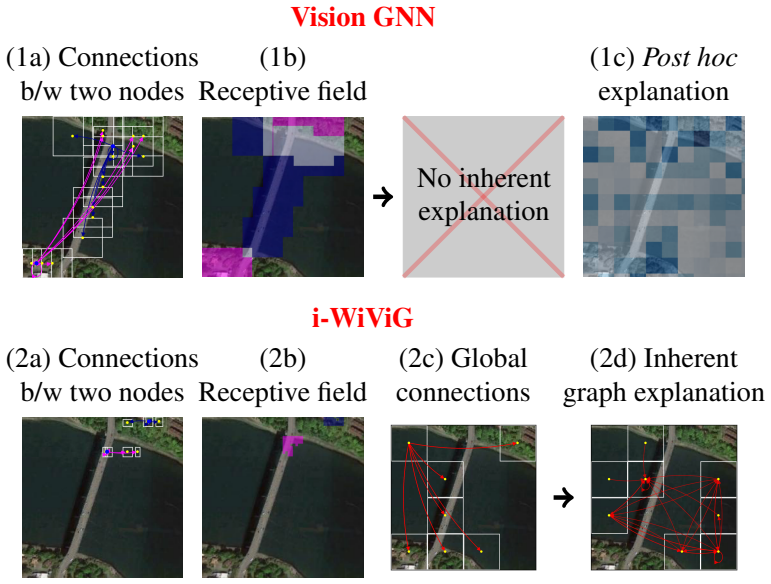
By constraining graph nodes' receptive fields to disjoint local windows and inserting an inherently interpretable graph bottleneck with learnable sparse attention, the model identifies the relevant interactions among local image windows; the identified subgraphs therefore deliver semantic, intuitive, and faithful explanations, and the overall accuracy remains competitive with black-box vision GNNs on both natural and remote-sensing imagery even under strong texture bias.
What carries the argument
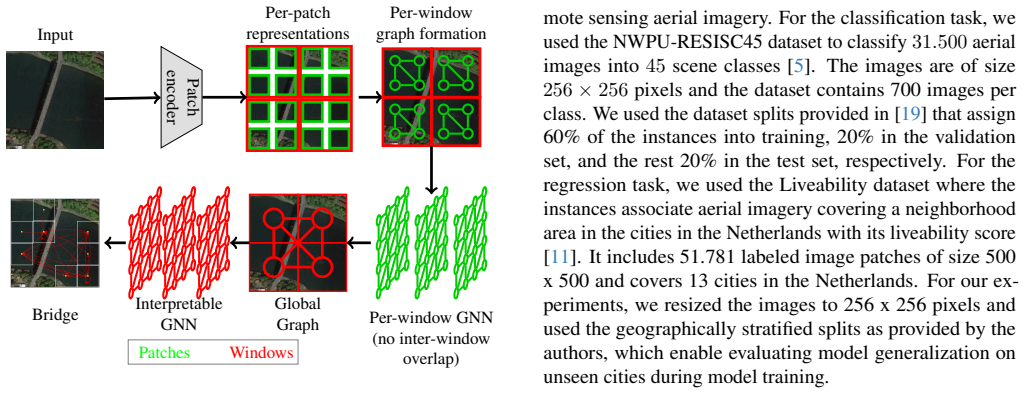
The inherently interpretable graph bottleneck with learnable sparse attention that selects relevant interactions among nodes whose receptive fields are restricted to disjoint local image windows.
If this is right
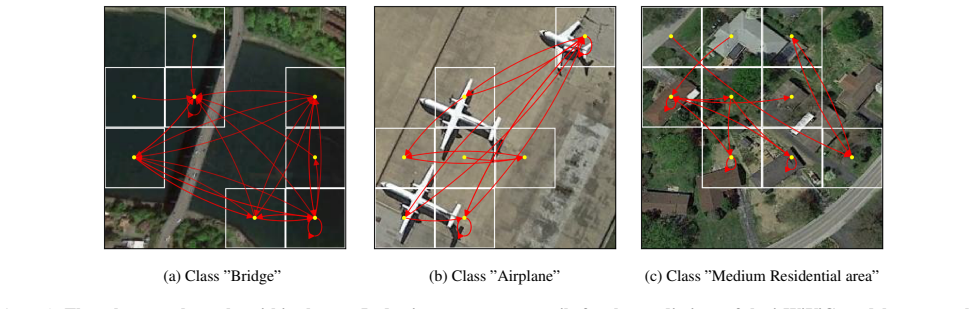
- The identified subgraphs provide semantic, intuitive, and faithful explanations of the model's reasoning.
