Toward General and Robust LLM-enhanced Text-attributed Graph Learning
Pith reviewed 2026-05-22 21:23 UTC · model grok-4.3
The pith
UltraTAG unifies LLM and GNN methods for text-attributed graphs while its robust version UltraTAG-S uses text propagation, augmentation, PageRank selection, and edge reconfiguration to cut sparsity losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
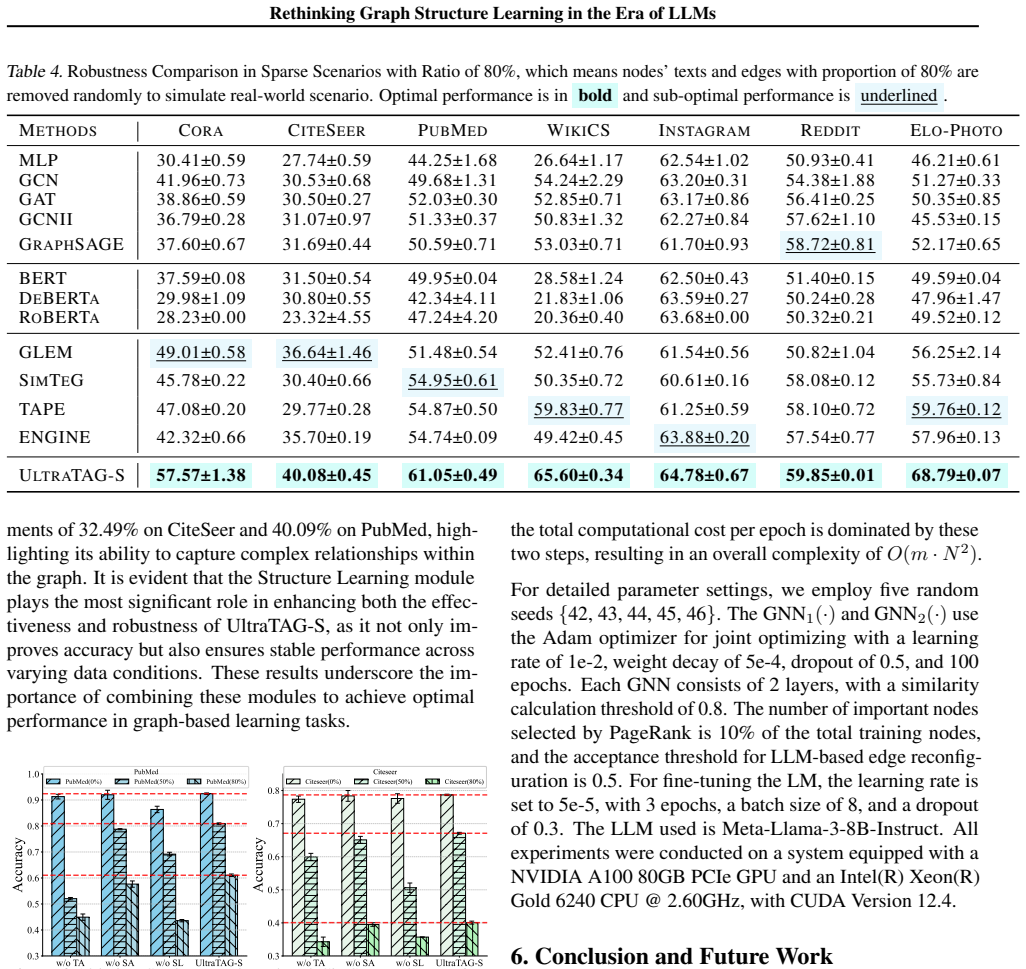
UltraTAG supplies a unified comprehensive domain-adaptive framework that systematizes LLM-enhanced TAG learning and organizes prior methods. UltraTAG-S instantiates the framework by applying LLM-based text propagation and text augmentation against text sparsity together with LLM-augmented PageRank node selection and edge reconfiguration against edge sparsity, delivering 2.12 percent and 17.47 percent gains over baselines in ideal and sparse regimes respectively.
What carries the argument
The UltraTAG pipeline that organizes LLM-GNN interactions for TAGs, instantiated in UltraTAG-S through LLM text propagation, text augmentation, PageRank-based node selection, and edge reconfiguration to mitigate sparsity.
