Fast and Simple Densest Subgraph with Predictions
Pith reviewed 2026-05-22 15:08 UTC · model grok-4.3
The pith
A reasonably accurate predictor of nodes in the densest subgraph enables simple linear-time (1-ε) approximation algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a predictor that estimates whether each node belongs to the solution with reasonable accuracy, one can design simple linear-time algorithms that achieve a (1-ε) approximation for both the standard densest subgraph problem and its densest at-most-k subgraph variant.
What carries the argument
A node-membership predictor that guides subgraph selection to achieve high density without exhaustive search.
If this is right
- Densest subgraph algorithms can be made linear-time while retaining strong approximation guarantees.
- The NP-hard densest at-most-k variant becomes tractable in practice when predictions are available.
- Experiments on real-world graphs confirm that the methods produce high-quality subgraphs efficiently.
- Simple prediction-guided procedures replace more intricate combinatorial techniques for these problems.
Where Pith is reading between the lines
- The same predictor-driven simplification may apply to other dense subgraph variants or related graph optimization tasks.
- Training predictors on historical graph data could create self-improving solvers that adapt to specific domains.
- Extending the approach to dynamic or streaming graphs where predictions are updated incrementally is a direct next direction.
Load-bearing premise
The predictor provides a reasonably accurate estimate of whether each node belongs to the optimal solution set.
What would settle it
An input graph and predictor where the predictor misclassifies enough nodes that the algorithm's returned subgraph has density strictly less than (1-ε) times the optimal density.
Figures







read the original abstract
We study the densest subgraph problem and its NP-hard densest at-most-$k$ subgraph variant through the lens of learning-augmented algorithms. We show that, given a reasonably accurate predictor that estimates whether a node belongs to the solution (e.g., a machine learning classifier), one can design simple linear-time algorithms that achieve a $(1-\epsilon)$approximation. Finally, we present experimental results demonstrating the effectiveness of our methods for the densest at-most-$k$ subgraph problem on real-world graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the densest subgraph problem and its NP-hard densest at-most-k variant through learning-augmented algorithms. It claims that a reasonably accurate predictor estimating node membership in the optimal solution (e.g., an ML classifier) enables simple linear-time algorithms achieving (1-ε) approximation. Experimental results on real-world graphs are presented to show effectiveness for the densest at-most-k case.
Significance. If the guarantees hold with truly linear runtime independent of ε, the work would provide a practical bridge between machine learning predictions and approximation algorithms for a fundamental graph problem. The emphasis on simplicity and linear time is valuable for large-scale instances, and the experiments add empirical support. This could influence similar prediction-augmented approaches for other subgraph problems.
major comments (2)
- [§3] §3 (algorithm description) and the proof of the main theorem: the construction must be checked to confirm that the predictor error is converted into an additive loss absorbed by ε without any ε-dependent iterations, sampling, or refinement passes; otherwise the linear-time claim fails for small ε while preserving the (1-ε) guarantee.
- [Theorem 1] Theorem 1 (or equivalent main guarantee): the required predictor accuracy is not stated explicitly as a function of ε; if accuracy must improve as O(ε) or better, the 'reasonably accurate' assumption becomes ε-dependent and the overall result is no longer parameter-free in the stated sense.
minor comments (3)
- [Experimental evaluation] The experimental section should include a direct comparison against standard linear-time or near-linear densest-subgraph baselines (e.g., Charikar's greedy peeling) both with and without the predictor to quantify the actual speedup and quality gain.
- [Preliminaries] Notation for the densest at-most-k variant (e.g., definition of the density function and the cardinality constraint) should be introduced once in a dedicated preliminaries subsection rather than scattered across the text.
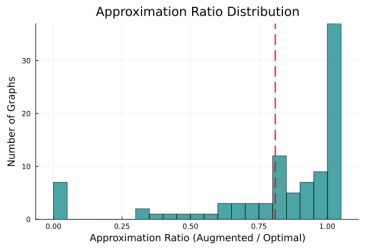
- [Figures] Figure captions for the runtime and approximation plots should explicitly state the graph sizes, predictor error rates used, and what the error bars represent.
Simulated Author's Rebuttal
We thank the referee for their careful review and for recognizing the potential impact of our work. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (algorithm description) and the proof of the main theorem: the construction must be checked to confirm that the predictor error is converted into an additive loss absorbed by ε without any ε-dependent iterations, sampling, or refinement passes; otherwise the linear-time claim fails for small ε while preserving the (1-ε) guarantee.