- Accuracy remains competitive with black-box counterparts on scene classification and regression tasks.
- Performance holds on datasets that exhibit strong texture bias.
- The same architecture works for both natural imagery and remote-sensing imagery.
Where Pith is reading between the lines
- The window-plus-bottleneck design could be tested on tasks that require explicit spatial reasoning, such as object counting or layout verification.
- Because explanations are produced by the same sparse attention used for prediction, the subgraphs offer a direct route to auditing whether the model relies on expected spatial relations.
- The method's restriction to local windows suggests a natural way to compare how different window sizes affect the balance between local texture and global context in the learned explanations.
Load-bearing premise
Limiting each node's receptive field to a disjoint local window and routing interactions through a learnable sparse attention bottleneck will surface interactions that are both faithful to the model's internal computation and semantically meaningful to humans.
What would settle it
A controlled test in which the subgraphs highlighted by the bottleneck do not align with the image regions that actually drive the model's output when the same input is fed to an otherwise identical black-box GNN.
Figures

read the original abstract
Vision graph neural networks have emerged as a popular approach for modeling the global and spatial context for image recognition. However, a significant drawback of these methods is that they do not offer an inherent interpretation of the relevant spatial interactions for their prediction. We address this problem by introducing i-WiViG, an approach that enables interpretable model reasoning based on a sparse subgraph in the image. i-WiViG is based on two key postulates: 1) constraining the graph nodes' receptive field to disjoint local windows in the image, and 2) an inherently interpretable graph bottleneck with learnable sparse attention that identifies the relevant interactions among the local image windows. We evaluate our approach on both scene classification and regression tasks using natural and remote sensing imagery. Our results, supported by quantitative and qualitative evidence, demonstrate that the method delivers semantic, intuitive, and faithful explanations through the identified subgraphs. Furthermore, extensive experiments confirm that it achieves competitive performance to its black-box counterparts, even on datasets exhibiting strong texture bias. The implementation is available on https://github.com/zhu-xlab/i-WiViG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces i-WiViG, a vision GNN for image recognition that enforces interpretability via two architectural postulates: (1) restricting each node's receptive field to disjoint local windows and (2) routing interactions through a learnable sparse-attention bottleneck that extracts a sparse subgraph. The central claims are that the resulting subgraphs yield semantic, intuitive, and faithful explanations of the model's reasoning and that the model attains competitive accuracy with black-box counterparts on scene classification and regression tasks (natural and remote-sensing imagery), even under strong texture bias.
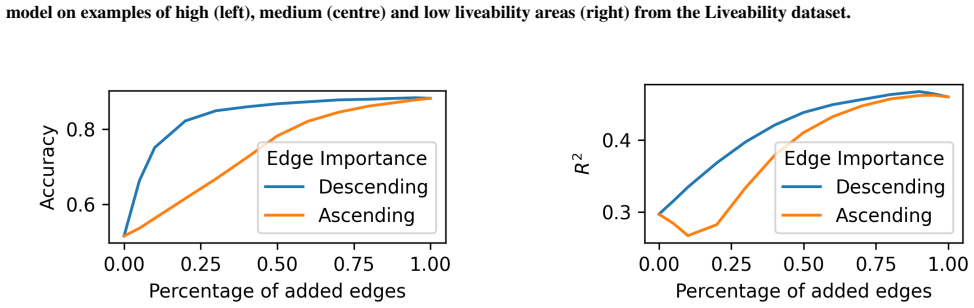
Significance. If the faithfulness claim holds, the work would supply a concrete architectural route to inherently interpretable vision GNNs without post-hoc explanation modules. The public code release is a clear strength. At present, however, the interpretability argument rests on qualitative visualizations and accuracy parity rather than quantitative faithfulness tests, so the advance over existing windowed or attention-based GNNs remains provisional.
