LatentStealth: Unnoticeable and Efficient Adversarial Attacks on Expressive Human Pose and Shape Estimation
Pith reviewed 2026-05-22 14:28 UTC · model grok-4.3
The pith
LatentStealth generates adversarial perturbations for human pose and shape models inside latent space rather than pixel space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By projecting inputs into the latent space, where adversarial patterns are generated and progressively refined along optimized directions, LatentStealth maintains high imperceptibility while preserving effectiveness and achieving competitive attack performance with low computational overhead using only a small number of model output queries.
What carries the argument
Projection of inputs into latent space followed by generation and progressive refinement of adversarial patterns along optimized directions guided by few model output queries.
If this is right
- EHPS models used in live-streaming and digital humans are exposed as vulnerable to stealthy attacks that current visual checks would miss.
- Attack success with only a small number of queries makes the threat practical for real-world deployment against deployed systems.
- The approach outperforms prior pixel-space attacks on standard 3DPW and UBody benchmarks in both stealth and efficiency.
- Security risks such as forced generation of violent or offensive poses can now be demonstrated without obvious tampering.
Where Pith is reading between the lines
- The same latent-space strategy could transfer to other regression-based vision tasks where pixel perturbations are too conspicuous.
- If the pretrained encoder used for the latent space has reconstruction errors, those errors might either aid or hinder attack transferability.
- Training EHPS models with latent-space robustness objectives would be a direct countermeasure suggested by the attack design.
Load-bearing premise
Structured latent representations of natural images allow adversarial patterns that remain visually imperceptible after decoding while still fooling the EHPS model, and that optimization with limited queries suffices without separate checks on reconstruction quality.
What would settle it
Decoded images from the perturbed latent codes show clearly visible artifacts or produce no measurable drop in EHPS accuracy on held-out test images.
Figures




read the original abstract
Expressive human pose and shape estimation (EHPS) plays a central role in digital human generation, particularly in live-streaming applications. However, most existing EHPS models focus primarily on minimizing estimation errors, with limited attention on potential security vulnerabilities, such as generating inappropriate content, violent actions, or racially offensive gestures and expressions. Current adversarial attacks on EHPS models often generate visually conspicuous perturbations, limiting their practicality and ability to expose real-world security threats. To address this limitation, we propose an unnoticeable adversarial method, termed \textbf{LatentStealth}, specifically tailored for EHPS models. The key idea is to exploit the structured latent representations of natural images as the medium for crafting perturbations. Instead of injecting noise directly into the pixel space, our method projects inputs into the latent space, where adversarial patterns are generated and progressively refined along optimized directions. This latent-space manipulation enables the attack to maintain high imperceptibility while preserving its effectiveness. Furthermore, as the optimization process is guided by only a small number of model output queries, the framework achieves competitive attack performance with low computational overhead, making it both practical and efficient for real-world scenarios. Extensive experiments on the 3DPW and UBody datasets demonstrate the superiority of LatentStealth, revealing critical vulnerabilities in current systems. These findings highlight the urgent need to address and mitigate security risks in digital human generation technologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LatentStealth, an adversarial attack on Expressive Human Pose and Shape Estimation (EHPS) models. Inputs are projected into the latent space of a pretrained encoder; adversarial patterns are generated and refined along optimized directions before decoding back to images. The method claims to achieve high imperceptibility, preserved attack effectiveness, and competitive performance with low overhead via a small number of model output queries. Experiments on 3DPW and UBody datasets are presented as demonstrating superiority over prior attacks.
Significance. If validated, the work is significant for highlighting security risks in EHPS models used in digital human generation and live-streaming. The latent-space formulation offers a practical route to imperceptible perturbations and few-query efficiency, which could inform defense design. The empirical focus on real-world applicability is a strength, though it requires quantitative grounding to realize that potential.
major comments (3)
- [§3] §3 (Method): The central mechanism projects images into latent space, adds refined adversarial patterns, and decodes. No encoder architecture is named, no reconstruction-error bound is given, and no analysis shows that small latent displacements map to imperceptible pixel changes. This assumption is load-bearing for the imperceptibility claim.
