The LZ78 Source
Pith reviewed 2026-05-23 00:03 UTC · model grok-4.3
The pith
Processes generated by LZ78 sequential probability assignments are almost stationary and ergodic yet have finite-state compressibility strictly larger than their entropy rate by a Jensen gap almost surely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We study a family of processes generated according to sequential probability assignments induced by the LZ78 universal compressor. Though not quite stationary, these sources are almost stationary and ergodic; similar to stationary and ergodic processes, they satisfy a Shannon-McMillan-Breiman-type property: the normalized log probability of their realizations converges almost surely to their entropy rate. Further, they are locally almost i.i.d. in the sense that the finite-dimensional empirical distributions of their realizations converge almost surely to a deterministic i.i.d. law. However, unlike stationary ergodic sources, the finite-state compressibility of their realizations is almost-s
What carries the argument
The LZ78 source defined by sequential probability assignments induced by the LZ78 universal compressor, which produces the almost-stationary processes with the stated convergence properties and Jensen gap.
If this is right
- These sources satisfy a Shannon-McMillan-Breiman-type property almost surely.
- Finite-dimensional empirical distributions of realizations converge almost surely to a deterministic i.i.d. law.
- Finite-state compressibility of realizations exceeds entropy rate by a positive Jensen gap almost surely.
- The sources can gauge performance of sequential probability models on non-Markovian non-stationary data.
- Realizations of the source can be applied to study in-context learning in transformer models.
Where Pith is reading between the lines
- The Jensen gap may serve as a concrete quantitative signature of the non-stationarity induced by the LZ78 assignments.
- These sources could benchmark whether model improvements come from handling non-stationarity specifically rather than other data features.
- Similar gaps might appear when other universal compressors define induced processes, offering a way to compare compressor families.
- The construction could extend to controlled experiments on how much non-stationarity affects in-context learning accuracy in transformers.
Load-bearing premise
The sequential probability assignments induced by the LZ78 compressor generate processes whose realizations satisfy the almost-sure convergence to an entropy rate, convergence of empirical distributions to a fixed i.i.d. law, and a strict positive Jensen gap between finite-state compressibility and entropy rate.
What would settle it
Generating long realizations from the LZ78 source and computing the limit of (finite-state compressibility minus entropy rate); if this limit equals zero with positive probability, the strict gap claim is false.
Figures














read the original abstract
We study a family of processes generated according to sequential probability assignments induced by the LZ78 universal compressor. We characterize entropic and distributional properties such as their entropy and relative entropy rates, finite-state compressibility and log loss of their realizations, and the empirical distributions that they induce. Though not quite stationary, these sources are "almost stationary and ergodic;" similar to stationary and ergodic processes, they satisfy a Shannon-McMillan-Breiman-type property: the normalized log probability of their realizations converges almost surely to their entropy rate. Further, they are locally "almost i.i.d." in the sense that the finite-dimensional empirical distributions of their realizations converge almost surely to a deterministic i.i.d. law. However, unlike stationary ergodic sources, the finite-state compressibility of their realizations is almost surely strictly larger than their entropy rate by a "Jensen gap". We present simulations demonstrating the theoretical results. These sources allow to gauge the performance of sequential probability models, both classical and deep learning-based, on non-Markovian non-stationary data. As such, we apply realizations of the LZ78 source to the study of in-context learning in transformer models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines a family of processes (the LZ78 source) via the sequential probability assignments induced by the LZ78 universal compressor. It characterizes their entropy and relative-entropy rates, finite-state compressibility, log loss, and induced empirical distributions. The central claims are that these processes are almost stationary and ergodic, satisfy an almost-sure Shannon-McMillan-Breiman property (normalized log-probability converges to the entropy rate), have finite-dimensional empirical distributions converging almost surely to a deterministic i.i.d. law, and exhibit a strict positive Jensen gap between finite-state compressibility and entropy rate; simulations and an application to transformer in-context learning are also presented.