major comments (3)
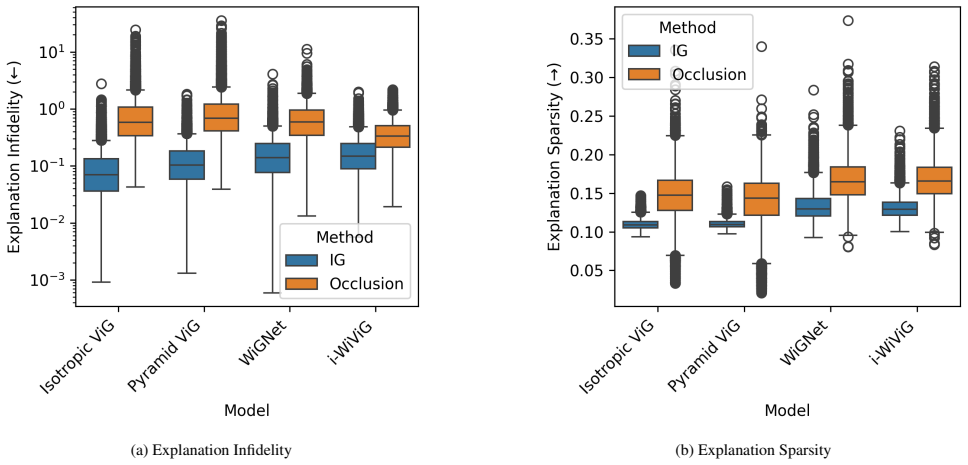
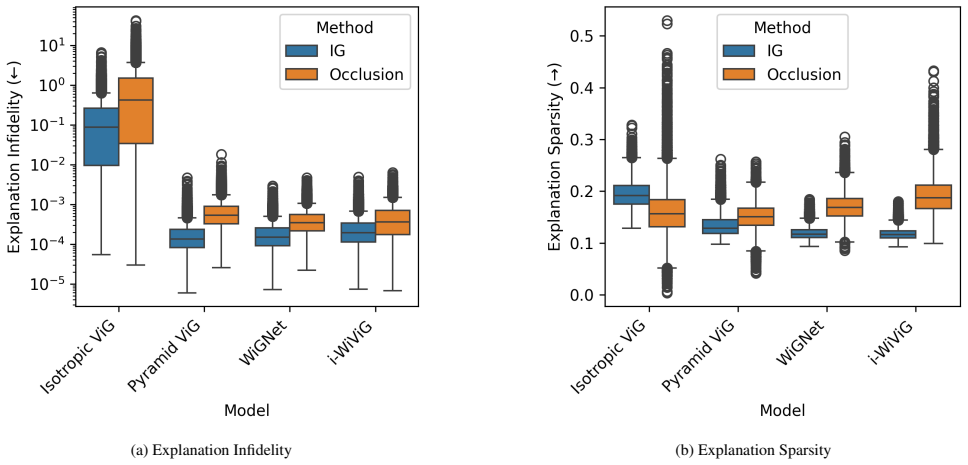
- [Abstract] Abstract: the assertion that the subgraphs are 'faithful' to the model's internal computation is not accompanied by any quantitative faithfulness metric (subgraph deletion AUC, gradient correlation, or comparison against a non-bottleneck ablation on the identical architecture). Only competitive accuracy and qualitative evidence are referenced.
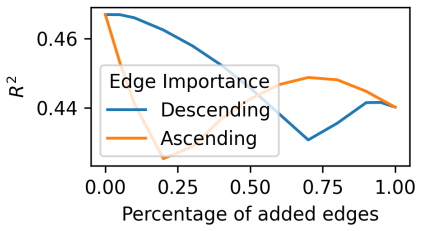
- [Abstract] Abstract (postulate 2): the claim that the learnable sparse attention bottleneck 'identifies the relevant interactions' is load-bearing for the interpretability contribution, yet no ablation is described that isolates the bottleneck's contribution to either accuracy or explanation quality versus a dense or non-learnable attention baseline.
- [Abstract] Abstract: the statement of 'quantitative and qualitative evidence' and 'extensive experiments' is unsupported by any reported error bars, dataset statistics, baseline tables, or ablation details in the provided summary, preventing verification that performance remains competitive under the stated texture-bias condition.
minor comments (2)
- [Abstract] Abstract: 'competitive performance to its black-box counterparts' should be accompanied by the specific baselines and metrics used.
- [Abstract] Abstract: the GitHub link is welcome, but the manuscript should state the exact commit or release tag used for the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the presentation of our interpretability claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the subgraphs are 'faithful' to the model's internal computation is not accompanied by any quantitative faithfulness metric (subgraph deletion AUC, gradient correlation, or comparison against a non-bottleneck ablation on the identical architecture). Only competitive accuracy and qualitative evidence are referenced.