If this is right
- TAG learning becomes feasible on the incomplete graphs common in practice rather than only on clean benchmark data.
- Performance margins widen rather than shrink as the fraction of missing text and edges grows.
- Existing LLM-GNN combinations can be placed inside one shared structure instead of remaining scattered.
- New domain-specific variants can be added to the same pipeline without redesigning the overall flow.
Where Pith is reading between the lines
- The same propagation-plus-reconfiguration steps could be tried on graphs that carry images or other modalities in addition to text.
- Scaling the method to graphs with millions of nodes would test whether the LLM calls remain practical.
- The observed robustness to increasing sparsity suggests the method may also help when graphs change over time rather than stay static.
Load-bearing premise
LLM-generated text, node selections, and edge changes reliably reduce sparsity without adding hallucinations or domain-specific biases that cancel the reported gains.
What would settle it
Running UltraTAG-S on a real sparse TAG dataset and observing either no accuracy lift over strong baselines or a measurable rise in biased or hallucinated predictions.
Figures





read the original abstract
Recent advancements in Large Language Models (LLMs) and the proliferation of Text-Attributed Graphs (TAGs) across various domains have positioned LLM-enhanced TAG learning as a critical research area. By utilizing rich graph descriptions, this paradigm leverages LLMs to generate high-quality embeddings, thereby enhancing the representational capacity of Graph Neural Networks (GNNs). However, the field faces significant challenges: (1) the absence of a unified framework to systematize the diverse optimization perspectives arising from the complex interactions between LLMs and GNNs, and (2) the lack of a robust method capable of handling real-world TAGs, which often suffer from texts and edge sparsity, leading to suboptimal performance. To address these challenges, we propose UltraTAG, a unified pipeline for LLM-enhanced TAG learning. UltraTAG provides a unified comprehensive and domain-adaptive framework that not only organizes existing methodologies but also paves the way for future advancements in the field. Building on this framework, we propose UltraTAG-S, a robust instantiation of UltraTAG designed to tackle the inherent sparsity issues in real-world TAGs. UltraTAG-S employs LLM-based text propagation and text augmentation to mitigate text sparsity, while leveraging LLM-augmented node selection techniques based on PageRank and edge reconfiguration strategies to address edge sparsity. Our extensive experiments demonstrate that UltraTAG-S significantly outperforms existing baselines, achieving improvements of 2.12\% and 17.47\% in ideal and sparse settings, respectively. Moreover, as the data sparsity ratio increases, the performance improvement of UltraTAG-S also rises, which underscores the effectiveness and robustness of UltraTAG-S.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UltraTAG, a unified comprehensive and domain-adaptive framework for LLM-enhanced text-attributed graph (TAG) learning that organizes existing methodologies, and UltraTAG-S, a robust instantiation addressing text and edge sparsity in real-world TAGs via LLM-based text propagation and augmentation, PageRank-based node selection, and edge reconfiguration strategies. Experiments are reported to show UltraTAG-S outperforming baselines by 2.12% in ideal settings and 17.47% in sparse settings, with gains increasing as the sparsity ratio rises.
Significance. If the empirical claims are substantiated, the unified framework could help systematize diverse LLM-GNN optimization perspectives in TAG learning, while UltraTAG-S could provide a practical method for improving performance and robustness under sparsity, a common issue in real-world TAG applications.
major comments (2)
- [Abstract] Abstract: The central performance claims of 2.12% and 17.47% improvements (and the increasing-gains-with-sparsity observation) are stated without any information on datasets, baselines, statistical tests, ablation studies, or controls for LLM output variability, leaving the robustness claim without verifiable support.
- [Abstract] Abstract: The robustness narrative in sparse regimes rests on the unverified assumption that LLM-based text propagation, augmentation, PageRank node selection, and edge reconfiguration mitigate sparsity without net negative effects from hallucinations or domain biases; no fidelity metrics, human validation of augmented content, or generation-quality ablations are described to support this load-bearing assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while making revisions where the comments identify clear gaps in the abstract or supporting discussion.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims of 2.12% and 17.47% improvements (and the increasing-gains-with-sparsity observation) are stated without any information on datasets, baselines, statistical tests, ablation studies, or controls for LLM output variability, leaving the robustness claim without verifiable support.