Significance. If the derivations hold, the work supplies an explicitly constructible family of non-stationary sources whose properties can be used to benchmark both classical and neural sequential probability models. The martingale argument for the SMB convergence and the explicit computation of the limiting empirical measure (yielding the gap via strict concavity of the logarithm) are concrete strengths that make the results falsifiable and reproducible.
minor comments (2)
- [Abstract] Abstract, paragraph 2: the phrase 'Jensen gap' is used before any definition or reference to the concavity argument; a parenthetical gloss would improve readability for readers outside information theory.
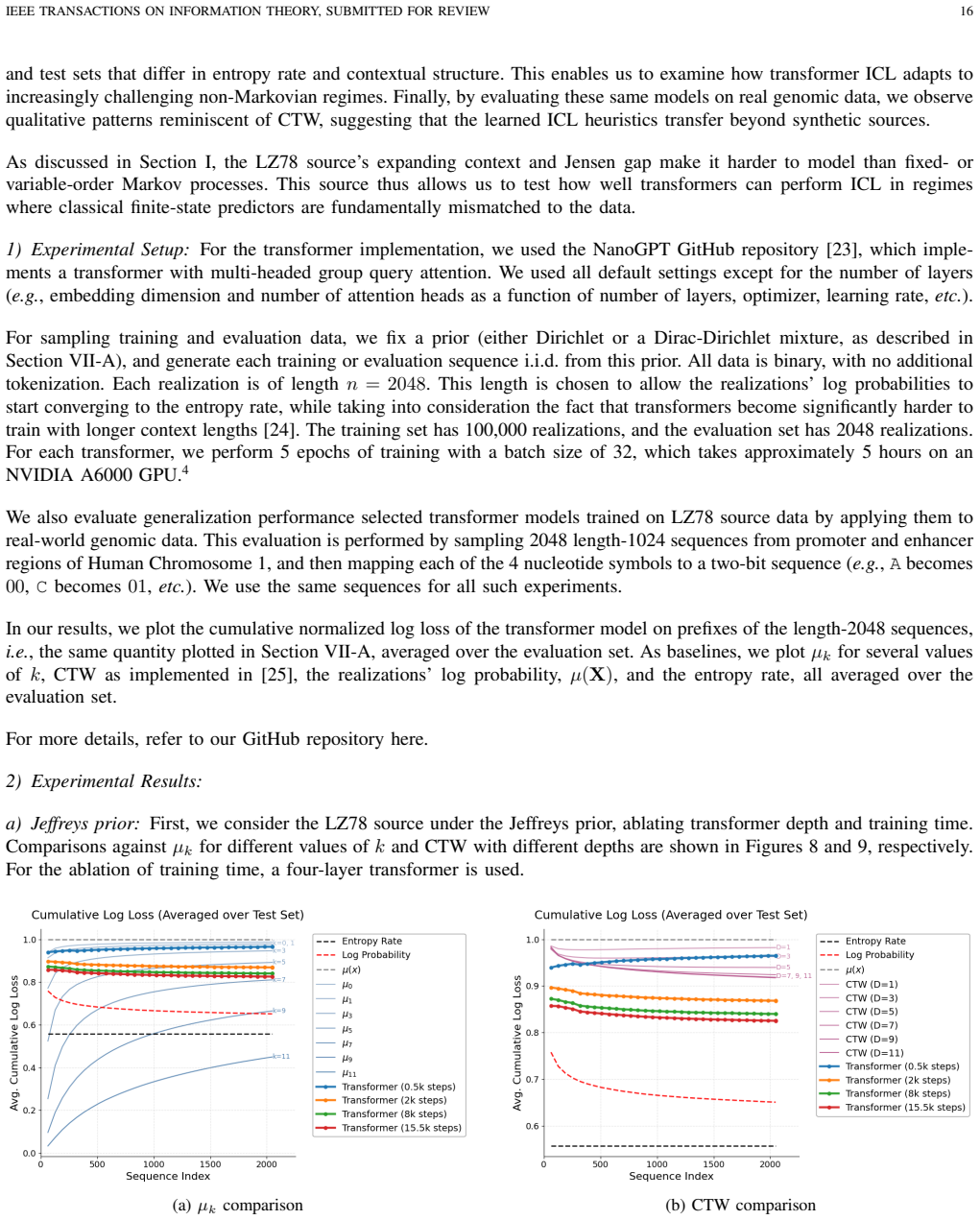
- [Simulations] The simulation section should state the alphabet size, the number of independent realizations, and the precise stopping criterion for the LZ78 parsing to allow exact reproduction of the reported convergence plots.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper explicitly defines the LZ78 source via recursive sequential probability assignments induced by the LZ78 compressor, then derives the SMB-type convergence, empirical measure convergence to a deterministic i.i.d. law, and the strict Jensen gap using martingale arguments and strict concavity of the logarithm. These steps rely on standard probabilistic tools and direct computation from the given recursive definitions rather than any reduction to fitted parameters, self-citations, or imported uniqueness results. The central claims therefore remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard results from ergodic theory and information theory that guarantee existence of entropy rates and almost-sure convergence statements of the Shannon-McMillan-Breiman type.