Authors: The faithfulness claim follows directly from the architecture: the sparse attention bottleneck is the sole pathway from input windows to the classifier, so the extracted subgraph is the model's computation by design (unlike post-hoc methods). The manuscript supports this with qualitative semantic analysis. We will revise the abstract to qualify the claim as 'architecturally faithful' and reference the relevant sections, without adding new quantitative experiments at this stage. revision: partial
-
Referee: [Abstract] Abstract (postulate 2): the claim that the learnable sparse attention bottleneck 'identifies the relevant interactions' is load-bearing for the interpretability contribution, yet no ablation is described that isolates the bottleneck's contribution to either accuracy or explanation quality versus a dense or non-learnable attention baseline.
Authors: Ablation studies isolating the learnable sparse attention (versus dense and non-learnable baselines) appear in the experiments section and demonstrate its impact on both accuracy and subgraph quality. The abstract condenses these results. We will update the abstract to explicitly reference the ablation studies supporting postulate 2. revision: yes
-
Referee: [Abstract] Abstract: the statement of 'quantitative and qualitative evidence' and 'extensive experiments' is unsupported by any reported error bars, dataset statistics, baseline tables, or ablation details in the provided summary, preventing verification that performance remains competitive under the stated texture-bias condition.
Authors: The abstract is a concise overview; the full manuscript contains the requested tables (with error bars), dataset statistics, baselines, and texture-bias ablations. We will revise the abstract to more precisely describe the evidence types presented in the paper. revision: yes
Circularity Check
No circularity; architecture and claims are self-contained
full rationale
The paper defines i-WiViG via two explicit architectural postulates (disjoint windows + sparse attention bottleneck) that are design choices, not derived quantities. Performance is shown via direct empirical comparison to black-box baselines on multiple datasets; explanations rest on qualitative subgraph visualizations rather than any equation that reduces a result to a fitted parameter defined in terms of itself. No self-citation chain, uniqueness theorem, or ansatz smuggling is used to justify the central claims. The derivation chain consists of standard GNN operations plus the stated constraints, with no step that is equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Constraining the graph nodes' receptive field to disjoint local windows preserves the spatial interactions needed for accurate prediction.
- domain assumption An inherently interpretable graph bottleneck with learnable sparse attention identifies the relevant interactions among the local image windows.
Reference graph
Works this paper leans on
-
[1]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfel- low, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. Advances in neural information processing systems, 31, 2018. 1, 3
work page 2018
-
[2]
Approximating cnns with bag-of-local-features models works surprisingly well on imagenet
Wieland Brendel and Matthias Bethge. Approximating cnns with bag-of-local-features models works surprisingly well on imagenet. International Conference on Learning Representa- tions, 2019. 5
work page 2019
-
[3]
Hierarchical gnn framework for earth’s surface anomaly detection in single satellite im- agery
Boan Chen, Zhi Gao, Ziyao Li, Siqi Liu, Aohan Hu, Weiwei Song, Yu Zhang, and Qiao Wang. Hierarchical gnn framework for earth’s surface anomaly detection in single satellite im- agery. IEEE Transactions on Geoscience and Remote Sensing,
-
[4]
Yongqiang Chen, Yatao Bian, Bo Han, and James Cheng. How interpretable are interpretable graph neural networks? In Forty-first International Conference on Machine Learning,
-
[5]
Remote sensing image scene classification: Benchmark and state of the art
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art. Proceedings of the IEEE, 105(10):1865–1883, 2017. 5
work page 2017
-
[6]
Pruning deep neural networks from a sparsity perspective
Enmao Diao, Ganghua Wang, Jiawei Zhan, Yuhong Yang, Jie Ding, and Vahid Tarokh. Pruning deep neural networks from a sparsity perspective. arXiv preprint arXiv:2302.05601,
-
[7]
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. InInternational Conference on Learning Representations, 2018. 1
work page 2018
-
[8]
Vision gnn: An image is worth graph of nodes
Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang, and En- hua Wu. Vision gnn: An image is worth graph of nodes. Advances in neural information processing systems, 35:8291– 8303, 2022. 1, 2, 3, 4, 5
work page 2022
-
[9]
Vision hgnn: An image is more than a graph of nodes
Yan Han, Peihao Wang, Souvik Kundu, Ying Ding, and Zhangyang Wang. Vision hgnn: An image is more than a graph of nodes. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 19878–19888,
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4, 5
work page 2016
-
[11]
Predicting the liveability of dutch cities with aerial images and semantic intermediate concepts
Alex Levering, Diego Marcos, Jasper van Vliet, and Devis Tuia. Predicting the liveability of dutch cities with aerial images and semantic intermediate concepts. Remote Sensing of Environment, 287:113454, 2023. 5
work page 2023
-
[12]
Guohao Li, Matthias Muller, Ali Thabet, and Bernard Ghanem. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF international conference on computer vision, pages 9267–9276, 2019. 1
work page 2019
-
[13]
Orphicx: A causality-inspired latent variable model for interpreting graph neural networks
Wanyu Lin, Hao Lan, Hao Wang, and Baochun Li. Orphicx: A causality-inspired latent variable model for interpreting graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13729–13738, 2022. 3
work page 2022
-
[14]
Qinghui Liu, Michael Kampffmeyer, Robert Jenssen, and Arnt-Børre Salberg. Self-constructing graph neural networks to model long-range pixel dependencies for semantic segmen- tation of remote sensing images. International Journal of Remote Sensing, 42(16):6184–6208, 2021. 1
work page 2021
-
[15]
Interpretable and generaliz- able graph learning via stochastic attention mechanism
Siqi Miao, Mia Liu, and Pan Li. Interpretable and generaliz- able graph learning via stochastic attention mechanism. In International Conference on Machine Learning, pages 15524– 15543. PMLR, 2022. 1, 3, 4
work page 2022
-
[16]
Mo- bilevig: Graph-based sparse attention for mobile vision ap- plications
Mustafa Munir, William Avery, and Radu Marculescu. Mo- bilevig: Graph-based sparse attention for mobile vision ap- plications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2211–2219,
-
[17]
Greedyvig: Dynamic axial graph construc- tion for efficient vision gnns
Mustafa Munir, William Avery, Md Mostafijur Rahman, and Radu Marculescu. Greedyvig: Dynamic axial graph construc- tion for efficient vision gnns. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 6118–6127, 2024. 1, 2, 3
work page 2024
-
[18]
Meike Nauta, Jan Trienes, Shreyasi Pathak, Elisa Nguyen, Michelle Peters, Yasmin Schmitt, J¨org Schl¨otterer, Maurice Van Keulen, and Christin Seifert. From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable ai. ACM Computing Surveys, 55(13s): 1–42, 2023. 7
work page 2023
-
[19]
In-domain representation learning for remote sensing
Maxim Neumann, Andre Susano Pinto, Xiaohua Zhai, and Neil Houlsby. In-domain representation learning for remote sensing. arXiv preprint arXiv:1911.06721, 2019. 5
-
[20]
Rise: Random- ized input sampling for explanation of black-box models
Vitali Petsiuk, Abir Das, and Kate Saenko. Rise: Random- ized input sampling for explanation of black-box models. In British Machine Vision Conference (BMVC), 2018. 6
work page 2018
-
[21]
Dy- namic routing between capsules
Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. Dy- namic routing between capsules. Advances in neural infor- mation processing systems, 30, 2017. 1
work page 2017
-
[22]
Augment to interpret: Unsupervised and inher- ently interpretable graph embeddings
Gregory Scafarto, Madalina Ciortan, Simon Tihon, and Quentin Ferre. Augment to interpret: Unsupervised and inher- ently interpretable graph embeddings. In Asian Conference on Machine Learning, pages 1183–1198. PMLR, 2024. 3
work page 2024
-
[23]
Graph infor- mation bottleneck for remote sensing segmentation
Yuntao Shou, Wei Ai, Tao Meng, and Nan Yin. Graph infor- mation bottleneck for remote sensing segmentation. arXiv preprint arXiv:2312.02545, 2023. 1
-
[24]
Xinyang Song, Zhen Hua, and Jinjiang Li. Context spatial awareness remote sensing image change detection network based on graph and convolution interaction. IEEE Transac- tions on Geoscience and Remote Sensing, 2024. 1
work page 2024
-
[25]
Wignet: Windowed vision 9 graph neural network
Gabriele Spadaro, Marco Grangetto, Attilio Fiandrotti, Enzo Tartaglione, and Jhony H Giraldo. Wignet: Windowed vision 9 graph neural network. arXiv preprint arXiv:2410.00807, 2024. 1, 2, 3, 4, 5
-
[26]
Fishnet: A versatile backbone for image, region, and pixel level prediction
