IAFormer: Interaction-Aware Transformer network for collider data analysis
Pith reviewed 2026-05-22 17:09 UTC · model grok-4.3
The pith
IAFormer classifies top quarks and quark-gluon jets at state-of-the-art accuracy using far fewer parameters than prior particle transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
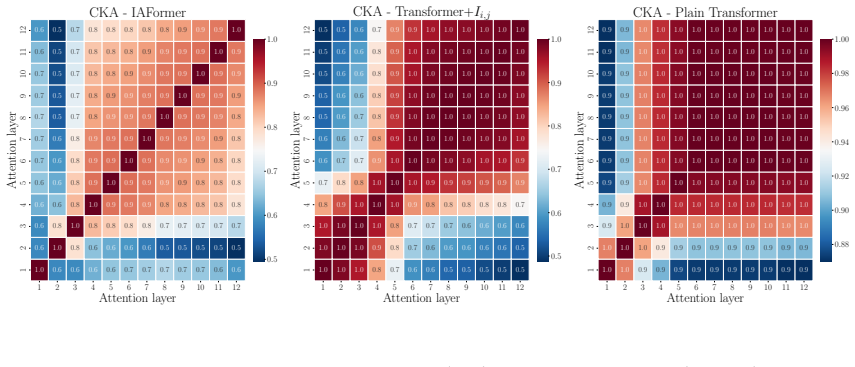
IAFormer achieves state-of-the-art performance on top and quark-gluon classification by making the attention matrix depend on predefined boost-invariant pairwise quantities and by replacing standard attention with a differential sparse mechanism that dynamically prioritizes informative particle tokens, thereby reducing model size and computation without loss of accuracy.
What carries the argument
Dynamic sparse attention whose matrix is constructed from a fixed set of boost-invariant pairwise quantities, combined with differential attention to select relevant tokens on the fly.
If this is right
- Large collider datasets can be processed with substantially lower memory and runtime requirements.
- Sparse attention layers produce outputs that remain stable under statistical fluctuations in the input events.
- Layer-wise interpretability reveals that physically relevant features are assembled progressively through the sparse mechanism.
- Domain-specific pairwise quantities can be injected into Transformer attention to reduce parameter count while retaining performance.
Where Pith is reading between the lines
- The same construction could be tested on regression or anomaly-detection tasks in collider physics where full attention is currently too expensive.
- If the predefined quantities prove sufficient across more datasets, future models might be initialized with far fewer learned interaction parameters.
- Real-time event selection at high-luminosity colliders could become feasible with networks of this reduced complexity.
Load-bearing premise
The chosen set of predefined boost-invariant pairwise quantities already encodes all the interaction information needed for high-accuracy classification on these datasets.
What would settle it
A direct comparison on the same top and quark-gluon datasets in which a standard particle transformer or a version of IAFormer without the predefined pairwise quantities reaches equal or higher accuracy at comparable or lower computational cost.
Figures




read the original abstract
In this paper, we introduce \texttt{IAFormer}, a novel Transformer-based architecture that efficiently integrates pairwise particle interactions through a dynamic sparse attention mechanism. \texttt{IAFormer} has two new mechanisms within the model. First, the attention matrix depends on predefined boost invariant pairwise quantities, reducing the network parameters significantly from the original particle transformer models. Second, \texttt{IAFormer} incorporates the sparse attention mechanism by utilizing the "differential attention", so that it can dynamically prioritize relevant particle tokens while reducing computational overhead associated with less informative ones. This approach significantly lowers the model complexity without compromising performance. Despite being computationally efficient by more than an order of magnitude than the Particle Transformer network, \texttt{IAFormer} achieves state-of-the-art performance in classification tasks on the top and quark-gluon datasets. Furthermore, we employ AI interpretability techniques, verifying that the model effectively captures physically meaningful information layer by layer through its sparse attention mechanism, building an efficient network output that is resistant to statistical fluctuations. \texttt{IAFormer} highlights the need for sparse attention in Transformer analysis to reduce the network size while improving its performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IAFormer, a Transformer architecture for collider data analysis that conditions the attention matrix on predefined boost-invariant pairwise particle quantities and employs a differential sparse attention mechanism. It claims this yields more than an order of magnitude computational efficiency gain over the Particle Transformer while achieving state-of-the-art classification performance on top-quark and quark-gluon jet tagging datasets, with additional support from layer-wise AI interpretability analysis showing capture of physically meaningful features.