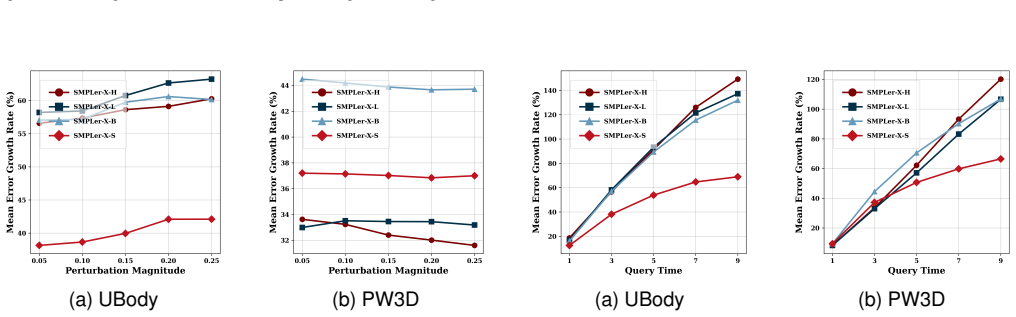
- [§4] §4 (Experiments): Superiority is asserted on 3DPW and UBody, yet the results provide no attack success rates, MPJPE or other EHPS error metrics, LPIPS/SSIM perceptual distances, or visual fidelity comparisons against pixel-space baselines. Without these numbers the effectiveness-plus-imperceptibility claim cannot be evaluated.
- [§3.2] §3.2 (Optimization): The few-query refinement process is described without a concrete query budget, convergence criterion, or trade-off curve relating attack success to reconstruction quality. This detail is required to substantiate the efficiency and imperceptibility guarantees.
minor comments (2)
- [Abstract] Abstract: The phrase 'extensive experiments demonstrate the superiority' should be accompanied by at least one concrete metric or baseline name to orient readers.
- [§3] Notation: Ensure the latent-space variables (e.g., direction vectors, refinement steps) are defined with consistent symbols when first introduced.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments point by point below. Where revisions are needed to strengthen the presentation, we have indicated that changes will be made in the next version of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central mechanism projects images into latent space, adds refined adversarial patterns, and decodes. No encoder architecture is named, no reconstruction-error bound is given, and no analysis shows that small latent displacements map to imperceptible pixel changes. This assumption is load-bearing for the imperceptibility claim.
Authors: We appreciate the referee pointing out the need for greater specificity in the method description. While the manuscript outlines the latent-space projection and decoding process, we agree that explicit details on the encoder architecture, reconstruction error bounds, and a supporting analysis for imperceptibility were insufficient. In the revised manuscript, we will name the specific pretrained encoder architecture employed, provide quantitative bounds on the reconstruction error, and include an analysis (with supporting experiments or mathematical justification) demonstrating that small displacements in the latent space result in imperceptible pixel-level changes. This will better substantiate the imperceptibility claim. revision: yes
-
Referee: [§4] §4 (Experiments): Superiority is asserted on 3DPW and UBody, yet the results provide no attack success rates, MPJPE or other EHPS error metrics, LPIPS/SSIM perceptual distances, or visual fidelity comparisons against pixel-space baselines. Without these numbers the effectiveness-plus-imperceptibility claim cannot be evaluated.
Authors: We acknowledge that the experimental section would benefit from additional quantitative metrics to allow for a more rigorous evaluation. The manuscript includes comparisons on the 3DPW and UBody datasets demonstrating the advantages of LatentStealth, but we agree that explicit reporting of attack success rates, MPJPE and other EHPS-specific error metrics, along with LPIPS and SSIM for perceptual quality, and side-by-side comparisons to pixel-space attack baselines, would strengthen the claims. We will incorporate these metrics and comparisons into the revised experiments section. revision: yes
-
Referee: [§3.2] §3.2 (Optimization): The few-query refinement process is described without a concrete query budget, convergence criterion, or trade-off curve relating attack success to reconstruction quality. This detail is required to substantiate the efficiency and imperceptibility guarantees.