Authors: We appreciate the referee's attention to the details of the runtime. After verifying the algorithm in Section 3 and the accompanying proof, we confirm that the error from the predictor is incorporated as an additive term in the density approximation. This term is bounded and absorbed into the (1-ε) factor through the analysis without necessitating any iterations, sampling, or refinement steps that scale with 1/ε. The procedure remains a straightforward linear-time algorithm. To address this comment, we will add a note in the revised manuscript explicitly stating that the runtime is independent of ε. revision: yes
-
Referee: [Theorem 1] Theorem 1 (or equivalent main guarantee): the required predictor accuracy is not stated explicitly as a function of ε; if accuracy must improve as O(ε) or better, the 'reasonably accurate' assumption becomes ε-dependent and the overall result is no longer parameter-free in the stated sense.
Authors: We agree that the accuracy requirement should be stated more explicitly. In the manuscript, the predictor is assumed to be 'reasonably accurate,' which in our analysis corresponds to correctly classifying a constant fraction of the nodes belonging to the optimal solution, where this fraction is independent of ε. Thus, the accuracy does not need to improve with smaller ε; a fixed level of accuracy suffices to achieve the (1-ε) approximation. We will revise Theorem 1 to include the precise constant-accuracy requirement to clarify this point. revision: yes
Circularity Check
No circularity: predictor is external input; approximation derived from standard techniques
full rationale
The paper treats the node-membership predictor as an independent external input (e.g., a machine-learning classifier) whose accuracy is assumed rather than fitted or derived inside the algorithm. The linear-time (1-ε) approximation procedures are constructed by augmenting existing peeling or flow-based methods with this input; no equation reduces the guarantee to a quantity defined in terms of the predictor's own outputs, no self-citation chain supplies a uniqueness theorem, and no ansatz is smuggled via prior work by the same authors. The derivation therefore remains self-contained once the predictor quality is granted from outside the paper.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard definition of densest subgraph as the induced subgraph with maximum average degree.
- domain assumption A predictor that outputs per-node membership probabilities or labels can be obtained from a machine-learning classifier.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
given a (1-ε)-partial solution S to H*, there exists an O(n+m)-time algorithm that finds a subgraph whose density is at least (1-O(ε+1/|H*|)) d(H*) (Theorem 1)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iteratively removes nodes with the lowest degree in T (trimming step)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Algorithms with predictions.https://algorithms-with-predictions. github.io/. Accessed: 2025-04-15
work page 2025
-
[2]
Chen, Siddharth Gollapudi, Sandeep Silwal, and Hao Wu
Anders Aamand, Justin Y. Chen, Siddharth Gollapudi, Sandeep Silwal, and Hao Wu. Improved approximations for hard graph problems using predictions. InICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025
work page 2025
-
[3]
Finding large and small dense subgraphs
Reid Andersen. Finding large and small dense subgraphs.CoRR, abs/cs/0702032, 2007
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[4]
Finding dense subgraphs with size bounds
Reid Andersen and Kumar Chellapilla. Finding dense subgraphs with size bounds. InW A W, volume 5427 ofLecture Notes in Computer Science, pages 25–37. Springer, 2009. 16
work page 2009
-
[5]
Bilu- linial stability, certified algorithms and the independent set problem
Haris Angelidakis, Pranjal Awasthi, Avrim Blum, Vaggos Chatziafratis, and Chen Dan. Bilu- linial stability, certified algorithms and the independent set problem. InESA, volume 144 of LIPIcs, pages 7:1–7:16. Schloss Dagstuhl - Leibniz-Zentrum f¨ur Informatik, 2019
work page 2019
-
[6]
Center-based clustering under perturbation stability.Inf
Pranjal Awasthi, Avrim Blum, and Or Sheffet. Center-based clustering under perturbation stability.Inf. Process. Lett., 112(1-2):49–54, 2012
work page 2012
-
[7]
Efficient primal-dual graph algo- rithms for mapreduce
Bahman Bahmani, Ashish Goel, and Kamesh Munagala. Efficient primal-dual graph algo- rithms for mapreduce. InW A W, volume 8882 ofLecture Notes in Computer Science, pages 59–78. Springer, 2014