Significance. If the performance and efficiency claims are substantiated, the work could offer a practical advance for scalable machine learning in high-energy physics by incorporating domain-specific invariants to reduce parameters and computation. The interpretability component is a constructive element that may help validate physical relevance in jet classification tasks.
major comments (2)
- [Abstract and results] Abstract and results sections: the central claims of SOTA performance on the top and quark-gluon datasets together with an order-of-magnitude efficiency improvement over the Particle Transformer are presented without any reported details on training procedure, data splits, baseline implementations, statistical uncertainties, or error bars. These omissions directly undermine evaluation of the empirical assertions that constitute the paper's primary contribution.
- [Architecture description (methods)] Architecture description (methods): the model deliberately fixes the set of boost-invariant pairwise quantities used to condition the attention matrix rather than learning interactions from embeddings. No ablation is described that replaces this fixed set with a learned pairwise module, leaving open whether the reported accuracy and efficiency gains are attributable to the differential attention or to an unusually well-matched choice of input features for these particular datasets.
minor comments (2)
- [Abstract] The abstract states that the model is 'resistant to statistical fluctuations' but provides no quantitative metric or test (e.g., variance across seeds or robustness to input perturbations) to support this phrasing.
- [Methods] Notation for the differential attention mechanism should be introduced with an explicit equation or pseudocode early in the methods section to allow readers to reproduce the sparsity implementation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major point below and have revised the manuscript to improve reproducibility and strengthen the analysis.
read point-by-point responses
-
Referee: [Abstract and results] Abstract and results sections: the central claims of SOTA performance on the top and quark-gluon datasets together with an order-of-magnitude efficiency improvement over the Particle Transformer are presented without any reported details on training procedure, data splits, baseline implementations, statistical uncertainties, or error bars. These omissions directly undermine evaluation of the empirical assertions that constitute the paper's primary contribution.
Authors: We agree that these details are necessary for proper evaluation. The revised manuscript includes an expanded Experimental Setup section with: complete training procedure (optimizer, learning rate, epochs, batch size); explicit data splits for both datasets; implementation details for the Particle Transformer baseline to ensure fair comparison; and results reported with statistical uncertainties and error bars from five independent runs with different random seeds. These additions directly support the reported performance and efficiency claims. revision: yes
-
Referee: [Architecture description (methods)] Architecture description (methods): the model deliberately fixes the set of boost-invariant pairwise quantities used to condition the attention matrix rather than learning interactions from embeddings. No ablation is described that replaces this fixed set with a learned pairwise module, leaving open whether the reported accuracy and efficiency gains are attributable to the differential attention or to an unusually well-matched choice of input features for these particular datasets.
Authors: The fixed boost-invariant quantities (invariant mass, Δη, Δφ) are a deliberate choice grounded in established collider physics to embed domain knowledge and minimize parameters. This design lets the differential attention focus on higher-order effects. We acknowledge the value of an ablation. The revised manuscript now includes a new ablation study replacing the fixed set with a learned pairwise module; the updated results and discussion clarify the relative contributions of the fixed features and the differential attention to accuracy and efficiency. revision: yes
Circularity Check
No circularity: performance claims rest on external empirical benchmarks
full rationale
The paper introduces IAFormer as a new architecture whose attention matrix is conditioned on a fixed set of predefined boost-invariant pairwise quantities and a differential sparse attention mechanism. The central claims of order-of-magnitude efficiency gains and state-of-the-art classification accuracy are established solely by direct numerical comparison against the Particle Transformer and other baselines on the standard top-tagging and quark-gluon tagging datasets. No equation or result in the derivation reduces to a quantity defined in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation whose content is itself unverified. The evaluation therefore remains externally falsifiable and independent of the model's internal definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- choice of boost-invariant pairwise quantities
axioms (2)
- domain assumption Boost invariance is a fundamental symmetry of high-energy particle collisions and can be used to define interaction features.