Authors: The abstract is intentionally concise as a high-level summary. All requested details—datasets (Cora, CiteSeer, PubMed, and others), baselines (including GNN and LLM-GNN methods), statistical reporting (means and standard deviations over multiple runs), ablation studies, and controls for LLM variability—are fully provided in Sections 4 and 5 of the manuscript. To improve verifiability at the abstract level, we have revised the abstract to briefly note the evaluation on standard TAG benchmarks with results averaged over runs. revision: yes
-
Referee: [Abstract] Abstract: The robustness narrative in sparse regimes rests on the unverified assumption that LLM-based text propagation, augmentation, PageRank node selection, and edge reconfiguration mitigate sparsity without net negative effects from hallucinations or domain biases; no fidelity metrics, human validation of augmented content, or generation-quality ablations are described to support this load-bearing assumption.
Authors: The increasing performance gains as sparsity rises provide direct empirical support that the net effect is positive. We acknowledge that dedicated fidelity metrics and human validation of LLM outputs are not present in the original submission. We have added a qualitative analysis subsection and discussion of potential hallucination risks in the revised experiments section, but comprehensive quantitative fidelity ablations would require new experiments beyond the current scope. revision: partial
Circularity Check
No circularity: empirical framework with experimental validation
full rationale
The paper proposes UltraTAG as a unified pipeline and UltraTAG-S as a sparsity-handling instantiation, with all central claims resting on experimental comparisons (2.12% and 17.47% gains) rather than any derivation, equation, or first-principles result. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text; the work is self-contained as an empirical engineering contribution whose validity is externally falsifiable via replication on the reported datasets.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can generate high-quality embeddings from graph descriptions that improve GNN representational capacity
- ad hoc to paper LLM-based text propagation, augmentation, PageRank node selection, and edge reconfiguration mitigate sparsity without net negative effects
Forward citations
Cited by 1 Pith paper
-
When LLM Agents Meet Graph Optimization: An Automated Data Quality Improvement Approach
LAGA is a unified multi-agent LLM framework that automates comprehensive quality optimization for text-attributed graphs by running detection, planning, action, and evaluation agents in a closed loop.
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
URL https:// arxiv.org/abs/2005.14165. Chen, M., Wei, Z., Huang, Z., Ding, B., and Li, Y . Simple and deep graph convolutional networks. In International Conference on Machine Learning, ICML,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Chien, E., Chang, W.-C., Hsieh, C.-J., Yu, H.-F., Zhang, J., Milenkovic, O., and Dhillon, I
URL https://arxiv.org/abs/2310.04668. Chien, E., Chang, W.-C., Hsieh, C.-J., Yu, H.-F., Zhang, J., Milenkovic, O., and Dhillon, I. S. Node feature extrac- tion by self-supervised multi-scale neighborhood predic- tion,
-
[3]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URL https://arxiv. org/abs/1810.04805. Duan, K., Liu, Q., Chua, T.-S., Yan, S., Ooi, W. T., Xie, Q., and He, J. Simteg: A frustratingly simple approach improves textual graph learning,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
Hamilton, W., Ying, Z., and Leskovec, J
URL https: //arxiv.org/abs/2302.12977. Hamilton, W., Ying, Z., and Leskovec, J. Inductive repre- sentation learning on large graphs. Advances in Neural Information Processing Systems, NeurIPS,
-
[6]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
URL https://arxiv.org/abs/2006.03654. He, X., Bresson, X., Laurent, T., Perold, A., LeCun, Y ., and Hooi, B. Harnessing explanations: Llm-to-lm inter- preter for enhanced text-attributed graph representation learning, 2024a. URL https://arxiv.org/abs/ 2305.19523. He, Y ., Sui, Y ., He, X., and Hooi, B. Unigraph: Learning a unified cross-domain foundation ...
work page internal anchor Pith review Pith/arXiv arXiv 2006
- [7]
-
[8]
Lightdic: A simple yet effective approach for large-scale digraph representation learning
Li, X., Liao, M., Wu, Z., Su, D., Zhang, W., Li, R.-H., and Wang, G. Lightdic: A simple yet effective approach for large-scale digraph representation learning. arXiv preprint arXiv:2401.11772, 2024a. Li, Z., Li, R.-H., Liao, M., Jin, F., and Wang, G. Privacy- preserving graph embedding based on local differential privacy, 2024b. URL https://arxiv.org/abs/...