Reference graph
Works this paper leans on
-
[1]
Compression of individual sequences via variable-rate coding,
J. Ziv and A. Lempel, “Compression of individual sequences via variable-rate coding,”IEEE Transactions on Information Theory, vol. 24, no. 5, pp. 530–536, 1978
work page 1978
-
[2]
Gambling using a finite state machine,
M. Feder, “Gambling using a finite state machine,”IEEE Transactions on Information Theory, vol. 37, no. 5, pp. 1459–1465, 1991
work page 1991
-
[3]
Universal prediction of individual sequences,
M. Feder, N. Merhav, and M. Gutman, “Universal prediction of individual sequences,”IEEE Transactions on Information Theory, vol. 38, no. 4, pp. 1258–1270, 1992
work page 1992
-
[4]
Universal decoding for finite-state channels,
J. Ziv, “Universal decoding for finite-state channels,”IEEE Transactions on Information Theory, vol. 31, no. 4, pp. 453–460, 1985
work page 1985
-
[5]
Universal filtering via prediction,
T. Weissman, E. Ordentlich, M. J. Weinberger, A. Somekh-Baruch, and N. Merhav, “Universal filtering via prediction,”IEEE Transactions on Information Theory, vol. 53, no. 4, pp. 1253–1264, 2007
work page 2007
-
[6]
A family of LZ78-based universal sequential probability assignments,
N. Sagan and T. Weissman, “A family of LZ78-based universal sequential probability assignments,” 2024. [Online]. Available: https://arxiv.org/abs/2410.06589
-
[7]
On Jacob Ziv’s individual-sequence approach to information theory,
N. Merhav, “On Jacob Ziv’s individual-sequence approach to information theory,” 2024. [Online]. Available: https://arxiv.org/abs/2406.02904
-
[8]
A universal random coding ensemble for sample-wise lossy compression,
——, “A universal random coding ensemble for sample-wise lossy compression,” 2022. [Online]. Available: https://arxiv.org/abs/2212.12208
-
[9]
The empirical distribution of good codes,
S. S. (Shitz) and S. Verd ´u, “The empirical distribution of good codes,”IEEE Transactions on Information Theory, vol. 43, no. 3, pp. 836–846, May 1997
work page 1997
-
[10]
The empirical distribution of rate-constrained source codes,
T. Weissman and E. Ordentlich, “The empirical distribution of rate-constrained source codes,”IEEE Transactions on Information Theory, vol. 51, no. 11, pp. 3718–3733, Nov. 2005, conference Name: IEEE Transactions on Information Theory. [Online]. Available: https://ieeexplore.ieee.org/document/1522635/
-
[11]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” 2023. [Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
The context-tree weighting method: basic properties,
F. Willems, Y . Shtarkov, and T. Tjalkens, “The context-tree weighting method: basic properties,”IEEE Transactions on Information Theory, vol. 41, no. 3, pp. 653–664, 1995
work page 1995
-
[13]
The evolution of statistical induction heads: In-context learning markov chains,
B. L. Edelman, E. Edelman, S. Goel, E. Malach, and N. Tsilivis, “The evolution of statistical induction heads: In-context learning markov chains,”
-
[14]
Available: https://arxiv.org/abs/2402.11004
[Online]. Available: https://arxiv.org/abs/2402.11004
-
[15]
Attention with markov: A framework for principled analysis of transformers via markov chains,
A. V . Makkuva, M. Bondaschi, A. Girish, A. Nagle, M. Jaggi, H. Kim, and M. Gastpar, “Attention with markov: A framework for principled analysis of transformers via markov chains,” 2025. [Online]. Available: https://arxiv.org/abs/2402.04161
-
[16]
In-context learning and induction heads,
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y . Bai, A. Chen, T. Conerly, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, S. Johnston, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah, “In-context learning and induction heads,”Transformer C...