- domain assumption Standard supervised classification loss and optimization suffice to train the model to capture physically meaningful patterns.
invented entities (1)
-
Differential attention mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the attention matrix depends on predefined boost invariant pairwise quantities... differential attention... αi,i′=softmax(W1·Ii,j)−βsoftmax(W2·Ii,j)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IAFormer... achieves state-of-the-art performance... with a significantly reduced network size
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Dissecting Jet-Tagger Through Mechanistic Interpretability
A Particle Transformer jet tagger contains a sparse six-head circuit whose source-relay-readout structure recovers most performance and whose residual stream preferentially encodes 2-prong energy correlators.
Reference graph
Works this paper leans on
-
[1]
J. M. Butterworth, A. R. Davison, M. Rubin, and G. P. Salam,Jet substructure as a new Higgs search channel at the LHC,Phys. Rev. Lett.100(2008) 242001, [arXiv:0802.2470]
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[2]
L. G. Almeida, M. Backović, M. Cliche, S. J. Lee, and M. Perelstein,Playing Tag with ANN: Boosted Top Identification with Pattern Recognition,JHEP07(2015) 086, [arXiv:1501.05968]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
Deep-learned Top Tagging with a Lorentz Layer
A. Butter, G. Kasieczka, T. Plehn, and M. Russell,Deep-learned Top Tagging with a Lorentz Layer,SciPost Phys.5(2018), no. 3 028, [arXiv:1707.08966]. 25
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Deep-learning Top Taggers or The End of QCD?
G. Kasieczka, T. Plehn, M. Russell, and T. Schell,Deep-learning Top Taggers or The End of QCD?,JHEP05(2017) 006, [arXiv:1701.08784]
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [5]
-
[6]
A. Butter et al.,The Machine Learning landscape of top taggers,SciPost Phys.7 (2019) 014, [arXiv:1902.09914]
-
[7]
A. Chakraborty, S. H. Lim, M. M. Nojiri, and M. Takeuchi,Neural Network-based Top Tagger with Two-Point Energy Correlations and Geometry of Soft Emissions, JHEP07(2020) 111, [arXiv:2003.11787]
-
[8]
S. Bhattacharya, M. Guchait, and A. H. Vijay,Boosted top quark tagging and polarization measurement using machine learning,Phys. Rev. D105(2022), no. 4 042005, [arXiv:2010.11778]
- [9]
- [10]
-
[11]
B. Tannenwald, C. Neu, A. Li, G. Buehlmann, A. Cuddeback, L. Hatfield, R. Parvatam, and C. Thompson,Benchmarking Machine Learning Techniques with Di-Higgs Production at the LHC,arXiv:2009.06754
- [12]
- [13]
- [14]
- [15]
- [16]
- [17]
-
[18]
D. Athanasakos, A. J. Larkoski, and J. Mulligan,Is infrared-collinear safe information all you need for jet classification?,arXiv:2305.08979
- [19]
- [20]
-
[21]
A. Hammad and M. M. Nojiri,Streamlined jet tagging network assisted by jet prong structure,JHEP06(2024) 176, [arXiv:2404.14677]. [22]CMSCollaboration, A. M. Sirunyan et al.,Identification of heavy-flavour jets with the CMS detector in pp collisions at 13 TeV,JINST13(2018), no. 05 P05011, [arXiv:1712.07158]. [23]ATLASCollaboration,Identification of Jets Co...