Authors: Thank you for this observation regarding the optimization details. The manuscript emphasizes the few-query nature of the refinement process, but we concur that concrete specifications are necessary for reproducibility and to support the efficiency claims. In the revision, we will provide the specific query budget utilized in our experiments, detail the convergence criteria employed, and include trade-off curves that illustrate the relationship between attack success and reconstruction quality under varying query counts. revision: yes
Circularity Check
No significant circularity in the proposed empirical method
full rationale
The paper presents LatentStealth as an algorithmic construction for generating adversarial perturbations in latent space of a pretrained encoder, followed by decoding and experimental validation on 3DPW and UBody datasets. No mathematical derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on empirical attack success and imperceptibility rather than any self-referential reduction to inputs by construction. This is the expected outcome for an applied CV attack paper whose validity is tested externally via experiments.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of optimization queries
- latent direction refinement steps
axioms (2)
- domain assumption Natural images possess structured latent representations that can be manipulated to produce adversarial effects while preserving visual fidelity after decoding.
- domain assumption Few-query optimization is sufficient to discover effective adversarial directions in latent space for EHPS models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
projects inputs into the latent space, where adversarial patterns are generated and progressively refined along optimized directions... VAE... η=0.05... multi-task loss L = -E[||Δα||² + ...] + pixel L2 term
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
strict test budget... only three queries of the model outputs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Smpl: A skinned multi-person linear model,
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: A skinned multi-person linear model,”ACM Transactions on Graphics, vol. 34, no. 6, 2015
work page 2015
-
[2]
Expressive body capture: 3d hands, face, and body from a single image,
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” inCVPR, 2019, pp. 10 967–10 977
work page 2019
-
[3]
Monocular real-time full body capture with inter-part correlations,
Y . Zhou, M. Habermann, I. Habibie, A. Tewari, C. Theobalt, and F. Xu, “Monocular real-time full body capture with inter-part correlations,” in CVPR, 2021, pp. 4811–4822
work page 2021
-
[4]
Pymaf- x: Towards well-aligned full-body model regression from monocular images,
H. Zhang, Y . Tian, Y . Zhang, M. Li, L. An, Z. Sun, and Y . Liu, “Pymaf- x: Towards well-aligned full-body model regression from monocular images,”TPAMI, vol. 45, no. 10, pp. 12 287–12 303, 2023
work page 2023
-
[5]
Smpler-x: Scaling up expressive human pose and shape estimation,
Z. Cai, W. Yin, A. Zeng, C. Wei, Q. Sun, W. Yanjun, H. E. Pang, H. Mei, M. Zhang, L. Zhanget al., “Smpler-x: Scaling up expressive human pose and shape estimation,” inNeurIPS, vol. 36, 2024
work page 2024
-
[6]
Avatarclip: Zero-shot text-driven generation and animation of 3d avatars,
F. Hong, M. Zhang, L. Pan, Z. Cai, L. Yang, and Z. Liu, “Avatarclip: Zero-shot text-driven generation and animation of 3d avatars,”ACM Transactions on Graphics, vol. 41, no. 4, pp. 1–19, 2022
work page 2022
-
[7]
Garment4d: Garment reconstruction from point cloud sequences,
F. Hong, L. Pan, Z. Cai, and Z. Liu, “Garment4d: Garment reconstruction from point cloud sequences,” inNeurIPS, vol. 34, 2021, pp. 27 940– 27 951
work page 2021
-
[8]
Understanding the robustness of skeleton-based action recognition under adversarial attack,