-
[9]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
URL https://arxiv.org/abs/1907.11692. Mernyei, P. and Cangea, C. Wiki-cs: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[10]
Distributed Representations of Words and Phrases and their Compositionality
URL https://arxiv. org/abs/1310.4546. Ni, J., Li, J., and McAuley, J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proc. of EMNLP,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Rossi, E., Kenlay, H., Gorinova, M
URL https://arxiv.org/abs/ 2402.12022. Rossi, E., Kenlay, H., Gorinova, M. I., Chamberlain, B. P., Dong, X., and Bronstein, M. On the unrea- sonable effectiveness of feature propagation in learn- ing on graphs with missing node features,
-
[12]
URL https://arxiv.org/abs/2111.12128. 9 Rethinking Graph Structure Learning in the Era of LLMs Sen, P., Namata, G., Bilgic, M., Getoor, L., Galligher, B., and Eliassi-Rad, T. Collective classification in network data. AI magazine,
-
[13]
Singh, G. and Sachan, M. Multi-layer perceptron (mlp) neural network technique for offline handwrit- ten gurmukhi character recognition. In 2014 IEEE International Conference on Computational Intelligence and Computing Research, pp. 1–5,
work page 2014
-
[14]
Veliˇckovi´c, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., and Bengio, Y
doi: 10.1109/ ICCIC.2014.7238334. Veliˇckovi´c, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., and Bengio, Y . Graph attention networks. In International Conference on Learning Representations, ICLR,
-
[15]
URL https://arxiv.org/ abs/2406.12608. Wen, Z. and Fang, Y . Augmenting low-resource text classi- fication with graph-grounded pre-training and prompt- ing. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, pp. 506–516. ACM, July
-
[16]
URL http: //dx.doi.org/10.1145/3539618.3591641
doi: 10.1145/3539618.3591641. URL http: //dx.doi.org/10.1145/3539618.3591641. Yan, H., Li, C., Long, R., Yan, C., Zhao, J., Zhuang, W., Yin, J., Zhang, P., Han, W., Sun, H., et al. A comprehen- sive study on text-attributed graphs: Benchmarking and rethinking. In Proc. of NeurIPS,
-
[17]
doi: 10.1145/3534678.3539121. URL http://dx.doi. org/10.1145/3534678.3539121. Zhao, J., Qu, M., Li, C., Yan, H., Liu, Q., Li, R., Xie, X., and Tang, J. Learning on large-scale text-attributed graphs via variational inference,
-
[18]
Zhu, Y ., Wang, Y ., Shi, H., and Tang, S
URL https: //arxiv.org/abs/2210.14709. Zhu, Y ., Wang, Y ., Shi, H., and Tang, S. Efficient tun- ing and inference for large language models on tex- tual graphs,
-
[19]
10 Rethinking Graph Structure Learning in the Era of LLMs A
URL https://arxiv.org/abs/ 2401.15569. 10 Rethinking Graph Structure Learning in the Era of LLMs A. Datasets This section provides a detailed introduction to the datasets used in the main content. The statistics of the TAG datasets we use is as shown in Table
-
[20]
dataset is derived from the Amazon-Electronics dataset (Ni et al., 2019). In this dataset, nodes represent electronics-related products, and edges sig- nify frequent co-purchases or co-views between products. Each node is labeled based on a three-level classification scheme for electronics products. User reviews serve as the textual attributes for the nod...
work page 2019
-
[21]
It consists of multiple layers of neurons, where each layer is fully connected to the previous one
is a simple feed-forward neural network model, commonly used for baseline classifi- cation tasks. It consists of multiple layers of neurons, where each layer is fully connected to the previous one. The model is trained via backpropagation, with the final output layer producing predictions. GCN (Kipf & Welling, 2017)is a graph-based neural net- work model ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.