-
[22]
M. Andrews et al.,End-to-end jet classification of boosted top quarks with the CMS open data,EPJ Web Conf.251(2021) 04030, [arXiv:2104.14659]
-
[23]
P. Keicher,Machine Learning in Top Physics in the ATLAS and CMS Collaborations, in15th International Workshop on Top Quark Physics, 1, 2023.arXiv:2301.09534
-
[24]
P. Baroň, J. Kvita, R. Přívara, J. Tomeček, and R. Vodák,Application of Machine Learning Based Top Quark and W Jet Tagging to Hadronic Four-Top Final States Induced by SM as well as BSM Processes, in16th International Workshop on Top Quark Physics, 10, 2023.arXiv:2310.13009
- [25]
- [26]
- [27]
-
[28]
Interpretable deep learning for two-prong jet classification with jet spectra,
A. Chakraborty, S. H. Lim, and M. M. Nojiri,Interpretable deep learning for two-prong jet classification with jet spectra,JHEP07(2019) 135, [arXiv:1904.02092]
- [29]
-
[30]
A. Subba and R. K. Singh,Role of polarizations and spin-spin correlations of W’s in e-e+→W-W+ at s=250 GeV to probe anomalous W-W+Z/γcouplings,Phys. Rev. D 107(2023), no. 7 073004, [arXiv:2212.12973]. 27
-
[31]
A. Bogatskiy, T. Hoffman, D. W. Miller, J. T. Offermann, and X. Liu,Explainable equivariant neural networks for particle physics: PELICAN,JHEP03(2024) 113, [arXiv:2307.16506]
- [32]
- [33]
- [34]
-
[35]
J. Guiang et al.,Improving tracking algorithms with machine learning: a case for line-segment tracking at the High Luminosity LHC, inConnecting The Dots 2023, 3, 2024.arXiv:2403.13166
-
[36]
J. Erdmann,A tagger for strange jets based on tracking information using long short-term memory,JINST15(2020), no. 01 P01021, [arXiv:1907.07505]
- [37]
-
[38]
J. Erdmann, O. Nackenhorst, and S. V. Zeißner,Maximum performance of strange-jet tagging at hadron colliders,JINST16(2021), no. 08 P08039, [arXiv:2011.10736]
-
[39]
P. T. Komiske, E. M. Metodiev, and M. D. Schwartz,Deep learning in color: towards automated quark/gluon jet discrimination,JHEP01(2017) 110, [arXiv:1612.01551]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Recursive Neural Networks in Quark/Gluon Tagging
T. Cheng,Recursive Neural Networks in Quark/Gluon Tagging,Comput. Softw. Big Sci.2(2018), no. 1 3, [arXiv:1711.02633]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
M. Abbas, A. Khan, A. S. Qureshi, and M. W. Khan,Extracting Signals of Higgs Boson From Background Noise Using Deep Neural Networks,arXiv:2010.08201. [46]CMSCollaboration, A. Tumasyan et al.,Search for Higgs Boson and Observation of Z Boson through their Decay into a Charm Quark-Antiquark Pair in Boosted Topologies in Proton-Proton Collisions at s=13 TeV,...