work page 2014
-
[8]
Densest subgraph in streaming and mapreduce.PVLDB, 5(5):454–465, 2012
Bahman Bahmani, Ravi Kumar, and Sergei Vassilvitskii. Densest subgraph in streaming and mapreduce.PVLDB, 5(5):454–465, 2012
work page 2012
-
[9]
Algorithms, 16(2):22:1–22:39, 2020
Maria-Florina Balcan, Nika Haghtalab, and Colin White.k-center clustering under perturba- tion resilience.ACM Trans. Algorithms, 16(2):22:1–22:39, 2020
work page 2020
-
[10]
Copycatch: Stopping group attacks by spotting lockstep behavior in social networks
Alex Beutel, Wanhong Xu, Venkatesan Guruswami, Christopher Palow, and Christos Falout- sos. Copycatch: Stopping group attacks by spotting lockstep behavior in social networks. In Proceedings of the 22Nd International Conference on World Wide Web (WWW), pages 119–130, 2013
work page 2013
-
[11]
Detecting high log-densities: anO(n 1/4) approximation for densestk-subgraph
Aditya Bhaskara, Moses Charikar, Eden Chlamtac, Uriel Feige, and Aravindan Vijayaragha- van. Detecting high log-densities: anO(n 1/4) approximation for densestk-subgraph. In STOC, pages 201–210. ACM, 2010
work page 2010
-
[12]
Sayan Bhattacharya, Monika Henzinger, Danupon Nanongkai, and Charalampos E. Tsourakakis. Space- and time-efficient algorithm for maintaining dense subgraphs on one- pass dynamic streams. InProc. 47th ACM Symposium on Theory of Computing (STOC), pages 173–182, 2015
work page 2015
-
[13]
Are stable instances easy?Combinatorics, Probability and Computing, 21(5):643–660, 2012
Yonatan Bilu and Nathan Linial. Are stable instances easy?Combinatorics, Probability and Computing, 21(5):643–660, 2012
work page 2012
-
[14]
Fast and accurate triangle counting in graph streams using predictions
Cristian Boldrin and Fabio Vandin. Fast and accurate triangle counting in graph streams using predictions. InICDM, pages 31–40. IEEE, 2024
work page 2024
-
[15]
Tsourakakis, Di Wang, and Junxing Wang
Digvijay Boob, Yu Gao, Richard Peng, Saurabh Sawlani, Charalampos E. Tsourakakis, Di Wang, and Junxing Wang. Flowless: Extracting densest subgraphs without flow com- putations. InWWW, pages 573–583. ACM / IW3C2, 2020
work page 2020
-
[16]
Learning- augmented maximum independent set
Vladimir Braverman, Prathamesh Dharangutte, Vihan Shah, and Chen Wang. Learning- augmented maximum independent set. InAPPROX/RANDOM, volume 317 ofLIPIcs, pages 24:1–24:18. Schloss Dagstuhl - Leibniz-Zentrum f¨ur Informatik, 2024
work page 2024
-
[17]
Greedy approximation algorithms for finding dense components in a graph
Moses Charikar. Greedy approximation algorithms for finding dense components in a graph. InAPPROX, volume 1913 ofLecture Notes in Computer Science, pages 84–95. Springer, 2000
work page 1913
-
[18]
Chandra Chekuri, Kent Quanrud, and Manuel R. Torres. Densest subgraph: Supermodularity, iterative peeling, and flow. InSODA, pages 1531–1555. SIAM, 2022
work page 2022
-
[19]
Dense subgraph extraction with application to community detec- tion.IEEE Trans
Jie Chen and Yousef Saad. Dense subgraph extraction with application to community detec- tion.IEEE Trans. on Knowl. and Data Eng., 24(7):1216–1230, 2012. 17
work page 2012
-
[20]
Chen, Sandeep Silwal, Ali Vakilian, and Fred Zhang
Justin Y. Chen, Sandeep Silwal, Ali Vakilian, and Fred Zhang. Faster fundamental graph algorithms via learned predictions. InICML, volume 162 ofProceedings of Machine Learning Research, pages 3583–3602. PMLR, 2022
work page 2022
-
[21]
Learning-augmented streaming algorithms for approximating MAX-CUT
Yinhao Dong, Pan Peng, and Ali Vakilian. Learning-augmented streaming algorithms for approximating MAX-CUT. InITCS, volume 325 ofLIPIcs, pages 44:1–44:24. Schloss Dagstuhl - Leibniz-Zentrum f¨ur Informatik, 2025
work page 2025
-
[22]
Extraction and classification of dense communities in the web
Yon Dourisboure, Filippo Geraci, and Marco Pellegrini. Extraction and classification of dense communities in the web. InProc. 16th International Conference on World Wide Web (WWW), pages 461–470, 2007
work page 2007
-
[23]
Applications of Uniform Sampling: Densest Subgraph and Beyond
Hossein Esfandiari, MohammadTaghi Hajiaghayi, and David P. Woodruff. Applications of uniform sampling: Densest subgraph and beyond.CoRR, abs/1506.04505, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Willem Feijen and Guido Sch ¨afer. Using machine learning predictions to speed-up dijkstra’s shortest path algorithm.CoRR, abs/2112.11927, 2021
-
[25]