H. Wang, F. He, Z. Peng, T. Shao, Y .-L. Yang, K. Zhou, and D. Hogg, “Understanding the robustness of skeleton-based action recognition under adversarial attack,” inCVPR, 2021, pp. 14 656–14 665
work page 2021
-
[9]
Towards robust 3d pose transfer with adversarial learning,
H. Chen, H. Tang, E. Adeli, and G. Zhao, “Towards robust 3d pose transfer with adversarial learning,” inCVPR, 2024, pp. 2295–2304
work page 2024
-
[10]
Distracting downpour: Ad- versarial weather attacks for motion estimation,
J. Schmalfuss, L. Mehl, and A. Bruhn, “Distracting downpour: Ad- versarial weather attacks for motion estimation,” inICCV, 2023, pp. 10 106–10 116
work page 2023
-
[11]
On the robustness of neural-enhanced video streaming against adversarial attacks,
Q. Zhou, J. Guo, S. Guo, R. Li, J. Zhang, B. Wang, and Z. Xu, “On the robustness of neural-enhanced video streaming against adversarial attacks,” inAAAI, vol. 38, no. 15, 2024, pp. 17 123–17 131
work page 2024
-
[12]
Whole-body human pose estimation in the wild,
S. Jin, L. Xu, J. Xu, C. Wang, W. Liu, C. Qian, W. Ouyang, and P. Luo, “Whole-body human pose estimation in the wild,” inECCV, 2020, pp. 196–214
work page 2020
-
[13]
Accurate 3d hand pose estimation for whole-body 3d human mesh estimation,
G. Moon, H. Choi, and K. M. Lee, “Accurate 3d hand pose estimation for whole-body 3d human mesh estimation,” inCVPR, 2022, pp. 2308–2317
work page 2022
-
[14]
One-stage 3d whole- body mesh recovery with component aware transformer,
J. Lin, A. Zeng, H. Wang, L. Zhang, and Y . Li, “One-stage 3d whole- body mesh recovery with component aware transformer,” inCVPR, 2023, pp. 21 159–21 168
work page 2023
-
[15]
Unveiling hidden vulnerabilities in digital human generation via adversarial attacks,
Z. Li, Y . Jin, F. Shen, Z. Liu, W. Chen, P. Zhang, X. Zhang, B. Chen, M. Shen, K. Wuet al., “Unveiling hidden vulnerabilities in digital human generation via adversarial attacks,”Pattern Recognition, vol. 170, p. 112042, 2026
work page 2026
-
[16]
LatentPoison - Adversarial Attacks On The Latent Space
A. Creswell, A. A. Bharath, and B. Sengupta, “Latentpoison-adversarial attacks on the latent space,”arXiv:1711.02879, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Can push- forward generative models fit multimodal distributions?
A. Salmona, V . De Bortoli, J. Delon, and A. Desolneux, “Can push- forward generative models fit multimodal distributions?” inNeurIPS, vol. 35, 2022, pp. 10 766–10 779
work page 2022
-
[18]
Auto-encoding variational bayes,
D. P. Kingma, M. Wellinget al., “Auto-encoding variational bayes,” 2013
work page 2013
-
[19]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS Workshop, 2021
work page 2021
-
[20]
Adversarial robustness of vaes through the lens of local geometry,
A. Khan and A. Storkey, “Adversarial robustness of vaes through the lens of local geometry,” inAISTATS, 2023, pp. 8954–8967
work page 2023
-
[21]
Generating out of distribution adver- sarial attack using latent space poisoning,
U. Upadhyay and P. Mukherjee, “Generating out of distribution adver- sarial attack using latent space poisoning,”SPL, vol. 28, pp. 523–527, 2021
work page 2021
-
[22]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inNeurIPS, vol. 30, 2017
work page 2017
-
[23]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”TIP, vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[24]
Sequential 3d human pose and shape estimation from point clouds,
K. Wang, J. Xie, G. Zhang, L. Liu, and J. Yang, “Sequential 3d human pose and shape estimation from point clouds,” inCVPR, 2020, pp. 7275– 7284
work page 2020
-
[25]
J. Li, C. Xu, Z. Chen, S. Bian, L. Yang, and C. Lu, “Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation,” inCVPR, 2021, pp. 3383–3393
work page 2021
-
[26]
Learning to estimate 3d human pose and shape from a single color image,