work page 2022
-
[17]
Transformers on markov data: Constant depth suffices,
N. Rajaraman, M. Bondaschi, K. Ramchandran, M. Gastpar, and A. V . Makkuva, “Transformers on markov data: Constant depth suffices,” 2024. [Online]. Available: https://arxiv.org/abs/2407.17686
-
[18]
Transformers learn variable-order markov chains in-context,
R. Zhou, C. Tian, and S. Diggavi, “Transformers learn variable-order markov chains in-context,” 2024. [Online]. Available: https: //arxiv.org/abs/2410.05493
-
[19]
I. Csisz ´ar and J. K ¨orner,Information Theory: Coding Theorems for Discrete Memoryless Systems, 2nd ed. Cambridge University Press, 2011
work page 2011
-
[20]
Y . Ephraim and N. Merhav, “Hidden Markov processes,”IEEE Transactions on Information Theory, vol. 48, no. 6, pp. 1518–1569, 2002
work page 2002
-
[21]
The individual ergodic theorem of information theory,
L. Breiman, “The individual ergodic theorem of information theory,”The Annals of Mathematical Statistics, vol. 28, no. 3, pp. 809 – 811, 1957. [Online]. Available: https://doi.org/10.1214/aoms/1177706899
-
[22]
Admissibility properties or Gilbert’s encoding for unknown source probabilities (corresp.),
T. Cover, “Admissibility properties or Gilbert’s encoding for unknown source probabilities (corresp.),”IEEE Transactions on Information Theory, vol. 18, no. 1, pp. 216–217, 1972
work page 1972
-
[23]
The performance of universal encoding,
R. Krichevsky and V . Trofimov, “The performance of universal encoding,”IEEE Transactions on Information Theory, vol. 27, no. 2, pp. 199–207, 1981
work page 1981
- [24]
-
[25]
Explaining context length scaling and bounds for language models,
J. Shi, Q. Ma, H. Liu, H. Zhao, J.-N. Hwang, and L. Li, “Explaining context length scaling and bounds for language models,” 2025. [Online]. Available: https://arxiv.org/abs/2502.01481
-
[26]
Universal estimation of directed information,
J. Jiao, H. H. Permuter, L. Zhao, Y .-H. Kim, and T. Weissman, “Universal estimation of directed information,”IEEE Transactions on Information Theory, vol. 59, no. 10, p. 6220–6242, Oct. 2013. [Online]. Available: http://dx.doi.org/10.1109/TIT.2013.2267934
-
[27]
On the notion of recurrence in discrete stochastic processes,
M. Kac, “On the notion of recurrence in discrete stochastic processes,”Bulletin of the American Mathematical Society, vol. 53, pp. 1002–1010, 1947
work page 1947
-
[28]
The asymptotics of waiting times between stationary processes, allowing distortion,
A. Dembo and I. Kontoyiannis, “The asymptotics of waiting times between stationary processes, allowing distortion,”The Annals of Applied Probability, vol. 9, no. 2, pp. 413–429, 1999. [Online]. Available: http://www.jstor.org/stable/2667339
-
[29]
Estimation of entropy and mutual information,
L. Paninski, “Estimation of entropy and mutual information,”Neural Computation, vol. 15, no. 6, pp. 1191–1253, 06 2003. [Online]. Available: https://doi.org/10.1162/089976603321780272
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.