Naughton, Douglas Brutlag, and Serafim Batzoglou
Eugene Fratkin, Brian T. Naughton, Douglas Brutlag, and Serafim Batzoglou. Motifcut: Reg- ulatory motifs finding with maximum density subgraphs.Bioinformatics (Oxford, England), 22:e150–7, 08 2006
work page 2006
- [26]
-
[27]
Improved parallel algorithms for density-based network clustering
Mohsen Ghaffari, Silvio Lattanzi, and Slobodan Mitrovi ´c. Improved parallel algorithms for density-based network clustering. InProc. 36th International Conference on Machine Learning (ICML), volume 97, pages 2201–2210, 2019
work page 2019
-
[28]
Improved parallel algorithms for density-based network clustering
Mohsen Ghaffari, Silvio Lattanzi, and Slobodan Mitrovic. Improved parallel algorithms for density-based network clustering. InICML, volume 97 ofProceedings of Machine Learning Research, pages 2201–2210. PMLR, 2019
work page 2019
-
[29]
Discovering large dense subgraphs in massive graphs
David Gibson, Ravi Kumar, and Andrew Tomkins. Discovering large dense subgraphs in massive graphs. InProceedings of the 31st International Conference on Very Large Data Bases (VLDB), pages 721–732, 2005
work page 2005
-
[30]
A. V. Goldberg. Finding a maximum density subgraph. Technical Report UCB/CSD-84-171, EECS Department, University of California, Berkeley, 1984
work page 1984
-
[31]
Samir Khuller and Barna Saha. On finding dense subgraphs. InICALP (1), volume 5555 of Lecture Notes in Computer Science, pages 597–608. Springer, 2009
work page 2009
-
[32]
Samir Khuller and Barna Saha. On finding dense subgraphs. InProc. 36th International Collo- quium on Automata, Languages and Programming (ICALP), pages 597–608, 2009
work page 2009
-
[33]
A survey on the densest subgraph problem and its variants.ACM Comput
Tommaso Lanciano, Atsushi Miyauchi, Adriano Fazzone, and Francesco Bonchi. A survey on the densest subgraph problem and its variants.ACM Comput. Surv., 56(8):208:1–208:40, 2024
work page 2024
-
[34]
SNAP Datasets: Stanford large network dataset collection
Jure Leskovec and Andrej Krevl. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014
work page 2014
-
[35]
Almost-polynomial ratio eth-hardness of approximating densest k- subgraph
Pasin Manurangsi. Almost-polynomial ratio eth-hardness of approximating densest k- subgraph. InSTOC, pages 954–961. ACM, 2017. 18
work page 2017
-
[36]
Andrew McGregor, David Tench, Sofya Vorotnikova, and Hoa T. Vu. Densest subgraph in dynamic graph streams. InMFCS (2), volume 9235 ofLecture Notes in Computer Science, pages 472–482. Springer, 2015
work page 2015
-
[37]
Algorithms with predictions.Commun
Michael Mitzenmacher and Sergei Vassilvitskii. Algorithms with predictions.Commun. ACM, 65(7):33–35, 2022
work page 2022
-
[38]
Faster global minimum cut with pre- dictions.CoRR, abs/2503.05004, 2025
Benjamin Moseley, Helia Niaparast, and Karan Singh. Faster global minimum cut with pre- dictions.CoRR, abs/2503.05004, 2025
-
[39]
Jean-Claude Picard and Maurice Queyranne. A network flow solution to some nonlinear 0-1 programming problems, with applications to graph theory.Networks, 12(2):141–159, 1982
work page 1982
-
[40]
Karate Club: An API Oriented Open- source Python Framework for Unsupervised Learning on Graphs
Benedek Rozemberczki, Oliver Kiss, and Rik Sarkar. Karate Club: An API Oriented Open- source Python Framework for Unsupervised Learning on Graphs. InProceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM ’20), page 3125–3132. ACM, 2020
work page 2020
-
[41]
Dense sub- graphs with restrictions and applications to gene annotation graphs
Barna Saha, Allison Hoch, Samir Khuller, Louiqa Raschid, and Xiao-Ning Zhang. Dense sub- graphs with restrictions and applications to gene annotation graphs. InResearch in Compu- tational Molecular Biology, pages 456–472, 2010
work page 2010
-
[42]
Dense subgraphs on dynamic networks
Atish Das Sarma, Ashwin Lall, Danupon Nanongkai, and Amitabh Trehan. Dense subgraphs on dynamic networks. InDISC, volume 7611 ofLecture Notes in Computer Science, pages 151–165. Springer, 2012
work page 2012
-
[43]
Near-optimal fully dynamic densest subgraph
Saurabh Sawlani and Junxing Wang. Near-optimal fully dynamic densest subgraph. In Proc. 52th ACM Symposium on Theory of Computing (STOC), 2020. To appear
work page 2020
-
[44]
Hsin-Hao Su and Hoa T. Vu. Distributed dense subgraph detection and low outdegree orien- tation. InDISC, volume 179 ofLIPIcs, pages 15:1–15:18. Schloss Dagstuhl - Leibniz-Zentrum f¨ur Informatik, 2020. 19
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.