Shuyang Sun, Jiangmiao Pang, Jianping Shi, Shuai Yi, and Wanli Ouyang. Fishnet: A versatile backbone for image, region, and pixel level prediction. Advances in neural infor- mation processing systems, 31, 2018. 5
work page 2018
-
[27]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International conference on machine learning, pages 3319–3328. PMLR, 2017. 6
work page 2017
-
[28]
Tailin Wu, Hongyu Ren, Pan Li, and Jure Leskovec. Graph information bottleneck. Advances in Neural Information Processing Systems, 33:20437–20448, 2020. 4
work page 2020
-
[29]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018. 1
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
On the (in) fidelity and sensitivity of explanations
Chih-Kuan Yeh, Cheng-Yu Hsieh, Arun Suggala, David I Inouye, and Pradeep K Ravikumar. On the (in) fidelity and sensitivity of explanations. Advances in neural information processing systems, 32, 2019. 6
work page 2019
-
[31]
Gnnexplainer: Generating explanations for graph neural networks
Zhitao Ying, Dylan Bourgeois, Jiaxuan You, Marinka Zitnik, and Jure Leskovec. Gnnexplainer: Generating explanations for graph neural networks. Advances in neural information processing systems, 32, 2019. 1, 3
work page 2019
-
[32]
Crossed siamese vision graph neural network for remote sensing image change detection
Zhi-Hui You, Jia-Xin Wang, Si-Bao Chen, Chris HQ Ding, Gui-Zhou Wang, Jin Tang, and Bin Luo. Crossed siamese vision graph neural network for remote sensing image change detection. IEEE Transactions on Geoscience and Remote Sensing, 2023. 1
work page 2023
-
[33]
Xgnn: To- wards model-level explanations of graph neural networks
Hao Yuan, Jiliang Tang, Xia Hu, and Shuiwang Ji. Xgnn: To- wards model-level explanations of graph neural networks. In Proceedings of the 26th ACM SIGKDD international confer- ence on knowledge discovery & data mining, pages 430–438,
-
[34]
Ex- plainability in graph neural networks: A taxonomic survey
Hao Yuan, Haiyang Yu, Shurui Gui, and Shuiwang Ji. Ex- plainability in graph neural networks: A taxonomic survey. IEEE transactions on pattern analysis and machine intelli- gence, 45(5):5782–5799, 2022. 3
work page 2022
-
[35]
Cutmix: Regu- larization strategy to train strong classifiers with localizable features
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regu- larization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF international con- ference on computer vision, pages 6023–6032, 2019. 1
work page 2019
-
[36]
Hcgnet: A hy- brid change detection network based on cnn and gnn
Cui Zhang, Liejun Wang, and Shuli Cheng. Hcgnet: A hy- brid change detection network based on cnn and gnn. IEEE Transactions on Geoscience and Remote Sensing, 2024. 1
work page 2024
-
[37]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017. 1 10 i-WiViG: Interpretable Window Vision GNN Supplementary Material A. i-WiViG Architecture Table 4 presents in detail the layer composition and the hy- perparameters used in our proposed i-WiViG model. Similar to the WiGNet and the pyramid ViG models, we perf...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Further, to obtain an inherently interpretable model that reveals the relevant subgraph for its prediction, we insert the GSAT graph in the final stage before the prediction head to learn the global long-range relations between the windows in the image by ranking the importance of the edges in the graph. Similar to the standard grapher layers in the ViG m...
-
[39]
Linear transformation of the node embeddings
-
[40]
GIN graph convolution
-
[41]
FFN layer processing Finally, the GSAT block is followed by a prediction head consisting of pooling and MLP layers, as illustrated in Table 4. B. i-WiViG Training Procedure For model training, we performed image transformations in the following order:
-
[42]
Resizing the images to a size of 256 x 256
-
[43]
Regarding the benchmark ViG models, we used the default hyperparameter setting of the tiny versions
Min-max image normalization Further, for the scene classification task, we have used the Cutmix [35] and Mixup [37] augmentations during training. Regarding the benchmark ViG models, we used the default hyperparameter setting of the tiny versions. For our i-WiViG model, we used the hyperparameters of the WiGNet grapher blocks illustrated in Table 4 settin...
-
[44]
for graph processing. Stage Output Size Hyperparameters Stem H 4 × W 4 Conv ×2 Stage 1 WiGNet block H 4 × W 4 D = 48 E = 4 k = 9 W = 4 × 2 Downsample H 8 × W 8 Conv ×2 Stage 2 WiGNet block H 8 × W 8 D = 96 E = 4 k = 9 W = 4 × 2 Downsample H 16 × W 16 Conv ×2 Stage 3 WiGNet block H 16 × W 16 D = 240 E = 4 k = 9 W = 4 × 4 Downs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.