- [42]
-
[43]
K. Goswami, S. Prasad, N. Mallick, R. Sahoo, and G. B. Mohanty,A machine learning-based study of open-charm hadrons in proton-proton collisions at the Large Hadron Collider,arXiv:2404.09839
- [44]
- [45]
- [46]
-
[47]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin,Attention is all you need,Advances in neural information processing systems30(2017)
work page 2017
- [48]
- [49]
- [50]
-
[51]
F. Blekman, F. Canelli, A. De Moor, K. Gautam, A. Ilg, A. Macchiolo, and E. Ploerer,Tagging more quark jet flavours at FCC-ee at 91 GeV with a transformer-based neural network,Eur. Phys. J. C85(2025), no. 2 165, [arXiv:2406.08590]
-
[52]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever,Generating long sequences with sparse transformers,arXiv preprint arXiv:1904.10509(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
- [53]
-
[54]
X. Pan, T. Ye, Z. Xia, S. Song, and G. Huang,Slide-transformer: Hierarchical vision transformer with local self-attention, inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 2082–2091, 2023
work page 2082
-
[55]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan,Longformer: The long-document transformer,arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[56]
A. Hassani, S. Walton, N. Shah, A. Abuduweili, J. Li, and H. Shi,Escaping the big data paradigm with compact transformers,arXiv preprint arXiv:2104.05704(2021)
-
[57]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel,Gaussian error linear units (gelus),arXiv preprint arXiv:1606.08415(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[58]
B. Zhang and R. Sennrich,Root mean square layer normalization,Advances in Neural Information Processing Systems32(2019)
work page 2019
-
[59]
S. Elfwing, E. Uchibe, and K. Doya,Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,Neural networks107(2018) 3–11
work page 2018
-
[60]
G. Kasieczka, T. Plehn, J. Thompson, and M. Russel,Top quark tagging reference dataset, Mar., 2019
work page 2019
-
[61]
P. Komiske, E. Metodiev, and J. Thaler,Pythia8 quark and gluon jets for energy flow, May, 2019
work page 2019
-
[62]
A comprehensive guide to the physics and usage of PYTHIA 8.3
C. Bierlich et al.,A comprehensive guide to the physics and usage of PYTHIA 8.3, SciPost Phys. Codeb.2022(2022) 8, [arXiv:2203.11601]. 29 [68]DELPHES 3Collaboration, J. de Favereau, C. Delaere, P. Demin, A. Giammanco, V. Lemaître, A. Mertens, and M. Selvaggi,DELPHES 3, A modular framework for fast simulation of a generic collider experiment,JHEP02(2014) 0...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[63]
Shimmin,Particle Convolution for High Energy Physics, 7, 2021
C. Shimmin,Particle Convolution for High Energy Physics, 7, 2021. arXiv:2107.02908
- [64]
-
[65]
J. Brehmer, V. Bresó, P. de Haan, T. Plehn, H. Qu, J. Spinner, and J. Thaler,A Lorentz-Equivariant Transformer for All of the LHC,arXiv:2411.00446
-
[66]
V. Mikuni and F. Canelli,Point cloud transformers applied to collider physics,Mach. Learn. Sci. Tech.2(2021), no. 3 035027, [arXiv:2102.05073]
-
[67]
V. Mikuni and B. Nachman,Method to simultaneously facilitate all jet physics tasks, Phys. Rev. D111(2025), no. 5 054015, [arXiv:2502.14652]
-
[68]
I. Loshchilov and F. Hutter,Decoupled weight decay regularization, inInternational Conference on Learning Representations, 2019
work page 2019
-
[69]
V. Mikuni and F. Canelli,ABCNet: An attention-based method for particle tagging, Eur. Phys. J. Plus135(2020), no. 6 463, [arXiv:2001.05311]
-
[70]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark, et al.,Training compute-optimal large language models,arXiv preprint arXiv:2203.15556(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[71]
On the relationship between self-attention and convolutional layers,
J.-B. Cordonnier, A. Loukas, and M. Jaggi,On the relationship between self-attention and convolutional layers,arXiv preprint arXiv:1911.03584(2019)
-
[72]
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton,Similarity of neural network representations revisited, inInternational conference on machine learning, pp. 3519–3529, PMLR, 2019
work page 2019
- [73]
-
[74]
A. Binder, G. Montavon, S. Lapuschkin, K.-R. Müller, and W. Samek,Layer-wise relevance propagation for neural networks with local renormalization layers, in Artificial Neural Networks and Machine Learning–ICANN 2016: 25th International Conference on Artificial Neural Networks, Barcelona, Spain, September 6-9, 2016, Proceedings, Part II 25, pp. 63–71, Spri...
work page 2016
-
[75]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, Grad-cam: visual explanations from deep networks via gradient-based localization, International journal of computer vision128(2020) 336–359
work page 2020
-
[76]
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala,PyTorch: an 30 imperative style, high-performance deep learning library. Curran Associates Inc., Red Hook, NY, USA, 2019. 31
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.