G. Pavlakos, L. Zhu, X. Zhou, and K. Daniilidis, “Learning to estimate 3d human pose and shape from a single color image,” inCVPR, 2018, pp. 459–468
work page 2018
-
[27]
Eventhpe: Event-based 3d human pose and shape estimation,
S. Zou, C. Guo, X. Zuo, S. Wang, P. Wang, X. Hu, S. Chen, M. Gong, and L. Cheng, “Eventhpe: Event-based 3d human pose and shape estimation,” inICCV, 2021, pp. 10 996–11 005
work page 2021
-
[28]
Benchmarking and analyzing 3d human pose and shape estimation beyond algorithms,
H. E. Pang, Z. Cai, L. Yang, T. Zhang, and Z. Liu, “Benchmarking and analyzing 3d human pose and shape estimation beyond algorithms,” in NeurIPS, vol. 35, 2022, pp. 26 034–26 051
work page 2022
-
[29]
Global-to- local modeling for video-based 3d human pose and shape estimation,
X. Shen, Z. Yang, X. Wang, J. Ma, C. Zhou, and Y . Yang, “Global-to- local modeling for video-based 3d human pose and shape estimation,” inCVPR, 2023, pp. 8887–8896
work page 2023
-
[30]
P. Huang, X. Zhang, S. Yu, and L. Guo, “Is-wars: Intelligent and stealthy adversarial attack to wi-fi-based human activity recognition systems,” TDSC, vol. 19, no. 6, pp. 3899–3912, 2021
work page 2021
-
[31]
Simple black-box adversarial attacks,
C. Guo, J. Gardner, Y . You, A. G. Wilson, and K. Weinberger, “Simple black-box adversarial attacks,” inICML, 2019, pp. 2484–2493
work page 2019
-
[32]
Adversarial texture for fooling person detectors in the physical world,
Z. Hu, S. Huang, X. Zhu, F. Sun, B. Zhang, and X. Hu, “Adversarial texture for fooling person detectors in the physical world,” inCVPR, 2022, pp. 13 307–13 316
work page 2022
-
[33]
Universal physical camouflage attacks on object detectors,
L. Huang, C. Gao, Y . Zhou, C. Xie, A. L. Yuille, C. Zou, and N. Liu, “Universal physical camouflage attacks on object detectors,” inCVPR, 2020, pp. 720–729
work page 2020
-
[34]
Y . Zhang, J. Hou, and Y . Yuan, “A comprehensive study of the robustness for lidar-based 3d object detectors against adversarial attacks,” inIJCV, vol. 132, no. 5, 2024, pp. 1592–1624
work page 2024
-
[35]
Towards transferable targeted 3d adversarial attack in the physical world,
Y . Huang, Y . Dong, S. Ruan, X. Yang, H. Su, and X. Wei, “Towards transferable targeted 3d adversarial attack in the physical world,” in CVPR, 2024, pp. 24 512–24 522
work page 2024
-
[36]
Content- based unrestricted adversarial attack,
Z. Chen, B. Li, S. Wu, K. Jiang, S. Ding, and W. Zhang, “Content- based unrestricted adversarial attack,” inNeurIPS, vol. 36, 2023, pp. 51 719–51 733
work page 2023
-
[37]
Diffusion models for imperceptible and transferable adversarial attack,
J. Chen, H. Chen, K. Chen, Y . Zhang, Z. Zou, and Z. Shi, “Diffusion models for imperceptible and transferable adversarial attack,”TPAMI, 2024
work page 2024
-
[38]
Generating adversarial attacks in the latent space,
N. Shukla and S. Banerjee, “Generating adversarial attacks in the latent space,” inCVPR, 2023, pp. 730–739
work page 2023
-
[39]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Enhanc- ing variational autoencoders with smooth robust latent encoding,
H. Lee, M. Kim, S. Jang, J. Jeong, and S. J. Hwang, “Enhanc- ing variational autoencoders with smooth robust latent encoding,” arXiv:2504.17219, 2025
-
[42]
Recovering accurate 3d human pose in the wild using imus and a moving camera,
T. V on Marcard, R. Henschel, M. J. Black, B. Rosenhahn, and G. Pons- Moll, “Recovering accurate 3d human pose in the wild using imus and a moving camera,” inECCV, 2018, pp. 601–617
work page 2018
-
[43]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
D. Alexey, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv: 2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[44]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018, pp. 586–595
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.